Token是什么?------从原理到实战,一篇讲透
作者 :Weisian
发布时间:2026年4月

直击痛点:
"面试官:'大模型里的 Token 是什么?'你:'就是分词后的单元......'面试官:'那为什么中文一个字就是一个 Token,英文却要分成 subword?'你:'呃......这个......'------这就是 Token 理解不深的'死亡问答':看似简单的问题,却能暴露你对大模型底层原理的认知盲区。"
在大模型时代,Token 是最基础却又最容易被误解的概念之一:
- 开发者:以为 Token 就是字或词,结果计费超预算;
- 算法工程师:不了解 Tokenization 对模型性能的影响;
- 产品经理:不清楚上下文长度限制的实际含义;
- 面试者:背了定义却说不清原理,错失高薪机会。
解决方案:深入理解 Token 的本质、作用和实际影响,掌握一套逻辑严密、生动易懂的解释框架。
📌 核心一句话 :
Token 是大模型处理文本的最小语义单元,相当于模型世界的"文字原子"。模型不认识文字,只认识数字向量,Token 是"文字→数字"的中间桥梁。
📌 面试金句先记牢:
- Token 定义:Token 是大模型处理文本的最小单位,相当于模型世界的"文字原子";它不是严格意义上的"字"或"词",而是介于两者之间的语义单元;
- 为什么需要 Token:模型不认识文字,只认识数字,Token 是编码中间单元;
- 切分原理:不是简单分词,而是基于统计频率的 subword 切分算法;
- 中文 vs 英文:中文 1 Token ≈ 1.2~1.5 汉字,英文 1 Token ≈ 4 个字母;
- 实际影响:决定上下文长度、计费标准、生成质量三大关键指标;
- 输出更贵原因:输出阶段必须逐个 Token 生成(串行),GPU 空转等待数据;
- 滚雪球效应:多轮对话把整个历史每次都重新输入,对话越长成本越高;
- Agent 放大效应:多轮推理 + 工具调用开销,Token 消耗是普通对话的 10 倍;
- 上下文窗口:指模型单次交互能处理的最大 Token 数量,决定"记忆容量";
- 优化技巧:压缩提示词、精简输出、用英文替代中文、用工具计算 Token;
- 技术本质:将人类语言转换为模型可处理的数字向量的中间载体。
一、Token 到底是什么?
1.1 一句话概括
Token 是大模型处理文本的最小语义单元,相当于模型世界的"文字原子"。模型不认识文字,只认识数字向量,Token 是"文字→数字"的中间桥梁。
1.2 通俗类比:乐高积木
想象一下:
- 人类语言 = 一座复杂的城堡(由砖块砌成)
- 大模型 = 只认识乐高积木的小孩
- Tokenization = 把城堡拆解成标准乐高积木的过程
- Token = 每一块标准乐高积木
为什么不用原子(字)?------如果用原子,城堡需要几百万块微小积木,小孩根本拼不过来。
为什么不用整座城堡(整个句子)?------模型又无法理解细节。
乐高积木(Token)刚刚好:既有语义完整性,又不会太细碎。

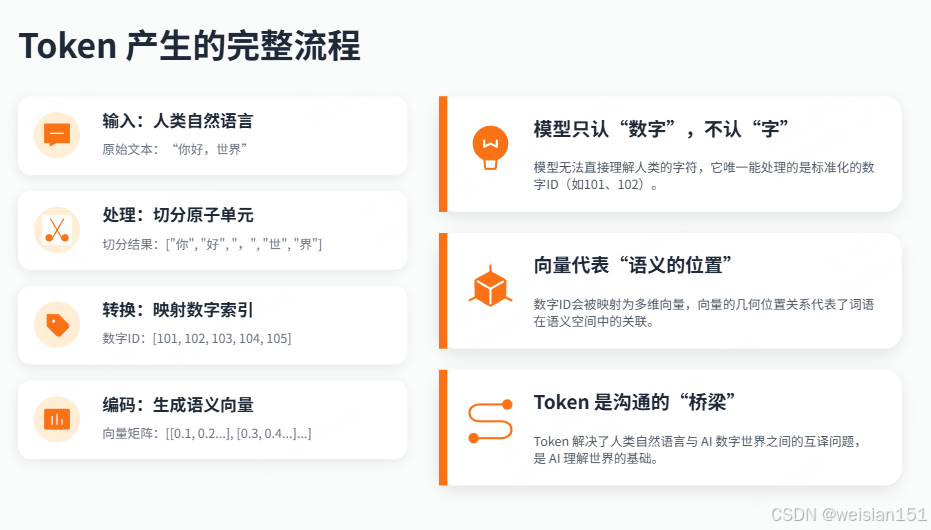
1.3 Token 产生的完整流程
模型处理文本的三步流程:
python
# 实际 Token 化过程
text = "我喜欢编程" # 原始文本
tokens = ["我", "喜欢", "编程"] # 中文 Token
token_ids = [100, 200, 300] # 对应 ID
embeddings = model.embed(token_ids) # 转为向量流程图解:
人类文字: "你好,世界"
│
▼
切分 Token: ["你", "好", ",", "世", "界"]
│
▼
转成数字ID: [101, 102, 103, 104, 105]
│
▼
转成向量: [[0.1, 0.2, ...], [0.3, 0.4, ...], ...]
│
▼
模型计算 → 输出核心理解:
- 模型不认识 "你"这个字,只认识数字 ID
101 - 数字 ID 映射到向量,向量代表"语义位置"
- Token 是人类文字和模型数字之间的桥梁
1.4 Token 的本质(面试拔高)
Token 的核心价值,是"桥梁"------连接人类自然语言和模型的数字世界。具体来说:
- 模型本身不认识任何文字,它只认识"数字向量"(一串连续的数字);
- Token 切分:先把人类的文本,切成一个个有语义的最小碎片(Token);
- Token 编码:再通过模型的 Tokenizer(编码工具),把每个 Token 转换成一个唯一的数字 ID,再映射成对应的向量;
- 模型计算:基于这些向量进行语义理解、推理和生成,最后再把生成的 Token 向量,解码回人类能看懂的文本。
面试加分回答:Token 的本质是"信息论中的符号单元",它剥离了"意义",只保留"形式"。这就是为什么有人提议翻译为"符元"而不是"智元"------因为 Token 本身不包含智能,智能是大量 Token 组合后的涌现现象。
1.5 Token 不是字,也不是词
| 概念 | 说明 | 示例 |
|---|---|---|
| 字符 | 人类书写的单个符号 | "你"、"好"、"a"、"b" |
| 词 | 有完整语义的单位 | "你好"、"apple" |
| Token | 模型切分后的最小处理单元 | "你"、"好"、"app"、"le" |
关键区别:
- 字符太细:模型要处理大量冗余信息
- 词太大:模型词汇表会爆炸(中文有几十万词)
- Token 是折中方案:比字符有语义,比词更小、更可控

