Unix 是现代操作系统(包括 Linux 和 macOS)的鼻祖,它的设计哲学极其优雅且影响深远。它的核心知识可以概括为以下几个部分:
🏗️ Unix 的四大核心架构
Unix 系统就像一个分工明确的团队,主要由四个部分组成:
- 内核 (Kernel):系统的"大脑"
它是操作系统的核心,直接与硬件打交道。它负责管理 CPU 时间(进程管理)、分配内存、控制硬盘读写(文件系统)以及驱动各种硬件设备。内核在后台默默工作,普通用户通常不直接接触它。 - Shell:用户与内核的"翻译官"
这就是你平时看到的命令行界面 (比如 Bash、Zsh)。当你输入一条命令(比如ls),Shell 会解析你的意图,然后指挥内核去执行,最后把结果展示给你。同时,Shell 本身也是一门强大的编程语言(即 Shell 脚本)。 - 文件系统:万物皆文件
Unix 有一个极其深刻的设计理念------"一切皆文件"。不仅普通的文档、图片是文件,就连你的键盘、鼠标、硬盘分区,甚至是正在运行的进程信息,在 Unix 眼里统统都是文件。这种高度统一的抽象,让操作变得极其简单。 - 应用程序与工具 (Applications/Utilities)
Unix 自带了大量短小精悍的实用工具(如ls,grep,cat等)。它们遵循"一个工具只做好一件事"的原则,可以通过组合来完成极其复杂的任务。
💡 必须了解的 Unix 哲学
Unix 的强大不仅在于技术,更在于它的设计思想,其中最核心的有三点:
- 一切皆文件 (Everything is a file):刚才提到的,统一了所有资源的访问接口。
- 组合小工具 (Compose small tools):不要试图写一个庞大的程序解决所有问题。而是提供很多专注的小工具,然后把它们串起来。
- 管道机制 (Pipe) :这是组合小工具的灵魂。管道符号
|能把上一个命令的"输出",直接变成下一个命令的"输入"。- 举个例子 :你想在日志文件里找包含 "ERROR" 的行,并统计有多少条。在 Windows 可能需要写个小程序,但在 Unix 只需要一行命令:
cat log.txt | grep "ERROR" | wc -l
(读取文件 -> 过滤出 ERROR -> 统计行数,完美体现了 C 语言那种简洁高效的美感!)
- 举个例子 :你想在日志文件里找包含 "ERROR" 的行,并统计有多少条。在 Windows 可能需要写个小程序,但在 Unix 只需要一行命令:
🌳 Unix 家族与 Linux 的关系
Unix 发展了几十年,开枝散叶形成了庞大的家族:
- 商业 Unix :早期由 AT&T 的 System V 和加州大学伯克利分校的 BSD 两大流派主导,衍生出了 IBM AIX、HP-UX、Sun Solaris 等昂贵的商业系统,常用于银行、电信等关键领域。
- macOS :苹果电脑的操作系统。它其实是基于 BSD 开发的,并且通过了官方认证,是当今世界上最流行的正宗 Unix 系统。
- Linux :由林纳斯·托瓦兹在 1991 年开发。它借鉴了 Unix 的设计思想和架构,但代码是完全重写的。虽然 Linux 严格意义上不能叫"Unix",但它完全继承了 Unix 的衣钵(即"类 Unix"系统),并且因为开源免费,成为了服务器、超级计算机和嵌入式设备的绝对霸主。
文件和目录
Unix 的文件和目录系统,可以说是整个操作系统的灵魂。它和我们平时用的 Windows 系统有着本质的区别,其中最核心的设计理念就是------"一切皆文件"。
在 Unix 里,不管是普通的文档、图片,还是你的键盘、鼠标、硬盘,甚至是正在运行的程序(进程),在系统眼里统统都是"文件"。这种高度统一的抽象,让操作变得极其简单和优雅。
🌳 倒立的树:目录结构
和 Windows 有 C盘、D盘这种分区概念不同,Unix 的目录结构像一棵倒立的树。
- 根目录
/:这是整棵树的根,是所有文件和目录的起点。 - 绝对路径与相对路径 :
- 绝对路径 :从根目录
/开始写起,比如/home/user/file.txt。它就像一个人的身份证号,是独一无二的。 - 相对路径 :从当前所在的目录出发,比如
./file.txt或../images/pic.jpg。它就像给别人指路说"往前走两百米",取决于你当前站在哪里。
- 绝对路径 :从根目录
- 几个必须认识的关键目录 :
