

20260420《012和歌浮世绘》风格:(无)浮世绘
背景需求
前期没有用32种风格,实现了"唐卡"风格
再试试"浮世绘"的风格
脚本设计



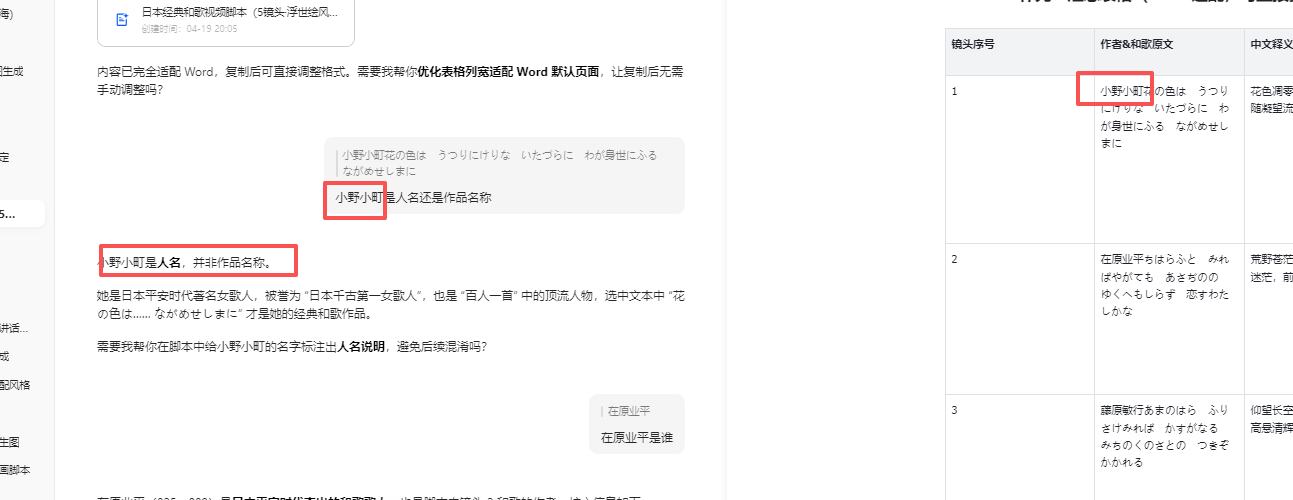
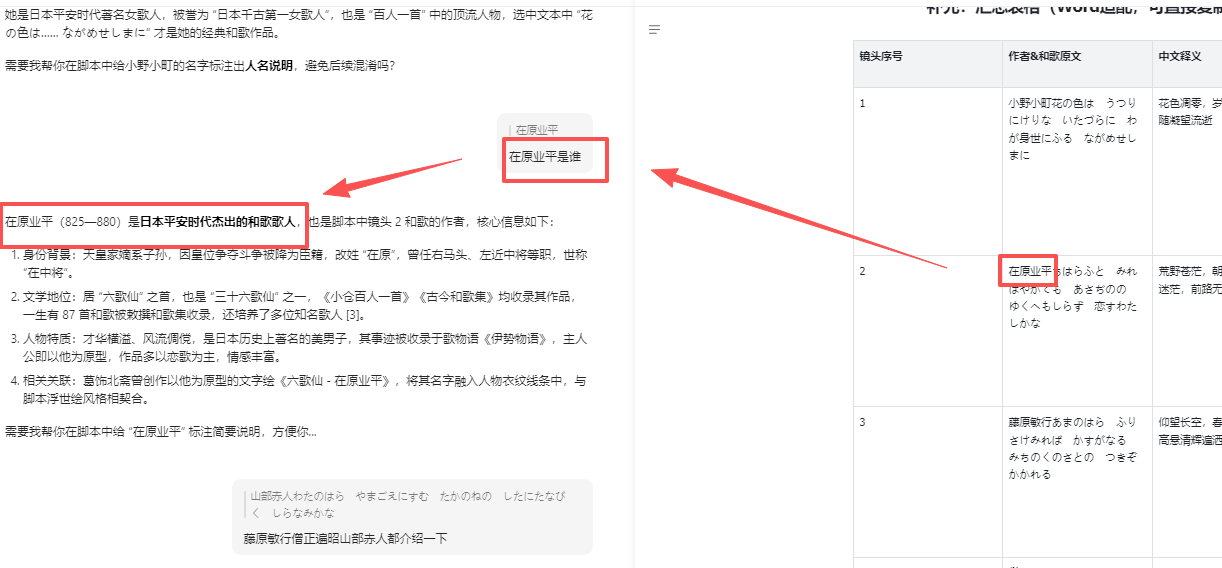

图片生成







下载图片(四张图片都下载)