1.6 Token 的三种切法:为什么同一句话 Token 数不一样?
同样是"我爱北京天安门",不同模型的分词器(Tokenizer)可能切出完全不同的结果:
| 切分粒度 | 示例 | Token数 | 优缺点 |
|---|---|---|---|
| 字符级 | ['我', '爱', '北', '京', '天', '安', '门'] |
7 | 词汇表极小,但序列太长,语义丢失 |
| 词级 | ['我', '爱', '北京', '天安门'] |
4 | 语义完整,但无法处理生僻词 |
| 子词级 | ['我爱', '北京', '天安门'] |
3 | 业界主流,平衡了效率和覆盖率 |
生活类比:
这就像切蛋糕。你可以切成 7 小块(字符级),每口一小块,但吃得很累;也可以切成 4 大块(词级),但遇到形状不规则的蛋糕就切不准;最聪明的切法是切成 3 块(子词级)------把常见的"我爱"作为一个块,把"天安门"作为一个整体,既高效又准确。这就是 BPE(Byte Pair Encoding)算法的思路。
1.7 Token vs. 汉字 vs. 英文单词:换算公式
面试高频题:"1 个 Token 大约等于多少个汉字/英文单词?"
实用换算表:
| 语言 | 1 Token ≈ | 示例 |
|---|---|---|
| 英文 | 0.75 个单词(4 个字符) | "Hello world" ≈ 2 Token |
| 中文 | 1-2 个汉字 | "你好" ≈ 2 Token,"人工智能" ≈ 2-4 Token |
| 代码 | 1-3 个字符 | "print" ≈ 1 Token,"def init" ≈ 4-5 Token |
为什么中文比英文"费Token"?
因为英文字母只有 26 个,高频组合(如"ing"、"tion")可以被编码为单个 Token;而汉字有数万个,模型无法为每个汉字单独编码,只能用多个 Token 组合表示复杂汉字。这就像英文是用 26 种乐高积木搭房子,中文是用几千种特殊积木------前者更容易用标准件拼装。
精确计算方法(面试必考):
python
# 方法1:使用tiktoken(OpenAI官方)
import tiktoken
def count_tokens_openai(text: str, model: str = "gpt-4") -> int:
"""使用OpenAI的分词器精确计算Token数"""
encoding = tiktoken.encoding_for_model(model)
tokens = encoding.encode(text)
return len(tokens)
# 示例
text = "Token是大模型处理文本的基本单位"
print(f"Token数: {count_tokens_openai(text)}") # 输出可能是12-15
# 方法2:使用HuggingFace transformers(适用任何模型)
from transformers import AutoTokenizer
def count_tokens_hf(text: str, model_name: str = "Qwen/Qwen2.5-7B") -> int:
"""使用模型自带的分词器"""
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokens = tokenizer.encode(text)
return len(tokens)
print(f"Qwen2.5 Token数: {count_tokens_hf('我爱北京天安门')}")1.8 实际例子:看看 Token 长什么样
python
# 使用 Ollama 的 tokenizer 查看 Token 切分
import requests
import json
def get_tokens(text, model="qwen2_5-7b-q6"):
"""获取文本的 Token 切分结果"""
url = "http://localhost:11434/api/tokenize"
payload = {"model": model, "text": text}
try:
response = requests.post(url, json=payload)
if response.status_code == 200:
return response.json().get("tokens", [])
except Exception as e:
print(f"请求异常: {e}")
return []
# 测试不同文本
test_cases = [
"Hello world!",
"人工智能很厉害",
"transformer",
"New York",
"2026年4月16日"
]
print("🔍 Token 切分结果分析:")
print("=" * 50)
for text in test_cases:
tokens = get_tokens(text)
print(f"\n原文: '{text}'")
print(f"Token 数量: {len(tokens)}")
print(f"Token 列表: {tokens}")预期输出:
原文: 'Hello world!'
Token 数量: 3
Token 列表: ['Hello', '▁world', '!']
原文: '人工智能很厉害'
Token 数量: 5
Token 列表: ['人', '工', '智能', '很', '厉害']
原文: 'transformer'
Token 数量: 2
Token 列表: ['trans', 'former']
原文: 'New York'
Token 数量: 3
Token 列表: ['New', '▁York', '']
原文: '2026年4月16日'
Token 数量: 5
Token 列表: ['2026', '年', '4', '月', '16', '日']观察发现:
- 英文单词可能被切成 subword(如
transformer→trans+former) - 中文通常是字或词的组合(如
人工智能→人工+智能) - 空格被编码为特殊符号
▁ - 标点符号和数字通常单独成 Token
二、为什么要切分成 Token?------ 从原理讲透
2.1 原始困境:字符 vs 词汇
如果直接用字符(Character):
- 中文:每个字都是一个 Token,5000 字的文章就有 5000 个 Token
- 英文:每个字母都是一个 Token,计算量爆炸
- 模型需要从零学习词语组合,效率极低
如果直接用词语(Word):
- 词典过大(中文 10 万+ 词,英文 20 万+ 词)
- 新词、专有名词无法处理(未登录词 OOV 问题)
- 内存占用巨大

