目录
[1. HTTP是什么](#1. HTTP是什么)
[2. HTTP协议格式](#2. HTTP协议格式)
[3. HTTP 请求(Request)](#3. HTTP 请求(Request))
[3.1 认识URL](#3.1 认识URL)
[3.1.1 URL的格式](#3.1.1 URL的格式)
[3.1.2 认识URL encode](#3.1.2 认识URL encode)
[3.2 认识"方法"](#3.2 认识“方法”)
[3.2.1 get](#3.2.1 get)
[3.2.2 post](#3.2.2 post)
[4. 请求的报头(header)](#4. 请求的报头(header))
[4.1 Host](#4.1 Host)
[4.2 Content-Length](#4.2 Content-Length)
[4.3 Content-Type](#4.3 Content-Type)
[4.4 User-Agent(简称UA)](#4.4 User-Agent(简称UA))
[4.5 Referer](#4.5 Referer)
[4.6 Cookie](#4.6 Cookie)
[5. 请求的正文(body)](#5. 请求的正文(body))
(响应报文在下篇讲解)
1. HTTP是什么
HTTP(全称"超文本传输协议")是应用非常广泛的应用层协议。
HTTP是无状态 的。(HTTPS是基于HTTP开发的,所以HTTPS也是无状态的)
HTTP是基于TCP进行的网络数据传输
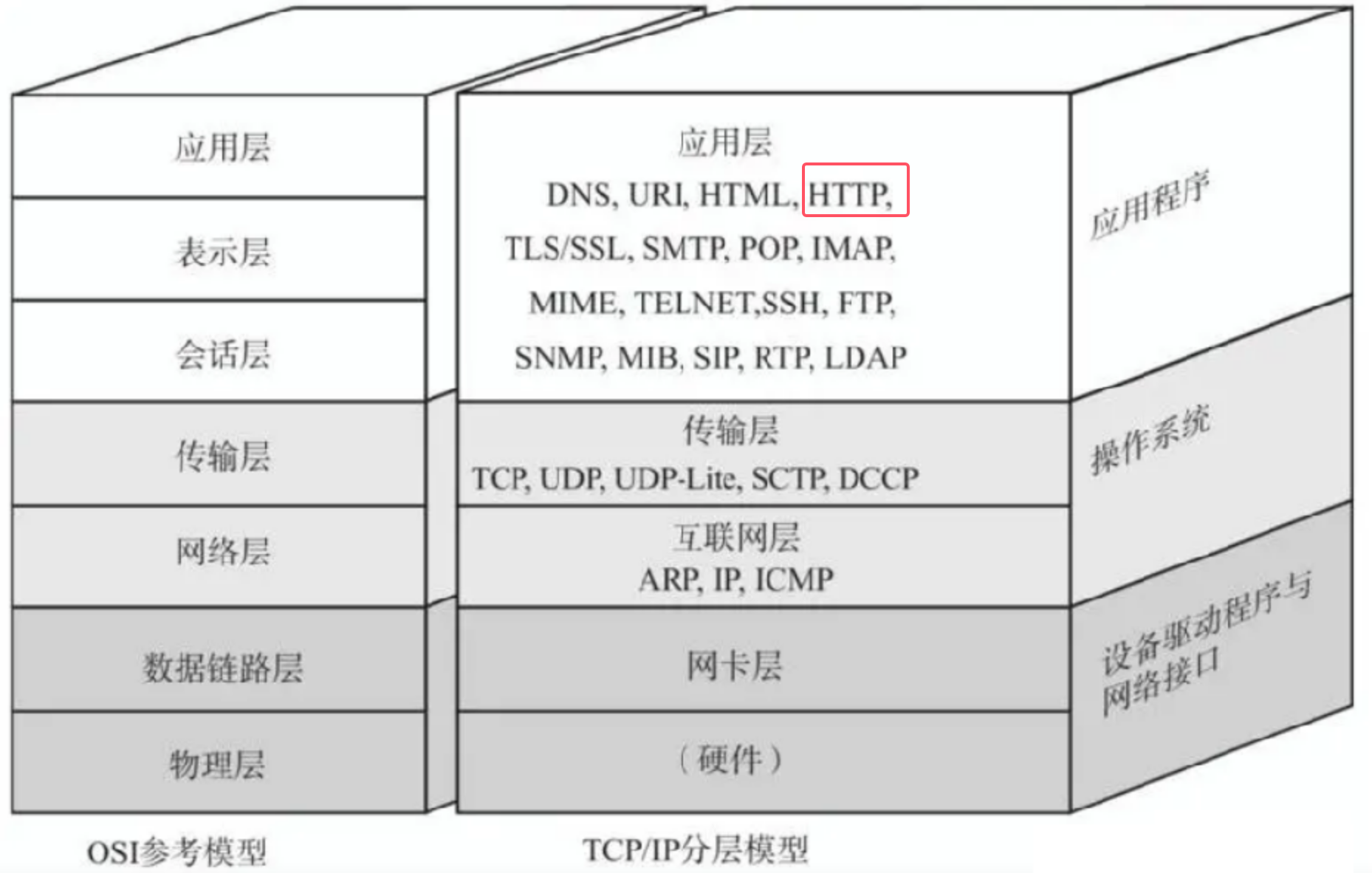
既然HTTP协议在TCP/IP五层协议模型中,那么该协议肯定也是用来网络通信的,直接展示:
例如,在浏览器中我们经常看见http(或https,https就是http+安全这个单词的首字母,也就是多了个安全层,http规定的协议https照样有),直接用https演示:
当然,HTTP协议也广泛应用于微服务,手机APP等,不仅应用在网站的请求与响应。
2. HTTP协议格式
HTTP在网络通信时分为请求报文 和响应报文, 因此也有人说HTTP协议格式 为HTTP报文格式。
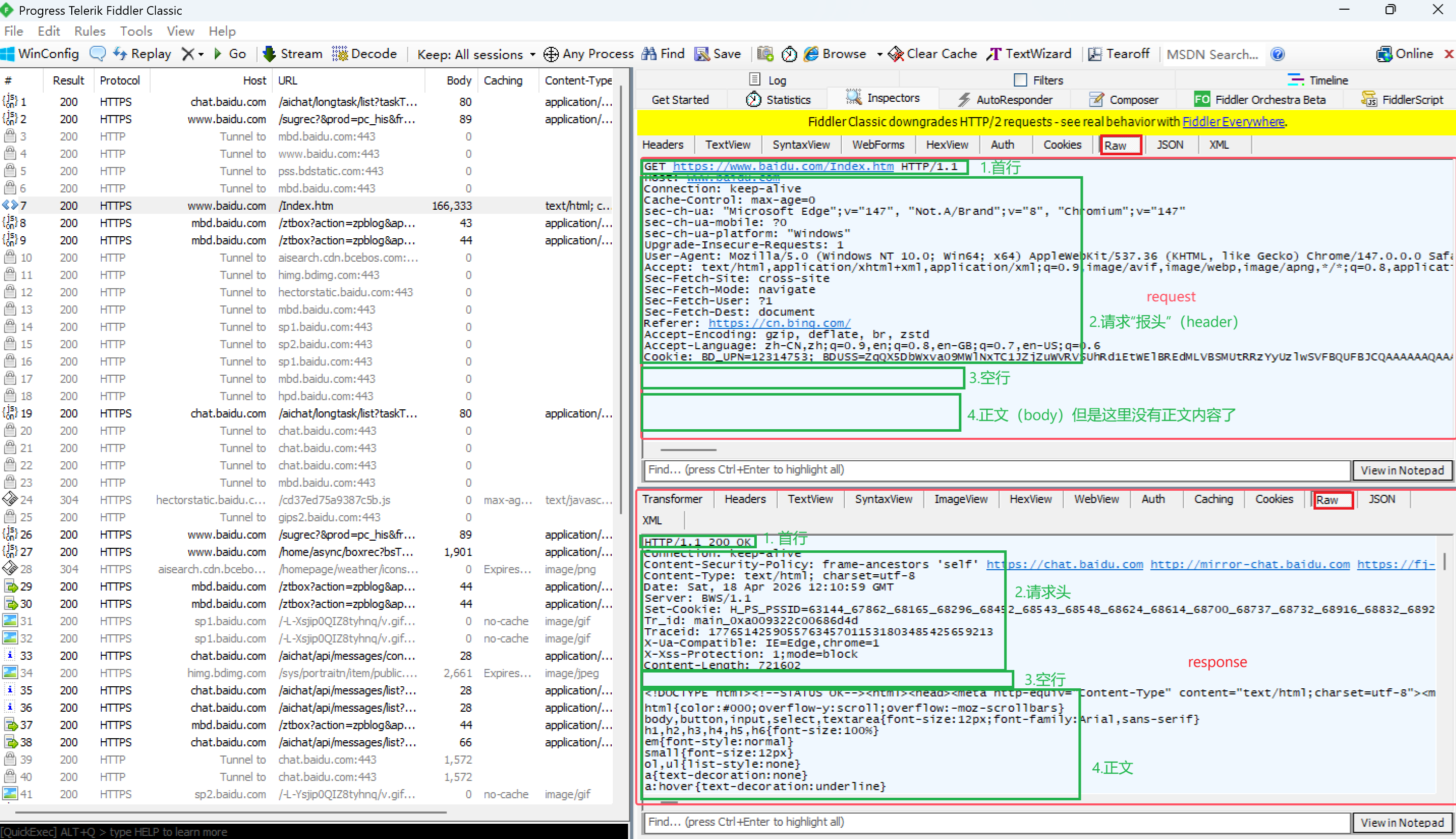
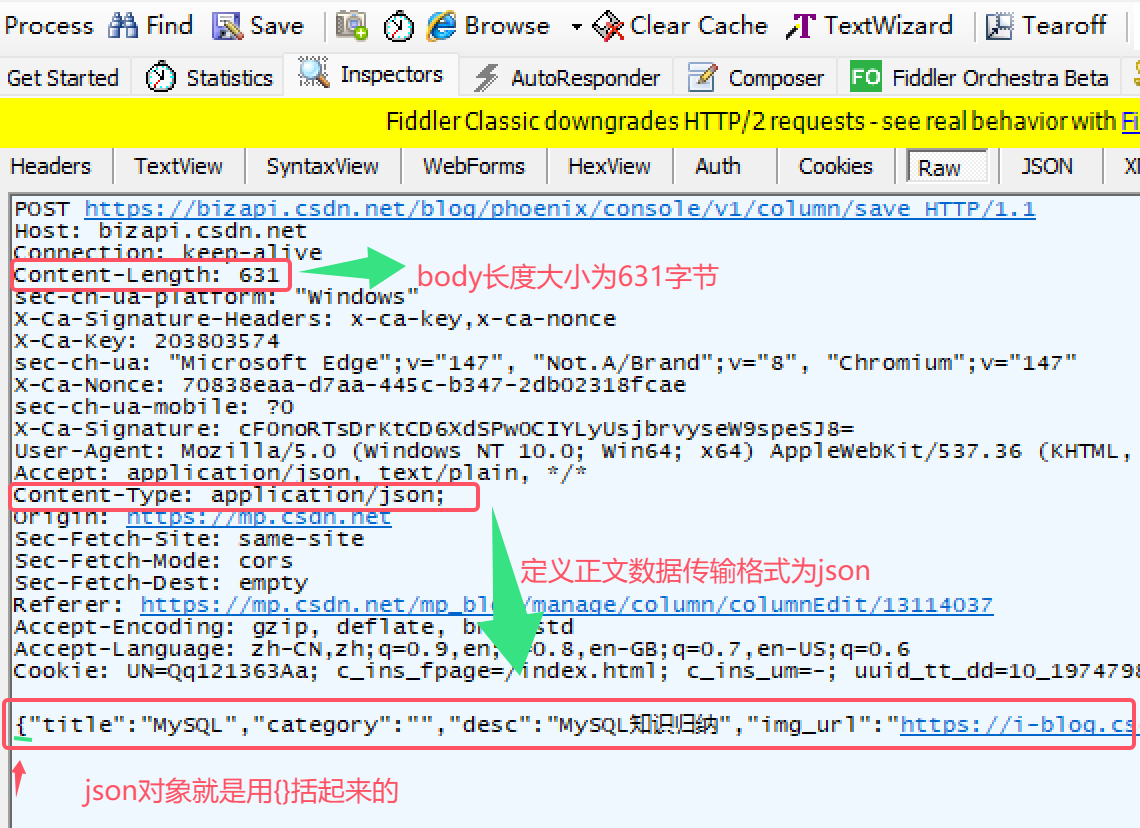
上述图片使用抓包工具 fiddler抓取的请求和响应。通过抓取到的http也能分析出http协议格式,不管请求还是响应,http结构大体分为四块:
- 首行
