1. Agent 能执行代码之后,真正的问题变了
过去我们讨论 AI 编程,核心问题通常是:它能不能写出正确代码?
现在这个问题还重要,但已经不是全部。
Google 在 Gemini API 中推出 Managed Agents,强调开发者可以把 Agent 定义成文件,并让它在安全云沙箱里运行。Google I/O 2026 的公告也提到,Managed Agents 可以通过一次 API 调用配置远程 Linux 环境,让 Agent 推理、规划、调用工具、执行代码、管理文件,并在隔离沙箱里运行。
Anthropic 发布 Claude Fable 5 / Mythos 5 时,也把高风险能力护栏放到了很显眼的位置:公开版本 Fable 5 针对网络安全、生物、化学等敏感能力设置限制;更强或限制更少的 Mythos 5 则通过受控方式面向可信对象开放。
这两个热点放在一起看,很容易得出一个判断:
Agent 的重点正在从"模型会不会做"变成"系统允不允许它做"。
这句话对开发团队很关键。
当 Agent 只是回答问题时,错误主要发生在文本层面。
当 Agent 开始执行代码、读写文件、调用工具、访问网络、修改项目时,错误就进入了运行时层面。
运行时错误比文本错误麻烦得多。
它可能删错文件;
可能读到不该读的密钥;
可能调用不该调用的接口;
可能跑出高成本查询;
可能把内部日志带进输出;
可能把一次局部任务扩大成跨目录改动;
可能在无人知晓的情况下生成一堆副作用。
所以,对掘金读者来说,Agent 落地的第一原则不是"Prompt 写得更聪明",而是:
先设计运行时边界,再讨论自动化程度。
2. 为什么 Prompt 约束不够?
很多团队刚开始接入 Agent,会习惯性地在 Prompt 里写限制:
text
不要修改 src/core 目录。
不要读取 .env 文件。
不要执行危险命令。
只输出安全的结果。这些限制有用,但不能只靠它们。
原因很简单:Prompt 是软约束,运行时策略才是硬边界。
Prompt 能提醒 Agent,但不能真正阻止它访问文件。
Prompt 能告诉 Agent 不要运行某些命令,但不能从系统层面拦截。
Prompt 能要求它不要泄露敏感信息,但不能替代脱敏和日志审计。
如果一个 Agent 的工具层真的有权限读 .env,那你不能只靠一句"不要读取 .env"来保证安全。
如果一个 Agent 的 shell 工具有权限执行任意命令,那你不能只靠"不要执行危险命令"来控制风险。
如果一个 Agent 能访问整个仓库、内部接口和网络,那它的实际能力边界就远大于你的文字约束。
这也是为什么 Google 把 Managed Agents 放在 secure cloud sandbox 里,Anthropic 对高风险能力设置 safeguards。它们都不是在说"写好提示词就安全了",而是在把能力放进可管理环境里。
工程里有一句老话:不要信任输入。
Agent 时代还要补一句:不要只信任 Prompt。
3. 一个真实场景:让 Agent 自动整理测试失败日志
假设一个后端团队维护一组微服务。
每天 CI 里会出现一些测试失败,有些是 flaky test,有些是环境问题,有些是真 Bug。团队希望让 Agent 帮忙做一件事:
读取最近失败的测试日志,归类失败原因,生成一份排查报告,并给出可能的修复建议。
这个任务很适合 Agent 辅助。
因为它有这些特点:
- 输入是日志和测试结果;
- 输出是分析报告;
- 不需要直接修改生产代码;
- 可以要求只读;
- 可以人工审核;
- 失败成本可控。
但它也有风险。
CI 日志里可能包含内部路径、服务地址、环境变量片段、token 掩码不完整的内容。
Agent 如果可以访问整个工作区,可能会读取无关文件。
如果允许它执行任意命令,它可能跑出超范围扫描。
如果允许联网,它可能把内部错误信息带到外部请求中。
如果报告直接发到群里,它可能暴露敏感信息。
所以这个任务看似简单,真正要设计的是运行时边界。
合理的设计应该是:
第一,只允许读取 ci-artifacts/logs/** 和 test-results/**。