2.2 为什么不直接用"字"?
| 问题 | 说明 | 示例 |
|---|---|---|
| 词汇表太大 | 汉字约 9 万个,英文字母仅 26 个但无语义 | "a"不代表任何含义 |
| 序列太长 | 同样语义,英文序列更长 | "你好世界"4字 vs "Hello World"10字母 |
| 没有语义信息 | 单字在不同语境意思不同 | "水"在"水果"和"洪水"里意思不同 |
2.3 为什么不直接用"词"?
| 问题 | 说明 | 示例 |
|---|---|---|
| 词汇表爆炸 | 中文词汇几十万甚至上百万 | 模型词汇表通常只有 3 万 ~ 10 万 |
| 生僻词处理不了 | 未登录词(OOV)问题 | "颟顸"(mān hān)无法识别 |
| 复合词无限 | 无法穷举所有组合 | "人工智能"、"人工+智能"、"AI"...... |
2.4 Token 的三大优势
| 优势 | 解释 | 示例 |
|---|---|---|
| 压缩长度 | 用更少的 Token 表达相同信息 | "unbelievable" → "un", "believable" (2 Token) |
| 语义保持 | 子词能保留词根、前缀、后缀的语义 | "unhappy" → "un", "happy","un"表示否定 |
| 泛化能力 | 遇到新词也能处理 | "ChatGPT" → "Chat", "GP", "T" |
生活类比:
就像打包快递。
字符模式:把每个小零件单独包装,快递费高,打包慢。
词汇模式:必须用标准尺寸箱子,不合适的物品无法邮寄。
Token 模式:用可组合的泡沫块填充,适应任何形状,又节省空间。
2.5 Subword Tokenization 的智慧
现代大模型普遍采用 Subword Tokenization 算法,主要包括:
- Byte Pair Encoding (BPE):GPT 系列使用
- WordPiece:BERT 系列使用
- SentencePiece:T5、LLaMA 等使用
核心思想:在字符级别和单词级别之间找到平衡点,既能处理未登录词,又能保持语义完整性。
BPE 算法示例:
初始: ["low", "lower", "newest", "widest"]
步骤1: 统计所有字符对频率 → "es" 出现最多
步骤2: 合并 "es" → ["low", "lower", "newest", "widest"]
步骤3: 重复直到达到目标词汇表大小
最终词汇表: ["l", "o", "w", "lo", "low", "er", "ne", "we", "st", "es", "est", ...]BPE 优势:
- 处理未登录词 :
unexpected→un+expect+ed - 压缩序列长度:常用词保持完整,减少 Token 数量
- 跨语言通用:同一套算法适用于不同语言

2.6 中英文 Token 效率对比
| 语言 | 字符数 | Token 数 | 压缩比 | 特点 |
|---|---|---|---|---|
| 英文 | 100 | ~25 | 4:1 | subword 切分,效率高 |
| 中文 | 100 | ~80 | 1.25:1 | 字/词混合,效率较低 |
| 代码 | 100 | ~30 | 3.3:1 | 符号丰富,subword 效果好 |
实际影响:
- 同样的上下文长度(如 8k Token),英文能处理更多内容
- 中文用户更容易达到上下文限制
- 多语言混合场景需要特别注意 Token 分配
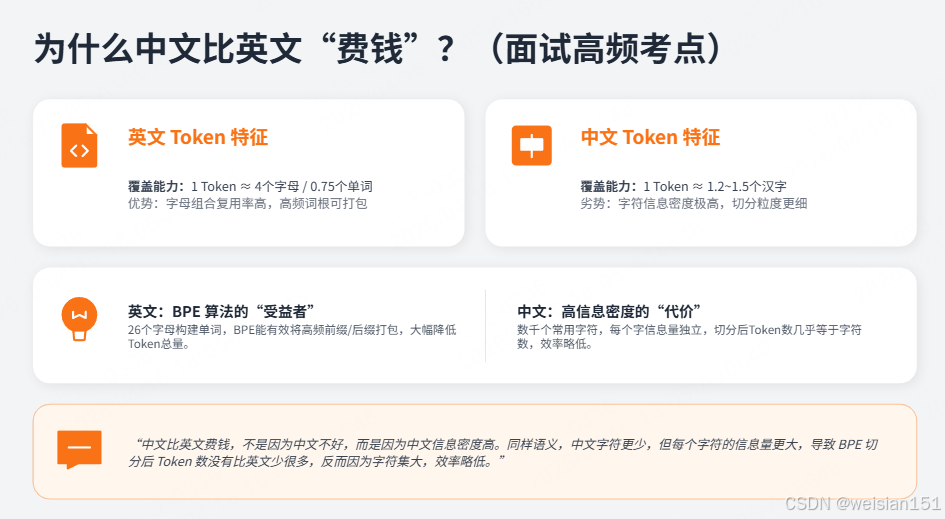
2.7 为什么中文比英文"费钱"?(面试高频考点)
| 对比维度 | 英文 | 中文 |
|---|---|---|
| 1 Token 覆盖 | 约 4 个字母 / 0.75 个单词 | 约 1.2~1.5 个汉字 |
| 10 个汉字 | ~10 个汉字 → 约 8-10 Token | ~10 个汉字 → 约 7-8 Token |
| 100 个汉字 | ~100 个汉字 → 约 80-100 Token | ~100 个汉字 → 约 70-80 Token |
| 原因 | 英文单词由字母组合,复用率高 | 汉字每个字符信息密度高,切分更细 |
核心原因:
- 英文:字母少(26个),但单词长 → BPE 可以把常见词根打包
- 中文:字符多(几千个常用),每个字符信息密度高 → 切分后 Token 数接近字符数
实际数据(GPT-4 实测):
英文:"Hello, how are you today?" → 约 8 Token
中文:"你好,今天怎么样?" → 约 7 Token
比例:中文 Token 数 ≈ 英文 Token 数的 1.2~1.5 倍面试金句:
"中文比英文费钱,不是因为中文不好,而是因为中文信息密度高。同样语义,中文字符更少,但每个字符的信息量更大,导致 BPE 切分后 Token 数没有比英文少很多,反而因为字符集大,效率略低。"
生活类比:
就像搬家。英文像乐高积木(小零件拼成大件),中文像成品家具(每个已经是完整单元)。乐高可以拆开打包,家具只能整体搬------不是家具不好,是搬运方式不同。
三、Token 决定模型的"视野"和"成本"
3.1 计费单位:Token 就是钱
无论是 OpenAI、文心一言,还是本地部署的模型(如 Ollama),云服务都是按 Token 计费------输入(Prompt)和输出(Completion)的 Token 数量之和,就是计费的依据。
主流大模型 API 计费标准:
| 模型 | 输入价格(每 1K Token) | 输出价格(每 1K Token) |
|---|---|---|
| GPT-4o | $0.005 | $0.015 |
| GPT-3.5 | $0.0005 | $0.0015 |
| Claude 3 | $0.003 | $0.015 |
| 文心一言 | ¥0.002 | ¥0.008 |

