单例模式总结
单例模式是一种设计模式
实现方法
- 懒汉(早)
- 饿汉(迟)
区别
饿汉方法效率高
无论是饿汉还是懒汉都要将构造方法设为private
线程安全
- 加锁要把if和new都包含进去
- 双重if判定
- volatile禁止指令重排序,保证内容可见性
a)创建内存
b)构造对象
c)把内存地址赋给引用
阻塞队列
队列在后端开发,分布式系统,微服务架构应用广泛
阻塞队列其实就是一种更复杂的队列
- 线程安全
- 阻塞特性
a)队列为空, 尝试出队列, 出队列操作就会阻塞. 阻塞到其他线程添加元素为止.
b)队列为满, 尝试入队列, 入队列操作也会阻塞. 阻塞到其他线程取走元素为止.
阻塞队列一个最主要的应用场景就是实现"生产者消费者模型"
此处谈到的阻塞时"极端情况"生产者与消费者之间速度不协调的时候
生产者消费者模型
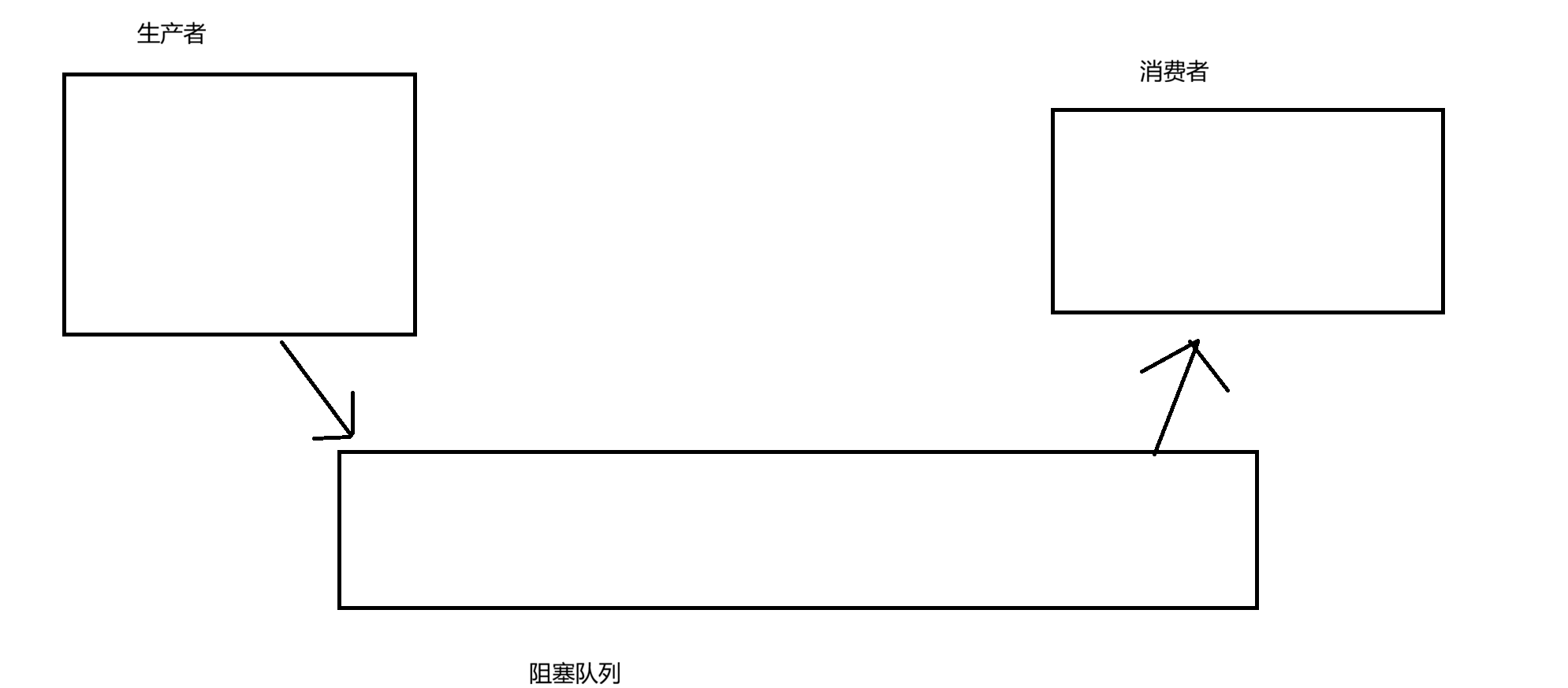
生产者不直接将数据传给消费者,而是通过中间的阻塞队列,因为当生产者传输的数据过多时,消
费者数据处理不过来会导致程序破溃,而通过阻塞队列可以有效防止这种情况。
生产者消费者模型两个重要的优势
1.解耦合(不一定是两个线程之间,也可以是两个服务器之间)
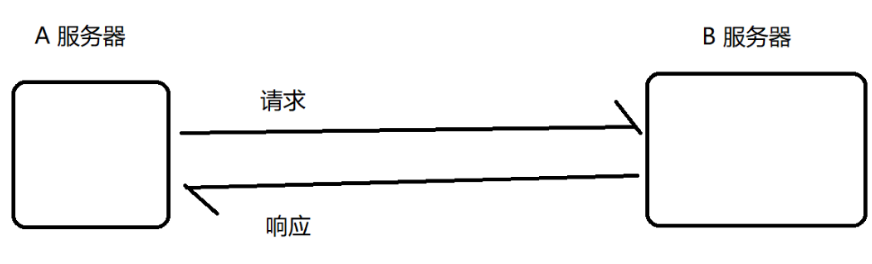
如果是A直接访问B,此时A和B的的耦合就很高
编写A代码的时候,多多少少会有一些和B相关的逻辑
编写B代码的时候,也会有一些A相关的逻辑
