背景介绍
随着 AI 模型结构不断演进,尤其是在 MoE 和多模态场景中,越来越多的网络开始采用动态、细粒度的小算子组合来表达计算。小算子虽然提升了模型设计灵活性,但单独执行时往往存在访存和调度开销大等问题,导致整体执行效率偏低,因此需要通过算子融合来提升性能。然而手动融合算子需要从算子代码层面进行重构,人力和时间成本开销大,为此CANN的AutoFuse组件与具有成熟生态的TorchInductor后端对接实现了算子的自动融合技术,极大降低模型的优化成本。经客户实际场景验证,DeepSeekV3.1-Terminus 通过AutoFuse技术优化后性能 提升17% 。
AutoFuse介绍
AutoFuse是CANN面向昇腾NPU提供的自动融合能力,目标是在保持模型语义不变的前提下,将多个适合协同执行的算子组织为融合算子,减少中间结果搬运与重复调度开销,从而提升整体执行效率。对于以小算子组合为主、访存开销占比较高的场景,AutoFuse能够更充分发挥NPU在本地存储、并行执行和向量计算方面的优势。
AutoFuse以AscIR图(AscGraph)作为输入。上层框架和AutoFuse适配层通常会先基于框架侧IR完成Lowering与融合策略处理,将原始计算图翻译为多个融合算子的集合,其中每个融合算子对应一张AscGraph.若上层能够提供CANN中抽象层级更高的Ascend IR图,AutoFuse提供了相应的能力将其转换为AscGraph;对于直接对接框架IR的场景,则可通过适配层将框架侧图翻译为多张AscGraph。随后,AutoFuse围绕输入的多张AscGraph依次完成 Schedule 、Auto Tiling 和 Codegen 三个阶段,生成可在昇腾NPU上执行的融合算子实现。
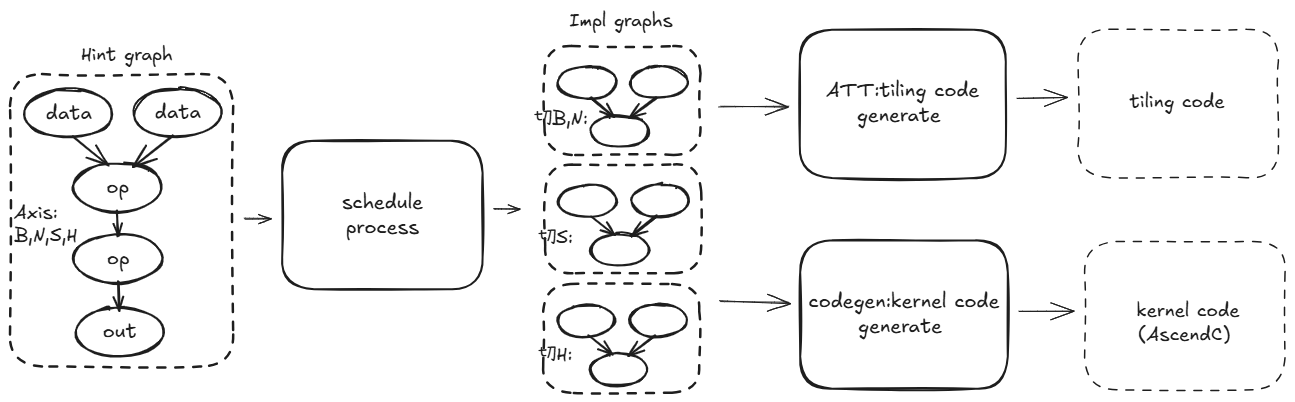
- Schedule:对输入的AscGraph进行重排和优化,并生成多个候选优化图供后续挑选.
- Auto Tiling:结合输入shape和硬件约束从候选优化图中选择最合适的优化图,并计算出此种优化图下最佳的Tiling参数。
- Codegen:对Schedule生成的多张候选图各生成一份可执行的硬件代码,并接收Auto Tiling计算的Tiling参数确认此次输入下应该选择的执行代码.
Schedule
Schedule阶段面向输入的AscGraph实现组织与执行优化。对于AutoFuse而言,进入Schedule阶段的AscGraph通常被称为 HintGraph 。HintGraph 对应的是一个进入后端处理的融合算子,它侧重描述的是计算逻辑本身,不考虑分核和内存管理。经过Schedule处理后,会形成一组用于后续选择的候选实现图,这些候选图称为 ImplGraph。
Schedule阶段的主要任务包括:
- 循环合并:通过对循环结构进行重构,减少访存次数与控制开销,提升数据局部性,并为后续调度优化创造更合适的循环形态。
- 生成TilingCase:根据融合算子的计算逻辑生成多种可行的切分策略(TilingCase)供后续选择最优的切分策略.