实战示例:
python
# 一段 1000 个汉字的提示词
# 中文:约 800 Token
# 英文翻译后:约 600 Token
# 成本差异(GPT-4o)
# 中文成本 = 800 / 1000 * 0.005 = $0.004
# 英文成本 = 600 / 1000 * 0.005 = $0.003
# 中文比英文贵 33%面试考点:
"如果公司要做大模型应用,你会怎么控制成本?" → 压缩提示词、用英文替代中文、选择更便宜模型、缓存常见回答。
3.2 上下文窗口:Token 决定模型能"记住"多少
大模型的"上下文窗口"(如 8k、32k、128k),本质就是"模型能同时处理的最大 Token 数量"------超过这个数量,模型就会"忘记"前面的内容,无法理解长文本。
| 模型 | 上下文窗口 | 相当于中文 |
|---|---|---|
| GPT-3.5 | 4K-16K | 约 3000-12000 汉字 |
| GPT-4 | 8K-128K | 约 6000-96000 汉字 |
| Claude 3 | 200K | 约 15 万汉字 |
| Qwen-72B | 32K-128K | 约 2.4 万-9.6 万汉字 |
实际含义:
- 上下文窗口 = 模型能"记住"的最大 Token 数
- 超过窗口,早期内容会被"遗忘"
- RAG 时要注意:检索内容 + 提示词 + 历史对话 + 输出 < 上下文窗口
实例说明:用 Ollama 部署的 qwen2_5-7b-q6 模型(上下文窗口 8k),如果输入一篇 10k Token 的文章让模型总结,模型只能处理前 8k Token,后面的内容会被截断。这也是为什么处理长文本时,需要用"分块处理"(把长文本切成多个 8k 以内的 Token 块,再逐个处理)。
面试考点:
"RAG 中,你检索了 10 个片段,每个 500 字,加上提示词和问题,超出了 8K 窗口怎么办?" → 压缩片段、只取 Top-K、用 Map-Reduce 策略。

3.3 生成长度:max_tokens 限制
在调用大模型时(如 Ollama、LangChain),有一个核心参数 max_tokens,它的作用就是"限制模型最多输出多少个 Token"------避免模型输出过长、偏离主题。
python
from langchain_ollama import ChatOllama
llm = ChatOllama(
model="qwen2_5-7b-q6",
max_tokens=500, # 最多输出 500 Token
)
# 如果模型想输出 800 Token,会被截断在 500 Token实际含义:
max_tokens限制模型输出长度- 输出 1 个汉字 ≈ 1.5 Token
max_tokens=500最多输出约 330-400 个汉字
3.4 性能:Token 越多越慢
模型计算复杂度 ≈ O(n²) 或 O(n³):
- Token 数量翻倍 → 计算时间翻 4-8 倍
- 优化 Token 数量 = 优化响应速度
3.5 Token 的"语言效率差异"(细节加分)
不同语言的 Token 和文字的对应关系不同,面试时说清楚这一点,体现你的细致:
| 语言 | Token 覆盖 | 示例 |
|---|---|---|
| 中文 | 1 Token ≈ 1.2~1.5 个汉字 | "我爱吃苹果"(5个汉字)≈ 4 Token |
| 英文 | 1 Token ≈ 4 个字母 / 0.75 个单词 | "data analysis"(2个单词)≈ 3 Token |
结论:同样长度的文本,中文的 Token 数量比英文少,所以中文在大模型处理时"效率更高"(相同 Token 数量,中文能表达更多语义)。
四、Token是怎么"消耗"的?------AI 算力计费的底层逻辑
4.1 消耗的本质:每生成一个 Token,GPU 都在"烧钱"
很多人的误区:以为 Token 消耗 = 输入字数 + 输出字数。
真相 :Token 消耗的不是"文字",而是生成这些文字所需的计算量。每生成一个 Token,背后都是一次完整的神经网络前向计算。
生活类比:
就像你开车去超市。你以为消耗的是"到达超市"这个结果,实际上消耗的是"发动机运转的每一分钟"。AI 每吐出一个字,GPU 都在满负荷运转,电表都在转。
4.2 自回归生成:为什么输出 Token 比输入 Token 贵 2-6 倍?
这是面试最高频的考点:"为什么 OpenAI 的 API 里,输出 Token 的价格是输入 Token 的 6 倍?"
答案藏在"自回归生成"的机制里:
输入阶段(Prefill):所有 Token 同时处理
┌─────────────────────────────────────────────────────────────┐
│ GPU:矩阵 × 矩阵(大规模并行计算) │
│ 效率:🔥🔥🔥🔥🔥 (计算密集型,GPU 满载) │
│ 成本:低 │
└─────────────────────────────────────────────────────────────┘
输出阶段(Decoding):一个 Token 一个 Token 生成
┌─────────────────────────────────────────────────────────────┐
│ GPU:矩阵 × 向量(每次只能算一个) │
│ 效率:🔥 (内存带宽瓶颈,GPU 空转等待数据) │
│ 成本:高(2-6 倍) │
└─────────────────────────────────────────────────────────────┘核心技术解释:
- 输入时:模型一次性看到所有 Token,可以并行计算它们之间的关系(注意力机制)。GPU 擅长这种"大矩阵乘大矩阵"的运算,效率极高。
- 输出时:模型每次只能生成 1 个 Token,而且这个 Token 依赖前面所有已生成的 Token。这意味着 GPU 必须反复从显存中读取参数,真正的计算时间只占 1%-5%,大部分时间在"空转等数据"。
生活类比:
输入阶段就像在流水线上同时组装 100 台手机------效率爆表。输出阶段就像只有一个工人,一台一台地组装,而且每装一台都要重新看一遍说明书------当然贵。