/bin和/usr/bin:存放系统最常用的命令(比如ls,cp等可执行程序)。/etc:存放系统的各种配置文件。/home:普通用户的家目录(比如你的代码、文档通常都放在这里)。/tmp:存放临时文件,重启系统后通常会被清空。
🛠️ 常用文件与目录操作命令
在命令行里,你只需要记住这几个最基础的命令,就能玩转大部分操作:
| 命令 | 作用 | 常用示例 |
|---|---|---|
ls |
列出目录内容 | ls -l (显示详细信息,如权限、大小) |
cd |
切换目录 | cd /home (进入home目录);cd .. (返回上一级) |
pwd |
显示当前所在路径 | 让你知道"我在哪" |
cp |
复制文件或目录 | cp file.txt backup.txt;cp -r dir1 dir2 (复制目录) |
mv |
移动或重命名 | mv old.txt new.txt (重命名);mv file.txt /tmp (移动) |
rm |
删除文件或目录 | rm file.txt;rm -rf dir1 (强制删除目录,慎用!) |
mkdir |
创建新目录 | mkdir my_project |
touch |
创建空文件或更新时间戳 | touch new_file.c |
🔒 文件权限(读、写、执行)
Unix 是一个多用户系统,所以它对文件权限的管理非常严格。当你使用 ls -l 查看文件时,会看到类似 -rwxr-xr-- 这样的一串字符,它们代表了文件的权限:
- 第一组
rwx:文件**所有者(Owner)**的权限。 - 第二组
r-x:和所有者在同一个**用户组(Group)**的人的权限。 - 第三组
r--:**其他人(Others)**的权限。
其中的字母含义如下:
- r (Read):读取权限(对文件来说是能看内容,对目录来说是能列出里面的文件)。
- w (Write):写入权限(对文件来说是能修改,对目录来说是能创建或删除里面的文件)。
- x (Execute):执行权限(对文件来说是能当作程序运行,对目录来说是能进入该目录)。
如果你想修改权限,可以使用 chmod 命令。比如 chmod +x script.sh 就是给脚本加上执行权限,让它能跑起来。
🔗 软硬链接(进阶概念)
在 Unix 中,一个文件可以有好几个"名字",这就是链接。它分为两种:
- 硬链接 (Hard Link):相当于给同一个文件起了个"别名"。删掉其中一个名字,文件内容依然在,只有当所有名字都被删掉,文件才会真正被删除。
- 软链接/符号链接 (Symbolic Link):相当于 Windows 里的"快捷方式"。它指向另一个文件的路径。如果原文件被删了,软链接就会失效(变成死链接)。
输入和输出
在 Unix/Linux 系统中,输入和输出(简称 I/O)是程序与外界沟通的桥梁。它完美体现了"组合小工具"的哲学------让每个程序只专注处理数据,至于数据从哪里来、到哪里去,则交给系统来灵活调度。
📡 三大标准流:程序的默认沟通管道
每当你在终端运行一个程序(比如 ls 或 cat),系统都会自动为它打开三个标准的沟通管道:
| 名称 | 缩写 | 文件描述符 | 默认设备 | 作用 |
|---|---|---|---|---|
| 标准输入 | stdin | 0 | 键盘 | 程序从这里读取你的输入 |
| 标准输出 | stdout | 1 | 屏幕(终端) | 程序把正常的结果打印到这里 |
| 标准错误 | stderr | 2 | 屏幕(终端) | 程序把报错信息打印到这里 |
注:文件描述符是内核用来标识文件的小整数,你可以把它理解为程序内部给这三个管道分配的专属编号。
🔄 重定向:改变数据的流向
默认情况下,输入来自键盘,输出显示在屏幕上。但重定向允许我们改变这些数据的默认流向,比如把结果存到文件里,或者让程序从文件里读取数据。
-
输出重定向
>和>>>(覆盖):把命令原本要输出到屏幕的内容,写入到一个文件中。如果文件已存在,会清空原内容再写入。>>(追加):把内容追加到文件的末尾,保留原有的内容。- 例如 :
ls > files.txt会把当前目录下的文件列表保存到files.txt中,而不是直接显示在屏幕上。
-
输入重定向
<<:让命令不再等待键盘输入,而是直接从一个指定的文件中读取数据。- 例如 :
wc -l < files.txt会直接统计files.txt这个文件里有多少行。