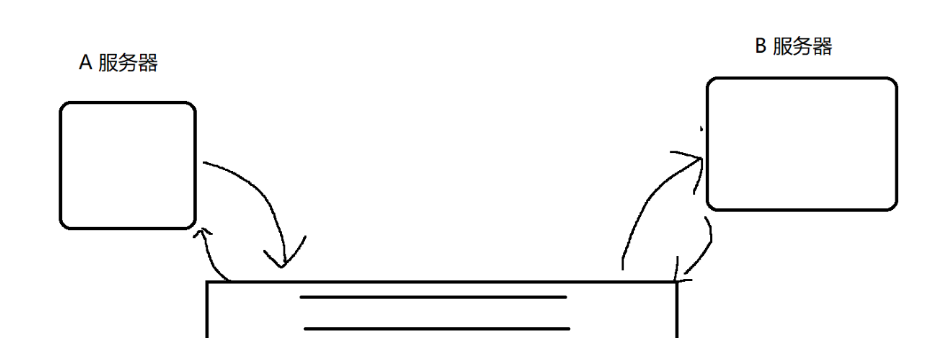
A 和 队列交互,B 和 队列交互,A 和 B 不再直接交互了
A 的代码中就看不见 B 了,B 的代码中也看不见 A 了
A 的代码中和 B 的代码中只能看到队列
2.削峰填谷
服务器收到的请求量的曲线图
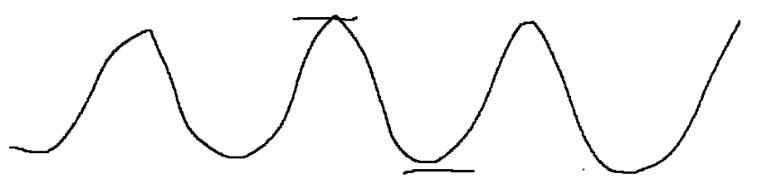
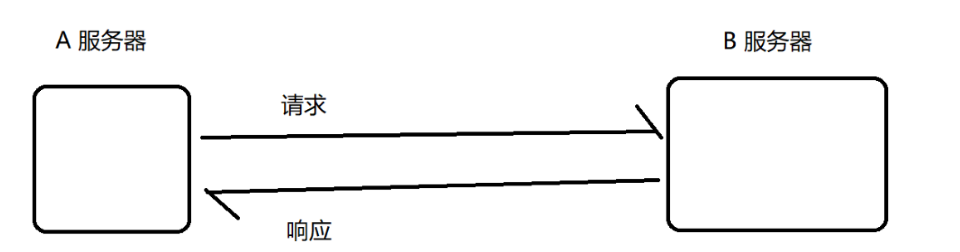
对于A和B这样的请求和响应服务器,A这边遇到一波流量激增此时每个请求都会转发给B,B也会
承担一样的压力,此时很容易把B给搞挂
一般来说 A 这种上游的服务器,尤其是 入口的服务器,干的活更简单,单个请求消耗的资源数少
像 B 这种下游的服务器,通常承担更重的任务量,复杂的计算/存储 工作,单个请求消耗的资源数
更多
日常工作中会给 B 这样角色的服务器分配更好的机器. 即使如此也很难保证 B 承担的访问量能够比
A 更高.
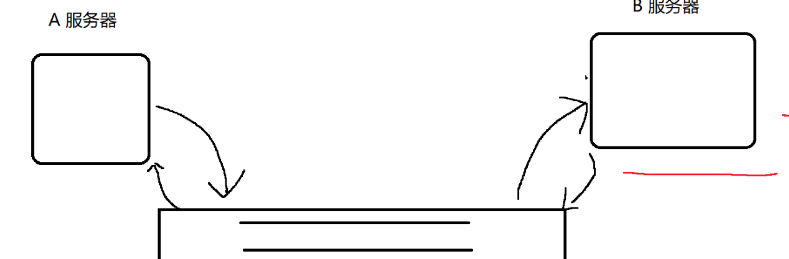
假设A突然收到一大波流量,A只要进行简单的传输,不需要去细化处理
队列服务器, 针对单个请求, 做的事情也少 (存储, 转发) 队列服务器往往是可以抗很高的请求量
B 这边可以不关心队列中的数据量多少 就按照自己的节奏,慢慢处理队列中的请求数据即可
趁着峰值过去了,B 仍然继续消费数据。 利用波谷的时间,来赶紧消费之前积压的数据
