文章目录
- 前言
- 一、MinerU的API模式
- 二、如何调用API
-
- 1.注册、登录MinerU
- 2.申请API
- 3.写一个脚本文件调用API
-
- [3.1 一个调用API解析本地论文的脚本文件](#3.1 一个调用API解析本地论文的脚本文件)
- [3.2 转换结果](#3.2 转换结果)
- [4. 使用MCP server调用minerU API](#4. 使用MCP server调用minerU API)
-
- [4.1 一个调用API解析本地论文的脚本文件](#4.1 一个调用API解析本地论文的脚本文件)
- 总结
- 参考
前言
这两天在学习、复现一些论文,涉及到把本地文献喂给大模型。小红书科研之后发现,直接把pdf喂给大模型不仅很浪费token,而且DOC/DOCX/PDF 格式也不是机器可读的。因此快速将这些文档转换为机器可读格式是非常重要的。
MinerU是上海人工智能创新中心 OpenDataLab 推出的将 PDF 转换为机器可读格式(例如 markdown、JSON)的大模型,获得了一致好评。这篇博文记录了我使用调用API批量转换文档的过程。后期有时间的话会考虑把MinerU大模型部署到课题组的本地服务器。

一、MinerU的API模式
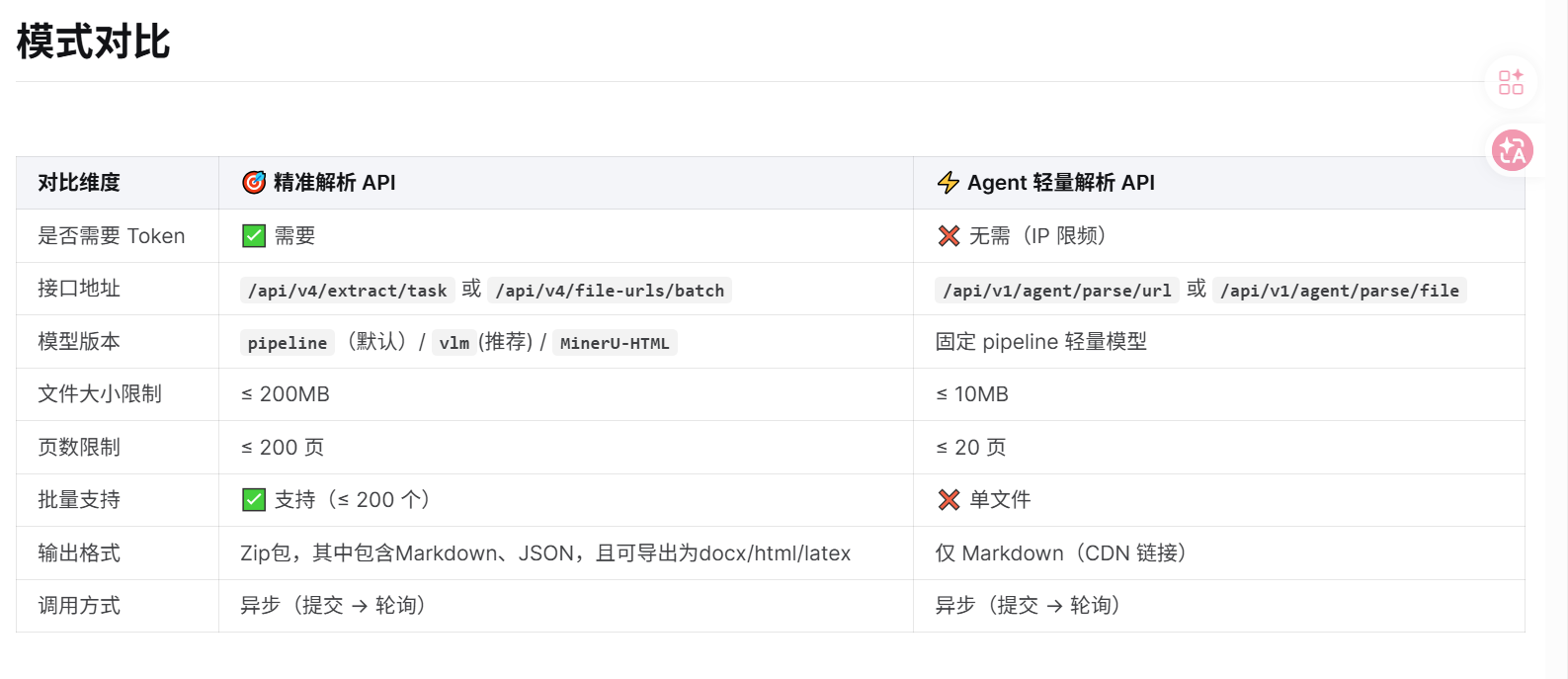
MinerU 提供两种文档解析 API,满足不同场景需求:
- 精准解析 API:需申请 Token,支持单文件/批量、表格/公式/多格式输出;
- Agent 轻量解析 API:免登录,IP 限频防滥用,专为 AI Agent 工作流设计
和我一样需要解析学术论文的朋友,建议选择精准解析 API。具体的MinerU API文档,请阅读官网说明:MinerU API文档。
二、如何调用API
1.注册、登录MinerU
首先进入MinerU官网,想获得精准解析 API,需要注册、登录。这里为了方便,我选择github账号登录。
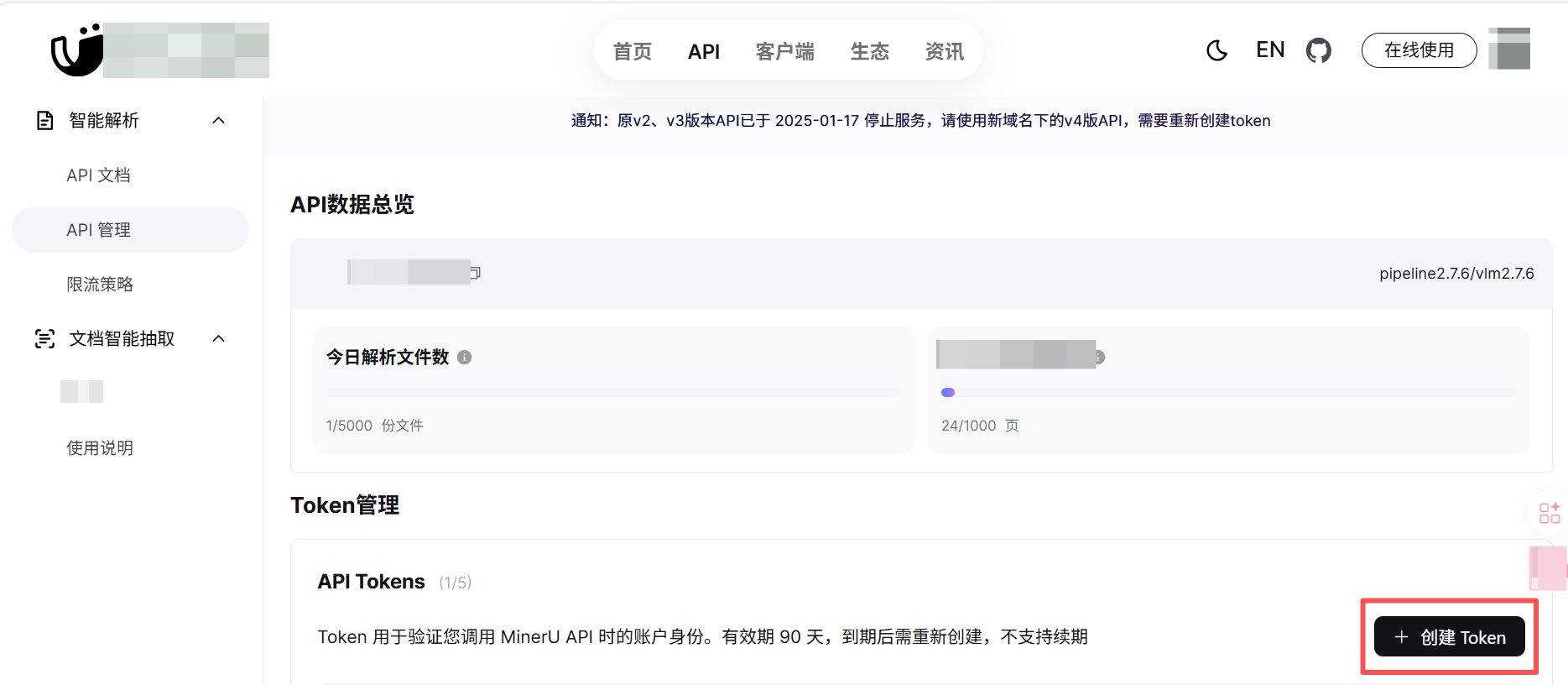
进入API管理界面
2.申请API
点击创建token
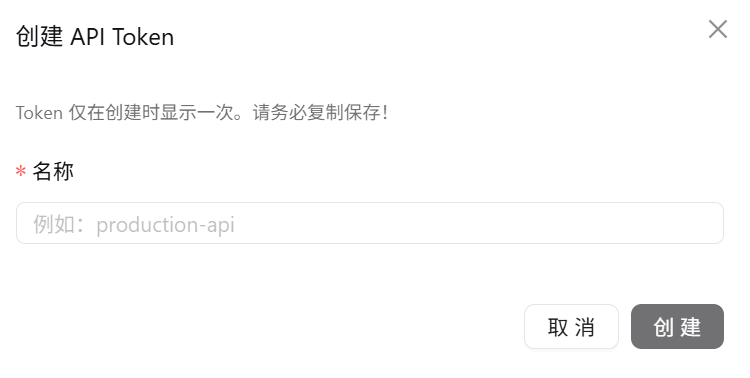
给自己的API取一个名字,注意保存好token。
3.写一个脚本文件调用API
这是从博主码里奥Ziho的视频里面学到的方法(PDF导入obsidian,打造本地知识库)。使用大模型帮我们写脚本文件,提示词为
帮我开发一个脚本,能够批量转换pdf成markdown,要求:需要 Token;接口地址为/api/v4/extract/task 或 /api/v4/file-urls/batch;模型版本为pipeline (默认)/vlm(推荐)/MinerU-HTML;文件大小限制≤ 200MB;页数限制≤200页;批量支持(≤200个);输出格式Zip包,其中包含Markdown、JSON,且可导出为docx/html/latex;调用方式是异步(提交>轮询)。我的api是xxxxxx (这里填我们刚才申请的api)。
等待片刻后,大模型会返回一个写好的脚本文件。但是根据我的实践过程,第一次写好的脚步存在各种各样的问题,需要调试几轮才可以正常使用。我遇到了需要安装pypdf包的问题。
bash
python -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pypdf3.1 一个调用API解析本地论文的脚本文件
下面介绍一下我使用的batch_pdf_to_markdown.py文件,给大家一个参考。我在项目根目录下面建立了一个tools文件夹,存放batch_pdf_to_markdown.py文件。
python
import http.client
import json
import os
import time
import urllib.error
import urllib.parse
import urllib.request
import zipfile
from pathlib import Path
BASE_URL = "https://mineru.net"
FILE_URLS_BATCH_ENDPOINT = "/api/v4/file-urls/batch"
URL_TASK_BATCH_ENDPOINT = "/api/v4/extract/task/batch"
BATCH_RESULTS_ENDPOINT = "/api/v4/extract-results/batch"