- 请求头(header)
- 空行
- 正文(body)
每一块又包含许多信息,比如各种键值对。这些数据的作用全部都会在请求报文和响应报文中讲到。
fiddler官方:Web Debugging Proxy and Troubleshooting Tools | Fiddler
请求和响应的报文格式大体结构一致,但每一块中,它们差别还是不小的,下面将具体分析。
3. HTTP 请求(Request)
http分为四部分:1.首行,2.请求头,3.空行,4.正文;请求报文首行包含方法、URL和协议版本号
3.1 认识URL
**URL是"统一资源定位符"(Uniform Resource Locator)的缩写,平常说"你把这个网站发给我",其实发的就是URL。**它是互联网上用于标识和定位某一特定资源(如网页、图片、视频、文件等)的唯一地址。
3.1.1 URL的格式
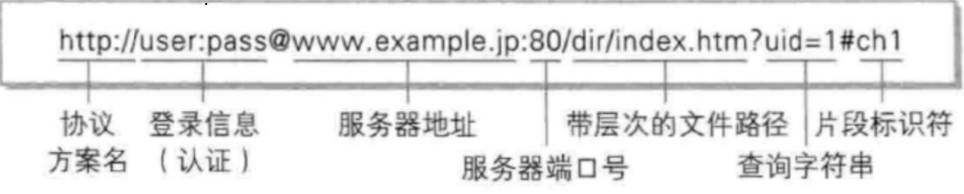
http与httpsURL格式都是一样的,只是开头换个协议方案名而已(http->https)。
图片中的格式是URL完整版,查询字符串和片段标识符是以key=value(键值对)的形式传输的;实际中"登录信息 "、"端口号 "、"文件路径 "、"查询字符串 "和"片段标识符 "都可以省略,如:https://www.baidu.com/
URL 可省略部分
- 登录信息:可以省略。因为信息安全问题,现在都省略了"登录信息"。
- 协议名:可以省略,省略后默认为http://
- IP地址/域名:在HTML中可以省略(比如 img, link, script, a 标签的scr或者href属性)。省略后表示服务器的 IP/域名 与当前HTML所属的 IP/域名 一致。
- 端口号:可以省略。省略后如果是http协议,端口号自动设为80;如果是https协议,端口号自动设为443。
- 带层次的文件路径:可以省略。省略后相当于/. 有些服务器会发现 / 路径的时候自动访问/index.html
- 查询字符串:可以省略。
- 片段标识:可以省略。
(下面有域名的解释)
大家不用觉得URL很高级,url的各项结构内容都是程序员自定义的,最突出的就是"层次文件路径 "和"查询字符串 "。本章不涉及URL的使用,在"JavaEE进阶:Spring MVC"文章(现在还未写)中会详细讲解设计和使用URL全程。
详解URL:URL("统一资源定位符")是为了定位网络资源的唯一地址。URL结构中的"IP/域名 "和"端口号"的作用自不必多说,我们详讲"带层次文件路径"和"查询字符串"。