生产者与消费者模型的劣势
- 引入队列之后,整体的结构会更复杂. 此时,就需要更多的机器,进行部署. 生产环境的结构会更复杂. 管理起来更麻烦.
- 效率会有影响
模拟实现生产者消费者模型
java
public static void main(String[] args) {
BlockingDeque<Integer> qeque=new LinkedBlockingDeque<>(100);
Thread t1=new Thread(()->{
int n=0;
while(true){
try {
qeque.put(n);
System.out.println("生产元素: "+ n);
n++;
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
Thread t2=new Thread(()->{
while(true){
try {
int ret=qeque.take();
System.out.println("消费元素:"+ret);
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
t1.start();
t2.start();
}阻塞队列的实现
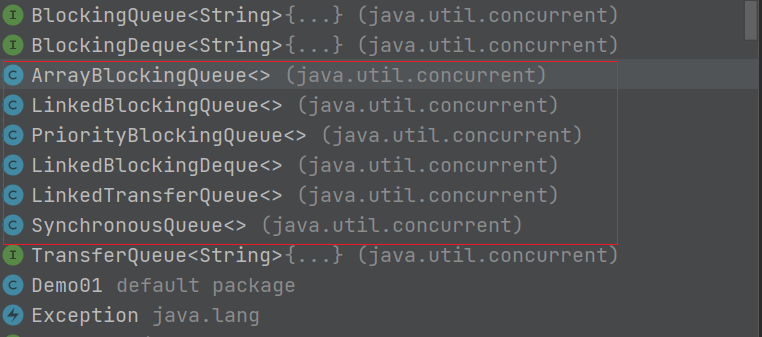
Java标准库中提供了现成的阻塞队列---BlockingQueue(阻塞队列)

