我:就是模型先思考要做什么,然后调用工具,再根据工具返回结果继续思考,这样循环下去。
面试官:Think、Action、Observation 三步在系统里具体怎么实现的?消息格式是什么结构?
我:(有点紧张)消息格式的话,就是用 system prompt 告诉模型要按特定格式输出,然后模型生成工具调用,系统执行后返回结果。
面试官:具体的标签格式呢?<think> 标签、<tool_call> 标签、<tool_response> 标签分别是什么结构?tool_response 用 user 角色还是 assistant 角色传回给模型?为什么这么设计?
我:(卡住了)这个,具体的格式细节我没记清楚。
面试官:(摇头)你只是知道 ReAct 叫什么,但不知道它怎么实现的。这道题很多人都答不上来,但它是 Agent 开发的基础。回去好好看看工程实现细节。
好,今天就把这个问题从原理到代码全部拆开讲。
简要回答
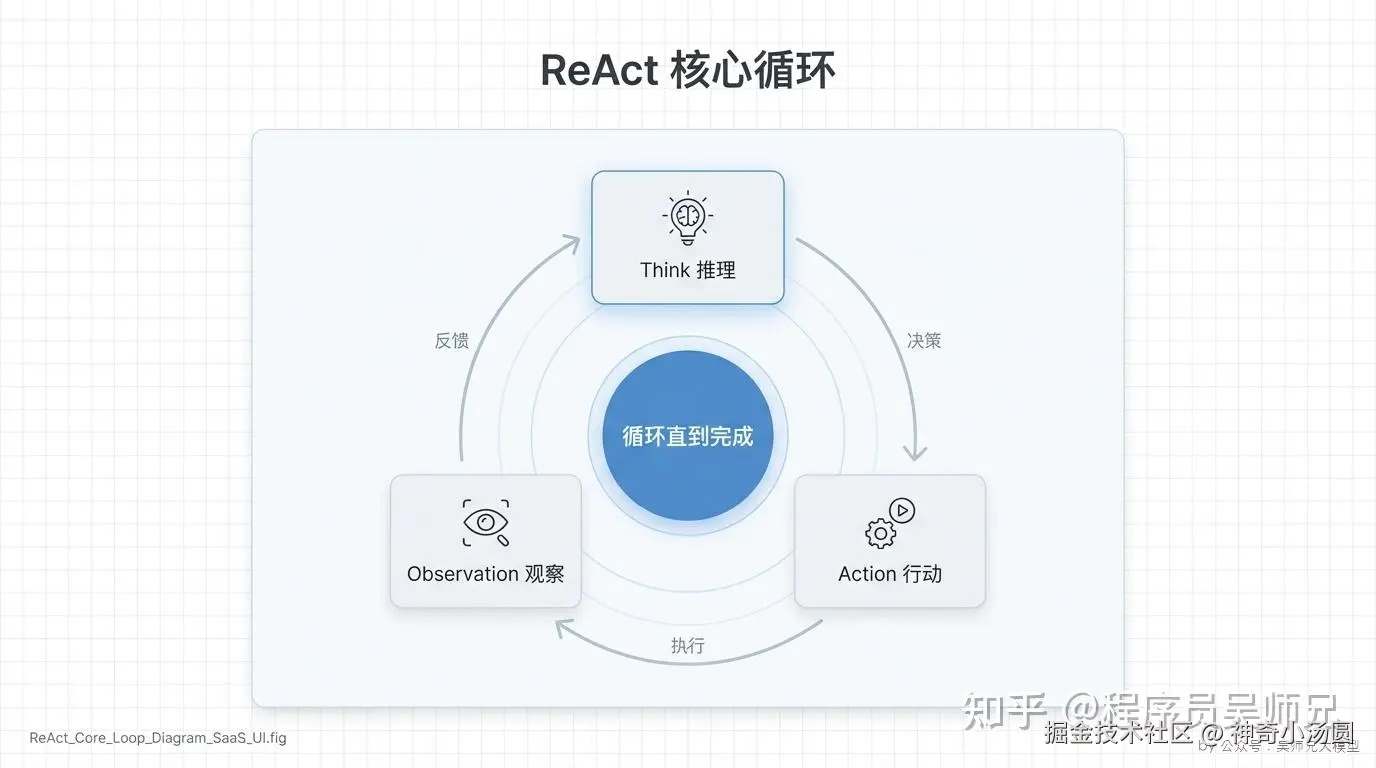
ReAct 框架的核心是 Reasoning(推理)+ Acting(行动)的循环,让大模型在执行任务时不是一步到位,而是"边想边做"。先推理(Think)下一步该做什么,然后调用工具执行(Action),再根据工具返回的结果(Observation)继续推理,形成一个循环,直到任务完成。
工程实现上,ReAct 用一套标签体系来结构化这个循环:<think> 包裹推理过程,<tool_call> 包裹工具调用参数,<tool_response> 包裹工具返回结果,<answer> 包裹最终答案。关键设计:tool_response 必须用 user 角色传回,因为它是外部世界的反馈,不是模型自己生成的内容。