4.3 主流模型 API 计费标准
| 模型 | 输入价格(每 1K Token) | 输出价格(每 1K Token) | 输出/输入比 |
|---|---|---|---|
| GPT-4o | $0.005 | $0.015 | 3 倍 |
| GPT-3.5 | $0.0005 | $0.0015 | 3 倍 |
| Claude 3 | $0.003 | $0.015 | 5 倍 |
| 文心一言 | ¥0.002 | ¥0.008 | 4 倍 |
4.4 对话越长越烧钱:"滚雪球"效应
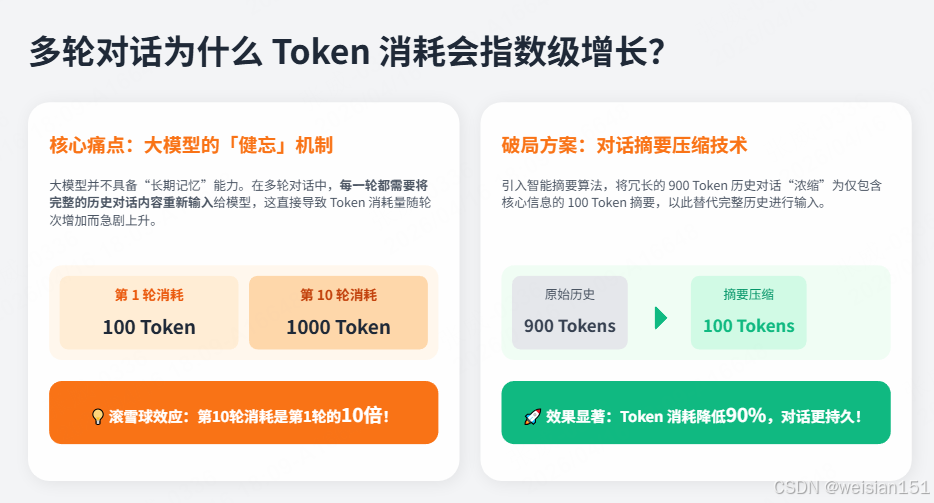
这是另一个高频考点:"为什么多轮对话会指数级增加 Token 消耗?"
核心原理 :大模型没有"记忆",它只是把整个对话历史每次都重新输入一遍。
第1轮:输入50 Token + 输出80 Token = 130 Token
第2轮:历史100 Token + 新输入50 Token + 输出80 Token = 230 Token
第5轮:历史800 Token + 新输入50 Token + 输出80 Token = 930 Token这意味着:同样的"你好"两个字,在第 1 轮只消耗少量 Token,在第 10 轮却要带着前面 9 轮的历史一起消耗。
生活类比:
就像你每次问问题,都要把前面所有对话记录复述一遍:"我们之前聊了 A、B、C、D...现在我问你第 5 个问题..." 对话越长,"复述"的成本越高。

4.5 实战代码:监控多轮对话的 Token 消耗
python
from langchain_ollama import ChatOllama
from langchain_core.messages import HumanMessage, AIMessage
class TokenCounter:
"""追踪多轮对话的Token消耗"""
def __init__(self, model_name: str = "qwen2.5:7b"):
self.llm = ChatOllama(model=model_name)
self.history = []
self.total_input_tokens = 0
self.total_output_tokens = 0
def _estimate_tokens(self, text: str) -> int:
"""估算Token数(中文约1.5字符/Token,英文约4字符/Token)"""
chinese_chars = sum(1 for c in text if '\u4e00' <= c <= '\u9fff')
english_chars = len(text) - chinese_chars
return int(chinese_chars / 1.5 + english_chars / 4)
def chat(self, user_input: str) -> str:
# 构建完整上下文
messages = self.history + [HumanMessage(content=user_input)]
# 估算输入Token(包含历史)
context_text = "".join([m.content for m in messages])
input_tokens = self._estimate_tokens(context_text)
# 调用模型
response = self.llm.invoke(messages)
# 估算输出Token
output_tokens = self._estimate_tokens(response.content)
# 更新统计
self.total_input_tokens += input_tokens
self.total_output_tokens += output_tokens
self.history.append(HumanMessage(content=user_input))
self.history.append(AIMessage(content=response.content))
print(f"📊 本轮:输入{input_tokens} Token → 输出{output_tokens} Token")
print(f"📈 累计:输入{self.total_input_tokens} → 输出{self.total_output_tokens}")
return response.content
# 演示滚雪球效应
counter = TokenCounter()
counter.chat("你好")
counter.chat("今天天气怎么样?")
counter.chat("再说一遍刚才的第一个问题")五、如何计算 Token?
5.1 使用 tiktoken(OpenAI 官方)
python
import tiktoken
# 加载编码器
encoding = tiktoken.get_encoding("cl100k_base") # GPT-4 使用
# 计算 Token 数
text = "你好,世界!Hello, World!"
tokens = encoding.encode(text)
print(f"文本:{text}")
print(f"Token 数:{len(tokens)}")
print(f"Token 列表:{tokens}")5.2 使用本地 Ollama + transformers(推荐)
python
# 使用 HuggingFace 的 tokenizer(支持本地模型)
from transformers import AutoTokenizer
# 加载 Qwen 的 tokenizer
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B", trust_remote_code=True)
def count_tokens(text: str) -> int:
"""计算文本的 Token 数量"""
tokens = tokenizer.encode(text)
return len(tokens)
# 测试
texts = [
"你好,世界!",
"Hello, World!",
"这是一个比较长的中文句子,用来测试 Token 数量的计算效果。",
"This is a longer English sentence to test token counting."
]
for text in texts:
token_count = count_tokens(text)
char_count = len(text)
print(f"文本:{text[:50]}...")
print(f" 字符数:{char_count},Token 数:{token_count},比例:{token_count/char_count:.2f}")
print()输出示例:
文本:你好,世界!
字符数:6,Token 数:5,比例:0.83
文本:Hello, World!
字符数:13,Token 数:4,比例:0.31
文本:这是一个比较长的中文句子,用来测试 Token 数量的计算效果...
字符数:28,Token 数:23,比例:0.82
文本:This is a longer English sentence to test token counting...
字符数:51,Token 数:11,比例:0.22六、生产环境 Token 优化策略
6.1 三种裁剪策略:当对话太长怎么办?
面试题:"如何控制长对话的 Token 消耗?"
核心思路:当上下文超过模型窗口时,需要"裁剪"历史消息。LangChain 提供了三种策略:
| 策略 | 原理 | 适用场景 | 效果示例 |
|---|---|---|---|
| Middle-out | 保留开头+结尾,删除中间 | 通用场景(最佳平衡) | 1000 条→83 条 |
| Head-out | 删除最早的消息 | 聊天应用(最近最重要) | 保留最近的消息 |
| Tail-out | 删除最新的消息 | RAG 应用(初始指令最重要) | 保留系统提示+早期消息 |
生活类比:
- Middle-out:像看电视剧,记得开头和结尾,中间忘了也不影响理解
- Head-out:像聊天,记得最近说了什么,三天前的忘了无所谓
- Tail-out:像做实验,记得实验步骤(开头),刚测的数据(结尾)反而可以丢掉