通过接口实现阻塞队列,Java提供了多种类来实例化对象
java
public static void main(String[] args) throws InterruptedException {
BlockingQueue<String> queue=new ArrayBlockingQueue<>(100);
for (int i=0;i<100;i++){
queue.put("a");
}
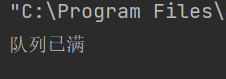
System.out.println("队列已满");
queue.put("a");
System.out.println("再次尝试put元素");
}入队列

出队列

offer和poll当然也可以使用,但是put和take才带有阻塞
java
public static void main(String[] args) throws InterruptedException {
BlockingQueue<String> queue=new ArrayBlockingQueue<>(100);
for (int i=0;i<100;i++){
queue.put("a");
}
System.out.println("队列已满");
queue.put("a");
System.out.println("再次尝试put元素");
}
超出容量范围,线程会停止下来

对于LinkedBlockingQueue来说,不加上capicity的取值范围,默认是一个非常大的数值
实际开发一般要求能够设置上你要求的最大值。否则你的队列可能变的非常大,导致把内存耗尽,
产生内存超出范围这样的异常
模拟实现一个阻塞队列
- 了解怎么使用
- 了解底层原理 => 注意事项,更高效,更稳定的使用。
- 能够模拟实现 => 有需要的时候,自行造一个 / 魔改一个出来。
java
class MyBlockingDuque{
private String[] data=null;
private int head=0;
private int tail=0;
private int size=0;
public MyBlockingDuque(int n){
data=new String[n];
}
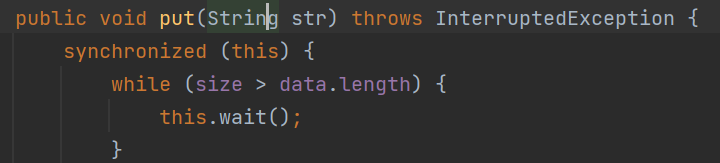
public void put(String str) throws InterruptedException {
synchronized (this) {
while (size > data.length) {
this.wait();
}
data[tail] = str;
tail++;
if (tail >= data.length) {
tail = 0;
}
size++;
this.notify();
}
}
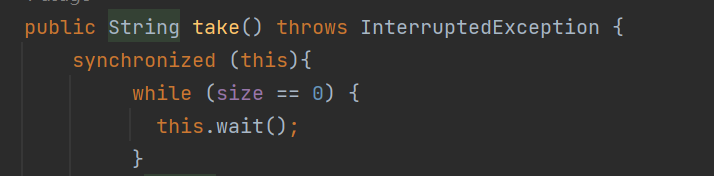
public String take() throws InterruptedException {
synchronized (this){
while (size == 0) {
this.wait();
}
String ret = data[head];
head++;
if (head >= data.length) {
head = 0;
}
size--;
this.notify();
return ret;
}
}
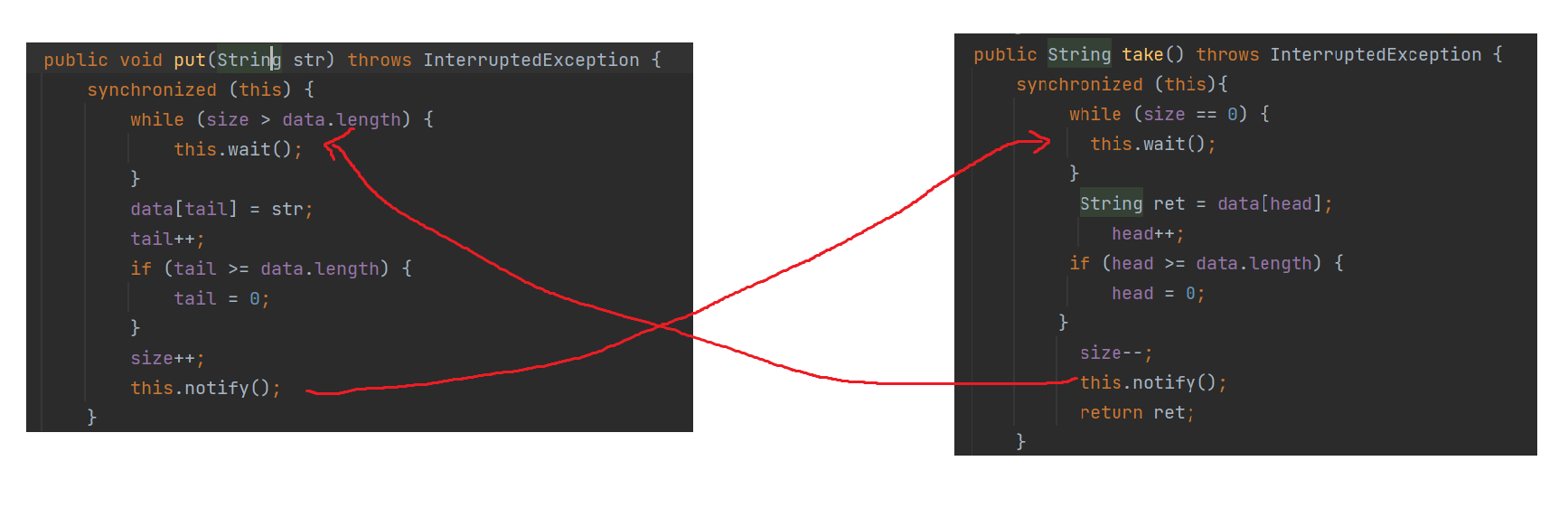
}
队列不满时才要唤醒,当其他线程执行成功take时,此时才会被唤醒
队列不空的时候,才要唤醒,当其他线程执行成功 put 的时,此时才会被唤醒
关于wait的关键环节
上述代码还有一个关键环节
1.此处要求wait要搭配while来进行使用
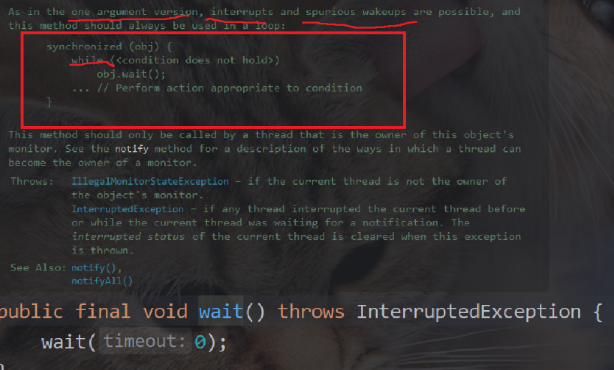

