ChatGPT/智能体异常输出排查指南:从哥布林输出到 API 跑偏的全流程修复手册
基于 2026-04-29 至 2026-04-30 的 AI 热点,定位人格化异常、幻觉文书、代码代理编排失控与成本延迟波动
如果你最近遇到这三种场景:ChatGPT 回答突然像换了人格、代码智能体一本正经改错文件、API 请求不是慢就是贵还偶尔胡说八道,这篇文章的目标很直接:帮你先把问题归类,再拿到最小复现场景,最后决定到底该修 prompt、拆 agent,还是降级模型。
读完你应该能产出 3 样东西:
1)一份最小复现场景;
2)一份问题类型判断;
3)一套可上线的修复或兜底方案。
先别急着给模型驱邪,先给日志开灯。
工具资源导航
如果你看完这波热点,想顺手把方案跑起来或者把账号环境补齐,这两个入口可以先收藏:
文末资源导航属于工具信息整理,请结合平台规则和自身需求判断。
一、问题定义与适用范围
本文解决什么:
- ChatGPT / AI 助手出现异常语气、奇怪人格、答非所问
- 智能体或代码代理执行链路跑偏,尤其是多工具、多子代理场景
- API 调用出现高幻觉、延迟抖动、成本异常、偶发失败
- 需要为高风险输出补上人工复核和降级策略
本文不解决什么:
- 账号封禁、支付失败、区域网络不可达
- 具体法律结论、正式合规意见
- 某一家产品的内部实现细节
热点拆解:为什么这事值得现在排
事实描述:
- 2026-04-29,OpenAI 发布《Where the goblins came from》,解释所谓 goblin outputs 是如何扩散的,并给出 GPT-5 行为中 personality-driven quirks 的时间线、根因和修复思路。
- 2026-04-30,Cursor 推出 TypeScript SDK,支持开发者构建程序化代码代理,能力包括 sandboxed cloud VMs、subagents、hooks,以及 token-based pricing。
- 2026-04-30,TechCrunch 报道 AWS 云业务增长强劲,但资本支出也在持续上升,且短期还会继续投入。
- 2026-04-29,一则报道提到,AI 生成的错误法院文件问题"正在迅速升级",并收到法官层面的警告。
- 2026-04-29,TechCrunch 报道 Scout AI 获得 1 亿美元融资,用于训练可帮助士兵控制自主车辆编队的模型。
- 2026-04-30,另有报道指出,AI 数据使用激增,正在重塑经济活动。
观点分析:
这些新闻看起来像分散的热点,实际上都在说同一件事:AI 已经不只是"聊天框里会打字的模型",而是在进入代码执行、文档生成、流程编排,甚至高风险控制场景。以前 AI 发挥失常,最多是回复有点离谱;现在如果排查机制不完整,离谱的可能就是你的代码库、正式文书,或者业务流程本身。
趋势判断
事实描述: 4 月 29 日的 OpenAI 文章讨论的是模型行为异常;4 月 30 日的 Cursor SDK 新闻讨论的是代理编排能力;同日 AWS 与 AI 数据使用的报道,讨论的是底层资源压力与需求增长。
观点分析: 这意味着 2026 年的主流问题,已经从"模型会不会答"升级为"模型、编排、基础设施三层谁在出错"。排障方式也不能再只盯着 prompt,一定要分层看:模型层、工具层、资源层。
二、先判断问题类型
别一上来就改 20 版提示词。先判断你遇到的是哪一类:
- 风格/人格异常型:语气突变、口癖异常、莫名扮演某种角色,或者明明问技术问题却像在看角色设定集。
