一、 数据流风格 (Data Flow Styles)
这类风格的核心是:数据像水流一样穿过系统,经过一系列的处理。
-
管道-过滤器 (Pipe and Filter)
-
特点: 每个构件(过滤器)读取输入数据流,对其进行局部变换,然后产生输出数据流。过滤器之间互不依赖,通过管道连接。
-
优点: 高内聚低耦合,支持重用(过滤器可以随意组合),支持并行执行。
-
缺点: 性能开销大(因为每次通过管道都要进行数据解析和反解析),不适合处理交互式系统。
-
经典应用: 传统编译器、Linux 命令行操作(如
ls | grep | sort)。
-
-
批处理序列 (Batch Sequential)
-
特点: 和管道-过滤器类似,但数据不是"流"过去的,而是一个完整的"批次"。必须等前一个步骤把所有数据处理完,打包成一个整体传递给下一个步骤。
-
经典应用: 银行的夜间账单结算系统、大型工资单结算。
-
二、 调用/返回风格 (Call/Return Styles)
这类风格的核心是:"你吩咐,我照办",通过函数调用或方法调用来实现交互。 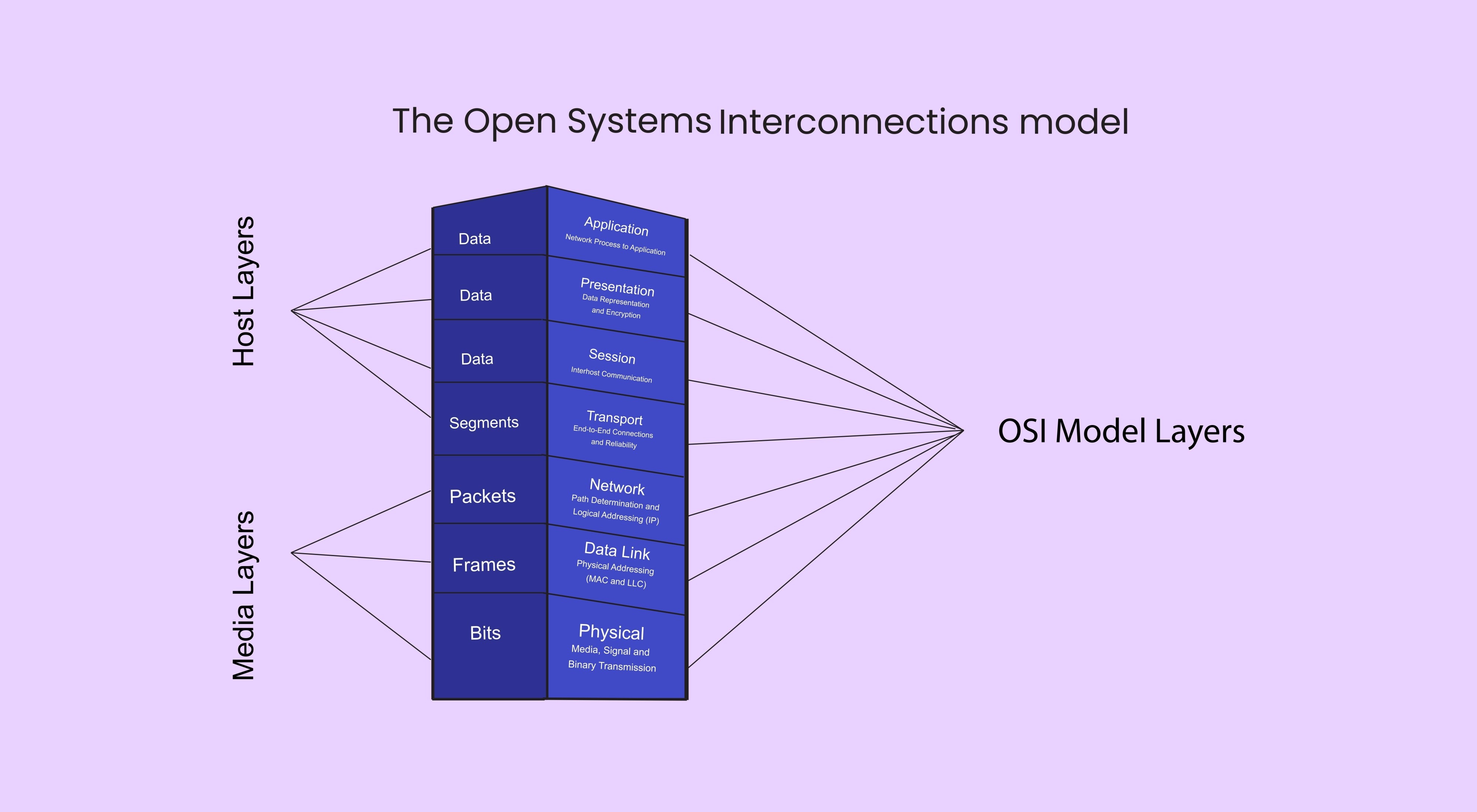
-
分层架构 (Layered Architecture)
- 特点: 系统被划分为若干层,每一层只对上一层提供服务,并作为下一层的客户。严格遵循"只能向下调用"的规则。
- 优点: 结构清晰,便于分工;某一层发生变化,只要接口不变,就不会影响其他层(良好的可维护性)。
- 缺点: 性能损耗(一个请求可能要穿透好几层),有时会造成级联修改。
- 经典应用: 计算机网络的 OSI 七层模型、TCP/IP 协议栈、传统的 MVC Web 架构。
-
面向对象 (Object-Oriented)
-
特点: 数据和操作数据的行为被封装在对象中。对象之间通过消息传递(方法调用)进行协作。
-
优点: 封装性好,贴近人类思维,支持代码复用和多态。
-
-
客户端/服务器 (Client/Server,简称 C/S)
- 特点: 分为请求服务的客户端和提供服务的服务端。胖客户端会在本地处理大量业务逻辑,瘦客户端(如网页端 B/S 架构)则只负责展示。
三、 独立构件风格 (Independent Component Styles)