这里的wait是用来确保接下来的操作是有意义的
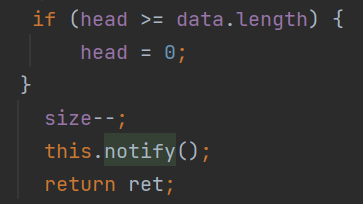
对于此处size是不会出现0情况,正常来说 wait 的唤醒是通过另一个线程执行 put 另一个线程 put
成功了, 此处的 size 肯定不是 0
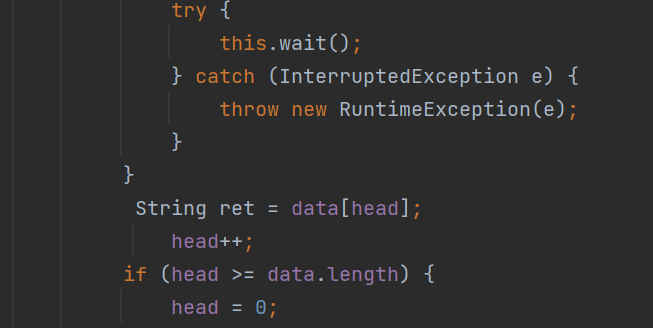
2.wait不一定是被notify唤醒的,还可能是被Interrupt这样的方法给中断
所以我们就在此处使用while循环

这里的循环的目的是为了"二次验证" 判定当前这里的条件是否成立.
wait 之前先判定一次 wait 唤醒也判定一次 (再确认一下, 队列是否不空)
线程池
线程池类似于常量池(字符串常量, 在 Java 程序最初构建的时候, 就已经准备好。等程序运行的时
候, 这样的常量也就加载到内存中了)
线程池的引入是为了解决频繁创建线程,让我们更高效的创建销毁进程
线程池时将线程提前创建好,放到一个地方(类似于数组),需要用的时候,随时去取,用完放回
池里
操作系统与线程池现成的区别
操作系统的线程
操作系统有用户态和内核态两种形态
内核态时操作系统的核心,可以理解为一个操作系统=内核+配套的应用程序
内核包含操作系统的各种核心功能
1)管理硬件设备
2)给软件提供稳定的运行环境
一个操作系统内核只有一份,给所有的应用程序提供服务支持
线程池的线程
线程里的线程是提前创建好的
二者区别
- 从线程池取现成的线程, 纯应用程序代码就可以完成. 可控、
- 从操作系统创建新线程, 就需要操作系统内核配合完成 不可控
- 使用线程池, 就可以省下应用程序切换到内核中运行这样的开销.
线程池的使用