MAX_FILE_BYTES = 200 * 1024 * 1024
MAX_PDF_PAGES = 200
MAX_BATCH_FILES = 200
FINISHED_STATES = {"done", "failed"}
SUPPORTED_MODELS = {"pipeline", "vlm", "MinerU-HTML"}
SUPPORTED_EXPORT_FORMATS = {"docx", "html", "latex"}#可以转换的格式
def collect_pdf_paths(pdf_dir):
if not pdf_dir.exists():
raise FileNotFoundError(f"PDF 目录不存在: {pdf_dir}")
if not pdf_dir.is_dir():
raise NotADirectoryError(f"PDF_DIR 必须是目录: {pdf_dir}")
return sorted(
[path for path in pdf_dir.iterdir() if path.suffix.lower() == ".pdf"],
key=lambda path: path.name.casefold(),
)
def count_pdf_pages(pdf_path):
try:
from pypdf import PdfReader
except ModuleNotFoundError as exc:
raise RuntimeError("需要安装 pypdf 才能在上传前校验 PDF 页数: pip install pypdf") from exc
reader = PdfReader(str(pdf_path))
return len(reader.pages)
def validate_pdf_batch(pdf_paths):
if not pdf_paths:
raise ValueError("没有找到可上传的 PDF 文件。")
if len(pdf_paths) > MAX_BATCH_FILES:
raise ValueError(f"最多支持 200 个 PDF,当前数量: {len(pdf_paths)}")
for pdf_path in pdf_paths:
if not pdf_path.exists():
raise FileNotFoundError(f"PDF 文件不存在: {pdf_path}")
if pdf_path.suffix.lower() != ".pdf":
raise ValueError(f"只支持 PDF 文件: {pdf_path}")
file_size = pdf_path.stat().st_size
if file_size > MAX_FILE_BYTES:
raise ValueError(f"{pdf_path.name} 超过 200 MB: {file_size} bytes")
page_count = count_pdf_pages(pdf_path)
if page_count > MAX_PDF_PAGES:
raise ValueError(f"{pdf_path.name} 超过 200 页: {page_count} 页")
def validate_model_version(model_version):
if model_version not in SUPPORTED_MODELS:
raise ValueError(f"model_version 必须是 {sorted(SUPPORTED_MODELS)} 之一,当前: {model_version}")
def validate_export_formats(export_formats):
unknown_formats = set(export_formats) - SUPPORTED_EXPORT_FORMATS
if unknown_formats:
raise ValueError(f"extra_formats 只支持 docx/html/latex,当前不支持: {sorted(unknown_formats)}")
def build_extract_payload(
urls,
model_version,
export_formats,
enable_formula,
enable_table,
language="ch",
no_cache=False,
):
validate_model_version(model_version)
validate_export_formats(export_formats)