说白了,ReAct 就是把"人类解决复杂问题的思考过程"显式化了。你不会一口气把答案说出来,而是先想想、查查资料、再想想、再查查,ReAct 让大模型也这么干。
ReAct 到底解决了什么问题?
在 ReAct 出现之前,大模型做任务有两种模式。
第一种是 Chain-of-Thought(CoT,思维链),让模型在回答前先"想一想",把推理过程写出来,最后给出答案。问题是:模型只能基于自己的参数知识推理,遇到需要实时信息的问题(比如"今天北京天气怎么样")就歇菜了。
第二种是 Tool Use(工具调用),让模型直接调用外部工具(搜索引擎、计算器、数据库),拿到结果后生成答案。问题是:模型不知道为什么要调这个工具、调完之后该干什么,缺少"推理"这一环。
ReAct 把两者结合起来:推理(Reasoning)告诉模型"为什么要这么做",行动(Acting)让模型"真的去做",观察(Observation)让模型"看到做的结果",然后继续推理。这个循环可以重复多次,直到任务完成。
类比一下:你要做一道菜,CoT 是"在脑子里想怎么做",Tool Use 是"直接动手炒",ReAct 是"边想边做"。先想"需要什么食材",然后去冰箱找(Action),发现没有葱(Observation),再想"那就去楼下超市买"(Think),买回来继续做(Action)。

ReAct 的完整消息格式(工程实现)
这是面试官真正要考察的,你能不能把 ReAct 的消息结构说清楚。很多人只知道"Think-Action-Observation"这三个词,但不知道在代码里怎么实现。