- 并行优化:通过将外层循环拆分成多核并行执行以及内层循环的标量计算重写为向量计算提升执行性能
- 内存优化:复用节点申请的内存,减少内存峰值占用和节省内存申请的耗时.
- 多模板生成:针对每个TilingCase都可能存在多种可行的实现方案,将每个方案都生成ImplGraph供后续选择.
Schedule阶段最关键的优化是 生成TilingCase 和 多模板生成 ,TilingCase的切分策略会极大影响算子的执行性能。在生成TilingCase阶段,算子的切分策略的设计和输入的shape,dtype等息息相关,因此此阶段会生成多个TilingCase供Auto Tiling阶段结合实际输入选择。在多模板生成阶段,每个切分策略又可能存在多种实现方案,在输入未确定前也无法确认方案的好坏。因此针对每个TilingCase会根据通用的输入设计一个通用方案,再根据不同的输入范围设计特定的实现方案,每个方案都看成是待选的模板,对应一张ImplGraph保存下来.因此输入的HintGraph会先生成多个TilingCase,每个TilingCase又会生成多个ImplGraph,最后得到Schdule阶段的输出-- ImplGraph集合。
Auto Tiling
Schedule阶段输出了ImplGraph集合 ,AutoTiling阶段就是根据实际的输入选取表现最好的 ImplGraph ,并将其计算成具体的Tiling参数传递给Codegen组成完整的执行代码.
Auto Tiling内部会经过如下三个阶段:
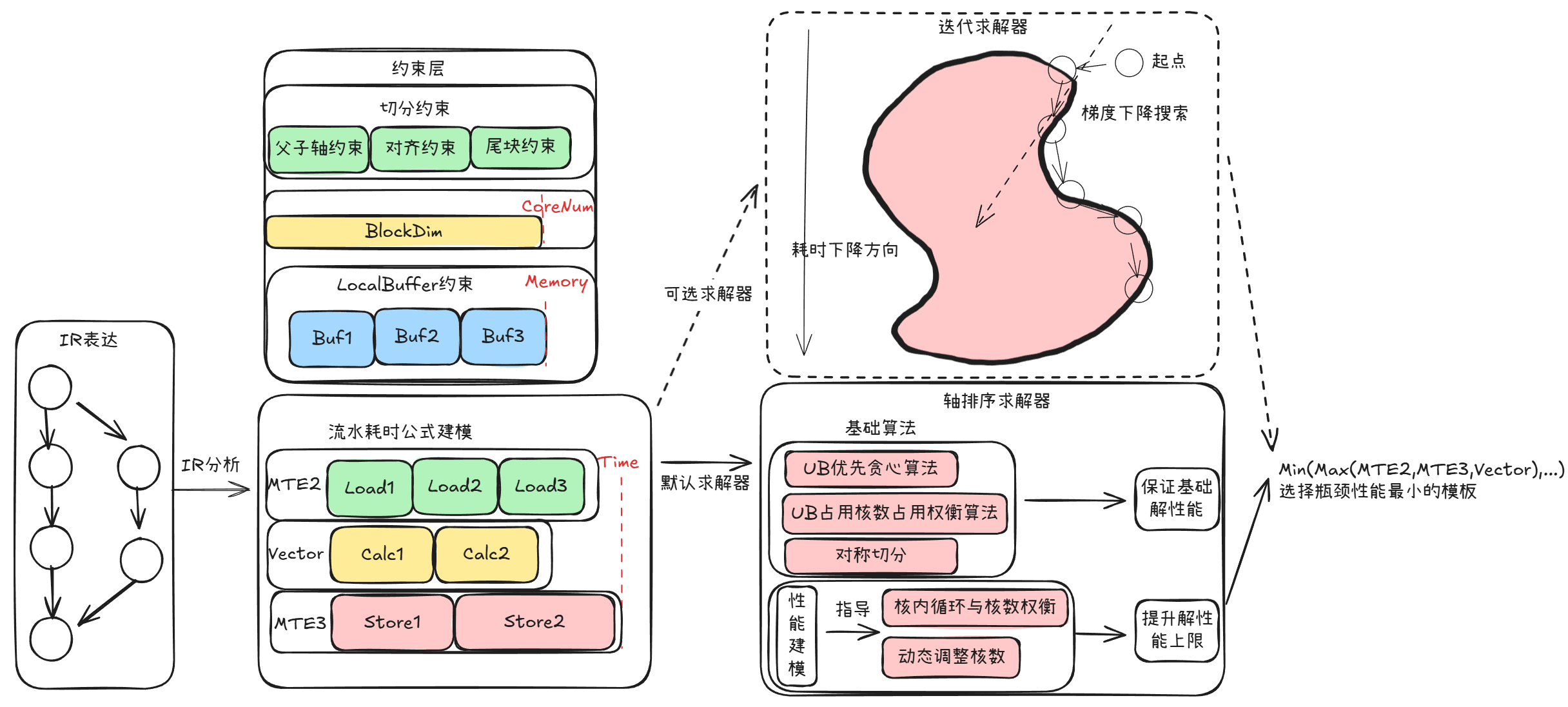
1. 约束的符号化表达: 在硬件代码执行时,会对算子进行一些约束判断确认算子执行逻辑是否满足硬件的要求.AutoTiling会从ImplGraph中提取 内存占用约束 、核数占用约束 、切分约束 ,将这些约束翻译成统一的符号供硬件代码执行时判断。
2. 耗时公式建模: 通过将输入ImplGraph翻译成Ascend C API的流水执行图,Ascend C API流水执行图中耗时最长的流水线的耗时便是此ImplGraph方案的执行耗时,由此建立每张ImplGraph的耗时公式.