if len(urls) > MAX_BATCH_FILES:
raise ValueError(f"最多支持 200 个 URL,当前数量: {len(urls)}")
return {
"enable_formula": enable_formula,
"enable_table": enable_table,
"language": language,
"files": [{"url": url, "is_ocr": True, "data_id": f"{idx:04d}"} for idx, url in enumerate(urls, start=1)],
"model_version": model_version,
"extra_formats": list(export_formats),
"no_cache": no_cache,
}
def build_local_upload_payload(pdf_paths, model_version, export_formats, enable_formula, enable_table, language="ch"):
validate_model_version(model_version)
validate_export_formats(export_formats)
files = [
{"name": pdf_path.name, "data_id": f"{idx:04d}-{pdf_path.stem}", "is_ocr": True}
for idx, pdf_path in enumerate(pdf_paths, start=1)
]
return {
"enable_formula": enable_formula,
"enable_table": enable_table,
"language": language,
"files": files,
"model_version": model_version,
"extra_formats": list(export_formats),
}
def mineru_headers(token, include_content_type=True):
if not token:
raise RuntimeError("未设置 MINERU_API_TOKEN 环境变量。")
headers = {
"Authorization": f"Bearer {token}",
"Accept": "*/*",
}
if include_content_type:
headers["Content-Type"] = "application/json"
return headers
def load_env_value(env_path, key):
if not env_path.exists():
return None
for line_number, raw_line in enumerate(env_path.read_text(encoding="utf-8").splitlines(), start=1):
line = raw_line.strip()
if not line or line.startswith("#"):
continue
if "=" not in line:
raise ValueError(f"{env_path} 第 {line_number} 行格式错误,应为 KEY=VALUE。")
current_key, current_value = line.split("=", 1)
if current_key.strip() == key:
value = current_value.strip()
if (value.startswith('"') and value.endswith('"')) or (value.startswith("'") and value.endswith("'")):
value = value[1:-1]
return value
return None
def get_api_token():
'''
获取API
'''
return os.environ.get("MINERU_API_TOKEN") or load_env_value(Path(".env"), "MINERU_API_TOKEN")
def request_json(method, endpoint, token, payload=None, timeout_seconds=60):
