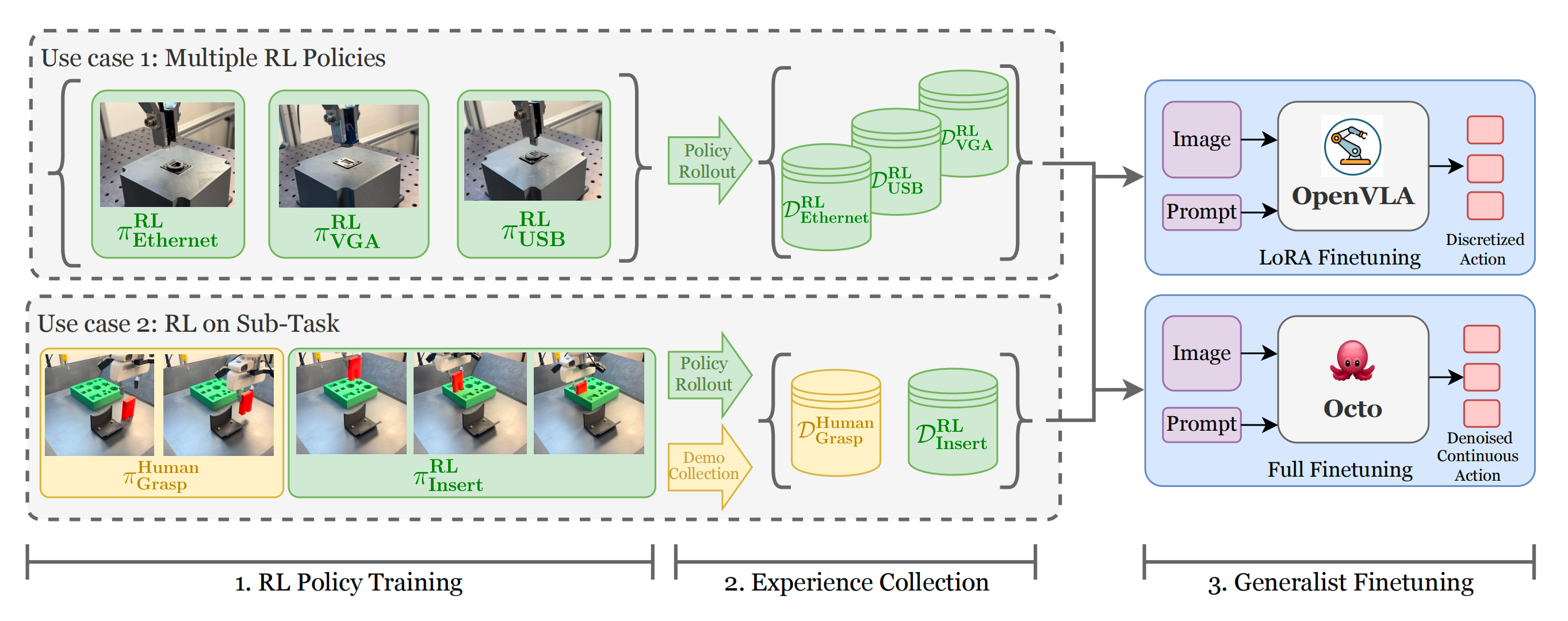
交互式模仿学习方法 *7-Hg-dagger: Interactive imitation learning with human experts* 可以在部署期间引入专家示范、纠正和干预,但它们主要将部署过程视为监督学习中动作标签的来源 因此,它们只利用了可用经验的一部分,而且缺乏一种有原则的机制来利用包含成功、失败、恢复、部分进展以及任务奖励等信息的自主试验
强化学习在原理上提供了这样一种机制,它通过任务结果和策略交互经验来优化策略行为 8-Q-learning
9-Addressing function approximation error in actor-critic methods
10-Continuous control with deep reinforcement learning
11-Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
然而,现有的机器人强化学习方法通常局限于小规模、短时程或任务特定的设定,并且经常是在一个预训练的通用策略基础上专门化到某个狭窄任务 12-Rl-100: Performant robotic manipulation with real-world reinforcement learning
13-Gr-rl: Going dexterous and precise for long-horizon robotic manipulation
14-Conrft: A reinforced fine-tuning method for vla models via consistency policy
包括 VLA-RL 18 和 RIPT 19,在模拟任务中的专用策略上取得了显著提升 31-Behavior-1k: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation
32-Maniskill: Generalizable manipulation skill benchmark with large-scale demonstrations
33-Libero: Benchmarking knowledge transfer for lifelong robot learning
34-Robotwin: Dual-arm robot benchmark with generative digital twins (early version)
20-πRL
35-Rlinf-user: A unified and extensible system for real-world online policy learning in embodied ai 36-Wovr: World models as reliable simulators for post-training vla policies with rl ------
然而,这些方法通常依赖于 on-policy 的数据收集方式,对于现实世界机器人而言,这种方式在样本利用上效率较低且成本较高 20-πRL, 37-Simplevla-rl: Scaling vla training via reinforcement learning**
39-Uni-o4: Unifying online and offline deep reinforcement learning with multi-step on-policy optimization
40-Offlineto-online reinforcement learning via balanced replay and pessimistic q-ensemble
12-Rl-100
14-Conrft
30-Rldg
41-Reincarnating reinforcement learning: Reusing prior computation to accelerate progress
42-Efficient online reinforcement learning with offline data,详见本博客中的解读《RLPD------利用离线数据实现高效的在线RL:不进行离线RL预训练,直接应用离策略方法SAC,在线学习时对称采样离线数据》
Luo 等人*16-SERL, 17-HIL-SERL* 利用少量人类示范来启动策略学习,并随后通过真实世界交互对单一机器人技能进行专门化
然而,LWD 与这一方法不同之处在于:它在多任务上对一个共享的通用 VLA 策略进行后训练,将离线与在线的回放统一在一个学习循环中,并在分布式、车队级部署环境下运行
近期研究采用不同的策略提取机制,在在线改进阶段重用离线数据 25-Q-learning with adjoint matching
43-Awac:Accelerating online reinforcement learning with offline datasets
44-Hybrid rl: Using both offline and online data can make rl efficient
45-Steering your diffusion policy with latent space reinforcement learning
24-Adjoint matching: Fine-tuning flow and diffusion generative models with memoryless stochastic optimal control,建立了 Adjoint Matching 的数学基础与生成模型应用