python
# Token裁剪策略示例
from langchain_classic.chains import ConversationChain
from langchain.memory import ConversationTokenBufferMemory
from langchain_ollama import ChatOllama
def create_token_aware_chain():
"""创建Token感知的对话链"""
llm = ChatOllama(model="qwen2_5-7b-q6")
# 使用Token缓冲内存(超过2000 Token自动裁剪)
memory = ConversationTokenBufferMemory(
llm=llm,
max_token_limit=2000,
return_messages=True
)
chain = ConversationChain(
llm=llm,
memory=memory,
verbose=True
)
return chain
# 演示:长对话自动裁剪
chain = create_token_aware_chain()
for i in range(50):
response = chain.predict(input=f"这是第{i}条消息")
print(f"第{i}轮完成")6.2 成本优化实战技巧
| 技巧 | 原理 | 效果 | 实现方式 |
|---|---|---|---|
| 精简提示词 | 删除冗余描述,保留核心指令 | 节省 30-50% Token | 压缩系统提示 |
| 用英文替代中文 | 英文 Token 效率更高 | 节省 20-30% Token | 英文 Prompt |
| 缓存结果 | 相同查询不重复计算 | 节省 50%-90% Token | Redis 缓存 |
| 限制输出长度 | 设置 max_tokens 参数 | 控制成本可预期 | max_tokens=500 |
| 压缩历史 | 用 LLM 总结历史对话 | 减少 80% 历史 Token | ConversationSummaryMemory |
| 流式输出 | 边生成边返回 | 用户体验提升 | streaming=True |

python
# 完整示例:生产级Token优化
from langchain.memory import ConversationSummaryMemory
from langchain_ollama import ChatOllama
class OptimizedAgent:
"""带Token优化的Agent"""
def __init__(self):
self.llm = ChatOllama(
model="qwen2_5-7b-q6",
temperature=0.1,
num_predict=512, # 限制输出长度
streaming=True # 流式输出
)
# 使用摘要内存(自动压缩历史)
self.memory = ConversationSummaryMemory(
llm=self.llm,
max_token_limit=1000 # 历史压缩到1000 Token以内
)
self.cache = {} # 简单缓存
def chat(self, user_input: str) -> str:
# 1. 检查缓存
cache_key = hash(user_input)
if cache_key in self.cache:
print("✅ 命中缓存,节省Token")
return self.cache[cache_key]
# 2. 加载压缩后的历史
history = self.memory.load_memory_variables({})
# 3. 调用模型
response = self.llm.invoke([
{"role": "system", "content": "你是AI助手"},
{"role": "user", "content": user_input}
])
# 4. 更新缓存和历史
self.cache[cache_key] = response.content
self.memory.save_context(
{"input": user_input},
{"output": response.content}
)
return response.content6.3 实战:优化提示词减少 Token
python
# ❌ 冗长的提示词(约 150 Token)
long_prompt = """
你是一个专业的客服助手。请根据用户的问题,给出详细、专业、友好的回答。
用户的问题可能涉及产品信息、售后服务、订单查询等多个方面。
请你务必保证回答的准确性,如果遇到不确定的问题,请告知用户你不确定,
并建议用户联系人工客服。同时,请保持礼貌和耐心,不要使用任何不专业的词汇。
用户的问题是:{question}
"""
# ✅ 精简的提示词(约 50 Token,减少 67%)
short_prompt = """
你是客服助手,专业友好地回答用户问题。
不确定时告知用户并建议联系人工客服。
问题:{question}
"""
def test_prompt_cost():
encoding = tiktoken.get_encoding("cl100k_base")
long_tokens = len(encoding.encode(long_prompt))
short_tokens = len(encoding.encode(short_prompt))
print(f"冗长提示词:{long_tokens} Token")
print(f"精简提示词:{short_tokens} Token")
print(f"节省:{long_tokens - short_tokens} Token ({ (long_tokens - short_tokens)/long_tokens*100:.1f}%)")
test_prompt_cost()6.4 实战:RAG 中的 Token 控制
python
def smart_rag(query, documents, max_context_tokens=2000):
"""
智能 RAG:控制上下文 Token 数
"""
import tiktoken
encoding = tiktoken.get_encoding("cl100k_base")
# 计算 Query 的 Token
query_tokens = len(encoding.encode(query))
# 预留输出空间
reserved_output = 500 # 预留 500 Token 给输出
max_input_tokens = max_context_tokens - query_tokens - reserved_output
# 按 Token 数筛选文档片段
selected_docs = []
current_tokens = 0
for doc in documents:
doc_tokens = len(encoding.encode(doc))
if current_tokens + doc_tokens <= max_input_tokens:
selected_docs.append(doc)
current_tokens += doc_tokens
else:
# 如果放不下完整片段,尝试截断
remaining = max_input_tokens - current_tokens
if remaining > 100: # 至少 100 Token 才有意义
truncated = encoding.decode(encoding.encode(doc)[:remaining])
selected_docs.append(truncated)
break
context = "\n\n".join(selected_docs)
print(f"Query Token:{query_tokens}")
print(f"Context Token:{current_tokens}")
print(f"总输入 Token:{query_tokens + current_tokens}")
return context七、Agent 模式下 Token 消耗的"放大器"效应
7.1 为什么 Agent 比普通对话"烧钱"10 倍?
这是最新的面试热点:"AI Agent 的 Token 消耗为什么是指数级的?"
核心原因 :Agent 不是"一次对话",而是"多次推理的循环"。
普通对话:
用户提问 → 模型思考 → 输出回答 → 结束
(1次推理,1次输出)Agent 执行任务:
用户:"帮我查一下上个月销售额,画个饼图"
↓
Step 1(推理1): "需要先查数据库" → 调用 query_database 工具
↓
Step 2(推理2): "拿到数据了,需要画饼图" → 调用 python_analysis 工具
↓
Step 3(推理3): "图已经画好,生成最终回答" → 输出结果每一轮推理都会消耗 Token,而且每轮都带着完整的系统指令和历史上下文。
生活类比:
普通对话就像你直接问路,对方直接告诉你。Agent 就像你雇了一个助理:"去帮我买杯咖啡"------助理要先想"去哪买",然后走路,然后排队,然后付钱,然后回来------每一步都在消耗"精力"(Token)。

