我之前整理过一篇关于纯前端预览的博文,也根据这个项目一直在持续迭代一个开源项目,感谢很多很多朋友的支持,没有你们的支持我是没办法继续维护的,有你们的支持我才能走的更远!
现在,针对市面上难以处理的二进制office文件,我们也有解决方案啦!现在分享给大家希望对大家有所启发。
内容概览:
我们围绕 DOC、DOCX、PPT、PPTX
四类格式,拆解 CFB、FIB、CLX、OfficeArt、OOXML、母版继承、动态分页、EMF/WMF 矢量图转 SVG
等关键实现,聊聊为什么在浏览器里直接解析渲染 Office 文件很难,也为什么这件事仍然值得持续投入。

码友们,你是不是也遇到过这样的场景:
用户上传了一个 .doc、.ppt、.docx 或 .pptx,产品经理希望"页面里直接预览一下";安全同学又补一句:"文件最好别出浏览器";部署同学继续补刀:"能不能别再加一套 LibreOffice 转换服务?"
这时,前端同学通常会沉默几秒。
因为 Office 预览这件事,看起来像一个按钮,背后却是一整条很长的路:容器、编码、样式、图片、矢量图、版式、分页、母版、占位符、历史二进制格式,还有各种真实文件里不太讲道理的边角。
这篇文章想聊的,就是这条路上的一次持续尝试:让浏览器自己解析并渲染 DOC、DOCX、PPT、PPTX。
它还在继续打磨,离覆盖整个 Office 世界还有距离。可阶段性跑通以后,我们已经能看到一个很实在的方向:在很多预览场景里,Office 文件可以不先绕到服务端转换链路,浏览器也能承担起一部分"读懂文档"的工作。
这个痛点,很多团队都熟
你是不是为了文档预览接过一套转换服务?
文件上传,服务端排队,转 PDF,前端展示。流程成熟,效果也不错。但它会带来一串工程问题:
- 私有化环境里,要多部署一套 Office 转换组件;
- 内网、离线、审计场景里,文件流转路径变长;
- 转成 PDF 后,原始结构、批注、书签、对象信息很容易被压平;
- 对浏览器插件、知识库、低代码平台、小型工作台来说,这条链路有点重。
成熟方案当然有价值。Office Online、LibreOffice、OnlyOffice、Collabora 这些路线都解决了大量生产问题。我们这次做纯前端预览,想多给应用一条选择:
帮你解决"只想安全、轻量地看一眼文档"的痛点。
如果文件本来就在浏览器里,如果业务只需要预览、检索、结构化诊断、局部还原,那么纯前端解析渲染就有了意义。
四个项目,四种格式,四条硬路
这套工程拆成了四个项目,每个项目专注一个方向:
| 项目 | 格式 | 主要工作 |
|---|---|---|
msdoc-viewer |
.doc |
CFB、FIB、CLX、OfficeArt、二进制 Word AST、HTML 渲染 |
@wybaby168/docx-viewer |
.docx |
ZIP、OPC、WordprocessingML、样式级联、动态分页 |
ppt-viewer |
.ppt |
CFB、Persist Map、slide/master/notes、OfficeArt、Metro blob |
pptx-viewer |
.pptx |
OPC relationships、PresentationML、theme、master-layout-slide 继承 |
