目录
[1 CPU:通用计算的大脑](#1 CPU:通用计算的大脑)
[1.1 CPU 介绍](#1.1 CPU 介绍)
[1.2 提升CPU利用率](#1.2 提升CPU利用率)
[(1) 什么是CPU利用率](#(1) 什么是CPU利用率)
[(2) CPU利用率低的原因](#(2) CPU利用率低的原因)
[(3) 提升CPU利用率的方法](#(3) 提升CPU利用率的方法)
[2 GPU:并行计算的工厂](#2 GPU:并行计算的工厂)
[(1) GPU利用率低的原因分析](#(1) GPU利用率低的原因分析)
[(2) 提升GPU利用率的主要方案](#(2) 提升GPU利用率的主要方案)
[CPU V.S GPU](#CPU V.S GPU)
前言
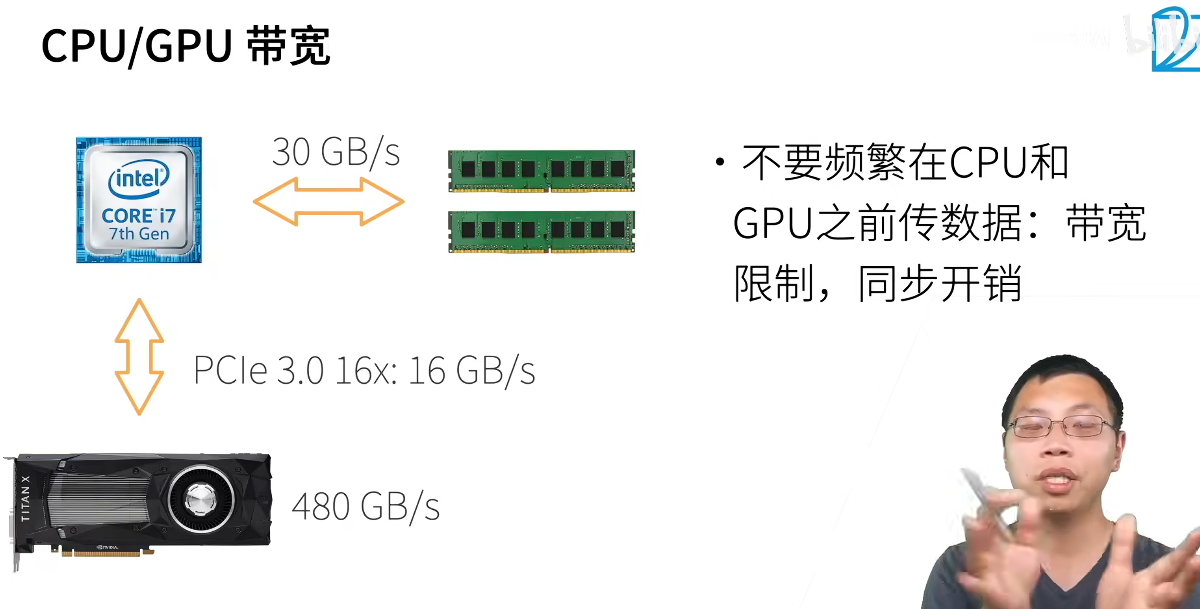
CPU从硬盘读取数据到内存,并经过预处理,将处理好的数据通过PCle总线"喂"给GPU。
// 下图是一个(i7 + Titan X + 32GB RAM)是在深度学习中的"高性能工作站"入门配置示例:

在深度学习领域,CPU 和 GPU 的关系常被比喻为"大学教授 "与"成千上万的小学生"。虽然教授逻辑极其严密,但在处理极其简单却数量庞大的重复任务时,速度远不及人多势众的小学生。
1 CPU:通用计算的大脑
1.1 CPU 介绍
CPU(Central Processing Unit)设计初衷是处理复杂的逻辑控制和串行任务。
**架构特点:**核心数量少(通常8-64核),但每个核心的主频很高,拥有复杂的分支预测和多级缓存(L1/L2/L3 Cache)。
擅长:CPU擅长处理复杂的逻辑分支(if-else)嵌套、串行指令流执行及操作系统调度和输入输出(I/O)管理等。
在深度学习中,CPU主要用于数据预处理------在训练前读取磁盘图像,进行随机裁剪、翻转等变换(通常由 PyTorch 的 DataLoader 调用 CPU多线程完成),以及进行某些非端到端的传统算法或极小规模的推理。
下图是一个4核CPU示例: Intel Core i7-6700K 处理器
中间绿色区域是"共享三级缓存"(Shared Last-Level Cache,LLC),即L3。它的作用是作为CPU核心与主存之间告诉数据缓冲区,4个核心可共同访问这块缓存,极大减少了访问内存的延迟。

1.2 提升CPU利用率
(1) 什么是CPU利用率
CPU在单位时间内用于执行有效计算任务的时间比例:举个例子,CPU忙7秒,空闲3秒,利用率为70%。
(2) CPU利用率低的原因
- I/O等待时间过多:CPU处理任务的时间远小于要处理的任务/数据加载到内存的时间,表现为CPU等磁盘、等网络、等数据等,从而造成CPU经常空闲。
- 程序没有并行执行:单线程程序只有一个CPU核心在工作,其余核心闲着。
- 算法效率低:算法本身的计算复杂度过高,或者访存效率低等。
- 资源配置不合理:比如CPU很多而线程很少从而导致资源浪费。
//案例1:下面是一个由算法设计引起的访存延时的问题。
CPU是按照块读取数据的,因此我们设计的访存方式应该尽可能让CPU较少的次数可以读到尽可能多的要用的数据。在样例分析中,访问一行可以连续读到要用的多个数据,而按列的话读到要用的数据比较少,因此效率低下。