3. 求解器求解: 确认耗时公式后,只需要估算公式里每个Ascend C API的耗时便能得到每张ImplGraph的执行耗时,而API的耗时由输入数据和Tiling切分参数决定。因此Auto Tiling内置了每个Ascend C API的性能建模公式,由于输入数据是固定的而Tiling参数可调整,此阶段通过求解器的方式,不断调整Tiling参数计算ImplGraph的执行耗时,以此得到最短执行耗时对应的Tiling参数。
经过这三个阶段之后,便选择出了最优的ImplGraph并计算出了对应的Tiling参数。
Codegen
Codegen负责将Schedule阶段生成的候选 ImplGraph 翻译为真正可编译、可执行的Ascend C算子代码。而Ascend C代码分为Host侧代码和Kernel侧代码:
其中,Host侧代码主要包括:
- tiling_func:负责将计算任务划分为更小的块(tiling),便于在Device上高效执行
- infer_shape:负责推导张量形状及相关元信息。
- get_kernel:获取Device侧Kernel代码。
Device侧代码主要包括:
- kernel:实际运行在昇腾NPU上的计算逻辑。
- tiling_data:用于描述如何划分和处理数据的结构,就是AutoTiling计算得到Tiling参数。
由于Schedule阶段生成了多张ImplGraph,在CodeGen阶段会为每张ImplGraph生成一个模板函数,在执行入口处通过TilingKey判断此次选择哪一个模板函数执行.而TilingKey由AutoTiling计算的Tiling参数中传递给Codegen,以此实现了AutoTiling选择最优方案,Codegen选择最优方案的执行代码.
TorchInductor对接AutoFuse
TorchInductor介绍
PyTorch 2.0推出了一套新的图模式即时编译系统,通过对模型计算过程进行编译优化来提升执行效率。Inductor正是这套系统中的重要组件,负责将TorchDynamo和AOTAutograd整理出的FX计算图完成面向后端的编译优化,生成可供目标硬件执行的代码.
在Inductor内部实现中,一张图通常会依次经过以下几个阶段:
1. Lowering到Inductor IR: 将FX图lower为Inductor IR图,把上层算子图转换成更适合依赖分析、融合组织和后端生成的中间表示。
2. Schedule调度: 将Inductor IR图进一步降低抽象层次翻译成带有执行顺序的Kernel集合,且过程中会经过一系列的优化提升执行性能,最重要的优化就是决定哪些算子可以融合成一个Kernel.
3. Codegen目标代码生成: 根据Schdule输出的Kernel集合进行目标代码生成,产出可编译、可运行的Kernel源码和调用代码,并对接后续编译执行流程。
inductor与AutoFuse对接
AutoFuse扩展了inductor在NPU上的Codegen后端,通过将InductorLoopIR转换为AscIR,调用AutoFuse模块进行Schedule模板选择、UB复用与Tiling调优,生成高效的Ascend C Kernel实现。
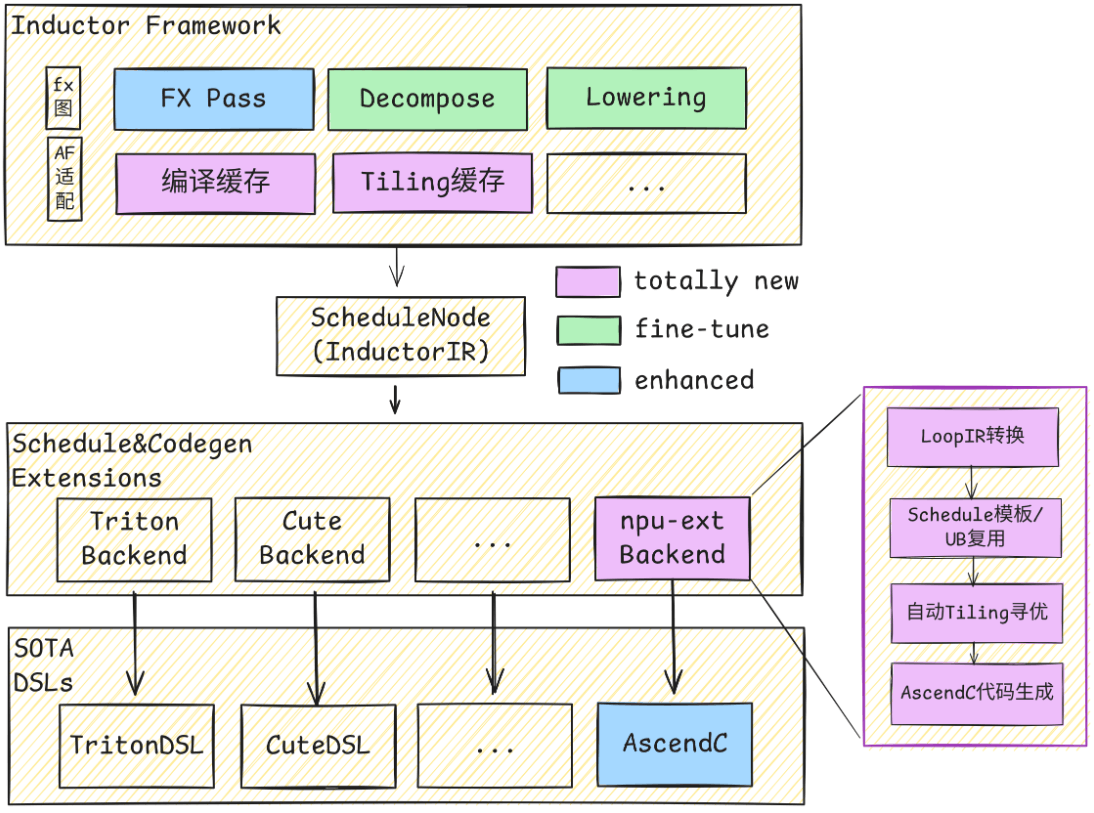
扩展实现参考:inductor_npu_ext源码地址
TorchInductor + AutoFuse 使用介绍
在脚本开头导入 inductor_npu_ext 以启用 inductor NPU 后端扩展。
python
import torch
import torch_npu
import inductor_npu_ext
@torch.compile
def test_add_sum(x, y):
"""
构造一个简单的计算逻辑:两个输入Tensor相加后对输出Tensor所有元素求和得到结果
不经过AutoFuse,add的输出结果可能要经历从AICORE的Local Memory搬运回Global Memmory,执行sum计算再搬回Local Memory的过程。经过AutoFuse融合,add输出结果可以缓存在Local Memory直接进行sum计算。
"""
return torch.add(x, y).sum()
x = torch.ones(32, 1024).npu()
y = torch.ones(1, 1024).npu()
out = test_add_sum(x, y)
print("out")TorchInductor + AutoFuse 使用实际收益
经过实际场景测试,在Atlas A3系列产品单卡部署DeepSeekV3.1-Terminus 模型吞吐经过TorchInductor+AutoFuse 优化后提升了 17% 。
| batchsize | Eager模式TPS | TorchInductor+AutoFuse TPS | 提升百分比 |
|---|---|---|---|
| 16 | 157.58 | 185.10 | 17% |
总结
基于TorchInductor与AutoFuse的对接,昇腾将PyTorch前端成熟的图编译能力与CANN后端的自动融合能力串联起来,形成了从Inductor IR到AscIR, 再到Ascend C代码生成的完整链路.这不仅降低了模型在昇腾侧进行算子融合优化的门槛,也让MoE、多模态等由大量细粒度算子组成的模型更容易获得稳定且可观的性能收益.
同时,AutoFuse作为开源模块,也在持续演进着自己的各项能力以提供更好的性能表现。开发者可以通过开源仓及时获取最新特性,并基于现有能力进一步验证和扩展面向昇腾NPU的自动融合方案.
AutoFuse源码地址: https://gitcode.com/cann/ge/tree/master/compiler/graph/optimize/autofuse