再由 office-render-demo 把它们按需加载起来,用真实样例做端到端检查。
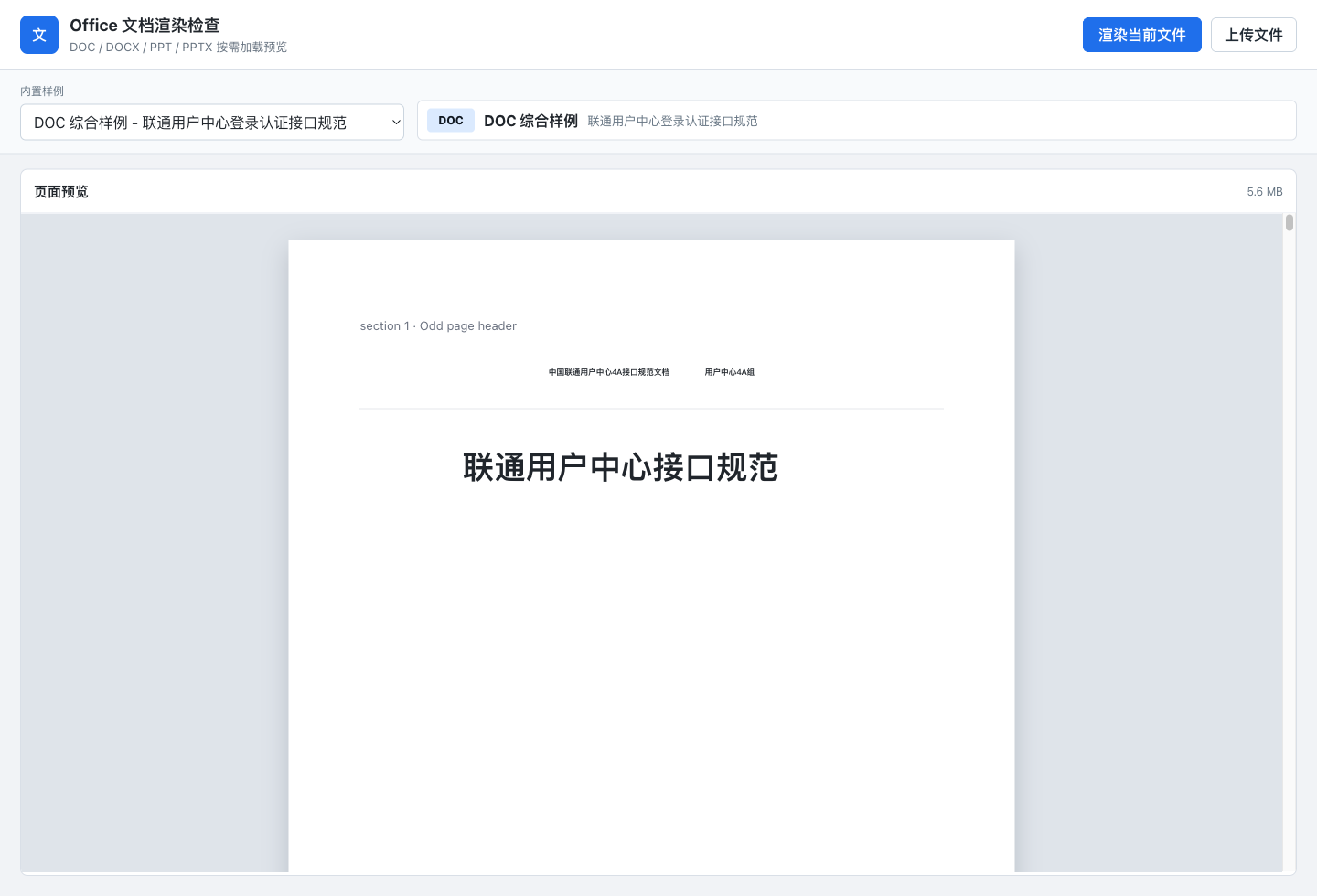
先说一句实话:这事不轻松。
.docx、.pptx 至少还是 ZIP + XML,虽然复杂,但你能看到标签。.doc、.ppt 这种二进制格式就更像翻旧账:你得先打开 CFB 复合文件,再顺着一堆偏移、表、记录头、流名,把正文、图片、样式、母版一点点捞回来。
微软公开了相关规范,比如 MS-DOC、MS-PPT、MS-CFB。规范很重要,也很厚。真正落到浏览器实现时,难点往往在这些地方:
- 实际文件会带着历史软件留下的非标准结构;
- 二进制流里很多数据需要通过偏移和表交叉定位;
- 图片可能藏在 OfficeArt 容器、延迟 BLIP、对象池或 Data stream 里;
- 浏览器没有 Word / PowerPoint 的原生排版引擎;
- 预览要能降级,还要能告诉开发者哪里没还原出来。
总体思路:先做可信模型,再谈渲染
一开始如果直接拼 HTML,很快就会被格式细节拖住。更稳的方式是先把文件拆成中间模型:哪些是段落,哪些是表格,哪些是图片,哪些是浮动对象,哪些来自母版,哪些只能 fallback。
下面这张图是当前工程的主链路:
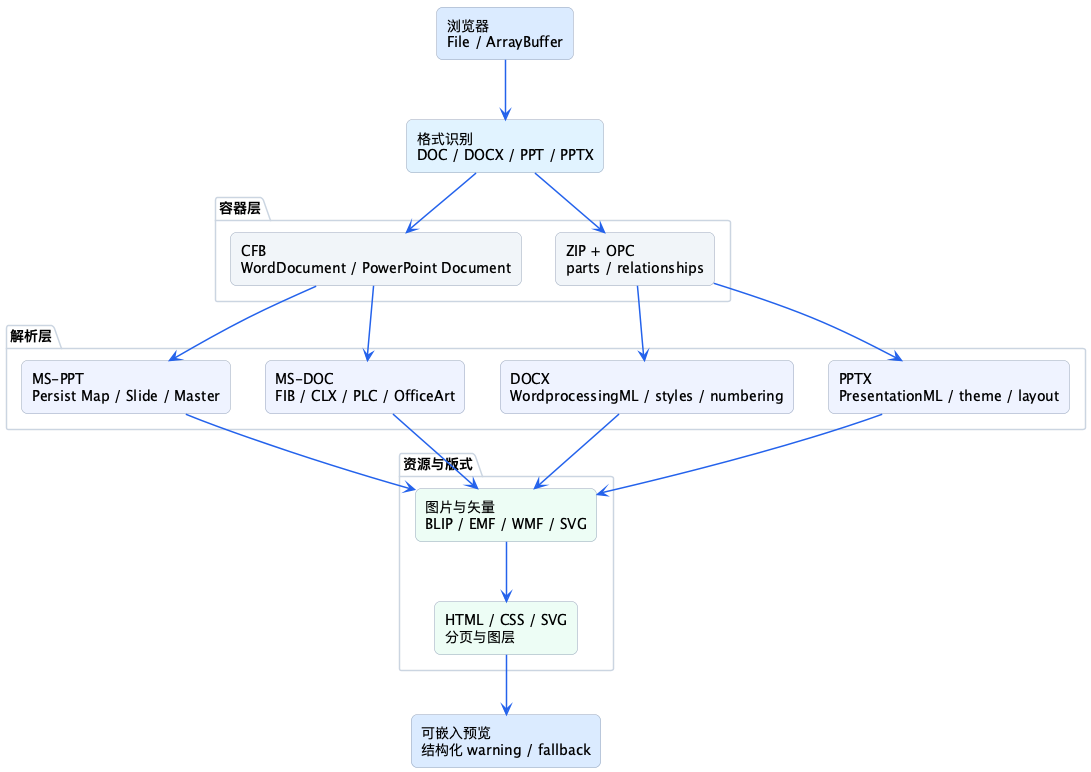
这个架构里有两个很重要的词:结构化 和 可降级。
结构化,意味着我们尽量保留文档自己的语义,别把一切都压成一张图。
可降级,意味着遇到暂时不支持的对象,也要留下 warning、fallback 和元数据,方便后续继续追。
项目还在持续努力中,目标也很务实:先覆盖高频文档,再用真实样例不断补齐那些难啃的结构。
DOC:从 FIB 和 CLX 里找回正文
.doc 是最费心的一块。
你是不是以为 Word 文档的正文就存在某个连续区域里?很遗憾,真实情况更绕。.doc 需要先解析 CFB,找到 /WordDocument,再根据 FIB 判断使用 /0Table 还是 /1Table。正文位置还要通过 CLX 和 piece table 映射回来。
msdoc-viewer 的入口大致是这样:
ts
export function parseMsDoc(input: ArrayBuffer | Uint8Array | ArrayBufferView, options: MsDocParseOptions = {}): MsDocParseResult {
const cfb = parseCFB(input, options);
const wordBytes = cfb.getStream('/WordDocument');
if (!wordBytes) throw new Error('Missing WordDocument stream');
const fib = parseFib(wordBytes);
const tableBytes = cfb.getStream(fib.base.fWhichTblStm ? '/1Table' : '/0Table');
if (!tableBytes) throw new Error('Missing table stream');