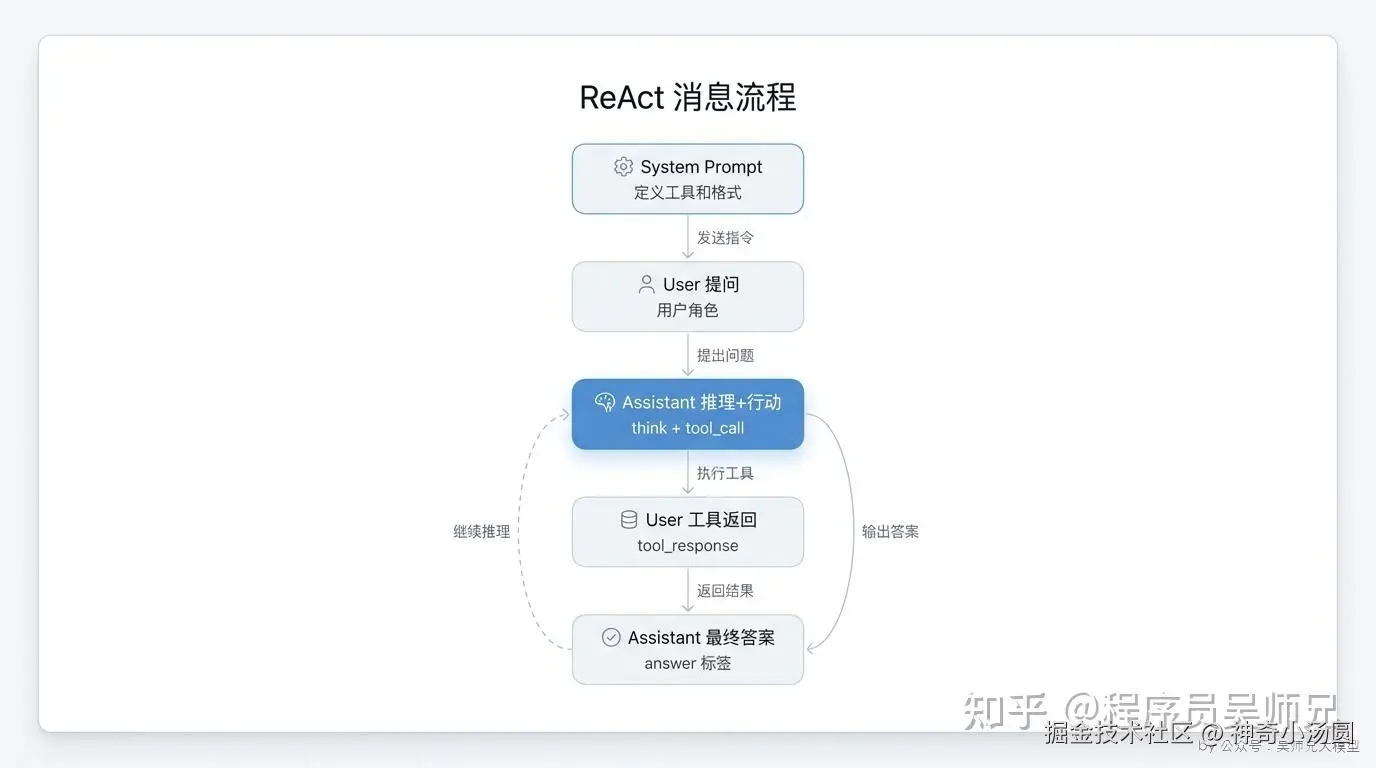
完整的 ReAct 消息流程分为六步。
第一步:系统提示词(system prompt)。定义可用工具列表(工具名、参数、说明),定义输出格式规范(标签体系),定义推理指引(先 think 再 act)。
第二步:用户提问(user 角色)。比如"2024年全球前五大电动车制造商中,哪些公司在研发固态电池?"
第三步:模型第一次推理和行动(assistant 角色)。模型输出 <think> 标签包裹的推理内容:"这个问题需要两步:先确定2024年全球前五大电动车制造商是哪些,再分别查询它们的固态电池研发情况。先搜索前五大制造商。"然后输出 <tool_call> 标签包裹的 JSON 格式工具调用:{"name": "search", "arguments": {"query": "2024年全球前五大电动车制造商排名"}}。
第四步:工具返回结果(user 角色)。系统执行搜索后,用 <tool_response> 标签包裹返回内容:"搜索结果:1. 特斯拉 2024年销量180万辆 2. 比亚迪 2024年销量300万辆 3. 大众集团 2024年销量120万辆 4. 通用汽车 2024年销量90万辆 5. 现代起亚 2024年销量85万辆"。
第五步:模型继续推理和行动(assistant 角色)。模型看到搜索结果后,继续输出 <think>:"已经确定了前五大制造商。现在需要分别搜索这些公司的固态电池研发情况。先搜索特斯拉。"然后输出新的 <tool_call>。
第六步:循环执行,直到模型输出 <answer> 标签包裹的最终答案。
为什么 tool_response 必须用 user 角色?