-
标准错误重定向
2>- 因为标准错误的编号是 2,所以用
2>可以专门把报错信息重定向到文件里,而让正常的输出依然显示在屏幕上。
- 因为标准错误的编号是 2,所以用
🌉 管道:连接命令的灵魂
管道(Pipe) 是 Unix 哲学中最精髓的部分,用符号 | 表示。它的作用是将左边命令的标准输出(stdout) ,直接作为右边命令的标准输入(stdin)。
有了管道,你就可以像搭积木一样,把许多功能单一的小命令组合起来,完成极其复杂的任务。
- 比如 :你想找出当前目录下名字里包含 "test" 的文件,并统计有多少个。
你不需要写任何 C 代码,只需要在终端输入:
ls | grep "test" | wc -lls列出所有文件。|把文件列表传给grep。grep "test"筛选出包含 "test" 的行。|再把筛选结果传给wc。wc -l统计行数并输出最终结果。
程序和进程
这两个概念听起来很像,但其实是完全不同的两码事。如果拿做菜来打比方,程序就是写在纸上的"菜谱",而进程就是厨师照着菜谱正在"炒菜"的那个动态过程。
📄 程序:躺在硬盘里的"死代码"
程序(Program) 本质上就是一个普通的二进制文件(比如你在 Linux 下用 gcc 编译出来的 a.out 文件)。
- 它静静地躺在硬盘里,占用着存储空间。
- 它包含了你写的 C 语言代码编译后的机器指令。
- 只要你不运行它,它就永远是一堆不会动的数据。
🏃 进程:活在内存里的"活任务"
进程(Process) 是程序被操作系统加载到内存中,并开始执行后的状态。
- 它是系统进行资源分配和调度的基本单位。
- 它不仅包含了程序的代码,还包含了当前的运行状态(比如程序运行到哪一行了、CPU寄存器里的数据是什么、它占用了多少内存等)。
- 同一个程序可以同时运行多次,产生多个独立的进程(比如你同时打开了三个终端窗口,其实就是运行了三个相同的终端程序,产生了三个不同的进程)。
📊 一张表看懂区别
| 维度 | 程序 | 进程 |
|---|---|---|
| 存在状态 | 静态的(代码指令的集合) | 动态的(代码的执行过程) |
| 存储位置 | 硬盘(磁盘) | 内存(RAM) |
| 生命周期 | 只要文件不被删,就一直存在 | 有创建、有运行、有消亡 |
| 组成 | 只有机器指令 | 程序代码 + 数据 + 进程控制块(PCB) |
🧠 深入理解:进程的"内存布局"
当你用 C 语言写了一个程序并运行起来后,操作系统会在内存里给这个进程划分出几个专属的区域,你可以把它想象成进程在内存里的"私人房间":
- 代码区(Text Segment):存放你编译好的机器指令(也就是程序本身的内容)。这块区域通常是只读的,防止程序自己把自己改坏了。
- 数据区(Data Segment):存放你已经初始化好的全局变量和静态变量。
- 堆区(Heap) :这是你最需要关注的区域! 当你使用 C 语言标准库里的
malloc()或free()动态分配内存时,操作的就是这块区域。堆区由你手动管理,如果只malloc不free,就会造成内存泄漏。 - 栈区(Stack) :存放你的局部变量、函数参数以及函数调用的返回地址。每当你调用一个函数,系统就会在栈上"压入"一层;函数执行完,就"弹出"一层。如果递归调用太深,把栈撑爆了,就会发生经典的栈溢出(Stack Overflow)。
💻 结合 Unix/Linux 命令来观察
在你的 Linux 终端里,有几个命令可以帮你直观地看到进程:
ps:查看当前瞬间的进程快照。- 常用
ps aux,可以列出系统中所有正在运行的进程,你会看到每行都有一个 PID(进程ID),这是进程的唯一身份证。
- 常用
top:像任务管理器一样,动态实时地显示进程状态(CPU和内存占用率)。./your_program &:在命令后面加个&,可以让你的 C 程序在后台作为一个进程运行,不占用当前的终端。kill <PID>:根据进程 ID 强制结束一个进程(相当于拔掉了它的电源)
出错处理
在 Unix/Linux 环境下用 C 语言写程序,出错处理绝对是决定程序是否健壮的关键一环。因为 Unix 的系统调用(比如打开文件、分配内存)一旦失败,通常不会直接让程序崩溃,而是会返回一个特定的错误码。如果你不主动去检查,程序就会带着错误继续"带病运行",最后导致更诡异的 Bug。
🔍 Unix 如何报告错误?
