当大模型不再只是云端"黑盒",而是能真正跑在国产服务器上、吃透企业数据、保障安全合规的时候,AI 才算真正走进了政企、金融、政务的核心业务。DeepSeek V4 的发布,让我们看到了这种可能性。
过去两年,大家都在做大模型。但你有没有发现一个现象:能用得好的,多是互联网和科技大厂;政企、金融这些"数据重地",反而一直隔岸观火?
原因不复杂:数据不能出域、模型不能出境、算力买不到最顶级的、国产芯片生态还在爬坡......三重、四重约束下,大模型私有化部署,成了一个"既要又要还要"的难题。
直到近期 DeepSeek-V4 开源。它到底解决了什么问题?为什么值得中间件团队、平台架构师、政企 AI 中台负责人认真研究?
我用一篇博客,把它的核心亮点、落地姿势、底层原理和"坑"都说清楚。
一、痛点:大模型落地政企,为啥这么难?
我们先看一张"四象限图"------虽然原文只有文字,但你可以脑补出那个画面:横轴是合规可控性(低→高),纵轴是能力上限(低→高)。
-
闭源 API(如 GPT-4):能力上限很高,但合规可控性极低------数据出域就是死罪,政务、金融直接 pass。
-
开源稠密 70B~100B 模型:可以私有化部署,但能力上限有限,复杂推理、多步 Agent 经常"翻车"。
-
早期 MoE(混合专家)模型:能力上限高一些,但工程门槛高,路由不稳定,专家失衡,训都训不稳。
-
DeepSeek V4:能力上限高 + 合规可控(开源+私有化),气泡(部署成本)比早期 MoE 明显缩小。
如果你在金融机构或政府部门负责 AI 中台,你一定会认同这几个典型的"日常折磨":
| 维度 | 痛点 | 业务影响 |
|---|---|---|
| 合规 | 数据不出域、模型不出境、日志可审计 | 公有云 API 不可用,必须自建 |
| 算力 | 单机 8 卡 H800 跑不动 600B+ 稠密模型 | 推理成本爆炸,并发上不去 |
| 信创 | 国产 GPU(昇腾/海光/沐曦)算子覆盖不全 | 从 CUDA 迁移过来像"跨物种移植" |
| 工程 | RAG/Agent 链路复杂、上下文窗口短、输出不稳定 | 业务接入周期按月算,运维天天救火 |
V4 要回应的,正是这些问题:
-
同样的显存,激活更多有效参数(MoE 细粒度化)
-
长上下文真正实用化(128K 可部署在 8 卡集群)
-
工具调用(tool calling)结构化输出更稳
-
对昇腾、海光、沐曦的适配逐渐成熟
二、落地:怎么把它跑起来,跑得稳?
我不讲虚的,直接上干货。
2.1 部署架构长啥样?
推荐"推理引擎 + 编排平面 + 数据平面 + 治理平面"四层结构。用 Mermaid 画出来是这样:
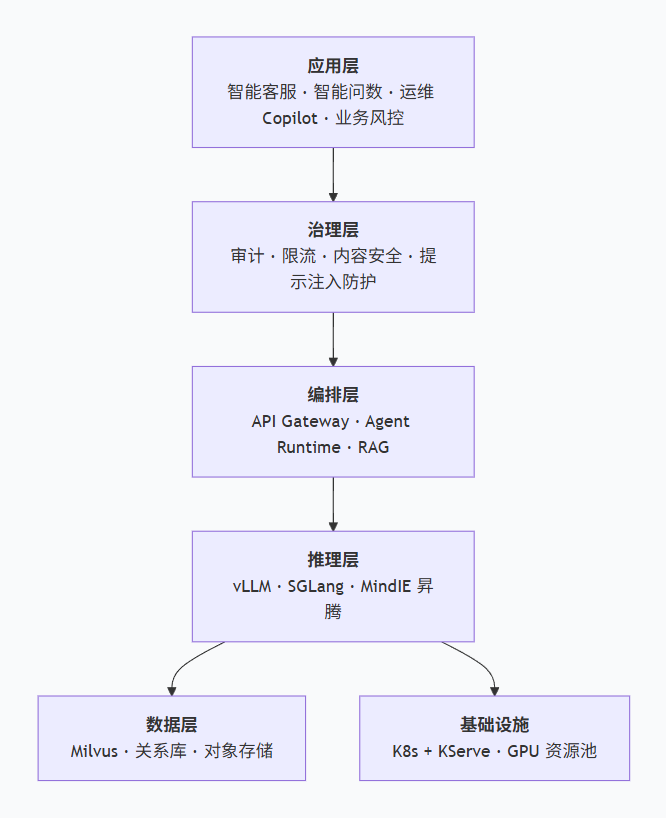
治理层是很多团队容易忽略的------限流、审计、内容安全,不能全指望大模型自带对齐。
2.2 推理引擎怎么配?拿 vLLM 举个例
V4 是 MoE + MLA 架构,推理时有两个关键开关:专家并行 和 KV cache 压缩。
from vllm import LLM
llm = LLM(
model="deepseek-ai/DeepSeek-V4",
tensor_parallel_size=8, # 8卡张量并行
enable_expert_parallel=True, # MoE必须开!
max_model_len=131072, # 128K上下文
quantization="fp8", # FP8量化,精度损失小
kv_cache_dtype="fp8_e5m2", # KV cache也压成FP8
)如果你不做专家并行,单卡装不下所有专家;如果你不做 KV cache 压缩,长上下文会把显存撑爆。这两个参数,生产环境必调。
2.3 国产芯片上要注意啥?
| 平台 | 推理栈 | 关键注意点 |
|---|---|---|
| 昇腾 910B | MindIE / vLLM-Ascend | 验证 FP8 算子覆盖长序列稳定性 |
| 海光 DCU | DTK + ROCm | MoE 路由 kernel 可能要 fallback |
| 沐曦 GPU | MXMACA | 张量并行通信带宽是瓶颈 |
| 鲲鹏 ARM | 编译推理 | 注意 4K vs 64K 页大小、NUMA 绑定 |
一句话:别信"完美兼容",先压测。
三、原理:V4 到底强在哪?