url = urllib.parse.urljoin(BASE_URL, endpoint)
data = None
if payload is not None:
data = json.dumps(payload, ensure_ascii=False).encode("utf-8")
request = urllib.request.Request(
url,
data=data,
headers=mineru_headers(token, include_content_type=payload is not None),
method=method,
)
try:
with urllib.request.urlopen(request, timeout=timeout_seconds) as response:
response_body = response.read().decode("utf-8")
except urllib.error.HTTPError as exc:
error_body = exc.read().decode("utf-8", errors="replace")
raise RuntimeError(f"HTTP {exc.code} 请求失败: {url}\n{error_body}") from exc
return json.loads(response_body)
def ensure_success_response(response_json):
if response_json.get("code") != 0:
raise RuntimeError(f"MinerU API 返回错误: {response_json}")
return response_json
def request_local_upload_urls(pdf_paths, token, model_version, export_formats, enable_formula, enable_table, language):
payload = build_local_upload_payload(pdf_paths, model_version, export_formats, enable_formula, enable_table, language)
response_json = request_json("POST", FILE_URLS_BATCH_ENDPOINT, token, payload)
data = ensure_success_response(response_json)["data"]
upload_urls = data["file_urls"]
if len(upload_urls) != len(pdf_paths):
raise RuntimeError(f"上传 URL 数量和 PDF 数量不一致: {len(upload_urls)} != {len(pdf_paths)}")
return data["batch_id"], upload_urls
def submit_url_batch(urls, token, model_version, export_formats, enable_formula, enable_table, language, no_cache):
payload = build_extract_payload(urls, model_version, export_formats, enable_formula, enable_table, language, no_cache)
response_json = request_json("POST", URL_TASK_BATCH_ENDPOINT, token, payload)
return ensure_success_response(response_json)["data"]["batch_id"]
def upload_bytes_to_signed_url(upload_url, file_bytes):
parsed_url = urllib.parse.urlsplit(upload_url)
if parsed_url.scheme not in {"http", "https"}:
raise ValueError(f"签名上传 URL 必须是 http/https: {upload_url}")
if not parsed_url.netloc:
raise ValueError(f"签名上传 URL 缺少 host: {upload_url}")
path_with_query = urllib.parse.urlunsplit(("", "", parsed_url.path or "/", parsed_url.query, ""))
connection_cls = http.client.HTTPSConnection if parsed_url.scheme == "https" else http.client.HTTPConnection
connection = connection_cls(parsed_url.netloc, timeout=300)
try:
connection.request("PUT", path_with_query, body=file_bytes, headers={})
response = connection.getresponse()
response_body = response.read()
finally:
connection.close()
if response.status not in {200, 201, 204}:
error_body = response_body.decode("utf-8", errors="replace")
raise RuntimeError(f"签名 URL 上传失败,HTTP {response.status}: {error_body}")
def request_bytes_from_url(url, method, body=None, headers=None, timeout_seconds=300):
parsed_url = urllib.parse.urlsplit(url)
if parsed_url.scheme not in {"http", "https"}:
raise ValueError(f"URL 必须是 http/https: {url}")
if not parsed_url.netloc:
raise ValueError(f"URL 缺少 host: {url}")
path_with_query = urllib.parse.urlunsplit(("", "", parsed_url.path or "/", parsed_url.query, ""))
connection_cls = http.client.HTTPSConnection if parsed_url.scheme == "https" else http.client.HTTPConnection
connection = connection_cls(parsed_url.netloc, timeout=timeout_seconds)
try:
connection.request(method, path_with_query, body=body, headers=headers or {})
response = connection.getresponse()
response_body = response.read()
finally:
connection.close()
if response.status not in {200, 201, 204}:
error_body = response_body.decode("utf-8", errors="replace")
raise RuntimeError(f"{parsed_url.netloc} 请求失败,HTTP {response.status}: {error_body}")
return response_body
def download_bytes_from_url(url):
return request_bytes_from_url(url, "GET", headers={"Accept": "*/*"})
def upload_file_to_signed_url(pdf_path, upload_url):
try:
request_bytes_from_url(upload_url, "PUT", body=pdf_path.read_bytes(), headers={})
except RuntimeError as exc:
raise RuntimeError(f"{pdf_path.name} 上传失败: {exc}") from exc
def is_task_finished(state):
return state in FINISHED_STATES