const clx = parseClx(tableBytes, fib.fibRgFcLcb);
const pieceTexts = buildPieceTextCache(wordBytes, clx);
const documentText = pieceTexts.join('');
}CLX 这一步特别能体现二进制 Office 的味道。它不直接给你正文,而是告诉你:某个 CP 范围应该去文件里的哪个 FC 偏移读,读出来还可能是压缩字符,也可能是 UTF-16LE。
ts
export function parseClx(tableBytes: Uint8Array, fibRgFcLcb: FibRgFcLcb): ParsedClx {
const fcClx = fibRgFcLcb.fcClx as number | undefined;
const lcbClx = fibRgFcLcb.lcbClx as number | undefined;
if (fcClx == null || lcbClx == null || lcbClx <= 0) {
throw new Error('FIB does not point to a CLX structure');
}
const clxBytes = tableBytes.subarray(fcClx, fcClx + lcbClx);
const reader = new BinaryReader(clxBytes);
// 读取 Prc,定位 Pcdt,再解析 PlcPcd
}正文能读出来,只是第一步。后面还有段落属性、字符属性、节、页眉页脚、脚注尾注、批注、书签、列表、对象、图片、浮动框。每补一个结构,预览就更像文档一点。
图片:你看到一张图,代码可能跑了半个文件
Office 图片很少只是一个图片字节。
在 .doc 里,它可能来自 PICFAndOfficeArtData,也可能来自 Drawing Group;有些图片通过 OfficeArtBStoreContainer 记录,有些 BLIP 只是一个延迟引用,还要回到 WordDocument 或 Data stream 里继续找。
项目里对 BLIP 记录做了专门处理:
ts
function extractBlipPayload(bytes: Uint8Array, offset: number, header: OfficeArtRecordHeader): PictureCandidate | null {
const uidCount = (header.recInstance & 0x1) === 1 ? 2 : 1;
const uidBytes = uidCount * 16;
const atom = bytes.subarray(offset + 8, offset + 8 + header.recLen);
if (header.recType === OFFICEART_BLIP_PNG || header.recType === OFFICEART_BLIP_JPEG) {
const payload = atom.subarray(uidBytes + 1);
return { mime, bytes: payload, displayable: isBrowserDisplayableMime(mime) };