在 Unix 系统中,当系统调用或库函数发生错误时,通常会遵循以下两个规则:
- 返回值 :大多数函数会返回
-1或者NULL来告诉你"出事了"。 - 全局变量
errno:这是 C 标准库提供的一个全局整数变量(定义在<errno.h>中)。当函数返回错误时,它会把具体的错误原因(一个数字编号)存进errno里。
🛠️ 如何把错误码变成人话?
光看 errno 的数字(比如 errno = 2)你肯定不知道发生了什么。C 库提供了两个非常好用的函数,能把这些数字翻译成你能看懂的英文提示:
perror(const char *s):非常省事。它会先打印你传入的字符串s,然后自动补上当前errno对应的错误描述。strerror(int errnum):定义在<string.h>中。它只负责把错误码转换成错误信息的字符串,你可以把它拼接到自己的日志里。
💻 实战:标准的错误处理写法
假设我们要打开一个文件,标准的"防御性编程"写法应该是这样的:
#include <stdio.h>
#include <stdlib.h>
#include <errno.h> // 提供 errno
#include <string.h> // 提供 strerror
#include <fcntl.h> // 提供 open 的 flags
int main() {
// 尝试打开一个不存在的文件
FILE *fp = fopen("not_exist_file.txt", "r");
// 第一步:检查返回值
if (fp == NULL) {
// 第二步:打印错误信息
// 写法 A:使用 perror(最简单直接)
perror("fopen failed");
// 终端会输出:fopen failed: No such file or directory
// 写法 B:使用 strerror(更灵活,可以自定义格式)
fprintf(stderr, "【自定义报错】打开文件时发生错误 (errno=%d): %s\n",
errno, strerror(errno));
// 第三步:进行错误后的收尾工作(比如退出程序)
exit(EXIT_FAILURE);
}
// 如果一切正常,继续执行...
printf("文件打开成功!\n");
fclose(fp);
return 0;
}⚠️ 避坑指南:关于 errno 的重要规则
- 只有出错时才有效 :如果一个函数调用成功了,它不一定 会把
errno清零。所以,千万不要在函数调用成功后去检查errno,必须先判断函数的返回值是否表示出错。 - 尽早处理 :
errno是一个全局变量,如果中间调用了其他函数,可能会被覆盖。所以一旦检测到出错,要立刻把errno的值保存下来或者直接打印出来。
用户标识
在 Unix/Linux 系统中,用户标识(UID,User Identifier) 是系统用来识别每一个用户的唯一数字编号。
虽然我们在日常操作中看到的是用户名(比如 root 或 alice),但实际上,Linux 内核和系统底层在管理权限、进程和文件时,只认 UID,不认用户名。UID 就像是每个用户在系统里的"身份证号"。
🪪 UID 的分类与常见范围
Linux 系统根据 UID 的大小,将用户分成了不同的等级和类型(不同版本的 Linux 范围略有差异,以目前主流的 CentOS 7/RHEL 为例):
- 0(超级用户 / root) :
UID 为0的用户拥有系统的最高权限,可以执行任何操作。系统默认只有root用户的 UID 是 0。 - 1 - 999(系统用户 / 程序用户) :
这些 UID 通常保留给系统内部的服务或进程使用(比如bin、daemon、apache等)。它们一般不允许登录系统,主要是为了保证系统服务安全地运行。 - 1000 - 65535(普通用户) :
由管理员创建的真实人类用户。在现代 Linux 系统中,新建的普通用户 UID 默认从1000开始递增。
📂 UID 存在哪里?(/etc/passwd 文件)
系统中所有用户的基本信息都保存在 /etc/passwd 这个文件里。每行代表一个用户,用冒号 : 分隔成 7 个字段,其中第 3 个字段就是 UID。
格式如下:
用户名:密码占位符:UID:GID:用户描述:宿主目录:登录Shell
举个例子,查看 root 用户的信息:
root:x:0:0:root:/root:/bin/bash
这里的第 3 个字段 0,就代表 root 的 UID 是 0。
🛠️ 如何查看 UID?