要理解 V4,只要搞懂两个核心:MoE 和 MLA。
3.1 MoE:不是省算力,而是"花小钱办大事"
MoE 的全称是 Mixture of Experts(混合专家)。你可以把它理解成:一个大模型里藏着几十个"小专家",每次推理只激活其中几个最相关的。
DeepSeek 的 MoE 走过了三个阶段:
-
V2:细粒度专家 + 共享专家 ------ 解决"专家太专,通用能力差"
-
V3:无辅助损失负载均衡 ------ 用偏置项动态调整路由,不再傻傻加 aux-loss
-
V4:进一步细粒度化、跨层路由复用 ------ 目标是"相同显存,更高智能"
一个通俗类比:
传统稠密模型像一家全能医院,每个医生都得懂所有科室,人多了成本高。
MoE 像一家三甲医院,前台(路由)根据病情分诊到心内科、骨科......每个专家只钻研自己擅长的,但总人数多、大楼占地大(总参数大),而每次看病只花一个科室的成本(激活参数小)。
所以 MoE 不是"省钱",而是用更大的存储占地,换每次推理的更低计算成本。这在私有化部署中是巨大优势。
3.2 MLA:让长上下文不再是"显存杀手"
MLA(Multi-head Latent Attention)是 DeepSeek 让长上下文实用化的秘密武器。
传统注意力里,每个 token 都要存一份 K 和 V 向量,上下文越长,显存呈线性增长。MLA 的做法是:不直接存 K、V,而是存一个低维的"潜在向量" latent,推理时再临时还原。
效果:KV cache 显存占用大幅下降。128K 上下文在 8 卡 H800 上可以跑得动,这在过去不敢想。
你可以把 MLA 想象成压缩文件------平时存压缩包(latent),用的时候再解压(还原 K、V),虽然多了一步计算,但省下了大量硬盘(显存)空间。
3.3 MoE vs 稠密模型:怎么选?
| 维度 | 稠密 70B | DeepSeek V4 (MoE) |
|---|---|---|
| 总参数 | 较小 | 很大(数倍) |
| 激活参数 | =总参数 | 约 1/8 ~ 1/10 |
| 显存占用 | 线性正比于总参数 | 线性正比于总参数(更大!) |
| 推理计算 | 高 | 较低(只算激活专家) |
| 工程复杂度 | 低 | 高(路由、并行、负载均衡) |
| 单机最小部署 | 较易 | 必须多卡 |
| 能力上限 | 受参数规模约束 | 相同算力预算下更高 |
结论:MoE 不是免费午餐。它用更高的存储和工程复杂度,换来了更强的能力上限。如果你算力卡不多但存储够,MoE 很香;如果你只有单卡且无法扩展,稠密模型可能更现实。
四、最佳实践:少踩几个坑
我从原文里挑了 7 条最实用的,直接给:
-
版本锁死:模型权重 SHA、推理引擎版本,生产环境一定要固定,别追 daily build。
-
训练推理隔离:GPU 池子分开,避免训练占满导致 P99 抖动。
-
监控专家负载:定期看每个专家被激活的频率,发现长期不激活的专家,考虑再平衡。
-
建回归集:至少 200 条真实业务 prompt,每次模型或推理栈变更必须跑通。
-
量化先 FP8:金融/政务场景优先 FP8,精度损失最小;跑通了再试 W4A16。
-
冷启动优化:把系统提示词和常用 RAG 上下文用 Prefix Cache 缓存,首 Token 延迟大幅降低。
-
安全别丢给模型:在编排层做审计和内容过滤,别指望模型自己对答如流。
五、风险提示:别只看见优点,也要看见坑
| 风险 | 现象 | 对策 |
|---|---|---|
| MoE 输出不稳定 | 路由抖动,小概率"胡言乱语" | 加输出 schema 校验,异常率监控 |
| 专家负载失衡 | 少数专家永远闲置 | 监控激活分布,必要时微调 |
| 信创算子缺口 | FP8 GEMM 在国产卡上 fallback 到慢路径 | 完整压测,提前备 fallback 预案 |
| 长上下文幻觉 | 128K 输入中段关键信息被遗忘 | 关键信息放首尾,或重复强调 |
| 存储带宽压力 | 模型大,加载慢,占满 NVMe | 预加载 + 高速存储 + 镜像分发优化 |
六、写在最后
DeepSeek V4 不是"吊打 GPT-5"的神器,也不适合所有场景。但在 私有化、信创化、合规化 这三座大山面前,它确实给了我们一个当前能力上限最高、且敢真正落地到国产硬件的开源选项。
如果你正在为政企或金融机构选型 AI 基础模型,不妨拿它跑一跑你们的真实业务数据。也许你会发现:大模型私有化,真的离我们不远了。
*本文基于 DeepSeek 官方公开技术路径与开源生态实践整理。部分细节以 V2/V3 已公开机制为基线,结合 V4 公开特性进行合理延伸。生产环境部署请以官方最新文档为准。*