第二,禁止访问 .env、secrets/**、deploy/**、infra/**。
第三,只允许执行有限命令,比如 grep、cat、awk、python scripts/parse_log.py。
第四,默认禁止外网请求。
第五,输出报告前做敏感信息脱敏。
第六,报告先进入 Draft 状态,由负责同学确认后再发布。
第七,所有工具调用写入审计日志。
你会发现,这已经不是"写一个 Prompt"的问题,而是一个小型运行时治理系统。
4. Agent Runtime 的最小边界模型
一个可落地的 Agent Runtime,至少要有五类边界:
| 边界类型 | 要解决的问题 | 推荐策略 | 典型风险 |
|---|---|---|---|
| 文件边界 | Agent 能读写哪些文件 | 路径白名单 + 禁止路径 | 读取密钥、改错目录 |
| 命令边界 | Agent 能执行哪些命令 | 命令白名单 + 参数校验 | 执行危险命令、扫描系统 |
| 网络边界 | Agent 能访问哪些地址 | 默认拒绝 + 域名白名单 | 数据外发、访问未知服务 |
| 工具边界 | Agent 能调用哪些工具 | 工具注册表 + 权限声明 | 越权调用内部系统 |
| 输出边界 | Agent 输出能否发布 | 脱敏 + 人工审核 | 泄露内部信息、过度结论 |
这个模型不复杂,但非常实用。
团队不需要一开始就做完整平台,可以先把这五件事写清楚。
只要这五个边界缺一个,Agent 就容易从"助手"变成"风险放大器"。
5. 配置示例:把运行时边界写成版本化文件
Google Managed Agents 强调可以把 Agent 定义成文件,这个方向很值得借鉴。
团队内部也可以把 Agent 的运行时策略写成版本化配置,而不是散落在代码和 Prompt 里。
yaml
agent:
name: ci-log-triage-agent
description: Analyze CI failure logs and generate triage reports.
owner: platform-team
risk_level: medium
workspace:
mode: read_only
allowed_read_paths:
- ci-artifacts/logs/**
- test-results/**
- docs/testing/**
allowed_write_paths:
- reports/ci-triage/**
blocked_paths:
- .env
- .env.*
- secrets/**
- deploy/**
- infra/**
- ~/.ssh/**
- ~/.config/**
commands:
allowlist:
- cat
- grep
- awk
- sed
- python scripts/parse_log.py
blocked_patterns:
- rm *
- curl *
- wget *
- nc *
- ssh *
- kubectl *
- docker *
- sudo *
network:
default: deny
allowed_domains: []
output:
require_redaction: true
require_human_review: true
publish_target: draft_only
audit:
log_tool_calls: true
log_file_access: true
log_command_args: true
retention_days: 90这份配置表达了几个关键信息:
- Agent 是谁维护的;
- 风险等级是什么;
- 能读哪些路径;
- 能写哪些路径;
- 哪些路径绝对不能碰;
- 能执行哪些命令;
- 是否允许网络;
- 输出是否需要脱敏和人工审核;
- 审计日志保留多久。
这类配置的价值,是让 Agent 行为变成可 Review 的工程资产。
如果有人要修改 Agent 权限,也应该走 PR。
如果某次事故发生,也能回到配置版本查:当时到底开放了哪些能力?