在终端里,你可以使用 id 命令来快速查看当前用户或指定用户的 UID 和所属组信息:
# 查看当前登录用户的 UID 和 GID
id
# 查看指定用户(比如 alice)的 UID
id alice输出示例:uid=1000(alice) gid=1000(alice) groups=1000(alice)
💡 结合你的 C 语言背景
在你之前学习的 C 语言中,标准库其实已经为我们封装好了获取用户信息的功能。
getuid()函数 :定义在<unistd.h>中,调用它会直接返回当前进程的真实用户 ID(UID)。geteuid()函数 :返回有效用户 ID(Effective UID) 。这在处理权限提升(比如使用了sudo或设置了 SUID 位的程序)时非常有用,它决定了你当前实际操作所具备的权限。
信号
在 Unix/Linux 系统中,信号(Signal) 是进程之间传递"事件通知"的一种异步机制,本质上是一种**"软件中断"**。
如果说之前的"用户标识(UID)"决定了进程的身份和权限,那么"信号"就是系统或其他进程用来给这个进程"发号施令"或"发送通知"的快捷方式。它就像你生活中的门铃,不用一直盯着门口(轮询),门铃响了(收到信号),就知道有事件发生了。
🔔 信号的生命周期:从产生到处理
一个信号从产生到被处理,通常会经历以下几个阶段:
- 产生(Generation):由于某些事件(如按键、程序异常、系统调用等),内核为目标进程生成一个信号。
- 挂起/未决(Pending):信号被记录在进程的"信号位图"中,处于等待处理的状态。如果信号被进程阻塞,它会一直停留在这个状态。
- 递送与处理(Delivery & Handling):当进程从内核态返回用户态时,会检查是否有未处理的信号。如果有,进程会根据预设的方式(默认、忽略或自定义函数)来处理它。
📜 常见的信号类型
Linux 系统中有几十种信号,其中前 31 种是标准信号(不可靠,不支持排队),34~64 是实时信号(可靠,支持排队)。日常开发中最常接触的是标准信号,以下是几个必须认识的"高频信号":
| 信号编号 | 信号名称 | 默认动作 | 常见触发场景 |
|---|---|---|---|
| 2 | SIGINT | 终止进程 | 用户在终端按下 Ctrl+C |
| 3 | SIGQUIT | 终止+生成core文件 | 用户在终端按下 Ctrl+\ |
| 9 | SIGKILL | 强制终止 | kill -9 PID(无法被拦截或忽略) |
| 11 | SIGSEGV | 终止+生成core文件 | 非法内存访问(经典的段错误) |
| 15 | SIGTERM | 终止进程 | kill PID 默认发送的信号(可被拦截) |
| 17 | SIGCHLD | 忽略 | 子进程状态改变或退出时通知父进程 |
特别说明 :SIGKILL (9) 和 SIGSTOP (19) 是两个特权信号,它们不能被捕获、忽略或自定义处理,这是为了保证系统管理员在任何情况下都能强制控制进程。
⚙️ 信号的三种处理方式
当进程收到一个信号时,它可以采取以下三种动作之一:
- 默认处理(SIG_DFL):按照系统预定义的方式处理(绝大多数信号的默认动作是终止进程)。
- 忽略信号(SIG_IGN):收到信号后不做任何响应(SIGKILL 和 SIGSTOP 除外)。
- 自定义处理(Catch):进程提前注册一个"信号处理函数",当收到该信号时,中断当前的正常逻辑,转而去执行这个自定义函数。
💻 结合C 语言
在 C 语言中,你可以使用 <signal.h> 头文件中的 signal() 函数来为进程设置自定义的信号处理方式。
实战示例:拦截 Ctrl+C
下面这段代码展示了如何拦截 Ctrl+C,让程序不再直接退出,而是打印一条提示:
#include <stdio.h>
#include <signal.h>
#include <unistd.h>
// 自定义的信号处理函数
void handle_sigint(int sig) {
printf("\n嘿!我收到了信号 %d (SIGINT),但我选择不退出!\n", sig);
}
int main() {
// 注册信号处理函数:当收到 SIGINT 时,调用 handle_sigint
signal(SIGINT, handle_sigint);
printf("程序正在运行,PID 是 %d。试着按 Ctrl+C 看看?\n", getpid());
// 让主进程一直循环,等待信号的到来
while (1) {
sleep(1);
}
return 0;
}总结一下 :信号是 Linux 进程通信(IPC)中最古老也最基础的机制。无论是你日常用 kill 命令结束卡死的程序,还是程序因为访问空指针而崩溃(SIGSEGV),背后都是信号在起作用。理解信号,能帮你更好地控制进程的生命周期,也能在程序出现异常时快速定位问题。
时间值
在 Unix/Linux 系统和 C 语言编程中,时间的处理有着非常独特的底层逻辑。和你平时看到的"年-月-日 时:分:秒"不同,系统内核在底层只认一种最纯粹的时间------日历时间(Calendar Time)。
⏱️ 什么是日历时间(时间戳)?