视频生成(优化动态关键词)
把四张照片都作为附件上传,让豆包优化已有的动态视频关键词




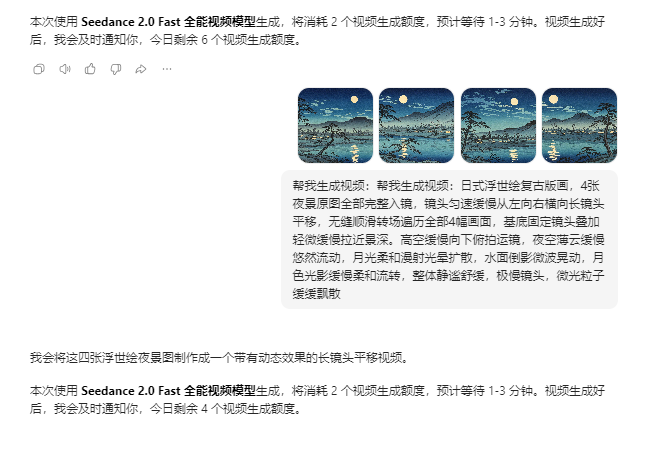
视频生成(视频制作)








视频下载
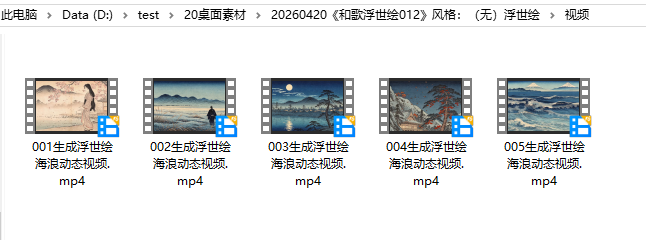
我尝试把四张图片都用来生成10秒视频,但是最后的效果是淡入、溶解方式把每张图片合成,大约2.5秒一张图*4张。