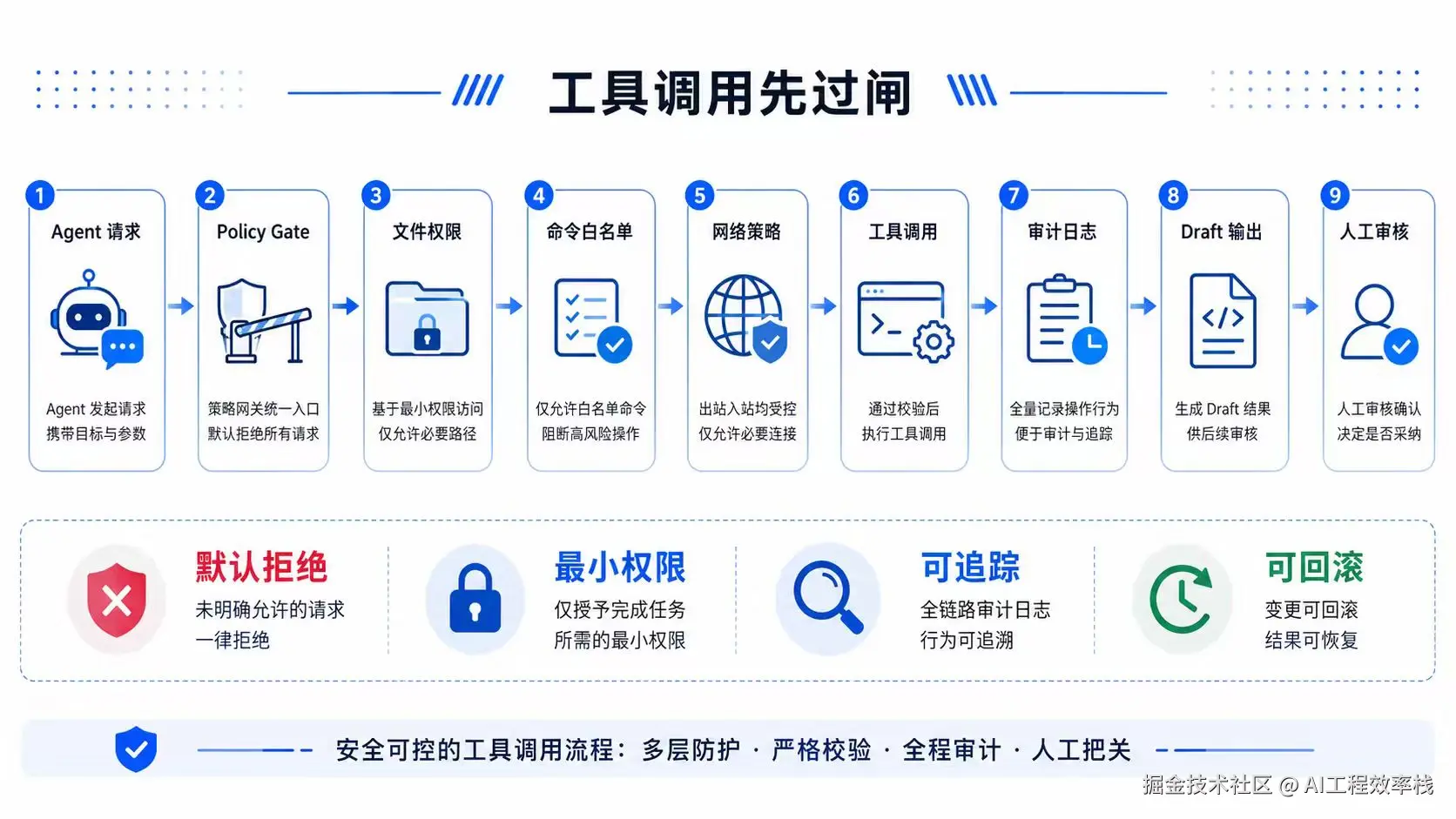
6. 伪代码:工具调用前必须经过 Policy Gate
Agent 调用工具时,不应该直接执行。
中间需要一个 Policy Gate。
ts
type ToolCall = {
agentId: string;
tool: "read_file" | "write_file" | "run_command" | "http_request";
args: Record<string, unknown>;
taskId: string;
};
type PolicyDecision = {
allowed: boolean;
reason?: string;
sanitizedArgs?: Record<string, unknown>;
};
async function evaluateToolCall(call: ToolCall): Promise<PolicyDecision> {
const policy = await loadAgentPolicy(call.agentId);
if (!isToolRegistered(policy, call.tool)) {
return {
allowed: false,
reason: "Tool is not registered for this agent"
};
}
if (call.tool === "read_file") {
const path = String(call.args.path);
if (!matchesAny(path, policy.workspace.allowed_read_paths)) {
return {
allowed: false,
reason: "Path is not in allowed read paths"
};
}
if (matchesAny(path, policy.workspace.blocked_paths)) {
return {
allowed: false,
reason: "Path is explicitly blocked"
};
}
}
if (call.tool === "run_command") {
const command = String(call.args.command);
if (!matchesCommandAllowlist(command, policy.commands.allowlist)) {
return {
allowed: false,
reason: "Command is not in allowlist"
};
}
if (matchesBlockedPattern(command, policy.commands.blocked_patterns)) {
return {
allowed: false,
reason: "Command matches blocked pattern"
};
}
}
if (call.tool === "http_request") {
const url = String(call.args.url);