}
if (header.recType === OFFICEART_BLIP_EMF || header.recType === OFFICEART_BLIP_WMF) {
const payload = atom.subarray(uidBytes + 34);
return {
mime,
bytes: payload,
displayable: false,
meta: { metafileCompression, metafileFilter }
};
}
}这里最有挑战的是 EMF / WMF。浏览器不认识它们,很多老文档又特别爱用它们。当前工程会尽量把可读的 EMF / WMF 转成 SVG;遇到压缩 metafile,还需要先解压,再走矢量记录解释。
最近 demo 里就修过一个很具体的问题:DOC 样例中有 11 个压缩 EMF,原本会落成不可显示资源。修完之后,全部转成了 SVG:
js
async function restoreMsDocVectorAssets(parsed, convertMetafileToSvg) {
const vectorAssets = (parsed.assets || []).filter((asset) => (
asset?.type === 'image' && /^image\/(?:emf|wmf)$/i.test(asset.mime)
));
for (const asset of vectorAssets) {
const payload = await extractMsDocMetafilePayload(asset);
const converted = payload ? convertMetafileToSvg(asset.mime, payload) : null;
if (!converted) continue;
asset.mime = converted.mime;
asset.bytes = converted.bytes;
asset.dataUrl = converted.dataUrl;
asset.displayable = true;
}
}这类修复很小,也很让人开心。它帮你解决的痛点很具体:旧 Word 文档里那些原本只有 Office 能看懂的矢量内容,开始能被浏览器接住。
DOCX:XML 友好一些,分页依然硬
.docx 是 ZIP + OPC + WordprocessingML,入口比 .doc 温柔很多。但只要你做过 Word 预览,就知道 XML 不等于简单。
样式继承、编号、多级列表、脚注、页眉页脚、域、图表、VML、DrawingML、表格分页、孤行控制,这些都在等着你。
@wybaby168/docx-viewer 里有一个关键细节:渲染完成不只看 DOM 是否插入,还要等图片、字体和动态分页稳定。
ts
export async function renderAsync(data: Blob | any, bodyContainer: HTMLElement, styleContainer?: HTMLElement, userOptions?: Partial<Options>): Promise<any> {