def poll_batch_results(batch_id, token, poll_seconds, timeout_seconds):
deadline = time.monotonic() + timeout_seconds
endpoint = f"{BATCH_RESULTS_ENDPOINT}/{batch_id}"
while True:
response_json = request_json("GET", endpoint, token)
data = ensure_success_response(response_json)["data"]
extract_results = data.get("extract_result") or []
if extract_results and all(is_task_finished(result["state"]) for result in extract_results):
failed_results = [result for result in extract_results if result["state"] == "failed"]
if failed_results:
details = "\n".join(
f"{result.get('file_name')}: {result.get('err_msg', '未知错误')}"
for result in failed_results
)
raise RuntimeError(f"MinerU 解析失败:\n{details}")
return extract_results
if time.monotonic() >= deadline:
raise TimeoutError(f"等待 MinerU batch_id={batch_id} 超时。")
states = ", ".join(
f"{result.get('file_name')}={result.get('state')}" for result in extract_results
)
print(f"等待解析完成: {states or '尚无结果'}")
time.sleep(poll_seconds)
def download_file(url, output_path):
output_path.parent.mkdir(parents=True, exist_ok=True)
output_path.write_bytes(download_bytes_from_url(url))
def download_and_extract_results(extract_results, output_dir):
zip_dir = output_dir / "zip"
extracted_dir = output_dir / "extracted"
saved_zip_paths = []
for result in extract_results:
file_name = Path(result["file_name"]).stem
zip_url = result.get("full_zip_url")
if not zip_url:
raise RuntimeError(f"{result['file_name']} 缺少 full_zip_url,无法下载结果。")
zip_path = zip_dir / f"{file_name}.zip"
download_file(zip_url, zip_path)
saved_zip_paths.append(zip_path)
target_dir = extracted_dir / file_name
target_dir.mkdir(parents=True, exist_ok=True)
with zipfile.ZipFile(zip_path) as archive:
archive.extractall(target_dir)
return saved_zip_paths
if __name__ == "__main__":
PDF_DIR = Path("papers/raw_papers")
OUTPUT_DIR = Path("papers") / "mineru_outputs"
MODEL_VERSION = "vlm"#解析模型参数,官方推荐"vlm",解析精度最高
EXPORT_FORMATS = ["docx", "html", "latex"]#转换后的文件格式参数: 除了 MinerU 默认输出的 Markdown、JSON、ZIP 内容外,脚本还要求额外导出:docx, html, latex