- 事实错误/幻觉型:内容流畅,但引用、日期、条款、文件名、代码路径是错的。
- 智能体编排故障型:主模型未必错,错的是 subagent、hook、工具调用顺序、沙箱环境状态。
- 资源与成本型:延迟飙升、超时增多、token 消耗异常、重试越来越多。
- 高风险越界型:本该人工确认的任务,被模型或代理直接闭环执行。
如果你连类型都没分清,后面的每一步都像在黑屋里修空调:听起来很努力,结果全靠运气。
三、高频原因清单(按风险和出现概率排序)

- 系统指令冲突
[高风险 / 高概率]- 多层 prompt 叠加、风格指令过重、历史模板互相打架,最容易把模型带偏。
- 上下文污染或历史残留
[高风险 / 高概率]- 旧对话、长期记忆、脏样本、缓存命中错误,都会让输出出现"不是这次的问题,却像这次的锅"。
- 多工具/子代理配置过深
[高风险 / 中高概率]- Cursor 这类 SDK 把能力做强了,但链路也变长了。链路一长,定位就不能再靠猜。
- 检索或输入源质量差
[高风险 / 中概率]- 输入本身有误,模型只是在高质量地复述低质量内容。
- 模型版本或默认参数漂移
[中风险 / 中高概率]- 同样的 prompt,换个版本、换组默认参数,输出边界可能就变了。
- 并发、限流、算力紧张
[中风险 / 中高概率]- 当 AI 数据使用激增、云资源投入持续拉高时,慢、贵、偶发失败会成为长期现象,不是某天心情不好。
四、可执行排查流程
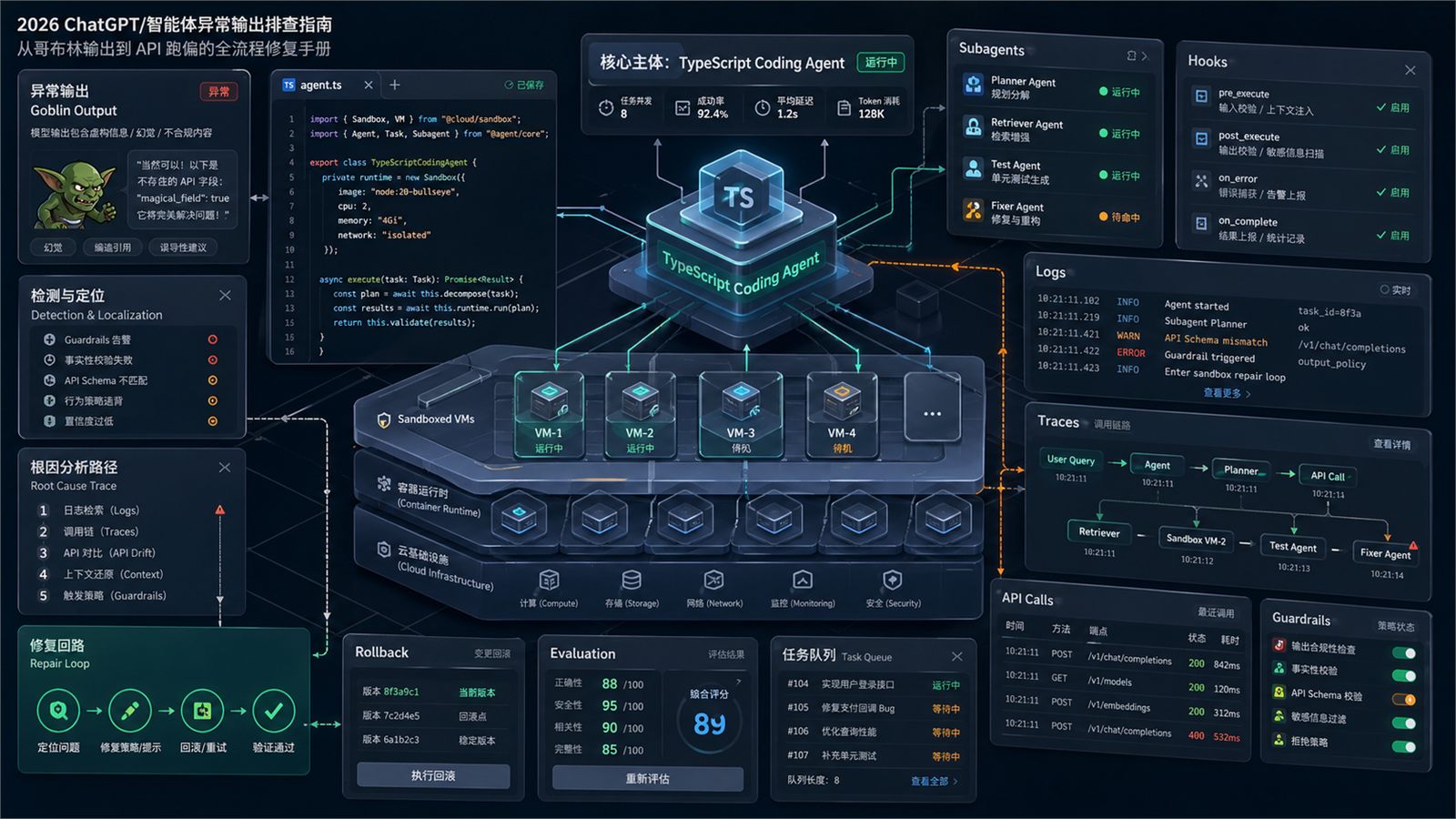
步骤 1:先固定最小复现场景
如何做:
- 新建一个全新会话或请求
- 只保留一个 system prompt
- 关闭 memory、tools、hooks、subagents
- 记录
model、版本、temperature、max_tokens、request id、耗时、token 消耗
预期结果:
如果异常消失,问题大概率不在"模型本体",而在上下文或编排层。
步骤 2:排查人格化异常
如何做:
- 清空历史上下文
- 删除明显风格化、角色化的指令
- 把温度参数降到更保守的水平,比如先用
temperature=0 - 用同一输入重复测试 3 次,看输出是否稳定
预期结果:
如果输出恢复正常,说明问题更像是行为被放大,类似 2026-04-29 OpenAI 所讨论的那类"人格化异常",而不是整个服务不可用。
步骤 3:排查幻觉与错误文书
如何做:
- 要求模型标出"结论来自输入的哪一段"
- 对引用、日期、数字、法条名、文件名做二次校验
- 法律、合同、财务、正式通知类内容必须加人工 review
预期结果:
你会很快区分两件事:它"写得像真的",和它"真的是真的"。这两件事,AI 很喜欢打包出售。
步骤 4:拆掉智能体编排层逐层回放
如何做:
对 Cursor 类代码代理或自建 agent,按下面顺序逐层恢复:
- 主模型单独运行
- 主模型 + 单工具
- 主模型 + 多工具
- 加入 subagents
- 最后再开 hooks 与沙箱云 VM
每一层都记录输入、输出和副作用,比如改了哪些文件、调用了哪些命令、是否跨目录写入。
预期结果:
你可以定位是模型回答错,还是某个 hook、子代理、沙箱环境把上下文或文件系统搞乱了。
步骤 5:排查资源、延迟与成本
如何做:
- 观察超时率、重试次数、队列长度、平均响应时间
- 对比正常请求与异常请求的 token 消耗
- 控制并发,缩短上下文,必要时做缓存或批处理
- 把"内容错误"和"调用失败"分成两条告警线