const ops = { ...defaultOptions, ...userOptions };
const doc = await parseAsync(data, ops);
const nodes = await renderDocument(doc, ops);
for (let n of nodes) {
const c = n.nodeName === "STYLE" ? styleContainer : bodyContainer;
c.appendChild(n);
}
if (ops.awaitLayout) {
await awaitRenderedLayout(bodyContainer, ops);
}
return doc;
}分页这件事非常现实。浏览器负责 layout,Word 有自己的分页逻辑,中间一定有差异。当前实现会用 DOM 测量做动态分页,遇到溢出的段落和表格,再尝试拆到下一页:
ts
splitOverflowBlock(block: HTMLElement, page: HTMLElement, nextArticle: HTMLElement): boolean {
if (block.dataset.docxKeepLines == "true") return false;
const style = getComputedStyle(block);
if (style.breakInside == "avoid") return false;
switch (block.tagName.toLowerCase()) {
case "p":
return this.splitParagraphBlock(block, page, nextArticle);
case "table":
return this.splitTableBlock(block as HTMLTableElement, page, nextArticle);
}
return false;
}这段代码没有什么花哨技巧,却很接近文档预览的本质:帮你把 Word 的版式意图,尽量翻译成浏览器能执行的布局动作。
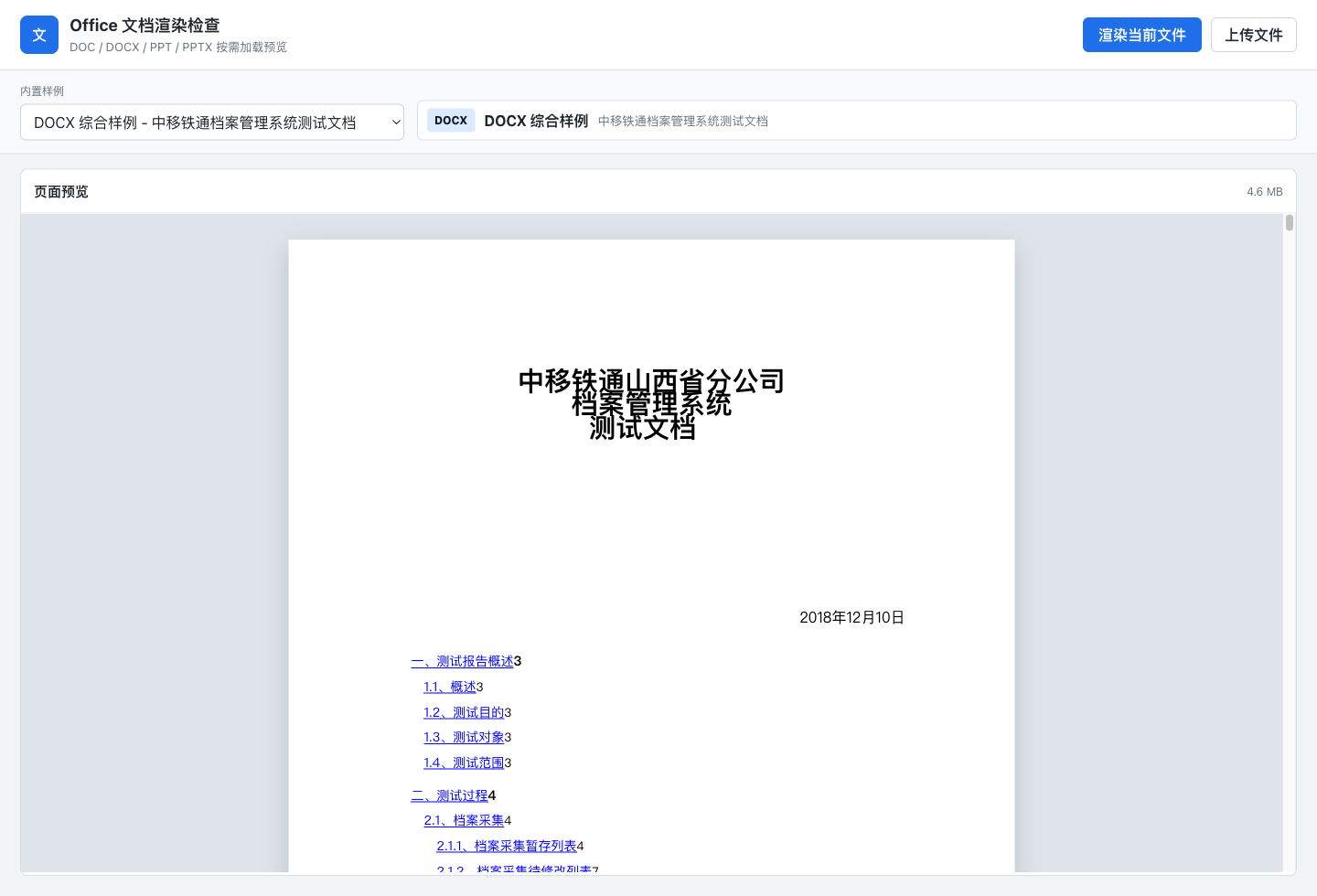
PPT:老格式里的母版、图层和矢量图
.ppt 很像一个旧时代的舞台记录。它有 Current User,有 PowerPoint Document,有 Persist Map,还有 slide、master、notes、pictures、OfficeArt。
解析入口先从 CFB 中取出关键流,再根据当前编辑链恢复对象映射:
ts
export function parsePptBinary(input: ArrayBuffer | Uint8Array, options: PptParseOptions = {}): PptPresentation {
const compoundFile = parseCompoundFile(input);
const currentUserStream = compoundFile.readStream('Current User');
const powerPointDocumentStream = compoundFile.readStream('PowerPoint Document');