|----------------------------------------------------------------------------|----------------------------------------------------------------------------|
|  |
|  |
|
//案例2:下面是一个并行计算引起的CPU利用率低下问题。
分析:
- 左边代码:① python是解释型语言,在for循环中,解释器需要逐行读取代码然后执行,而每执行一次循环都要重复这个过程;② 要进行n次:访问元素、执行家法、赋值等,每次调用都有开销。③ 并且python不知道ai、bi具体是什么类型,每次循环时它都必须停下来检查数据类型,确定该调用哪种加法逻辑,这种"运行时检查"减慢了速度。④每次通过
a[i]取值,由于 Python 列表存储的是对象的指针,数据在内存中可能并不是连续存放的。CPU 经常要停下来去不同的内存地址"跳跃式"找数,导致缓存命中率极低。
循环100万次,这套繁琐的检查就要做100万次。
- 右边代码:① 这是一个"向量化"操作,它只在最开始检查一次类型,然后直接执行底层已经编译好的C语言或者Fortan函数进行"批量处理"。NumPy 等库在内存中开辟的是一块连续的二进制空间。CPU 读第一个数时,顺便就把后面一串数字都带进了高速缓存。这种"按序预取"让 CPU 几乎不需要等待。
|----------------------------------------------------------------------------|----------------------------------------------------------------------------|
|  |
|  |
|
(3) 提升CPU利用率的方法
① 使用多线程:并发执行,同时做多件事情,适用于I/O密集型任务。
② 使用多进程:适用于CPU密集型任务,让多个CPU同时工作。
③ 减少I/O等待:做数据缓存以避免重复读取磁盘;做批量读取以提升效率;
④ 优化算法(根本策略)
⑤ 使用异步编程:适用于大量 I/O 任务,CPU不等待 I/O 去执行其他任务。
⑥ 系统方面:合理设置线程数(线程数=CPU核心数)、减少上下文切换等
2 GPU:并行计算的工厂
GPU(Graphics Processing Unit)最初为图形渲染设计,现在已成为深度学习的标配,特别是带有 Tensor Core(张量核心)的现代显卡。
架构特点:核心数量极多(数千个 CUDA Core),虽然单个核心的逻辑处理能力弱,但它们可以同时执行相同的数学运算。
擅长:
- 深度学习的本质是大量的矩阵乘法和加法(
),这可以拆解成数百万个独立的乘加运算并行执行,而这正是GPU所擅长的。
- 另外,GPU拥有极高的显存带宽(如 H100 或 RTX 4090 使用的 GDDR6X),能快速吞吐海量张量数据,为深度学习高计算需求提供支撑。
在深度学习的模型训练过程中,GPU承担99%以上的梯度计算、反向传播和参数更新任务,并能够在高并发场景下快速完成模型预测。