日历时间,也就是我们常说的 Unix 时间戳(Unix Timestamp) 。它的定义非常硬核:
从协调世界时(UTC)1970年1月1日 00:00:00 开始,到现在所经过的总秒数。
在 C 语言中,这个时间通常用 time_t 这个长整型(long)来存储。比如,当前时间(2026年4月29日)的时间戳大约是一个 17 亿多的整数。
为什么系统要这么设计?
因为用一个单纯的整数来表示时间,不受时区、夏令时、闰年等复杂规则的影响,计算机在做时间计算(比如计算两个时间相差多少秒)时会极其高效和准确。
🛠️ C 语言中的时间处理工具链
C 语言标准库 <time.h> 为我们提供了一套完整的时间处理工具,主要包含以下几个核心角色:
time_t(日历时间):存储从 1970 年开始的秒数。struct tm(分解时间):把时间戳"打碎"成年、月、日、时、分、秒等人类可读的字段。- 常用时间函数:负责在"日历时间"和"分解时间"之间来回转换。
💻 实战:获取并打印当前时间
在 C 语言中,获取当前时间并转换成人能看懂的格式,通常分为三步:
-
调用
time()获取时间戳(time_t)。 -
调用
localtime()将时间戳转换为本地的分解时间(struct tm)。 -
提取
struct tm中的字段,或者用格式化函数打印出来。#include <stdio.h>
#include <time.h>int main() {
// 1. 获取当前的日历时间(时间戳)
time_t now = time(NULL);
printf("当前时间戳: %ld\n", now);// 2. 将时间戳转换为本地时区的分解时间 // 注意:localtime 返回的是指向静态内存的指针 struct tm* t = localtime(&now); // 3. 手动提取字段并格式化输出 // 注意:tm_year 是从 1900 年开始算的,所以要 +1900 // tm_mon 是从 0 开始算的(0代表1月),所以要 +1 printf("当前本地时间: %04d-%02d-%02d %02d:%02d:%02d\n", t->tm_year + 1900, t->tm_mon + 1, t->tm_mday, t->tm_hour, t->tm_min, t->tm_sec); // 4. 偷懒写法:直接用 ctime 打印固定格式的时间字符串 printf("偷懒打印: %s", ctime(&now)); return 0;}
⚠️ 避坑指南与进阶知识
-
struct tm的字段陷阱 :在使用
localtime转换出来的struct tm结构体时,一定要记住:tm_year:代表的是"距离 1900 年的偏移量",所以打印真实年份必须+1900。tm_mon:月份是从 0 开始计数的(0~11 代表 1月~12月),所以打印真实月份必须+1。
-
2038年问题(Year 2038 Problem) :
在传统的 32 位系统中,
time_t是一个 32 位的有符号整数。它的最大值只能存储到 格林威治时间 2038年1月19日 03:14:07。过了这一秒,时间戳就会发生溢出变成负数,导致系统时间"穿越"回 1901 年。- 解决方法 :现在的 64 位操作系统和编译器(如 64 位的 Linux 或 Visual C++)已经将
time_t扩展为 64 位,可以轻松表示几百亿年后的时间,基本解决了这个问题。
- 解决方法 :现在的 64 位操作系统和编译器(如 64 位的 Linux 或 Visual C++)已经将
-
更高精度的时间 :
time()函数的精度只有秒 。如果你在 Linux 下做高性能计算或网络编程,需要微秒(μs)甚至纳秒(ns)级的精度,可以使用 Linux 特有的gettimeofday()(微秒级)或clock_gettime()(纳秒级)函数。
总结一下 :在 Unix 世界里,时间戳(time_t)是机器看的,分解时间(struct tm)是人看的 。掌握它们之间的转换,以及注意 tm_year 和 tm_mon 的偏移量,你就能轻松搞定 C 语言里的时间处理!