7.2 实战:监控 Agent 的 Token 消耗
python
from langchain_ollama import ChatOllama
from langchain_core.tools import tool
from langchain_classic.agents import create_tool_calling_agent, AgentExecutor
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
import tiktoken
# 初始化Token计数器
encoding = tiktoken.get_encoding("cl100k_base")
def count_tokens(text: str) -> int:
"""精确计算Token数"""
return len(encoding.encode(text))
class TokenTrackingAgent:
"""带Token追踪的Agent"""
def __init__(self):
self.llm = ChatOllama(model="qwen2_5-7b-q6", temperature=0.1)
self.tools = [self.query_database, self.python_analysis]
self.total_prompt_tokens = 0
self.total_completion_tokens = 0
self.step_count = 0
# 创建Agent
prompt = ChatPromptTemplate.from_messages([
("system", "你是数据分析助手,可以调用工具查询数据库和画图。"),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
])
agent = create_tool_calling_agent(self.llm, self.tools, prompt)
self.executor = AgentExecutor(agent=agent, tools=self.tools, verbose=False)
@tool
def query_database(self, sql: str) -> str:
"""执行SQL查询"""
# 模拟数据库查询
return f"查询结果:销售额总计10000元"
@tool
def python_analysis(self, code: str) -> str:
"""执行数据分析"""
return "图表已生成"
def invoke(self, input_text: str) -> str:
# 估算输入Token
input_tokens = count_tokens(input_text)
# 执行Agent(内部会多次调用LLM)
result = self.executor.invoke({"input": input_text})
# 估算输出Token
output_tokens = count_tokens(result['output'])
# 估算中间步骤Token(Agent的思考过程)
intermediate_tokens = 0
if 'intermediate_steps' in result:
for step in result['intermediate_steps']:
intermediate_tokens += count_tokens(str(step))
self.total_prompt_tokens += input_tokens + intermediate_tokens
self.total_completion_tokens += output_tokens
self.step_count += 1
print(f"\n📊 Token消耗明细:")
print(f" - 用户输入:{input_tokens} Token")
print(f" - Agent思考:{intermediate_tokens} Token({len(result.get('intermediate_steps', []))}次工具调用)")
print(f" - 最终回答:{output_tokens} Token")
print(f" - 合计:{input_tokens + intermediate_tokens + output_tokens} Token")
return result['output']
# 演示Agent的Token放大效应
agent = TokenTrackingAgent()
agent.invoke("帮我查一下销售额")
agent.invoke("帮我查一下上个月销售额,然后画个饼图") # 这个会消耗更多7.3 Agent Token 消耗的放大倍数分析
| 任务类型 | 推理次数 | 工具调用次数 | Token 消耗 | 相比普通对话 |
|---|---|---|---|---|
| 普通问答 | 1 | 0 | ~500 | 1x |
| 单步 Agent | 2 | 1 | ~1500 | 3x |
| 多步 Agent | 3-5 | 2-4 | ~3000-5000 | 6-10x |
| 复杂 Agent | 5+ | 5+ | ~10000+ | 20x+ |
八、不同模型的 Token 差异
8.1 主流模型 Tokenizer 对比
| 模型 | Tokenizer | 词汇表大小 | 中文效率 | 特点 |
|---|---|---|---|---|
| GPT-4 | cl100k_base | 100K | 中 | 英文效率高 |
| Claude 3 | 自研 | ~100K | 中 | 长上下文 |
| Qwen2.5 | 自研 | 152K | 高 | 中文优化好 |
| Llama 3 | tiktoken | 128K | 低 | 英文为主 |
| DeepSeek | 自研 | 128K | 高 | 中文高效 |

8.2 实测:不同模型对同一段中文的 Token 数
python
from transformers import AutoTokenizer
text = "人工智能是计算机科学的一个分支,致力于创建能够执行通常需要人类智能的任务的系统。"
# Qwen2.5
qwen_tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B")
qwen_tokens = len(qwen_tokenizer.encode(text))
# Llama 3
llama_tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B")
llama_tokens = len(llama_tokenizer.encode(text))
print(f"文本长度:{len(text)} 字符")
print(f"Qwen2.5 Token:{qwen_tokens}")
print(f"Llama 3 Token:{llama_tokens}")
print(f"差异:Llama 3 比 Qwen 多 {(llama_tokens - qwen_tokens)} Token")结论:
- 中文场景选择 Qwen、DeepSeek 等中文优化模型更省钱
- 英文场景 GPT、Claude 效率更高
九、面试高频题详解(高压版)
Q1:请解释 Token 是什么?为什么它是大模型的核心概念?
参考答案 :
Token 是大语言模型处理文本的最小语义单元,是模型"理解"和"生成"语言的基本粒子。
它之所以核心,有三个原因:
- 计算单位:大模型的每一次矩阵运算都是在 Token 级别进行的
- 计费单位:所有商业 API 都按 Token 计费,输入 Token 和输出 Token 价格不同
- 能力边界:模型的上下文窗口(如 128K Token)直接决定了它能"记住"多长的对话
加分回答:Token 的本质是"信息论中的符号单元",它剥离了"意义",只保留"形式"。这就是为什么有人提议翻译为"符元"而不是"智元"------因为 Token 本身不包含智能,智能是大量 Token 组合后的涌现现象。
Q2:为什么不直接用字或词?
参考答案 :
直接用字:序列太长、没语义信息。直接用词:词汇表爆炸、生僻词处理不了。Token 是折中方案,用 BPE 算法把常见组合打包、生僻组合拆分,平衡了词汇表大小和语义表达。
Q3:为什么输出 Token 比输入 Token 贵?
参考答案 :
根本原因在于计算模式的不同:
- 输入阶段:GPU 可以并行处理所有 Token,这是"矩阵×矩阵"运算,GPU 擅长,效率极高
- 输出阶段:必须逐个 Token 生成,每个 Token 依赖前面的结果,这是"矩阵×向量"运算,GPU 大部分时间在等待数据从显存传输,效率只有 1%-5%
生活类比:输入阶段像在流水线上同时组装 100 台手机,输出阶段像只有一个工人一台台组装。