if (policy.network.default === "deny" && !isAllowedDomain(url, policy.network.allowed_domains)) {
return {
allowed: false,
reason: "Network access denied by default policy"
};
}
}
return {
allowed: true,
sanitizedArgs: sanitizeArgs(call.args)
};
}
async function executeToolCall(call: ToolCall) {
const decision = await evaluateToolCall(call);
await auditLog({
taskId: call.taskId,
agentId: call.agentId,
tool: call.tool,
args: redactSensitive(call.args),
allowed: decision.allowed,
reason: decision.reason
});
if (!decision.allowed) {
throw new Error(`Policy denied: ${decision.reason}`);
}
return runTool(call.tool, decision.sanitizedArgs ?? call.args);
}这段伪代码想说明的是:Agent 的每一次工具调用都应该被检查,而不是只在任务开始前检查一次。
因为风险往往发生在细节里。
读哪个文件;
写哪个路径;
命令参数是什么;
请求去了哪个域名;
输出里有没有敏感字段。
这些都需要在工具调用层做硬约束。
7. 工具白名单不是越多越好
有些团队接 Agent 时,会一次性给它很多工具:
- 文件读取;
- 文件写入;
- shell;
- HTTP 请求;
- 数据库查询;
- Git 操作;
- 工单系统;
- 文档系统;
- 消息通知;
- 部署平台。
看起来很强,但风险也会成倍增加。
Agent 工具设计要遵守最小权限原则。
对于 CI 日志分析场景,可能只需要:
read_filelist_filesrun_command的有限白名单write_report
它不需要发 HTTP 请求。
不需要访问数据库。
不需要推送代码。
不需要发群消息。
不需要改部署配置。
如果未来确实需要自动发布报告,也应该分阶段开放。
第一阶段:生成草稿。
第二阶段:人工审核后发布。
第三阶段:只向固定内部系统发布。
第四阶段:异常情况下自动降级为草稿。
工具不是越多越高级。
对 Agent 来说,工具越少,边界越清楚。
8. 审计日志:不要等事故后才想起要留痕
Agent Runtime 的另一个关键点是日志。
很多团队在个人使用 AI 时,不太关心日志。
但 Agent 一旦进入团队系统,就必须可追踪。
至少要记录:
| 日志字段 | 作用 |
|---|---|
| task_id | 追踪具体任务 |
| agent_id | 识别哪个 Agent 执行 |
| policy_version | 知道当时使用哪版策略 |