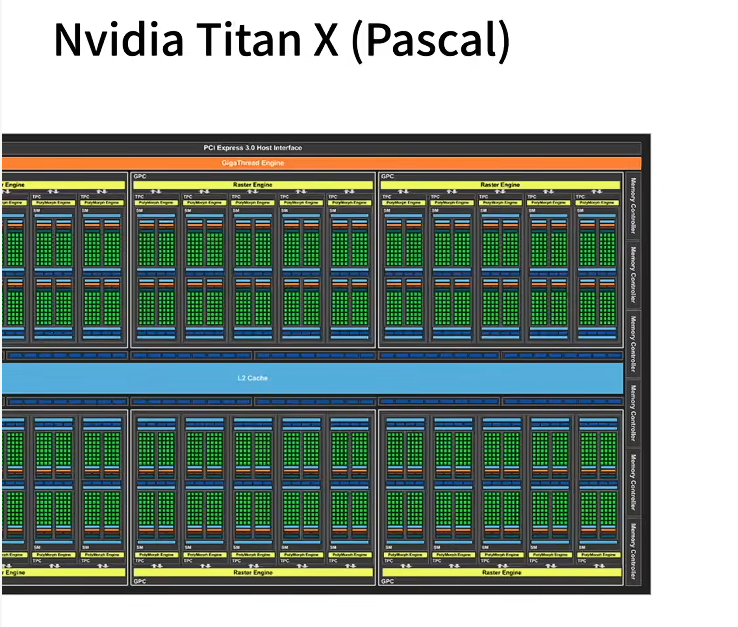
下面是Nvidia Titanx 的架构图。包含六个大核,每个大核里面若干小核。
提升GPU利用率
GPU利用流程(GPU Utilization)通常指的是GPU在采样周期内有任务在运行的时间比例。
(1) GPU利用率低的原因分析
① 数据加载慢:GPU算力再强,如果CPU送数据的速度跟不上,GPU就会处于"饥饿状态"。
② BatchSize太小:GPU核心没有被充分使用
③ 模型太小:必须小型CNN、简单MLP等模型,GPU会很快算完,然后等待。
④ 数据预处理太复杂:
在程序开始执行后,一些数据预处理桥段在CPU上缓慢执行,造成GPU等待。
⑤ GPU与CPU数据传输慢:若CPU→GPU数据传输频繁也会降低利用率。
(2) 提升GPU利用率的主要方案
① 增加DataLoader 线程数:多个CPU线程并行加载数据,减少GPU等待时间。在 PyTorch 中增加
DataLoader的num_workers参数。② 增加 BatchSize:一次给GPU更多数据,但要注意首显存限制,如果显存不够会Out Of Memory (OOM)。
③ 固定内存 (Pinned Memory): 在 PyTorch 中设置
DataLoader的 ``pin_memory=True。这可以将数据缓存在锁页内存中,使得数据传输到显存的速度更快。④ 减少数据预处理时间:提前处理数据并缓存到内存。
⑤ 减少CPU-GPU之间数据拷贝:少搬数据,多计算。
⑥ 自动混合精度 (AMP): 使用
torch.cuda.amp或float16/bfloat16进行训练。
原理: 减少内存带宽压力,并利用 NVIDIA 的 Tensor Cores 进行加速。
效果: 计算速度翻倍,且能腾出空间容纳更大的 Batch Size。
⑦ 使用多GPU训练:数据并行,同时使用多个GPU。
⑧ 优化模型计算结构:如减少小矩阵计算,增加大矩阵计算,GPU更擅长大规模并行计算。
⑨ 少用控制语句:GPU对逻辑控制支持有限,同步开销很大。
......
CPU V.S GPU
核心特性对比
| 特性 | CPU | GPU |
|---|---|---|
| 核心设计 | 核心少但强(复杂逻辑控制) | 核心多而专(海量浮点运算单元) |
| 处理模式 | 延迟导向(快速完成单个复杂任务) | 吞吐量导向(同时处理大量简单任务) |
| 内存结构 | 延迟低、容量大(数十 GB 到 TB 级) | 带宽极高、容量相对有限(通常 8GB-80GB) |
| 编程架构 | C++, Python, Java | CUDA (NVIDIA), OpenCL, ROCm (AMD) |
GPU的核远远多于CPU,所以其每秒计算浮点数也远大于CPU;另外一个影响计算效率的关键因素是内存带宽(读数据的速度跟不上处理数据的速度的话,处理器也是空闲),而GPU的内存带宽也做得比较大,从而能够实现处理大规模数据时并行计算。
但是GPU没法做到比较大的内存大小,并且控制流比较弱(CPU主要是用来做逻辑控制的,而GPU主要用来做运算的),GPU的芯片比CPU大一点点,而它放了大量的核,把所有做逻辑控制的单元删掉了------GPU就是给运算做设计的!