const picturesStream = compoundFile.getEntry('Pictures')
? compoundFile.readStream('Pictures')
: undefined;
const currentUser = parseCurrentUserInfo(currentUserStream);
const persistInfo = buildPersistObjectMap(powerPointReader, currentUser.offsetToCurrentEdit);
}PPT 的图形非常磨人。一个 shape 可能包含 fill、line、rotation、placeholder、text、group transform,还可能带 Metro blob。渲染时要把它们拆成 HTML、CSS 和 SVG:
ts
const metroComplex = propertyValue(properties, 937)?.complexData;
const metroBlob: PptMetroBlob | undefined = metroComplex ? { bytes: metroComplex.slice() } : undefined;
const base: PptShapeBase = {
id: shapeId,
typeId: shapeType,
typeName: shapeTypeName(shapeType),
fill: parseFill(properties),
line: parseLine(shapeType, properties),
zIndex: context.zCounter.value += 1,
};
if (metroBlob !== undefined) {
base.metroBlob = metroBlob;
}这里还有一个实际踩过的坑:同步渲染路径在浏览器里容易漏掉某些异步矢量转换。切到 parsePpt() 和 renderPptHtmlAsync() 后,EMF / WMF 与 Metro 渲染链路才能完整走完:
js
if (format === 'ppt') {
const { parsePpt, renderPptHtmlAsync } = await loadViewerModule('ppt');
const parsed = await parsePpt(bytes, {});
elements.preview.innerHTML = parsed.html || await renderPptHtmlAsync(parsed);
}你是不是也遇到过 PPT 首页能显示、后面图形全乱的情况?很多时候问题就藏在母版、图层、group 坐标系和矢量资源里。它们不显眼,但每一项都影响最终画面。
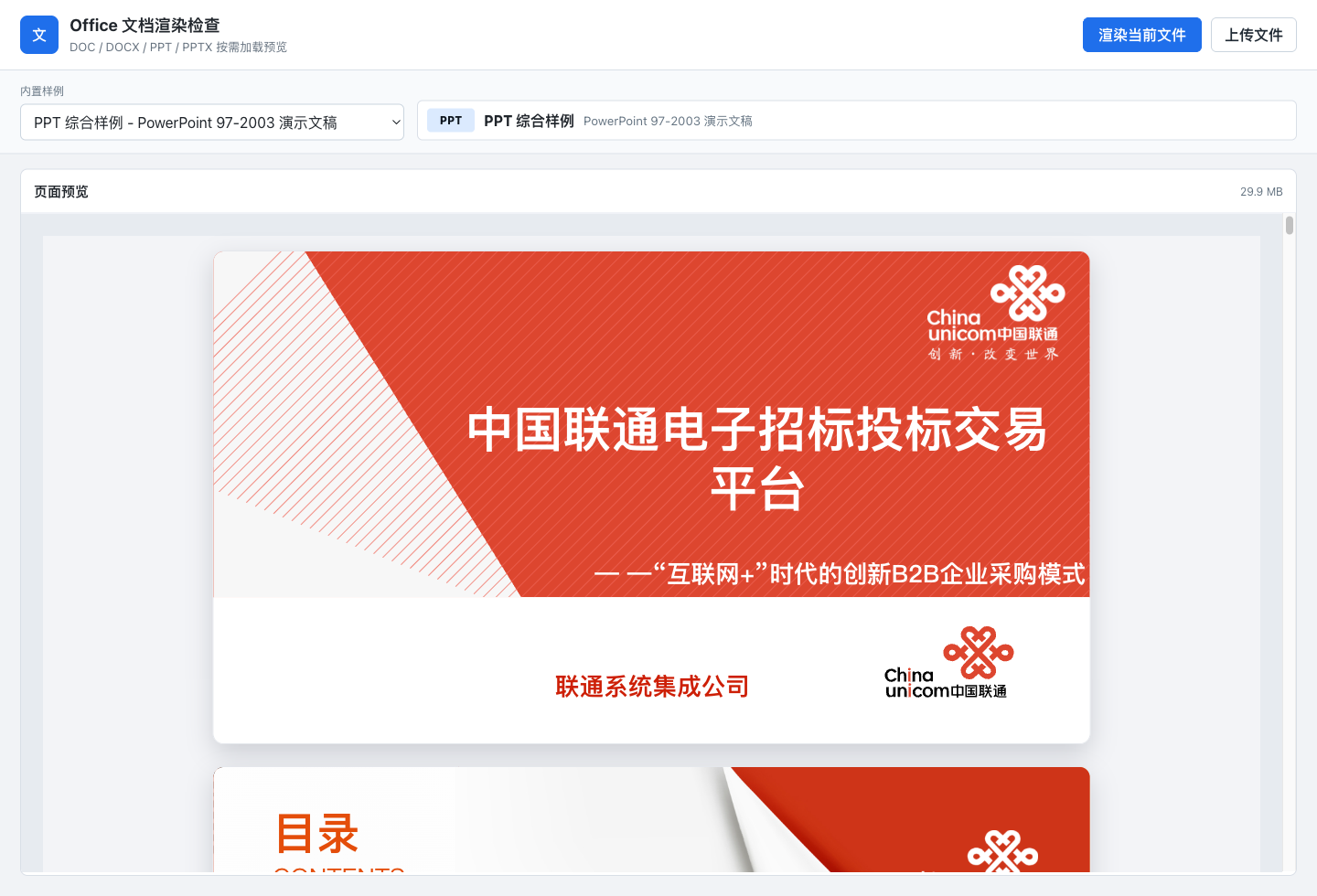
PPTX:现代格式也有自己的脾气
.pptx 更现代,结构也更清晰。可 PresentationML 的难点,集中在关系和继承。
一页 slide 往往引用 layout,layout 引用 master,master 引用 theme。颜色、字体、背景、占位符、默认文本样式,可能来自任何一层。
