Jina Serve:重塑云原生AI服务的构建与部署范式
当单一模型API无法满足复杂业务需求,当自建服务在并发与运维面前步履维艰,一个旨在将AI应用从"实验品"变为"工业品"的开源框架正获得开发者青睐。Jina Serve以其云原生基因和多模态处理能力,正在降低企业运用先进AI技术的门槛。
在人工智能工程化(MLOps)领域,一个核心痛点是:如何将实验室中训练好的模型,高效、稳定、可扩展地部署为生产环境中的在线服务。传统方法往往需要开发者耗费大量精力在服务框架、协议转换、负载均衡和监控运维等基础设施上。由 Jina AI 推出的开源框架 Jina Serve ,正是为了系统性地解决这一问题而生。它不是一个简单的模型推理封装工具,而是一个面向生产环境的云原生AI服务框架,让开发者能够像构建微服务一样,轻松构建、编排和扩展多模态AI应用。
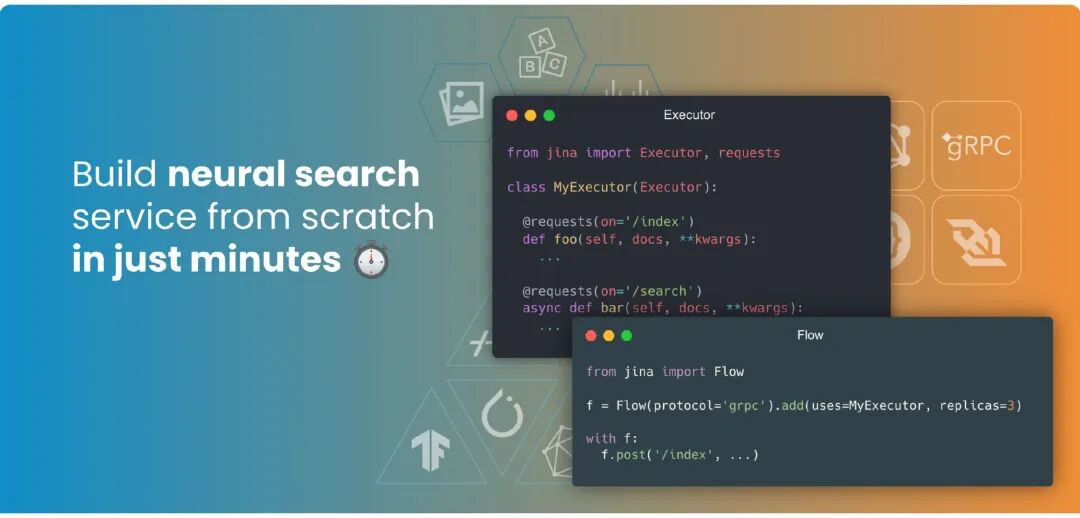
项目定位:AI微服务与工作流编排平台
Jina Serve 的核心定位是成为连接AI模型与实际业务应用的**"服务化中间件"**。其设计哲学是将复杂的AI能力拆解为独立的、可复用的"执行单元"(Executor),并通过灵活的"流"(Flow)进行管道式编排,最终通过统一的"网关"(Gateway)对外提供高性能的API服务。
与直接将模型包装为HTTP端口的简单方案不同,Jina Serve 强调云原生、高性能和可观测性。它原生支持多协议(gRPC, HTTP, WebSocket)、动态批处理、自动负载均衡和弹性扩缩容,能够无缝集成到Docker、Kubernetes等现代基础设施中,使得AI服务具备与传统微服务同等的可管理性和可靠性。其目标是让AI开发者能够专注于算法和业务逻辑,而非基础设施的复杂性。
核心架构与核心概念
Jina Serve 的架构围绕几个核心概念构建,清晰的分层设计是其强大能力的基石。
核心三层抽象
-
Document (文档):这是Jina生态中统一的数据表示层,来源于其底层库 DocArray。它将文本、图像、音频、视频、3D网格、PDF等多模态数据统一封装为"Document"对象,使得整个框架能够以一致的方式处理和传输不同类型的数据。
-
**Executor (执行器)**:这是业务逻辑的核心载体。一个Executor就是一个Python类,负责处理接收到的DocumentArray(文档数组)。开发者只需继承
Executor基类,并使用@requests装饰器定义服务端点,即可将任何模型或处理逻辑(如文本编码、图像分类、翻译)封装成一个独立的服务单元。Jina提供了 Executor Hub,方便开发者共享和复用他人封装好的执行器。 -
**Deployment 与 Flow (部署与流)**:这是服务的编排与部署层。
-
Deployment用于部署单个Executor,并管理其生命周期、副本数和扩缩策略。 -
Flow则用于编排多个Executor,构建有向无环图(DAG)形式的复杂AI工作流。例如,可以构建一个"文本翻译 -> 文本生成图像"的流,Jina Serve会自动处理服务发现、负载均衡和中间数据传输。
-
核心功能特性
基于上述架构,Jina Serve提供了开箱即用的企业级功能:
-
高性能服务:支持异步和非阻塞处理、动态批处理,可显著提升高并发下的吞吐量。
-
弹性扩展:通过简单的配置即可为任意Executor设置副本(Replicas)和分片(Shards),实现水平扩展。
-
多协议网关:内置的Gateway组件同时暴露gRPC、HTTP、WebSocket和GraphQL接口,满足不同客户端的调用需求。
-
完整的可观测性:无缝集成OpenTelemetry、Prometheus和Grafana,提供链路追踪、指标监控和日志管理能力。
快速开始指南
安装与环境
安装Jina Serve非常简单,通过pip即可完成:
pip install jina基础示例:从单一服务到工作流
1. 创建并部署一个翻译执行器首先,定义一个将法语翻译为英语的Executor:
# translate_executor.py
from docarray import DocumentArray
from jina import Executor, requests
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