主流CPU、GPU厂商了解
(1)CPU
很多游戏电脑、工作站都使用 AMD CPU。
AMD (Advanced Micro Devices)目前是高性能 x86 架构中唯一能与 Intel 深度抗衡的公司。他们的关键产品Ryzen(锐龙) 系列统治个人电脑市场,EPYC(霄龙) 系列在服务器和数据中心市场(如云计算节点)凭借高核心数和高性价比获得极大成功,近年来在制程工艺(由台积电代工)和多核性能上表现极其激进。
ARM 比较特殊,它不生产CPU,而是设计CPU架构。很多公司会:购买ARM架构授权,然后自己制造芯片。很多手机 CPU 都基于 ARM 架构。
ARM (Advanced RISC Machines)是目前移动端(手机、平板)的霸主,也是能效比(Performance per Watt)的王者。几乎所有智能手机(苹果 A 系列、高通骁龙)都基于 ARM 指令集。苹果的 M 系列芯片(M1/M2/M3)证明了 ARM 在电脑端的强大性能。亚马逊(Graviton)、阿里巴巴(倚天)等也在自研 ARM 服务器芯片以降低功耗。ARM设计精简指令集(RISC),极其省电,适合需要大规模部署的数据中心和便携式设备。
(2)GPU
CPU主要用于通用计算,GPU应用非常广泛,包括:图形、视频、游戏、深度学习、手机、自动驾驶等,因此,GPU厂商更多、应用领域更广。
AMD 是少数同时做 CPU 和 GPU 的公司,他们的典型 GPU:Radeon 系列,常见于:游戏显卡、工作站显卡。在高性能计算(HPC)领域表现强劲,但在深度学习生态(CUDA)方面稍逊于 NVIDIA,目前正通过开源的 ROCm 框架努力追赶。
Intel 不仅做 CPU,也做 GPU。产品:核显(UHD/Iris)、独立显卡(Arc 系列)及数据中心显卡(Ponte Vecchio)。虽然 Intel 是显卡市场份额的大头(主要靠集成显卡),但其在独立显卡和高性能 AI 加速卡领域仍处于快速扩张期。
ARM的GPU主要用于移动设备 SoC。我们在 Android 手机(如联发科天玑系列)中看到的显卡往往就是 ARM 原生的 Mali 架构。它们专注于在极低功耗下提供流畅的 UI 体验和游戏画面。
Qualcomm 是手机芯片的重要厂商,典型产品骁龙(Snapdragon)处理器内置的 Adreno GPU。Qualcomm 是移动端 GPU 的性能标杆。Adreno 技术起源于买下的 ATI 移动部门(Adreno 是 Radeon 的变位词),在移动端图形性能和能效平衡上具有极强的技术壁垒。

当我们想榨干 CPU 或 GPU 的性能时,不能只靠 Python,需要更底层、更高性能的编程方式。
CPU/GPU高性能计算编程
CPU 编程的重点在于复杂逻辑控制 和指令级并行 。高性能计算通常使用 C++,因为它接近硬件,执行效率高。C++ 会提前编译成机器码,执行时几乎没有额外开销。此外,经过数十年的发展,GCC、Clang 和 MSVC 等编译器已经极其成熟 。它们具备极其强大的自动向量化(SIMD) 和自动优化能力,能将代码优化到接近硬件极限,比如编译器会自动做循环展开、自动向量化、缓存优化、指令调度等工作,这也是 CPU 编程比较稳定的重要原因。
GPU 高性能编程:++CUDA++是 NVIDIA 提供的一套 GPU 编程平台。本质是:让程序员用 C/C++ 写 GPU 程序,它将 C++ 扩展到了 GPU 领域,其调试工具(Nsight)、文档和社区支持是目前所有 GPU 编程框架中最完善的。这也是为什么:深度学习几乎默认用 NVIDIA GPU。
++OpenCL(Open Computing Language)++是一个开放标准,理论上可以在 AMD、Intel、Qualcomm 甚至 CPU 上运行。"质量取决于硬件厂商"------虽然 OpenCL 跨平台,但不同厂商对标准的实现程度不同,同时在 NVIDIA 显卡上,OpenCL 的性能通常不如 CUDA;在某些嵌入式平台上,驱动程序的不稳定或编译器优化不足会导致开发成本剧增。
目前的计算编程领域还有几个重要的新兴力量:
-
AMD 的 ROCm / HIP: 为了挑战 CUDA,AMD 推出了 HIP 框架。它的语法与 CUDA 极其相似,甚至提供工具(hipify)直接将 CUDA 代码转换为可以在 AMD GPU 上运行的代码。
-
苹果的 Metal: 在 Mac 和 iPhone 上,苹果不再支持 OpenCL,而是全力推行 Metal,它在苹果自研芯片上拥有极高的利用率。
-
WebGPU: 随着浏览器技术的进步,WebGPU 正在成为网页端调用 GPU 算力的新标准(你之前提到的 Web 端可视化系统可能会涉及到此技术)。
总的来说,CPU 高性能编程主要依赖 C++,因为编译器成熟、优化充分。GPU 编程最主流的是 CUDA,尤其在 NVIDIA GPU 上。OpenCL 是跨厂商方案,但性能取决于厂商实现。在 AI 和深度学习领域,CUDA 是最重要的 GPU 编程方式。
总结
CPU:可以处理通用计算。性能优化考虑数据读写效率和多线程。
GPU:使用更多的小核和更好的内存带宽,适合能大规模并行的计算任务。