这是一个很多人搞混的设计细节。
错误理解:tool_response 是模型生成流程的一部分,应该用 assistant 角色。
正确理解:tool_response 的内容不是模型生成的,是外部工具(搜索引擎、数据库、API)返回的。把它放在 user 角色下,在语义上表示"外部世界的信息反馈给模型",让模型清楚区分"自己生成的内容"和"外部工具返回的内容"。
类比一下:你在跟朋友聊天(assistant),朋友让你去查个资料,你去百度搜了一下(Action),百度返回的结果(tool_response)不是你说的话,而是"外部世界"(user)告诉你的信息,你再基于这个信息继续跟朋友聊(assistant)。
如果把 tool_response 也放在 assistant 角色下,模型在训练时会学到"我应该预测搜索引擎会返回什么内容",而不是"我应该在什么时候调用什么工具、用什么参数"。这是 Agent 训练和普通 LLM 训练最大的区别之一。

ReAct 的三个核心优势
第一个优势:可解释性强。每一步推理过程都在 <think> 标签里,你能看到模型为什么要调这个工具、为什么要这么搜索。传统的黑盒模型你只能看到最终答案,ReAct 让整个思考过程透明化。
第二个优势:容错能力强。如果某一步工具调用失败(比如搜索没结果、API 超时),模型可以在下一轮 Think 中调整策略,换个关键词重新搜、换个工具、或者承认"这个信息查不到"。传统的单次调用模式遇到失败就直接挂了。
第三个优势:支持复杂任务。对于需要多步推理的任务(比如"对比A和B的优缺点"),ReAct 可以先搜A、再搜B、再对比,每一步都有明确的目标。传统模式要么一次性把所有信息塞给模型(上下文爆炸),要么只能做简单的单步任务。
对比总结
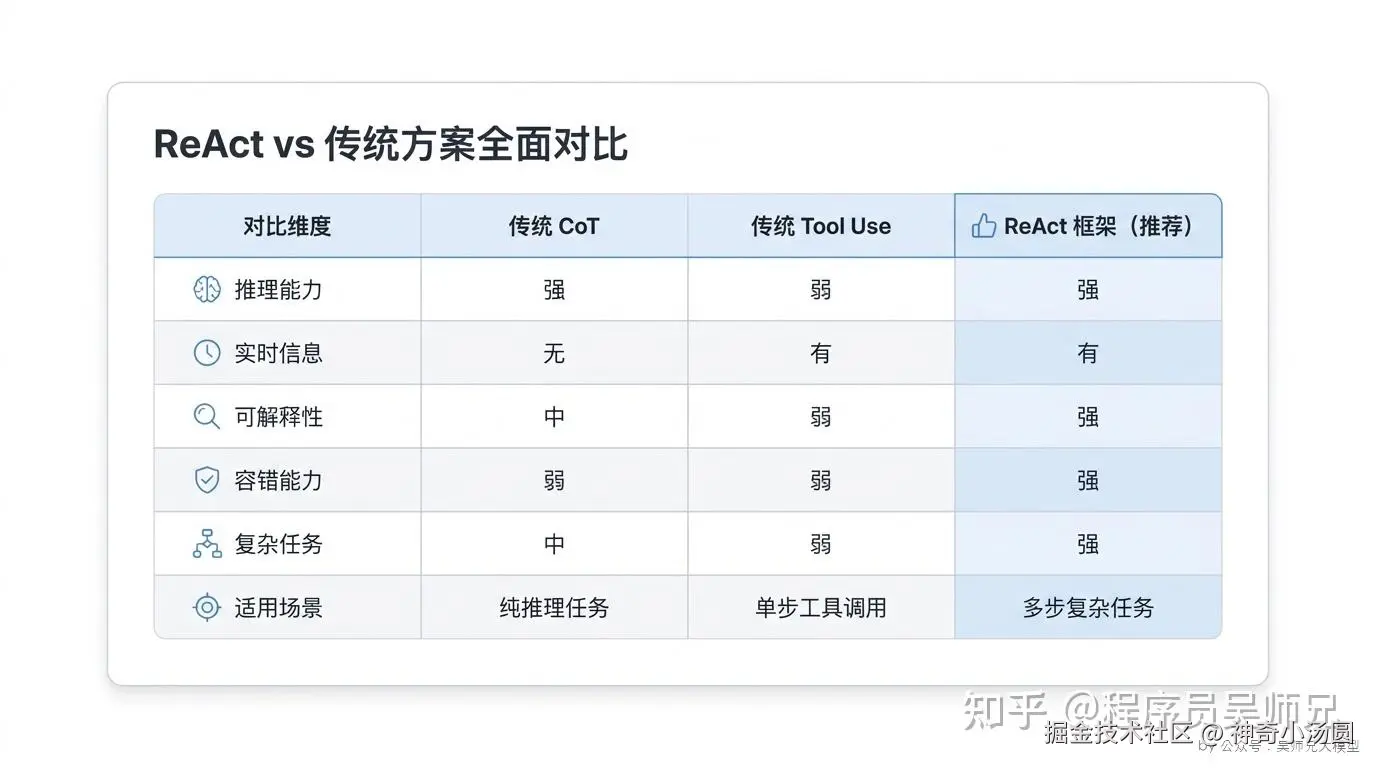
| 对比维度 | 传统 CoT | 传统 Tool Use | ReAct 框架 |
|---|---|---|---|
| 推理能力 | 强 | 弱 | 强 |
| 实时信息 | 无 | 有 | 有 |
| 可解释性 | 中 | 弱 | 强 |
| 容错能力 | 弱 | 弱 | 强 |