1 .一个完整的项目中有许多 资源/接口 映射的网络路径,用户在使用产品跳转到不同界面时,就会调用到不同的路径,这些路径对应着不同的资源/接口,那么这个路径就是"带层次的文件路径"。(类似在文件夹中找文件)
2 .在浏览器搜索内容时,输入想查询的内容,这些内容就作为"查询字符串"的值(value)传给服务器处理了。根据查询字符串的值,服务器返回相应的数据。如,搜索"衣服",就会返回关于衣服的数据。最贴切的就是在购物商城上买东西。
域名解释:www.baidu.com是域名 ,域名通过DNS(域名解析系统)绑定一个IP地址。(因为IP地址不好记,字母好记忆,域名就此诞生。)服务器地址直接写IP地址也可以,就像JDBC一样:jdbc:mysql://127.0.0.1:3306/java113?characterEncoding=utf8&allowPublicKeyRetrieval=true&useSSL=false
3.1.2 认识URL encode
URL encode是一种编码方式,你在搜索栏中输入内容,这些内容就会被编码成带%号的十六进制的值,拼接在url查询字符串上,如:
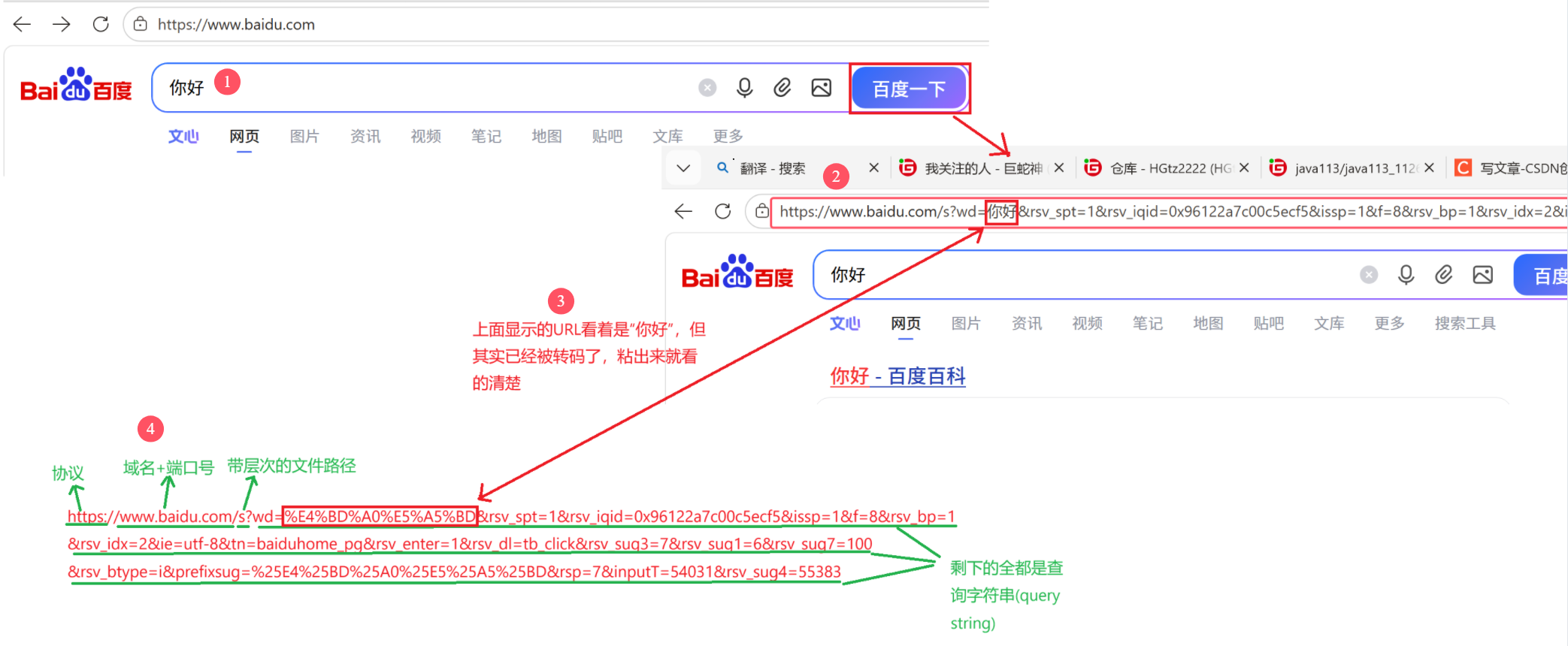
为什么要编码?因为URL格式中使用了许多符号分割区域,如"/、?、&、="。如果用户输入的值含有这些有特殊意义的字符,不转码直接将内容拼接到query string 上,那么系统是会出错的;如前面的已经出现了"?",表示带"层次的文件路径"结束,如果后又出现"?",难不成文件路径又来了?这时系统就乱套了。
URL encode工具:UrlEncode编码/UrlDecode解码 - 站长工具
3.2 认识"方法"
http请求报文需要方法进行发送。
方法有如下几种:
|----------|-------------|-----------------|
| 方法 | 说明 | 支持的HTTP协议版本 |
| GET | 获取资源 | 1.0、1.1 |
| POST | 传输实体主体 | 1.0、1.1 |
| PUT | 传输文件 | 1.0、1.1 |
| HEAD | 获得报文首部 | 1.0、1.1 |
| DELETE | 删除文件 | 1.0、1.1 |
| OPTIONS | 询问支持的方法 | 1.0 |
| TRACE | 追踪路径 | 1.0 |
| CONNECT | 要求用隧道协议连接代理 | 1.0 |
| LINK | 建立和资源之间的联系 | 1.0 |