Q4:多轮对话为什么 Token 消耗会指数级增长?
参考答案 :
大模型没有"记忆",它只是把整个对话历史每次都重新输入一遍。
假设每轮对话产生 100 Token:
- 第 1 轮:消耗 100 Token
- 第 10 轮:历史已有 900 Token + 新输入 100 Token = 1000 Token
这意味着第 10 轮消耗的是第 1 轮的 10 倍。这就是"滚雪球效应"。
解决方案:使用对话摘要压缩历史,将 900 Token 的历史压缩为 100 Token 的摘要。
Q5:Agent 模式下 Token 消耗有什么特点?
参考答案 :
Agent 模式会"放大"Token 消耗,因为:
- 多轮推理:一个任务可能拆解为多个步骤,每步都消耗 Token
- 工具调用开销:每次工具调用都要附带指令描述和参数
- 重复上下文:每步都带着完整的系统指令和历史
数据对比:
- 普通问答:1 次推理,约 500 Token
- Agent 任务:3-5 次推理,约 2000-5000 Token
优化建议:精简系统指令、使用更高效的工具描述、缓存常见结果。
Q6:如何计算一段文本的 Token 数量?
参考答案 :
有三种方法:
- 精确方法:使用模型对应的分词器
python
import tiktoken
encoding = tiktoken.encoding_for_model("gpt-4")
token_count = len(encoding.encode("你的文本"))-
估算方法(面试快速回答):
- 英文:1 Token ≈ 0.75 个单词 ≈ 4 个字符
- 中文:1 Token ≈ 1-2 个汉字
-
公式 :
Token 数 ≈ (中文字符数 / 1.5) + (英文字符数 / 4)
Q7:实际工作中如何优化 Token 消耗?
参考答案 :
五点策略:第一,精简提示词,去掉冗余描述,能省 30-50% Token;第二,用英文提示词替代中文(如果模型英文能力强);第三,RAG 中控制检索片段数量和长度,用 Token 截断;第四,选择对中文优化好的模型(如 Qwen),Token 效率更高;第五,监控 Token 使用量,设置预算告警。
Q8:上下文窗口和 Token 的关系?
参考答案 :
上下文窗口就是模型能处理的最大 Token 数。窗口大小决定了模型能"记住"多少内容。做 RAG 时,检索片段 + 提示词 + 历史对话 + 输出总和不能超过窗口。超过会截断或遗忘早期内容。常见窗口:GPT-3.5 是 4K-16K,GPT-4 是 8K-128K,Claude 是 200K。
Q9:如何估算一个任务需要多少 Token?
参考答案 :
经验公式:中文 1 Token ≈ 1.5 汉字,英文 1 Token ≈ 4 个字母。实际用 tiktoken 或 transformers 的 tokenizer 精确计算。建议在代码里加 Token 计数日志,上线前压测,设置单次任务 Token 上限。
Q10:为什么中文比英文费钱?
参考答案 :
核心原因是信息密度和 BPE 切分方式不同。英文 1 个 Token 覆盖约 4 个字母或 0.75 个单词,中文 1 个 Token 覆盖约 1.2-1.5 个汉字。同样语义,中文的 Token 数约为英文的 1.2-1.5 倍。加上中文优化模型的 Tokenizer 不如英文成熟,所以实际使用中文成本更高。
十、话术速查表
| 问题类型 | 回答时间 | 核心要点 |
|---|---|---|
| 什么是 Token | 10秒 | 最小语义单元,文字→数字的桥梁 |
| 为什么需要 Token | 30秒 | 不用字(太长/无语义),不用词(词表爆炸),Token 是折中 |
| 中文 vs 英文 | 30秒 | 中文信息密度高,1 Token≈1.5汉字,英文≈4字母,中文贵1.2-1.5倍 |
| 为什么输出贵 | 30秒 | 输入并行计算,输出串行生成,GPU 空转等数据 |
| 滚雪球效应 | 20秒 | 大模型无记忆,每次都重新输入整个历史 |
| Agent 放大效应 | 30秒 | 多轮推理+工具调用,Token 消耗是普通对话的 10 倍 |
| 实际影响 | 30秒 | 计费、上下文窗口、生成长度、性能 |
| 优化方法 | 30秒 | 精简提示词、英文替代、控制 RAG 长度、选中文模型 |
| 上下文窗口 | 20秒 | 模型能处理的最大 Token 数,决定能"记住"多少 |
总结
核心知识点速记
Token 是基础单元,文字数字间桥梁。
BPE 算法来切分,常见打包生僻拆。
中文密度比较高,一个 Token 一点五汉字。
英文单词效率好,四个字母一 Token。
输入并行输出串,输出价格贵几倍。
对话越长越烧钱,历史包袱滚雪球。
Agent 多轮又调用,Token 放大十倍多。
计费窗口和长度,全都受它影响大。
优化要精简提示,英文替代更省钱。
面试把原理讲透,Offer 拿到手不慌。核心要点回顾
- Token 定义:大模型处理文本的最小语义单元,是"文字→数字"的桥梁;
- 为什么需要 Token:不用字(太长/无语义),不用词(词表爆炸),BPE 折中;
- 中文 vs 英文:中文 1 Token≈1.5 汉字,英文≈4 字母,中文成本高 1.2-1.5 倍;
- 实际影响:计费单位、上下文窗口、生成长度、性能;
- 优化方法:精简提示词、英文替代、控制 RAG 长度、选中文模型;
- 计算工具:tiktoken(OpenAI)、transformers(本地模型)、自研工具类。
- BPE 算法:通过统计频率合并高频字符对,平衡词汇表大小和语义表达;
- 输出更贵原因:输出阶段必须逐个 Token 生成(串行),GPU 空转等待数据;
- 滚雪球效应:多轮对话把整个历史每次都重新输入,对话越长成本越高;
- Agent 放大效应:多轮推理 + 工具调用开销,Token 消耗是普通对话的 10 倍;

写在最后
Token 看似简单,但讲透它需要理解 BPE 算法、模型架构、计费模式、优化策略。面试官问 Token,不是在考"定义",而是在考察你的基础扎实程度 和工程化思维。
记住:能讲清楚 Token 的人,RAG 成本优化、上下文管理、模型选型都不会差。
如果觉得有帮助,欢迎点赞、收藏、转发!有问题欢迎在评论区留言交流。