pptx-viewer 的主流程会先打开 package,再解析 themes、masters、layouts 和 slides:
ts
export async function parsePptx(source: BinarySource, options: ParseOptions = {}): Promise<PptxDocument> {
const packageStore = await openPackage(source, {
assetMode: options.assetMode ?? 'data-uri',
onProgress: options.onProgress
});
const presentationRoot = await packageStore.getXml(packageStore.info.presentationPath);
const presentationRelationships = packageStore.getRelationships(packageStore.info.presentationPath);
const themeParts = await parseThemes(packageStore, options);
const slideMasters = await parseSlideMasters(...);
const slideLayouts = await parseSlideLayouts(...);
const slides = await parseSlides(...);
}真正渲染某一页时,要把 master、layout 和 slide 自己的元素合并起来,还要处理 placeholder 是否被占用、是否应该继承、zIndex 怎么错开:
ts
function mergeInheritedSlideElements(
slideRoot: XmlElement,
slideElements: SlideElement[],
layout: SlideLayoutModel | undefined,
master: SlideMasterModel | undefined
): SlideElement[] {
const slidePlaceholderKeys = collectPlaceholderKeySet(slideElements);
const visibleMasterElements = masterShapesVisible(slideRoot, layout)
? filterInheritedElements(master?.elements ?? [], masterOccupiedKeys)
: [];
const visibleLayoutElements = filterInheritedElements(layout?.elements ?? [], slidePlaceholderKeys);
return [
...visibleMasterElements.map((element) => offsetElementZIndex(element, 0)),