| UNLINK | 断开连接关系 | 1.0 |
(解释:POST主要是传输一段数据,PUT是传输文件)
各位不要害怕,看着有10个方法,其实掌握GET和POST就行了,再往大了说 ,掌握1.**GET、2.POST、3.PUT和4.DELETE,**这四个方法就ok了。
有句话说得好:天下方法共十斗,get独占八斗,post占一斗,剩余方法共分一斗。
3.2.1 get
get发送请求特点:
- 首行的第一部分为 GET
- URL 的 query string 可以为空,也可以不为空
- header 部分有若干个键值对结构
- body 部分为空
get和post是最常见的http请求方法,使用fiddler随便抓一个http数据包就能看到,
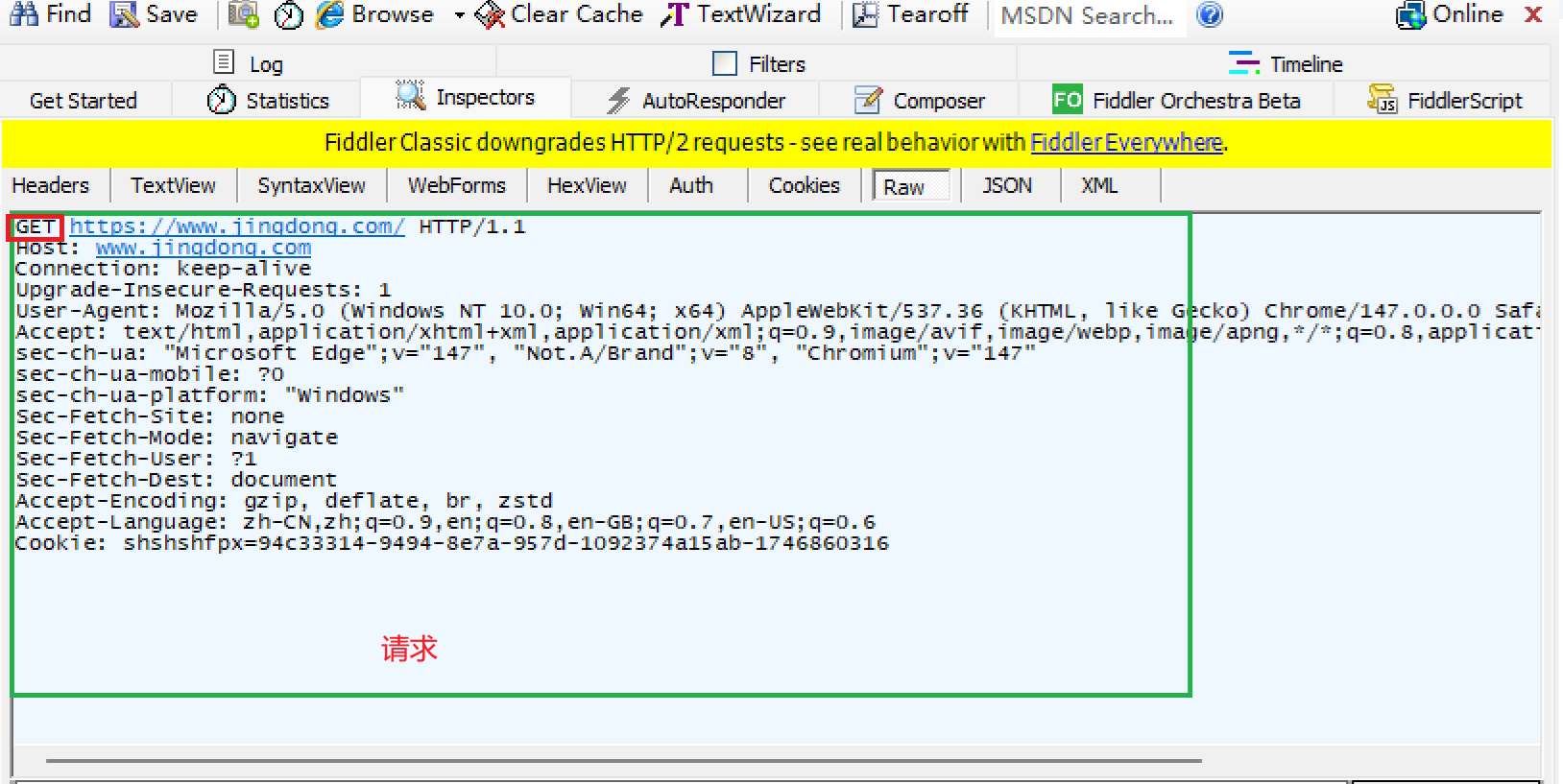
1.get http请求常用于获取资源。get http请求一般不带正文 (语法上可带正文,实际中很少有带正文的),所以请求携带的数据都拼接在查询字符串上,查询字符串过长会很难看,因此get请求大多只为了获取服务器响应。
2.拼接在查询字符串上就会导致url过长,虽然现在的浏览器没有规定url的长度,或规定了是一个非常大的长度范围,我们依然不建议使用get请求给服务端传输大量数据。
综合上面两点,get请求常用于向服务端发起不含正文的请求获取资源。例如,进行某页面跳转时,浏览器发送get请求给服务器,服务器就返回图片、视频、前端代码(HTML、CSS、Java script 代码等)等资源,这样下个页面内容就出来了。
补充:get方法是幂等的,所以浏览器会将get请求的数据缓存在本地,这样下次再次访问这个页面就不会再加载响应的某些数据(前端代码,图片等)。
如果需要重新加载响应数据,可以强制刷新(Ctrl + F5)。
3.2.2 post
post发送请求特点:
- 首行的第一部分为 POST
- URL 的 query string 一般为空(也可以不为空)
- header 部分有若干个键值对结构
- body 部分一般不为空。body 内的数据格式通过header中的 Content-Type 指定。body的长度由header中的 Content-Length 指定
先来了解post请求的应用场景,再详讲请求头(header)中,诸多键值对的含义。
get的应用场景是"用于获取资源"。post的应用场景是:
前端需要提供数据给服务端,就使用post请求。如,**进行登录时,我们的账号、密码就会作为正文内容发送给服务端。**不信你可以使用抓包工具看你登录发送的请求,看看是不是post请求:
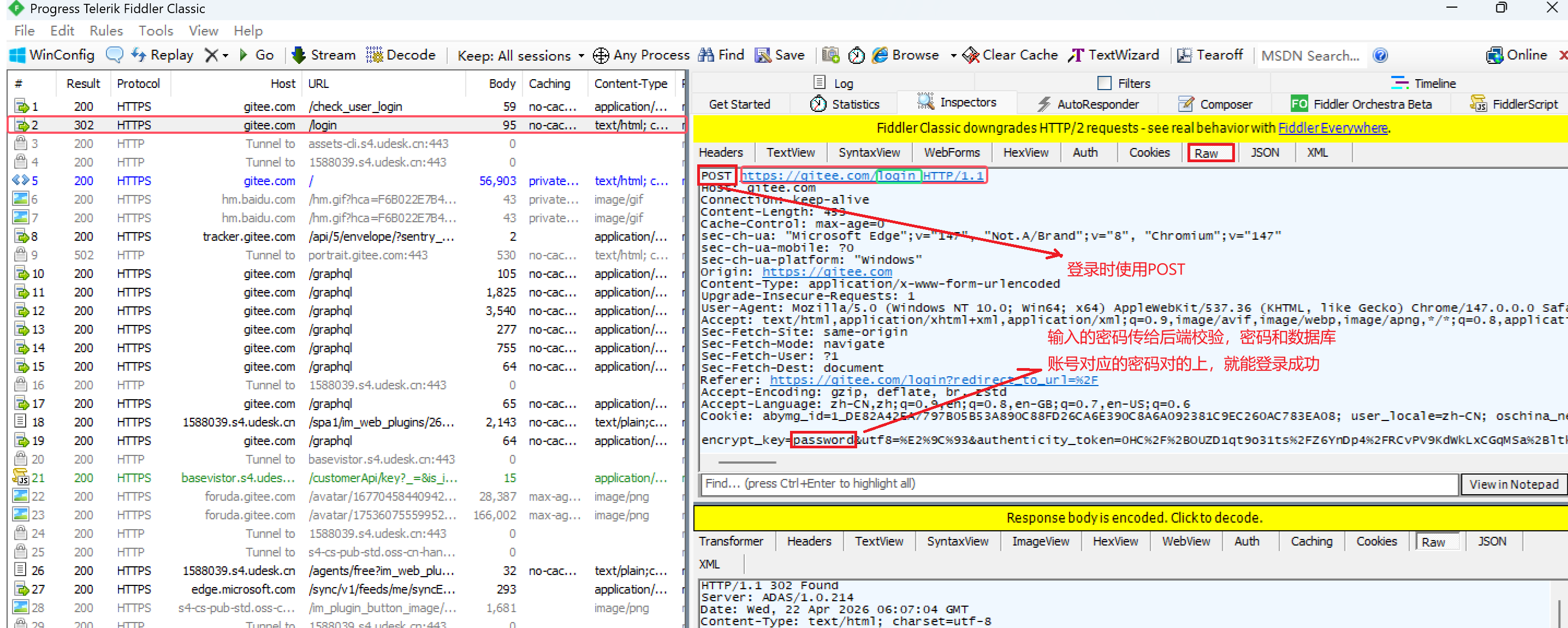
使用post发送含有数据的请求,是因为body(正文) 装载数据或看数据更方便,不像get一堆数据放在查询字符串上。
下面详讲header。
4. 请求的报头(header)
header整体格式是键值对。
4.1 Host
表示服务器主机的地址和端口。
4.2 Content-Length
表示 body 中的数据长度,单位字节。
get请求一般不含有。
4.3 Content-Type
表示请求的body中的数据格式。
get请求一般不含有。
常见数据格式:
application/x-www-form-urlencoded 是form 表单提交的数据格式。
multipart/form-data 也是from表单提交的数据格式(在from标签加上"enctyped="multipart/form-data".)通常用于提交图片/文件。
application/json 数据为json格式。
text/html 数据格式为HTML
application/json数据为json格式
详细格式类型:HTTP content-type | 菜鸟教程
关于Content-Type 详细情况:Media types (MIME types) - HTTP | MDN
4.4 User-Agent(简称UA)
表示发起请求的客户端的浏览器 和操作系统属性。如:
表格
User-Agent 中的标识 对应的操作系统 Windows NT 10.0 Windows 10 / Windows 11 Windows NT 6.3 Windows 8.1 Windows NT 6.2 Windows 8 Windows NT 6.1 Windows 7 Windows NT 6.0 Windows Vista Windows NT 5.1 Windows XP Windows NT 5.0 Windows 2000 User-Agent格式之所以是现在这样,完全是历史遗留问题;想了解这段故事的:zhuanlan.zhihu.com/p/398807396
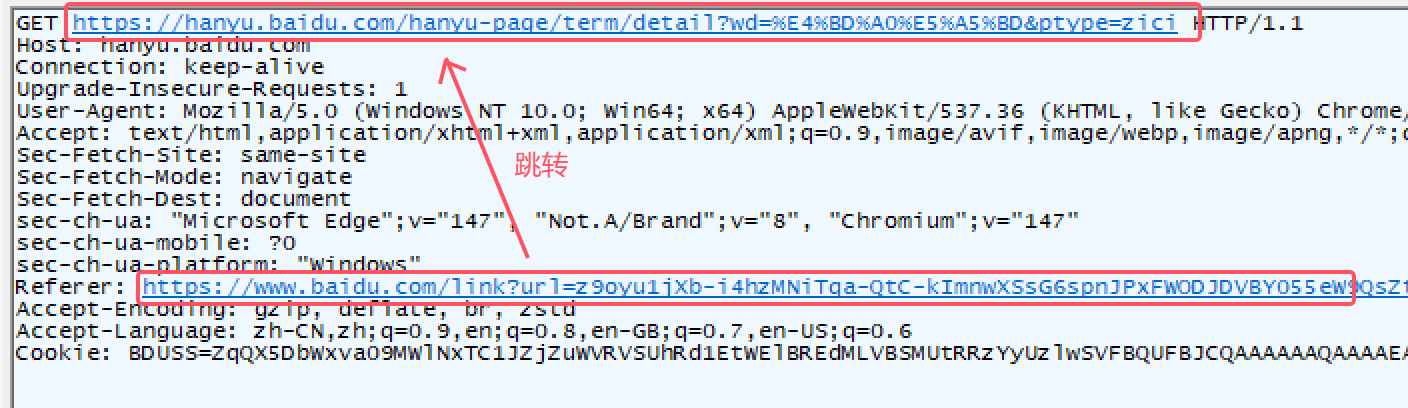
4.5 Referer
表示这个页面是从哪个页面跳转过来的。如:
注意:直接输入URL,或通过收藏夹访问页面是没有Referer的。
补充:
是否存在修改Referer导致页面跳转错误的操作?