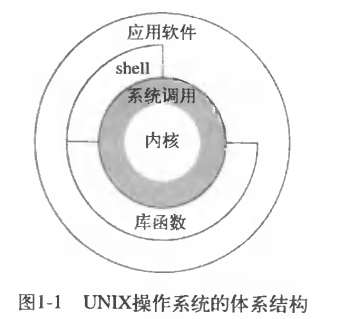
系统调用和库函数
简单来说,系统调用是操作系统内核提供的"底层大门" ,是用户程序访问内核资源(如硬件、文件、进程)的唯一合法途径;而库函数是前人封装好的"便捷工具箱",它们在系统调用的基础上,提供了更高级、更易用的功能。
🆚 核心区别对比
为了让你更直观地理解,我们可以通过以下几个维度来对比它们:
| 对比维度 | 系统调用 (System Call) | 库函数 (Library Function) |
|---|---|---|
| 提供者 | 操作系统内核(Kernel) | 标准C库(如 Linux 下的 glibc) |
| 运行空间 | 内核态(特权级,可直接操作硬件) | 用户态(非特权级,受限运行) |
| 性能开销 | 高(需要进行用户态与内核态的切换) | 低(纯逻辑运算无切换,或通过缓冲减少调用次数) |
| 可移植性 | 差(依赖特定操作系统内核) | 好(遵循 C 标准或 POSIX 标准,跨平台) |
| 功能粒度 | 最小粒度,只做单一底层操作 | 功能更丰富,可能封装了多个系统调用 |
| 典型例子 | open, read, write, fork |
fopen, printf, malloc, strlen |
⚙️ 它们是如何协作的?
库函数和系统调用并不是完全割裂的,它们之间主要有三种协作关系:
- 1个库函数 → 1个系统调用 :比如库函数
fclose在内部封装了close系统调用,帮你释放文件资源。 - 1个库函数 → 多个系统调用 :比如
malloc(申请内存),底层可能会根据申请的大小,自动调用brk或mmap等系统调用,同时帮你处理复杂的内存碎片管理。 - 库函数完全不依赖系统调用 :比如
strlen(计算字符串长度)、strcpy(字符串复制)等纯逻辑运算函数,它们只在用户态做数学计算,完全不需要惊动内核。
💡 为什么库函数通常比直接调用系统调用更快?
很多初学者会有个误区,觉得"库函数底层也是调系统调用,多了一层封装肯定更慢"。其实恰恰相反,库函数往往通过**缓冲机制(Buffering)**极大地提升了性能。
- 直接调用系统调用(如
write):如果你要写入 1000 个字符,每次只写 1 个,那么就会触发 1000 次从用户态到内核态的切换,开销极大。 - 使用库函数(如
printf或fwrite) :库函数会在用户空间先开辟一块"缓冲区"。你调用 1000 次,数据其实只是被放进了用户态的缓冲区里。等缓冲区满了,或者遇到换行符时,库函数才会一次性 调用底层的write系统调用把数据刷入内核。这极大地减少了昂贵的上下文切换次数。
💻 结合C 语言
你在写 C 语言代码时,其实一直在无意识地使用库函数。
- 日常开发 :优先使用库函数(如
printf,fopen,malloc)。因为它们遵循 POSIX 或 C 标准,不仅开发效率高,而且代码可以轻松移植到 Windows、macOS 等其他系统上。 - 底层/系统开发 :当你需要追求极致性能(避免缓冲带来的延迟),或者需要实现一些库函数没有提供的特殊功能(如创建进程
fork、挂载文件系统等)时,才会直接去调用系统调用(如open,write,mmap)。
一个小技巧 :在 Linux 下,你可以通过 man 手册来区分它们。输入 man 2 open(第2章通常是系统调用)和 man 3 printf(第3章通常是库函数),就能看到它们详细的底层定义和用法区别。