这类风格的核心是:组件之间互不相识,通过一个中间媒介来"暗中观察"或"喊话"。
-
发布-订阅 / 事件驱动 (Publish-Subscribe / Event-Driven)
-
特点: 构件不直接调用对方,而是"发布"一个事件或消息。其他构件事先向系统"订阅"这个事件,一旦事件发生,系统就会自动触发订阅了该事件的构件。
-
优点: 极度的低耦合。新增一个订阅者,发布者完全不需要改代码;非常适合异步处理。
-
缺点: 流程控制变得困难(发布者不知道最终到底有谁处理了这个事件,也不知道什么时候处理完),排查 Bug 较难。
-
经典应用: 消息队列(Kafka, RabbitMQ)、GUI 图形界面的按钮点击响应。
-
四、 数据中心风格 / 仓库风格 (Data-Centered Styles)
这类风格的核心是:大家围着一个"中央数据池"转。
-
信息库 / 数据库系统 (Repository / Database Systems)
-
特点: 有一个中央数据结构表示系统的当前状态,多个独立的执行构件对这个中央数据进行增删改查。数据是被动响应的。
-
优点: 数据共享方便,易于扩展新的处理构件。
-
经典应用: 所有的现代业务信息管理系统(如电商后台、人事管理系统)。
-
-
黑板系统 (Blackboard System)
-
特点: 是一种特殊的信息库。它的数据结构(黑板)是主动的,当黑板上的数据发生变化时,会自动唤醒相关的专家系统(知识源)来处理。它就像一群专家围着一块黑板解题,谁能接着往下算,谁就上去写。
-
优点: 非常适合解决没有确定算法、高度复杂的非结构化问题。
-
经典应用: 语音识别、模式识别、复杂的人工智能系统。
-
五、 虚拟机风格 (Virtual Machine Styles)
这类风格的核心是:自定义一套语言或规则,自己翻译自己执行。
-
解释器 (Interpreter)
-
特点: 包含一个状态机、一个执行引擎、以及被解释的代码。它可以在运行时将自定义的语言或脚本翻译成机器能懂的操作。
-
优点: 极高的灵活性,可以跨平台,能够动态改变系统行为。
-
缺点: 性能较差(因为是边翻译边执行)。
-
经典应用: Java 虚拟机 (JVM)、Python 解释器、游戏引擎中的脚本执行器。
-