| 复杂任务 | 中 | 弱 | 强 |
| 适用场景 | 纯推理任务 | 单步工具调用 | 多步复杂任务 |
面试总结
回到开头的面试场景,如果面试官问"ReAct 框架的核心循环是什么?消息格式怎么设计?",满分回答的结构是:
第一步(20秒):讲清楚 ReAct 的核心思想。ReAct 是 Reasoning + Acting 的缩写,核心是让大模型在执行任务时"边想边做",先推理(Think)下一步该做什么,然后调用工具执行(Action),再根据工具返回的结果(Observation)继续推理,形成一个循环,直到任务完成。
第二步(40秒):讲清楚消息格式的完整结构。工程实现上,ReAct 用一套标签体系来结构化这个循环:<think> 标签包裹模型的推理过程,<tool_call> 标签包裹工具调用参数(JSON 格式),<tool_response> 标签包裹工具返回结果,<answer> 标签包裹最终答案。关键设计:tool_response 必须用 user 角色传回给模型,因为它是外部世界的反馈,不是模型自己生成的内容。这样模型在训练时才能学到"在什么时候调用什么工具",而不是"预测工具会返回什么"。
第三步(20秒):类比加深理解。类比做菜:CoT 是"在脑子里想怎么做",Tool Use 是"直接动手炒",ReAct 是"边想边做",先想需要什么食材,去冰箱找(Action),发现没有葱(Observation),再想去超市买(Think),买回来继续做(Action)。
第四步(20秒):补充 ReAct 的核心优势。ReAct 的三个核心优势:可解释性强(每一步推理都可见)、容错能力强(某一步失败可以调整策略)、支持复杂任务(多步推理,每步有明确目标)。
很多人准备 Agent 面试时,只背了"ReAct 是 Reasoning + Acting"这个概念,但面试官真正要考察的是:你能不能把 ReAct 的消息格式、角色设计、循环逻辑说清楚。这道题的区分度很高,答不上来说明你只是看过教程,答得上来说明你真的写过代码、跑通过完整流程。如果你简历上写了"用 ReAct 框架做了 XX 项目",那这道题就是送分题。如果答不上来,面试官会直接判定你的项目经历有水分。