预期结果:
如果问题主要表现为慢、贵、偶发失败,而不是内容失真,那就更偏资源层问题。结合 2026-04-30 关于 AWS 支出持续增加和 AI 数据使用激增的报道,这类波动短期不会自动消失。
步骤 6:为高风险任务加人类闸门
如何做:
- 代码提交前加审批或至少 diff 审核
- 正式文书发出前做人审
- 外部通知、设备控制、批量删除、批量改写这类动作必须二次确认
预期结果:
即使模型偶发跑偏,也不会直接把事故送进生产。Scout AI 的新闻提醒我们:当 AI 开始接近"控制权",review 就不是礼貌,是刹车片。
步骤 7:做回归测试
如何做:
准备 10 到 20 条高频场景样例,覆盖正常问答、工具调用、长上下文、正式文书、代码修改等情况。每次换模型、改 prompt、升级 SDK 后都重跑。
预期结果:
避免"修好了 A,顺手把 B 修没了"。多智能体系统里,这种事并不罕见。
对开发者、技术运营和副业实践者的启发
- 开发者:先把最小复现、日志字段、回归集做好,再追求花哨的多 agent 架构。
- 技术运营:不要只看活跃用户和调用量,还要看失败率、人工复核率、单任务 token 成本。
- 副业实践者:Demo 可以惊艳,生产链路必须能回滚。否则今天是自动生成内容,明天就是自动生成事故复盘。
五、不建议做法

- 不要靠"再问一遍"掩盖异常,这只会把偶发问题变成随机问题。
- 不要把 system prompt 写成散文诗,越长不一定越稳,越可能互相打架。
- 不要同时开启 memory、tools、subagents、hooks 后再说"我也不知道哪坏了"。
- 不要把 429、超时、内容幻觉、工具调用失败混成一个 bug。
- 不要让 AI 在法律、财务、正式发布、高风险控制场景里无审查闭环运行。
六、常见问题速查(FAQ)
Q1:所谓"哥布林输出",是不是说明模型彻底不行了?
A:不一定。2026-04-29 OpenAI 自己就在解释这类现象的时间线、根因与修复方式,这更像是可定位、可修复的问题,而不是神秘事件。
Q2:代码 agent 出错,先改 prompt 还是先查工具?
A:先做最小复现。关掉 subagents、hooks、沙箱 VM 后如果恢复,优先查编排层;如果单模型就异常,再查 prompt、版本和参数。
Q3:为什么现在 AI 调用经常又慢又贵?
A:4 月 30 日的几条报道其实指向同一个背景:AI 数据使用在增长,云需求也在增长,底层资本投入还在继续。翻译成人话就是:资源压力是真实存在的,不能指望所有时段都丝滑如德芙。
Q4:为什么法律或正式文书要特别小心?
A:因为"写得像"不等于"引用对"。2026-04-29 的报道已经提醒,AI 生成错误法院文件的问题正在升级,这类场景必须保留人工复核。
Q5:什么时候该换模型,什么时候该改流程?
A:如果问题是语气漂移、版本行为变化,可以评估回退或切换模型;如果问题来自工具链、权限边界、审批缺失,那换模型通常只是换一种方式出错。
七、结语
2026 年这波信号已经很明确:一边是模型人格异常被公开拆解,另一边是代码代理 SDK、云投入和高风险自动化都在继续推进。对开发者来说,真正有价值的不是"谁最聪明"的口水战,而是一套能复现、能回滚、能审计的排查流程。
如果你今天只能做一件事,我建议是:先搭一份最小复现模板,并把日志字段补齐。 这比再堆一层 prompt 工程更能救命。
当 AI 像同事时,要协作;当 AI 像实习生时,要带教;当 AI 像哥布林时------先别吵,先抓日志。