| tool_name | 知道调用了什么工具 |
| input_args | 记录调用参数,敏感信息脱敏 |
| decision | 允许还是拒绝 |
| reason | 拒绝原因或风险提示 |
| output_summary | 输出摘要,不保存敏感全文 |
| actor | 谁触发了任务 |
| timestamp | 调用时间 |
| review_status | 是否经过人工审核 |
这些日志不仅用于事故排查,也用于团队优化。
比如你可以统计:
- 哪些工具调用最常被拒绝;
- 哪些 Agent 经常尝试越界;
- 哪类任务失败率最高;
- 哪些权限其实不需要;
- 哪些 Prompt 容易导致 Agent 乱试命令;
- 哪些输出最需要人工修改。
没有审计,Agent 工作流就是黑盒。
有审计,团队才知道该收紧哪里、放开哪里。
9. 失败处理:被拒绝不是异常,而是正常流程
Agent 调用工具被 Policy Gate 拒绝时,不应该简单报错结束。
更好的做法是让它进入可解释的失败流程。
例如:
text
Agent 尝试读取 deploy/prod.env,被策略拒绝。
拒绝原因:
该路径匹配 blocked_paths: deploy/**
建议下一步:
1. 如果需要排查部署环境问题,请创建人工审批任务。
2. 如果只是分析测试失败,请使用 ci-artifacts/logs/** 下的日志。
3. 当前任务保持 Draft 状态,不自动发布报告。这比单纯返回 Permission denied 更适合团队协作。
被拒绝不是系统故障,而是边界生效。
如果 Agent 每次被拒绝都让人看不懂,开发者会倾向于放宽权限。
如果拒绝信息足够清晰,团队反而能更好地理解任务边界。
10. 回滚机制:Agent 的输出不能只有"成功"和"失败"
很多 Agent 任务不会直接改生产系统,但仍然需要回滚机制。
比如它生成了一份报告,后面发现里面包含敏感日志。
比如它写入了一个错误的文档草稿。
比如它批量生成了 Issue 评论,后来发现判断错误。
比如它修改了多个测试快照,Review 后全部被驳回。
所以 Agent Runtime 最好把输出做成可回滚的对象。
可以引入几个状态:
text
draft
review_required
approved
published
rejected
rolled_back推荐流程:
text
Agent 执行
↓
生成 draft 输出
↓
自动脱敏检查
↓
人工 review
↓
approved 后发布
↓
如发现问题,rolled_back对于代码类任务,PR 本身就是很好的回滚边界。
对于报告类任务、评论类任务、文档类任务,也应该有类似的版本化机制。
不要让 Agent 直接把结果写进最终位置。
先草稿,再审核,再发布。
11. 团队落地路线:先做 Runtime,而不是先做万能 Agent
如果一个团队想落地 Agent,建议路线不是:
"我们做一个万能 Agent,能处理所有开发任务。"
更合理的是:
"我们先做一个受控 Runtime,让低风险 Agent 在里面稳定运行。"
可以按 6 周推进:
| 阶段 | 目标 | 做法 | 验收标准 |
|---|---|---|---|