核心方法---submit(Runnable)
通过 Runnable 描述一段要执行的任务
通过 submit 任务放到线程池中.
此时线程池里的线程就会执行这样的任务.
构造这个类的时候, 构造方法, 比较麻烦. (参数有点多)

对于ThreadPoolExecutor这个类有四种构造方法,我们可以通过了解最后一个(即次数最多的一
个)来理解所有的构造方法
int corePoolSize
核心线程数,至少有多少个线程,线程池一创建,,这些线程也要随之创建,直到整个线程池销毁,
这些线程才会销毁
int maximumPoolSize
最大线程数,最大线程数=核心线程 + 非核心线程(自适应),不繁忙就销毁,繁忙就再创建。
补充
- Java 的线程池, 里面包含几个线程, 是可以动态调整的.
- 任务多的时候, 自动扩容成更多的线程
- 任务少的时候, 把额外的线程干掉, 节省资源
long keepAliveTime
非核心线程允许空闲的最大时间
TimeUnit unit
枚举
BlockingQueue<> workQueue
工作队列,选择使用数组/链表,指定capacity,指定是否要带有优先级/比较规则
线程池, 本质上也是 生产者消费者模型,调用 submit 就是在生产任务,线程池里的线程就是在消
费任务
ThreadFactory threadFactory
工厂模式 (也是一种设计模式, 和单例模式是并列的关系,用来统一构造并且初始化线程),用来弥
补构造方法的缺陷的,给线程类提供的工厂类,线程中有一些属性可以设置,线程池是一组线程
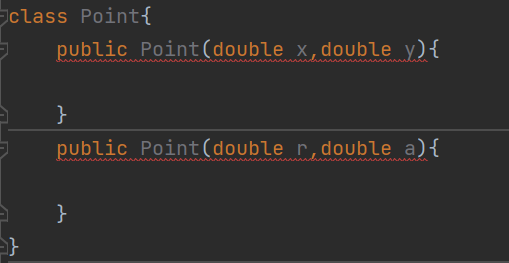
构造方法的名字是固定的,要想提供不同的版本,就需要通过重载,有时候不一定能构成重载.
工厂方法的核心, 通过静态方法, 把构造对象 new 的过程,各种属性初始化的过程, 封装起来了.
提供多组静态方法, 实现不同情况的构造.
工厂方法的模拟实现
提供工厂方法的类就叫做工厂类
java
class PointFactory{
public static PointFactory makeFactoryXY(double x,double y){
PointFactory pointFactory=new PointFactory();
return pointFactory;
}
public static PointFactory makeFactoryRA(double r,double a){
PointFactory pointFactory=new PointFactory();
return pointFactory;
}
}工厂方法

RejectedExecutionHandler handler
拒绝策略,整个线程池七个参数中, 最重要, 最复杂的。
submit 把任务添加到任务队列中,任务队列是阻塞队列。队列满了,再添加,阻塞,一般不希望
程序阻塞太多。
对于线程池来说,发现入队列操作时,队列满了,不会真的触发"入队列操作",不会真阻塞而是执
行拒绝策略相关的代码
添加拒绝策略的原因
如果调用 submit 就阻塞(业务逻辑中的线程调用 submit),就会使这个线程就没法干别的事情了,
不是一个好的选择.
这个线程要响应用户的请求,如果阻塞了, 用户迟迟拿不到请求的响应, 用户等很久直观上看到的
现象"卡了",与其是 "卡了" 不如直接告诉我 "失败"
拒绝策略的四种形式

线程池的实际使用
Java 标准库提供了另一组类, 针对 ThreadPoolExecutor 进行了进一步封装, 简化线程池的使用.
也是基于工厂设计模式
java
public static void main(String[] args) {
ExecutorService executorService2= Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
int id=i;
executorService2.submit(()->{
System.out.println("hello"+id+","+Thread.currentThread().getName());
});
}
}对于上面一个使用线程池的方法,创建线程池的部分有两种方法
Executors.newFixedThreadPool
指定线程池中的线程数量

这种情况,核心线程数和最大线程数一样,同时已经将线程池中的线程总数两进行了规定
Executors.newCachedThreadPool
使用默认线程池
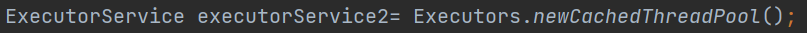
最大线程数是一个很大的数字(线程可以无数增加)