class Translator(Executor):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.tokenizer = AutoTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", src_lang="fr_XX")
self.model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
@requests
def translate(self, docs: DocumentArray, **kwargs):
for doc in docs:
doc.text = self._translate(doc.text)
# ... _translate 方法细节见上文然后,使用一个YAML文件来部署它:
# deployment.yml
jtype: Deployment
with:
uses: Translator
py_modules:
- translate_executor.py
timeout_ready: -1通过CLI命令jina deployment --uses deployment.yml即可启动服务,框架会输出服务的访问端点。
2. 编排一个多模型工作流接下来,我们将翻译服务与一个文生图模型串联,构建更复杂的Flow:
# flow.yml
jtype: Flow
executors:
- uses: Translator
timeout_ready: -1
py_modules:
- translate_executor.py
- uses: jinaai://jina-ai/TextToImage # 使用Jina Hub上的执行器
timeout_ready: -1
install_requirements: true使用jina flow --uses flow.yml启动这个工作流。客户端只需输入一句法语描述,即可获得对应的生成图像。
进阶配置:实现弹性与高性能
在生产环境中,可以轻松为Executor配置扩展和优化。以下YAML示例展示了如何为文生图模型创建2个GPU副本并启用动态批处理:
jtype: Deployment
with:
uses: jinaai://jina-ai/TextToImage
env:
CUDA_VISIBLE_DEVICES: RR # 在副本间轮询GPU
replicas: 2 # 启动2个副本
uses_dynamic_batching:
/default:
preferred_batch_size: 10 # 首选批处理大小
timeout: 200 # 等待超时(毫秒)应用场景与最佳实践
Jina Serve 适用于任何需要将AI模型工程化、服务化的场景:
-
智能对话系统:编排意图识别、实体抽取、对话管理和回复生成等多个模块,构建企业级客服机器人。
-
多模态检索与RAG:统一处理来自文本、图像、PDF等不同来源的查询,构建新一代知识库系统。
-
内容生成流水线:串联文本摘要、翻译、图像生成、内容审核等模型,实现自动化内容创作。
-
推荐系统:将召回、排序、重排等多个模型部署为可独立扩展的服务,灵活调整推荐链路。
最佳实践建议:
-
开发与配置分离:将Executor的业务逻辑(Python代码)与部署拓扑、资源需求(YAML配置)分离,便于在不同环境迁移。
-
善用Executor Hub:优先使用Hub上经过验证的执行器,避免重复造轮子并简化依赖管理。
-
强化可观测性:在生产部署中,务必启用并配置监控指标和分布式追踪,这是快速定位性能瓶颈和故障的前提。
总结与展望
Jina Serve 通过清晰的抽象和强大的云原生集成,成功地将构建生产级AI服务的复杂性封装起来。它标志着AI应用开发正从"脚本模式"迈向"服务编排模式",让开发者能够以更高维度的视角去设计和实现复杂的AI应用。
值得一提的是,Jina AI 团队及其技术已在2025年10月被企业搜索领域的领导者 Elastic 收购。这一结合预示着向量搜索、多模态AI与成熟的企业级数据平台将进一步融合,Jina Serve所代表的技术方向------开放、云原生、多模态的AI服务化------可能会在更广阔的企业搜索和知识管理场景中加速落地。对于开发者和企业而言,现在深入学习和应用Jina Serve,不仅是构建下一代AI应用的有力工具,也可能是在把握未来智能搜索与AI基础设施演进的重要脉络。