ENABLE_FORMULA = True
ENABLE_TABLE = True
LANGUAGE = "ch" #语言参数: Chinese+English
POLL_SECONDS = 15
TIMEOUT_SECONDS = 60 * 60
api_token = get_api_token()
pdf_paths = collect_pdf_paths(PDF_DIR)
validate_pdf_batch(pdf_paths)
print(f"准备上传 {len(pdf_paths)} 个 PDF。")
batch_id, signed_upload_urls = request_local_upload_urls(
pdf_paths,
api_token,
MODEL_VERSION,
EXPORT_FORMATS,
ENABLE_FORMULA,
ENABLE_TABLE,
LANGUAGE,
)
print(f"batch_id: {batch_id}")
for current_pdf_path, signed_upload_url in zip(pdf_paths, signed_upload_urls):
print(f"上传: {current_pdf_path.name}")
upload_file_to_signed_url(current_pdf_path, signed_upload_url)
print("上传完成,开始轮询解析结果。")
completed_results = poll_batch_results(batch_id, api_token, POLL_SECONDS, TIMEOUT_SECONDS)
saved_zips = download_and_extract_results(completed_results, OUTPUT_DIR)
print("下载完成:")
for saved_zip in saved_zips:
print(saved_zip)这里面有4个核心参数,分别是language,is_ocr,model_version,extra_formats。详细解释可以查阅官方文档:核心参数详解及注意事项和官方教程:MinerU保姆级教程|全面掌握 MinerU 在线 API 调用。
因为我有把代码上传到github托管的习惯,我在项目根目录下的.vscode文件下编写了launch.json文件,在项目根目录下编写了.env文件,以防止API被 Git 跟踪。
①./.env文件:存放API
bash
MINERU_API_TOKEN=API②./.vscode/launch.json文件
json
{
"version": "0.2.0",
"configurations": [
{
"name": "Run MinerU Batch PDF",
"type": "python",
"request": "launch",
"program": "${workspaceFolder}/tools/batch_pdf_to_markdown.py",
"console": "integratedTerminal",
"envFile": "${workspaceFolder}/.env"
}
]
}3.2 转换结果
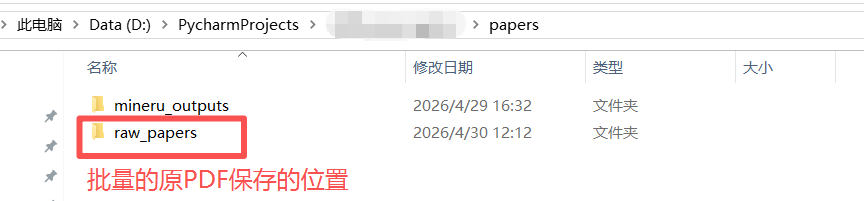

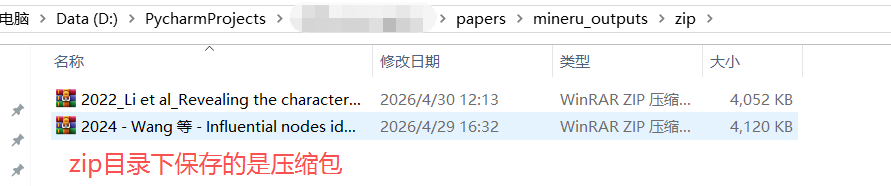
每篇论文单独保存在一个文件夹中,文件夹名称是原pdf名称
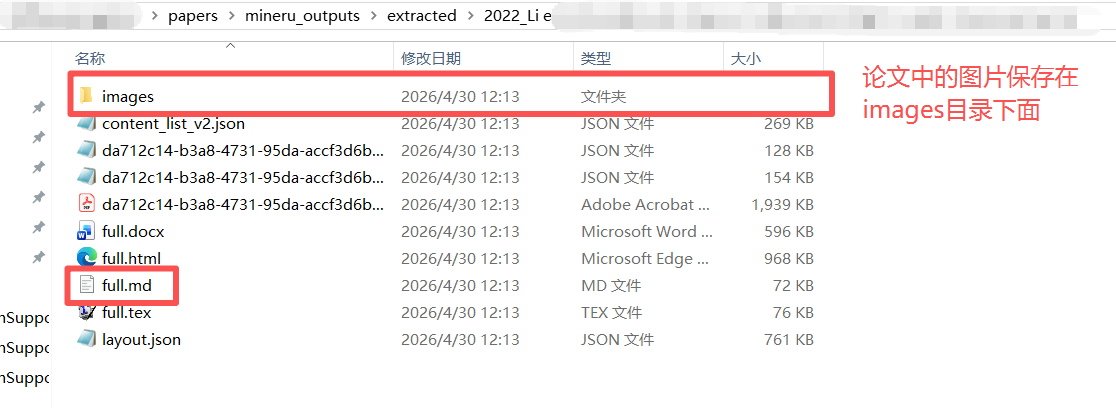
4. 使用MCP server调用minerU API
还有一种调用API的方式,把现在的batch_pdf_to_markdown.py 从"直接运行的脚本"改造成一个 MinerU MCP server ,让 cursor、Codex、claude code等AI agent通过 MCP 工具调用它。这样我们可以使用自然语言把PDF转换为markdown。例如,
用 MinerU 把 papers/raw_papers 里的 PDF 转成 Markdown,输出到 papers/mineru_outputs,模型用 vlm。
4.1 一个调用API解析本地论文的脚本文件
总结
今天介绍的是如何在一个脚本文件中调用API,解析本地论文(PDF格式),转换为机器可读的markdown文件。