这种情况在2014年非常普遍(以前网络数据包大多使用http传输),特别是运营商(移动、电信等)。我们知道,商家在广告平台投广告后,用户点击跳转广告多少次,商家就按点击次数给广告平台的相应钱。比如百度、搜狐等公司用户点击某个广告,请求广告的请求数据包,要经过运营商机器进行数据传输,这时运营商也有自己的广告平台呀,那么他就会把Referer修改了,自己赚钱。这就叫"运营商劫持"。
但,15年左右百度牵头,搜狐、360等互联网大厂联合推出了"HTTPS协议",HTTPS请求、响应数据包得到加密,问题迎刃而解!
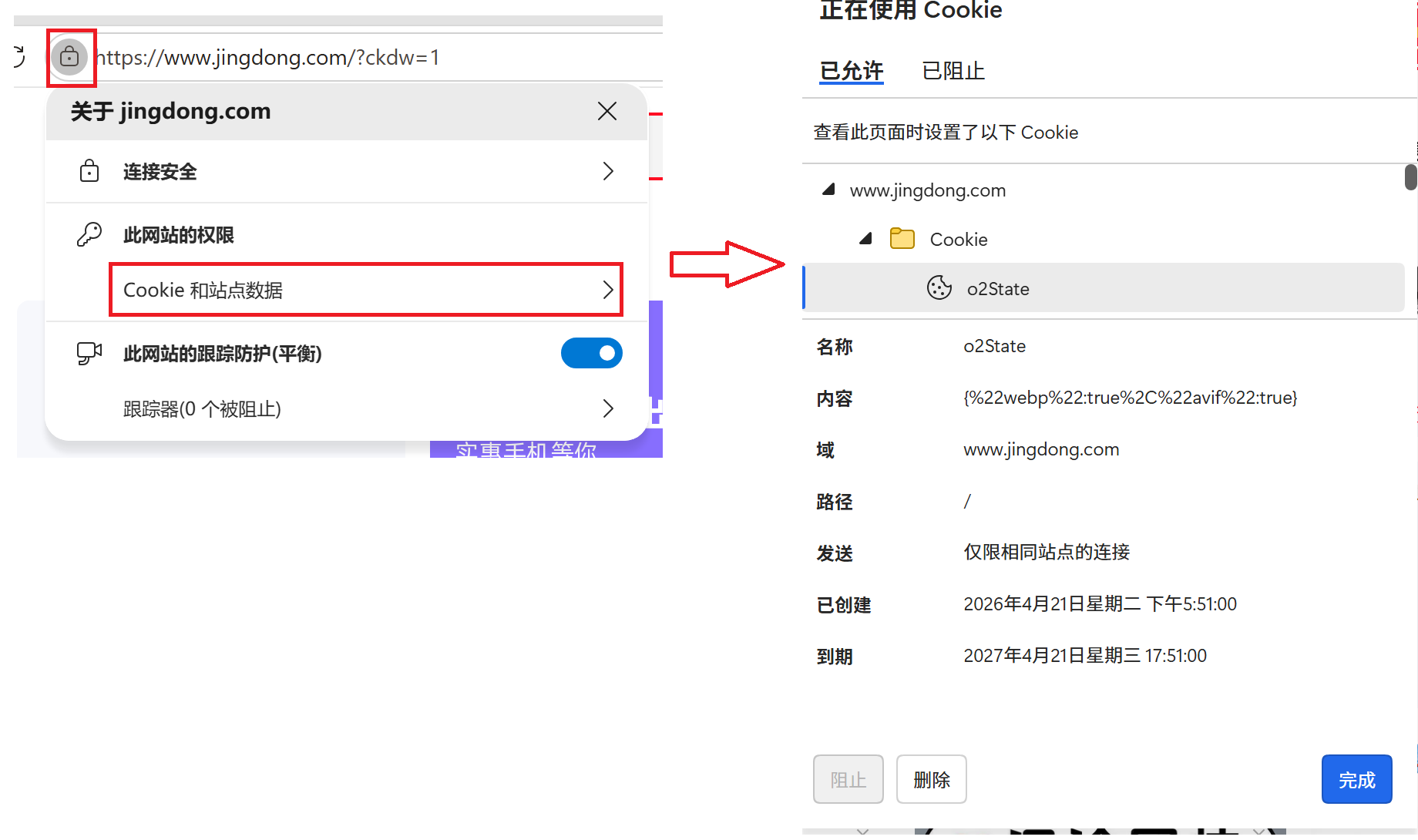
4.6 Cookie
- Cookie是浏览器提供给网页存放数据在本地硬盘的一种机制。(也就是一块能存储数据的内存空间)
- 使用键值对存储机制
Cookie由来:返回的网页包含js代码,为了防止别人瞎搞,使用js代码直接操控用户硬盘,就得隔绝网页和本地硬盘的交互,但实际开发中有时又希望把数据存放在本地硬盘,这时浏览器引入了Cookie机制;