...visibleLayoutElements.map((element) => offsetElementZIndex(element, layoutOffset)),
...slideElements.map((element) => offsetElementZIndex(element, slideOffset))
];
}这一步做好了,PPTX 才会像一页真正的幻灯片:母版背景、页脚、占位符默认样式都能回到画面里。
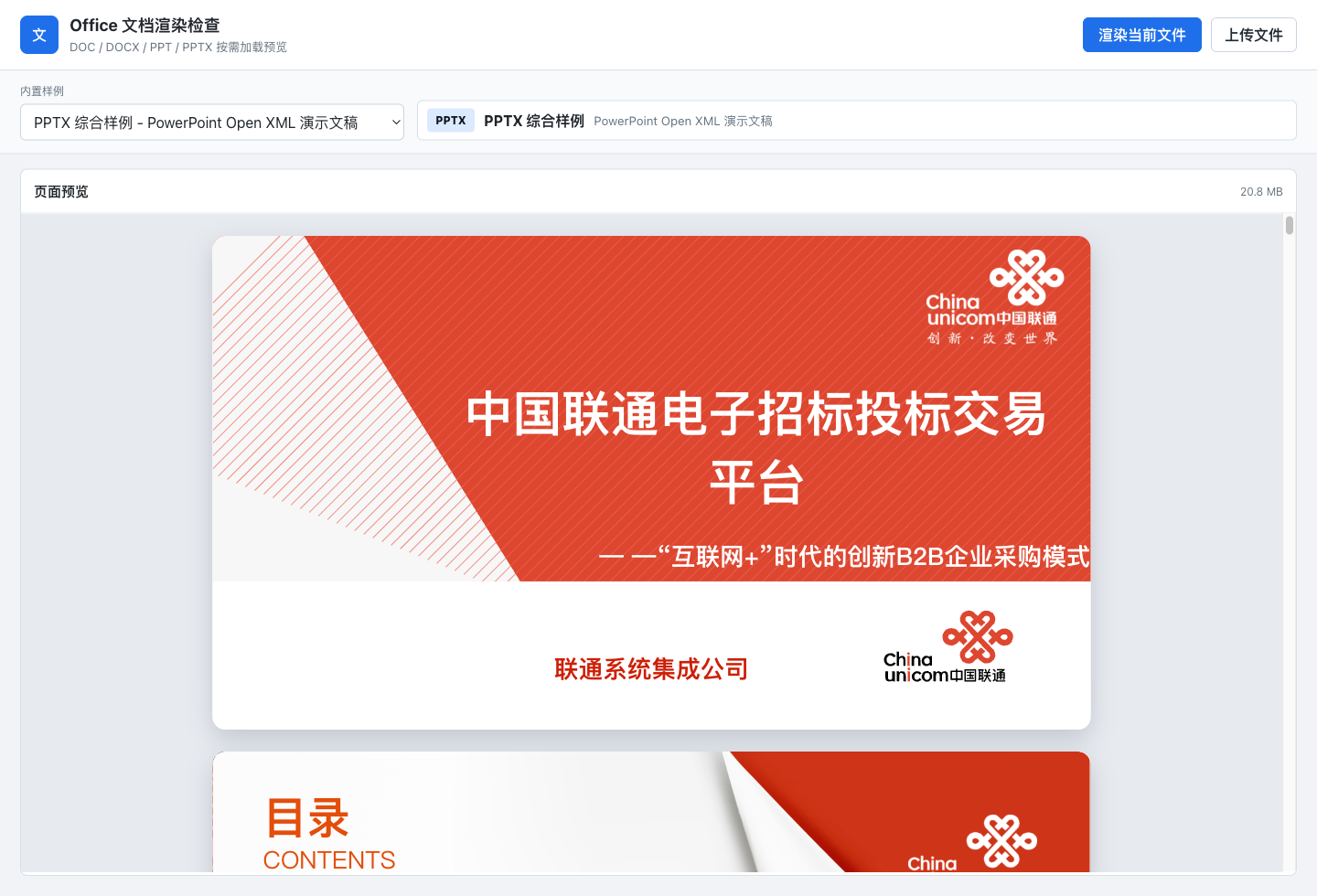
现在做到哪了
当前 demo 里,四类样例都已经能端到端预览:
| 格式 | 样例结果 | 阶段性能力 |
|---|---|---|
| DOC | 602 个块,11 个压缩 EMF 转 SVG | CFB / FIB / CLX / OfficeArt / floating shape |
| DOCX | 99 页,56 张图片 | WordprocessingML / 样式 / 编号 / 动态分页 |
| PPT | 35 页 | Persist Map / OfficeArt / EMF/WMF / Metro blob |
| PPTX | 35 页,32 个 masters,530 个 layouts | OPC / relationships / theme / master-layout-slide |
这些数字更像路标,提醒我们已经走到了哪里。
项目还在持续努力中。后续会继续补真实文件里的复杂对象、更多 OfficeArt 记录、表格边界、字体度量、动画与媒体降级,也会探索更轻量的 WASM 分发与发布形态,让解析能力在更多运行环境里更容易被复用。
写在最后
如果你的系统也有 Office 预览痛点,希望文件少流转一点、部署轻一点、前端可控一点,这类纯前端方案值得认真看看。
它不会一下子替代完整 Office 套件,也不会承诺每份历史文件都像原生 Office 一样毫厘不差。可它已经能帮我们解决一批很现实的问题:在浏览器里直接打开文件,尽量还原主要内容,保留结构化信息,遇到困难也给出可追踪的 fallback。
很多工程就是这样慢慢长出来的。
先让一个文件亮起来。
再让一类图片亮起来。
再让一个母版、一段分页、一组矢量图回到它该在的位置。
这条路还有很多细节要补,但它已经从纸面想法落进了浏览器,真实地渲染出了 DOC、DOCX、PPT 和 PPTX。
这就足够让人愿意继续往前走。
参考资料
- Microsoft Learn: MS-DOC Word (.doc) Binary File Format
- Microsoft Learn: MS-PPT PowerPoint (.ppt) Binary File Format
- Microsoft Learn: MS-CFB Compound File Binary File Format
- Microsoft Support: Learn about file formats
- Microsoft Q&A: Need to render office documents in native form on the browser applications
- Seafile Admin Manual: Office Documents Preview with LibreOffice