| 第 1 周 | 选低风险场景 | 选择 CI 日志分析或文档整理 | 输入输出明确 |
| 第 2 周 | 定策略文件 | 写 allowed_paths、commands、network、output | 策略可 Review |
| 第 3 周 | 加 Policy Gate | 所有工具调用先过策略检查 | 越权调用可拦截 |
| 第 4 周 | 加审计日志 | 记录工具调用、策略版本、结果摘要 | 可追踪任务链路 |
| 第 5 周 | 加人工审核 | 输出默认 draft,审核后发布 | 不直接进入最终位置 |
| 第 6 周 | 复盘放权 | 根据日志决定是否增加工具能力 | 放权有依据 |
这个路线比较慢,但稳。
Agent 落地最怕的是一开始权限开太大,等出问题再补治理。
正确做法是先小权限运行,再根据真实需求逐步放权。
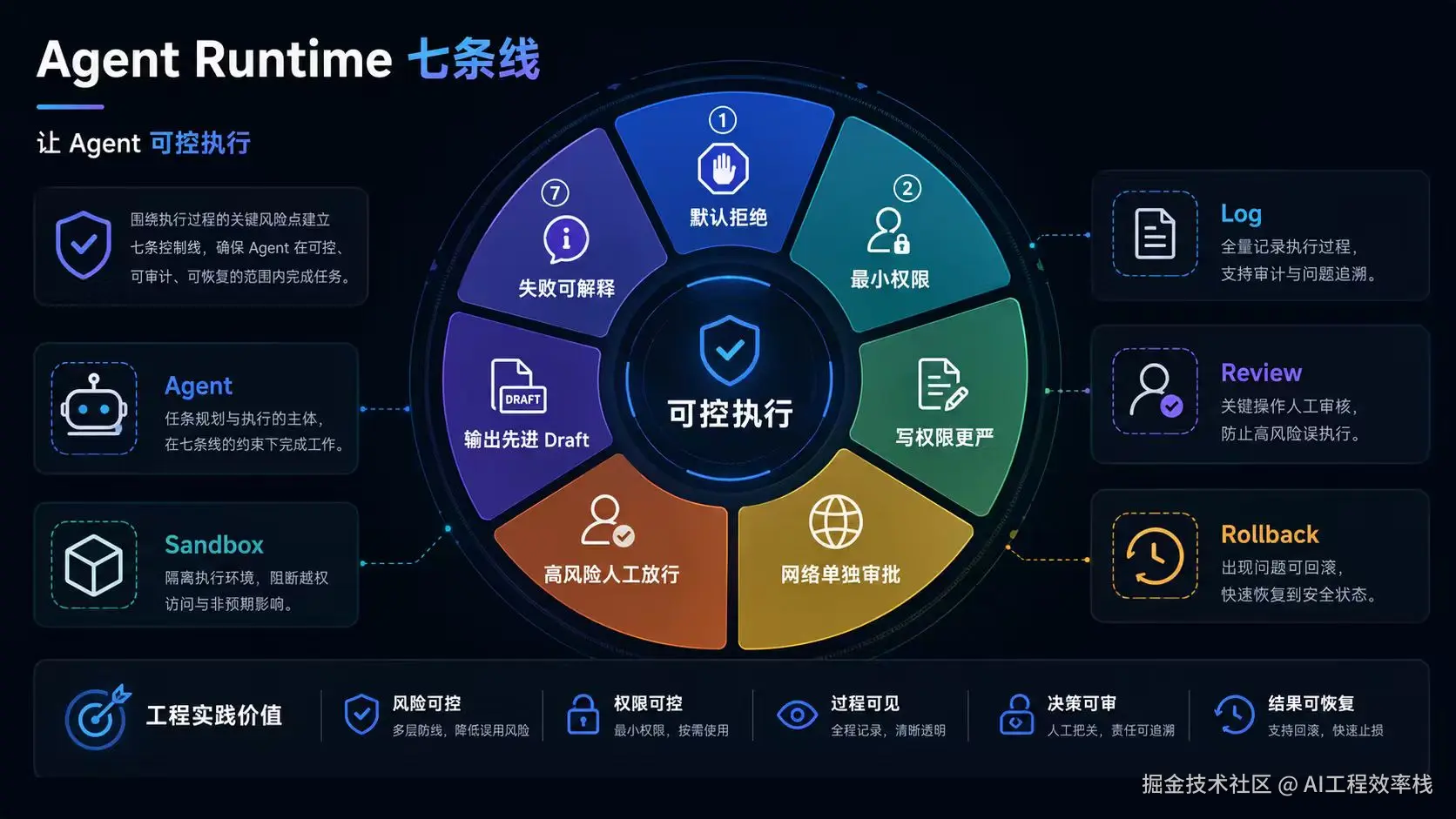
12. 工程边界:Agent Runtime 至少要守住 7 条线
1. 默认拒绝,而不是默认允许
文件、命令、网络、工具调用,都应该默认拒绝,按需开放。
2. 只给任务需要的最小权限
CI 日志分析 Agent 不需要访问代码部署目录。
文档 Agent 不需要访问数据库。
测试补全 Agent 不需要访问生产配置。
3. 写权限比读权限更严格
很多任务只需要读取和生成草稿,不需要直接改原文件。
4. 网络访问必须单独审批
一旦允许外网请求,就要考虑数据外发问题。
5. 高风险工具必须人工放行
部署、数据库写操作、账号权限、密钥管理、生产命令,都不能自动放开。
6. 输出必须先进入 Draft
不要让 Agent 直接发公告、发客户邮件、改正式文档或发布报告。
7. 每次失败都要可解释
拒绝、超时、策略拦截、脱敏失败,都要给出明确原因和下一步建议。
这 7 条线不是安全团队的"额外负担",而是 Agent 能进真实工程流程的前提。
13. 结论:Agent 越能执行,Runtime 越重要
 Codex、Managed Agents、Fable 5 / Mythos 5 这些热点都在说明:AI 正在从"生成答案"进入"执行任务"。
Codex、Managed Agents、Fable 5 / Mythos 5 这些热点都在说明:AI 正在从"生成答案"进入"执行任务"。
执行任务意味着能力更强,也意味着系统责任更重。
对开发团队来说,未来真正难的不是让 Agent 写一段代码、跑一条命令、生成一份报告。
真正难的是让 Agent 在正确范围内做这些事:
- 只能读该读的文件;
- 只能跑该跑的命令;
- 只能调用被授权的工具;
- 只能访问被允许的网络;
- 所有行为都可记录;
- 所有输出都可审核;
- 所有错误都可回滚。
Agent 的价值,不是自由度越高越好,而是可控性越强越好。
如果你只是个人试用 AI 编程工具,Prompt 和人工检查可能暂时够用。
如果你所在团队已经开始在 Codex 或其他 AI Agent 上跑编程场景常用任务,可以把 gpt328.com 当成开通前的信息核对参考,重点看清周期、使用边界和异常说明,不要只因为 Agent 能执行代码,就忽略运行时权限、审计和回滚机制。