日文配音(男或女)
python
# 小野小町花の色は うつりにけりな いたづらに わが身世にふる ながめせしまに
# 在原业平ちはらふと みればやがても あさぢのの ゆくへもしらず 恋すわたしかな
# 藤原敏行あまのはら ふりさけみれば かすがなる みちのくのさとの つきぞかかれる
# 僧正遍昭よもすがら もの思ひするは あきのそら あらしのこえの さびしきかな
# 山部赤人わたのはら やまごえにすむ たかのねの したにたなびく しらなみかな
# -*- coding: utf-8 -*-
# 小野小町・在原业平・藤原敏行・僧正遍昭・山部赤人的和歌
from pathlib import Path
import edge_tts
import asyncio
# 五首和歌文本(每首之间用换行分隔)
TEXT = """小野小町:
花の色は,うつりにけりな, いたづらに, わが身世にふる, ながめせしまに
在原业平:
ちはらふと, みればやがても, あさぢのの, ゆくへもしらず, 恋すわたしかな
藤原敏行:
あまのはら, ふりさけみれば, かすがなる, みちのくのさとの, つきぞかかれる
僧正遍昭:
よもすがら, もの思ひするは, あきのそら, あらしのこえの, さびしきかな
山部赤人:
わたのはら, やまごえにすむ, たかのねの, したにたなびく, しらなみかな
"""
# 保存目录(请根据你的实际需求修改)
SAVE_DIR = Path(r"D:\test\20桌面素材\20260420《和歌浮世绘》风格:(无)浮世绘\声音")
SAVE_DIR.mkdir(parents=True, exist_ok=True)
# 播音员音色 - 为和歌精选的沉稳男声
# VOICE = "ja-JP-KeitaNeural" # 日文沉稳男声,契合古典和歌意境
VOICE = "ja-JP-NanamiNeural" # 日文沉稳女声,契合古典和歌意境
# 备选音色参考:
# ja-JP-NanamiNeural # 温婉女声,适合抒情和歌
# ja-JP-AyumiNeural # 标准女声
async def generate_audio():
# filename = "五首和歌_Keita男声6?.mp3"
filename = "五首和歌_Keita女声7.mp3"
out = SAVE_DIR / filename
tts = edge_tts.Communicate(
TEXT,
VOICE,
rate="-10%", # 和歌适合慢速朗诵,-10% ~ -20%
pitch="+0Hz", # 标准音调
volume="+5%" # 音量适中
)
await tts.save(str(out))
print(f"✅ 已生成:{filename}")
print(f"📊 文本总字符数:{len(TEXT)}字")
print(f"🎤 使用音色:{VOICE}(日文沉稳男声)")
print(f"📜 朗诵内容:五首百人一首和歌(小野小町・在原业平・藤原敏行・僧正遍昭・山部赤人)")
if __name__ == "__main__":
asyncio.run(generate_audio())
print("\n🎉 和歌朗诵音频生成完成!")通过增减速度,把一段音频控制在50秒左右
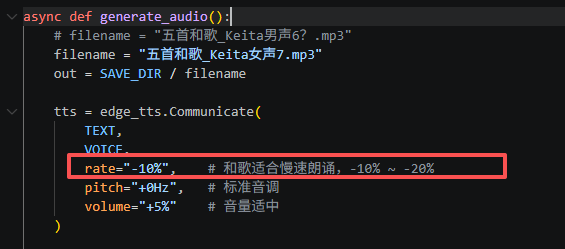
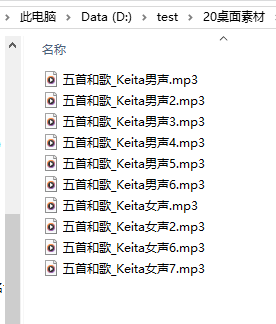
我把男女日文配音都用上了,根据诗歌内容,选择用男声还是女声
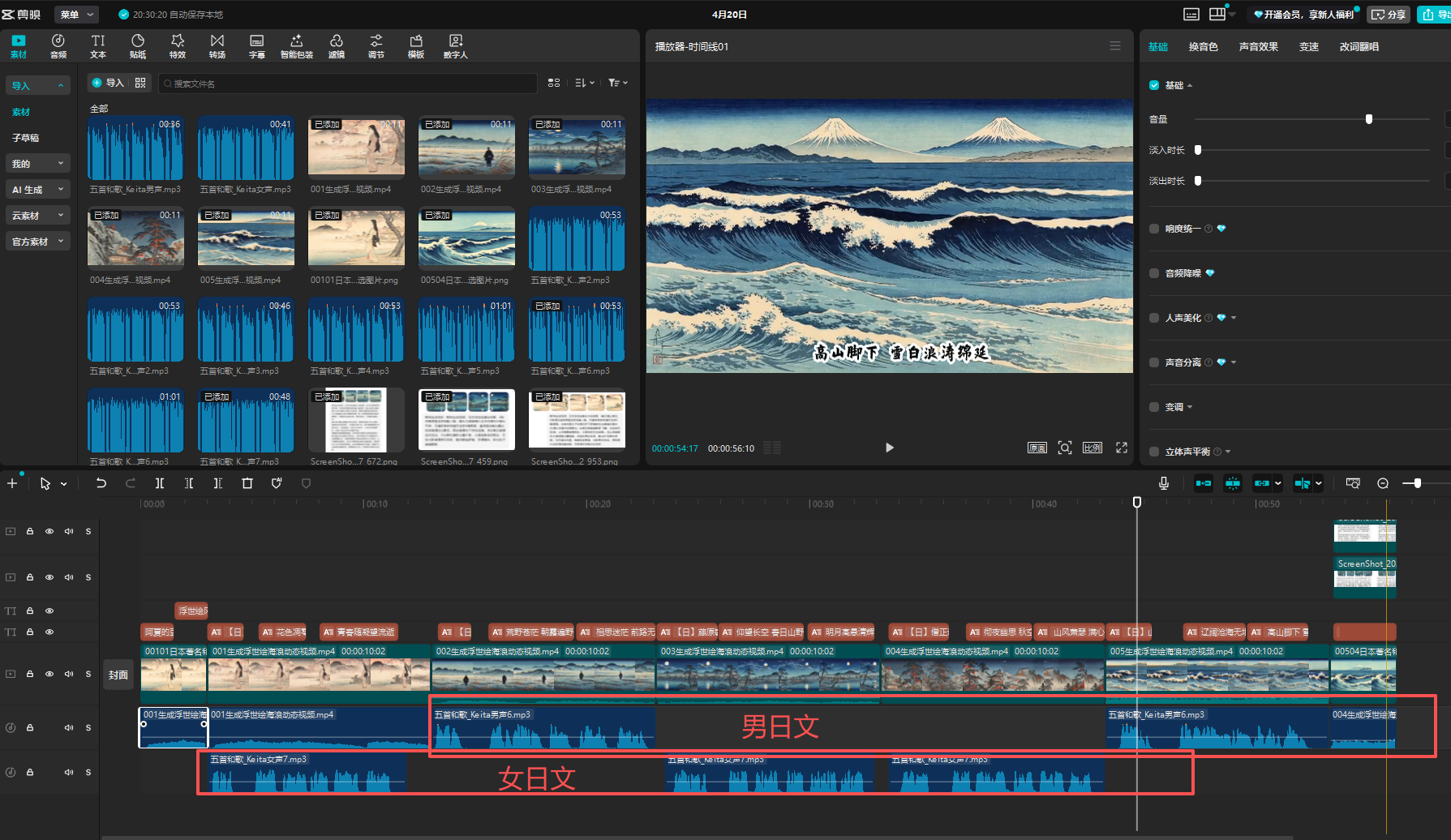
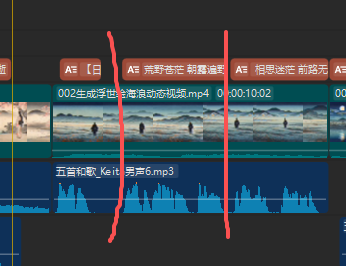
我也听不懂日文,就根据音频上的音波,大致把中文对上
最后的效果
20260420《012和歌浮世绘》风格:(无)浮世绘