Cookie不是让网页直接访问硬盘,而是做了一层抽象,使用键值对 的方式存储数据。
查看方式Cookie的方式有多种:
方式一:
方式二:
按F12打开开发者工具
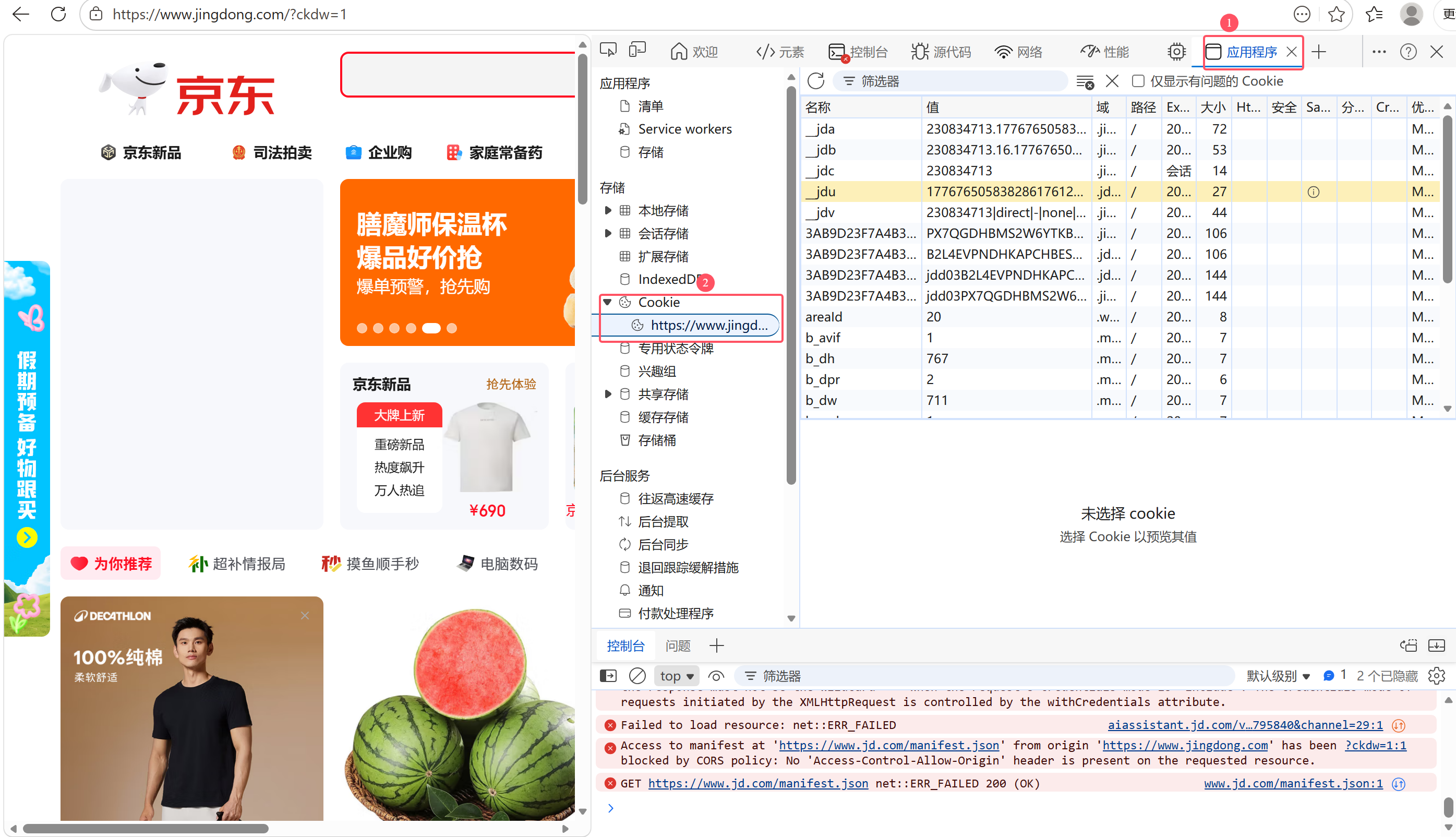
以京东网页为例,在主页面随意点击一个商品,使用fiddler抓包看到,不管是发送的请求,还是返回的响应中都有"Cookie 键值对"!
不知道你有没有想过,浏览器Cookie中存的键值对是怎么来的,这些键值对为什么在发送请求时要作为请求数据报数据发出?我来给你揭晓:
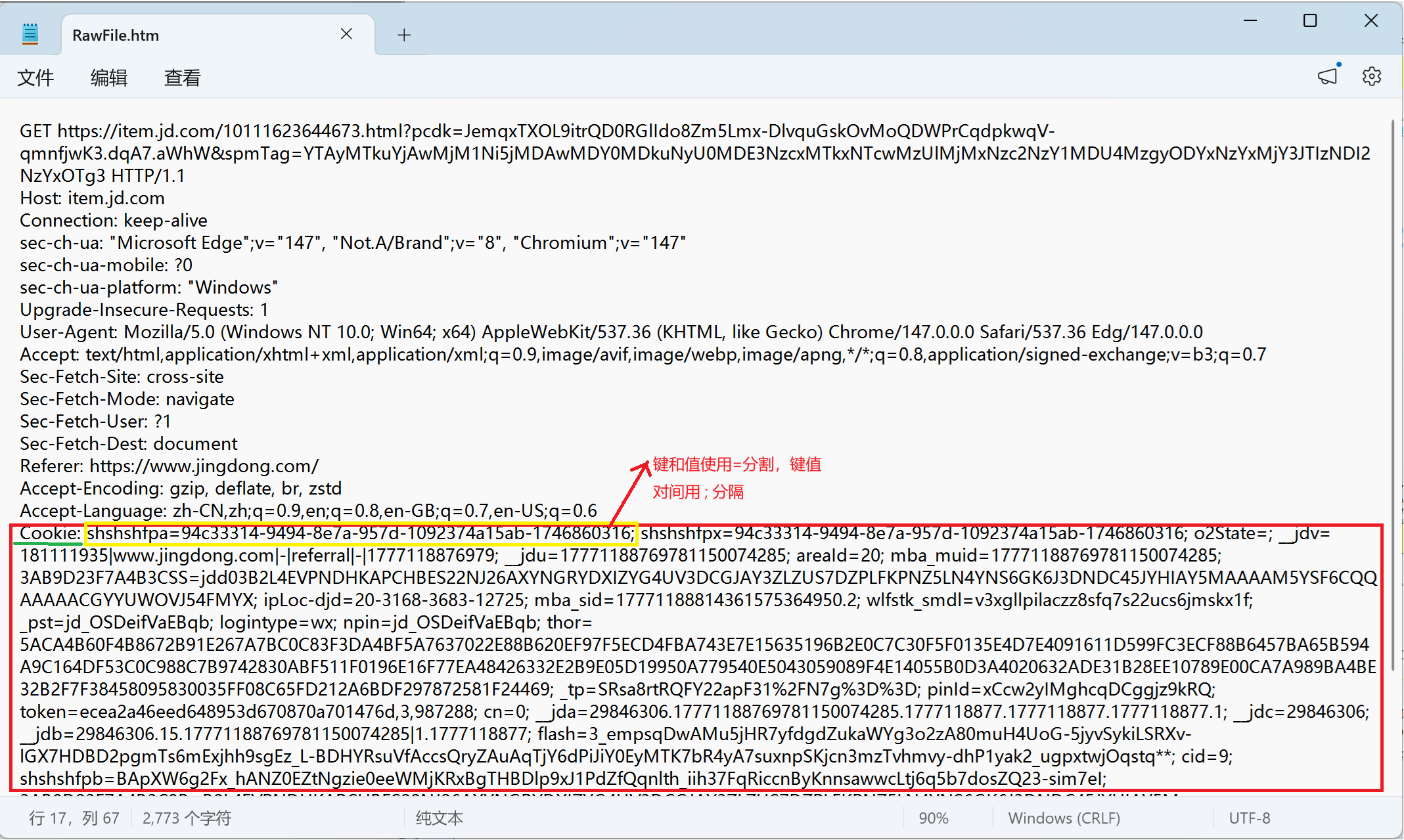
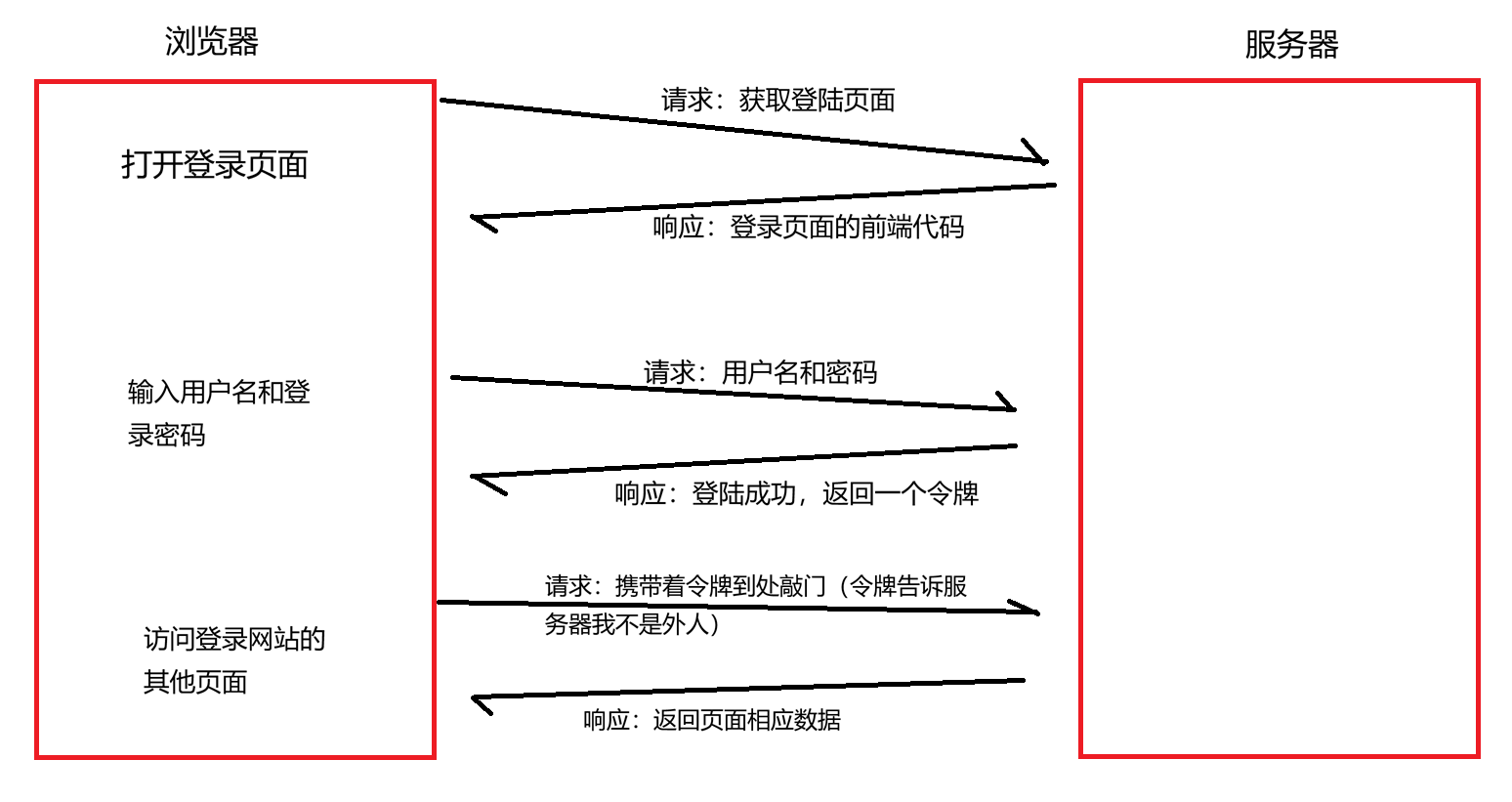
登录验证输入的用户名和密码,后端计算匹配后,会返回响应,响应中包含"Set-Cookie"键值对(值叫"令牌")。Cookie中存放的哪些值就是这些令牌,HTTP是无状态的,所以每次访问服务器都要携带令牌,告知我已经登录过了(令牌得在有效期内),否者访问网页时每次都要登录。
令牌存放在Set-Cookie 中的键值对中返回,例:
整个流程:
拓展:每个客户端在登录连接服务器时,服务器会给每个用户创建一个Session(会话) ,并在登录成功的响应中返回sessionId, 也就是存放在Set-Cookie返回的**令牌。**每个Session只有使用对应的SessionId才能获取。(令牌是一个广义的概念,泛指用于验证身份的凭证)
Session记录着本次连接产生的操作,就如某人申请去探监,他和犯人的这一次对话就会被记录下来,称为一次会话(Session)。

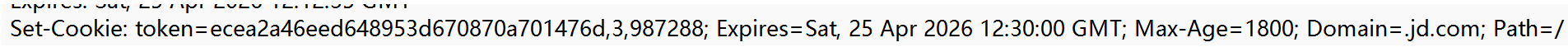
5. 请求的正文(body)
body数据格式与header的Content-Type密切相关。
body中的以json还是html或是其他数据传输,依赖Content-Type值的数据格式类型。例: