原文:https://mp.weixin.qq.com/s/hThfmLGZ9LPWzl53WyEqWA
上下文窗口是 Agent 的工作记忆
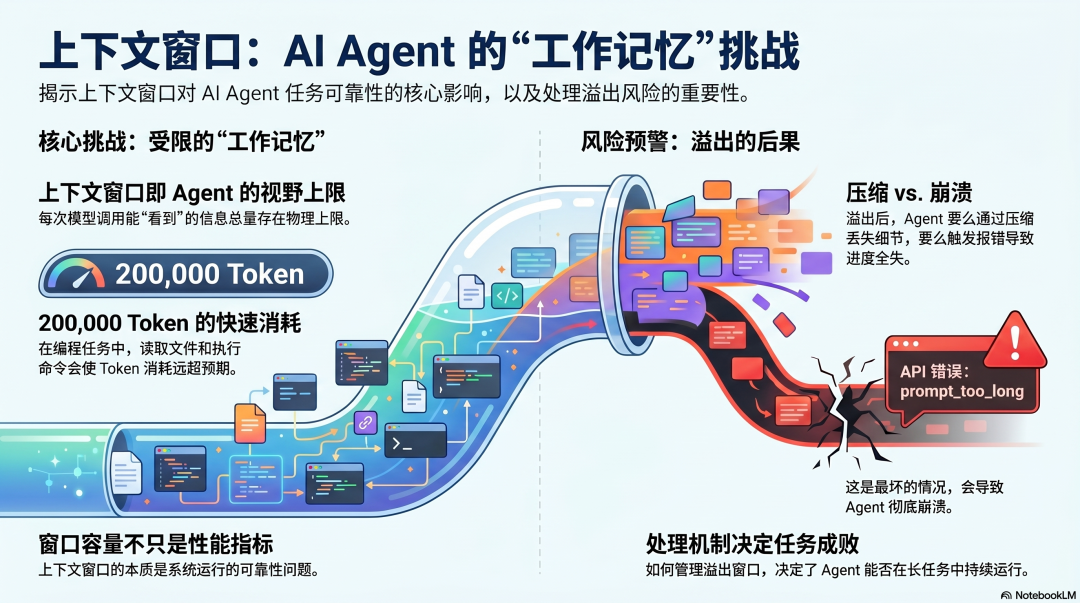
每次模型调用,它能"看到"的信息都有上限------这就是上下文窗口。
200,000 Token 听起来很大。但在一个中等复杂的编程任务里,读几十个文件、运行多轮 grep、执行几次 bash 命令,上下文就去了大半。工具调用结果、错误信息、中间推理......Token 消耗比你想象的快得多。
窗口满了会发生什么?
最好的情况:框架触发压缩,Agent 继续工作,只是丢失了一些细节。 最坏的情况:API 返回 prompt_too_long 错误,Agent 崩溃,所有进度丢失。
上下文窗口不只是性能问题,是系统可靠性问题。 如何处理窗口溢出,决定了 Agent 在长任务里能不能撑下去。
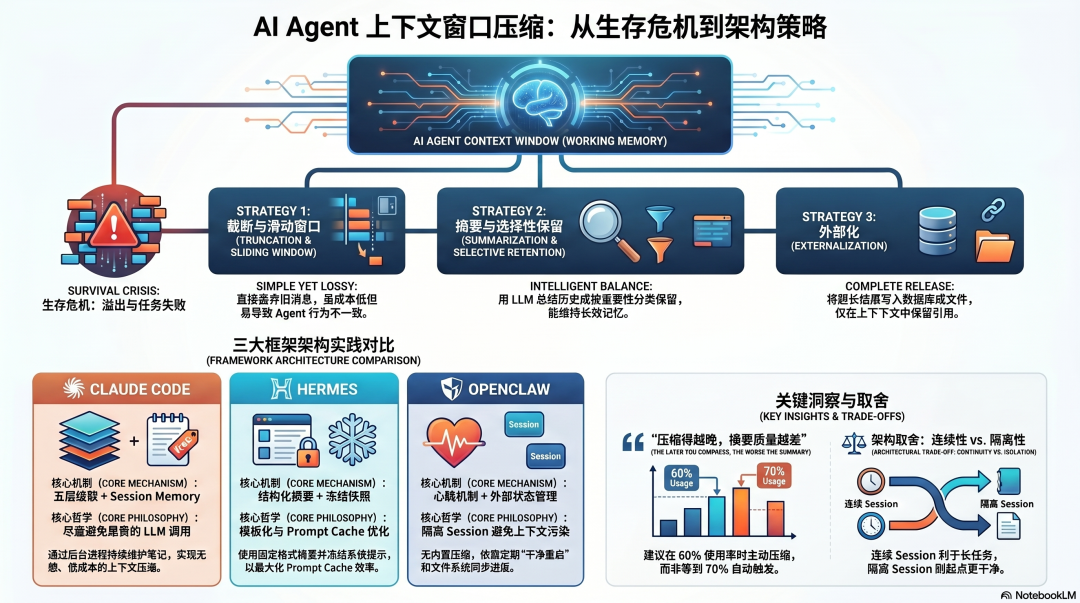
五种上下文压缩策略
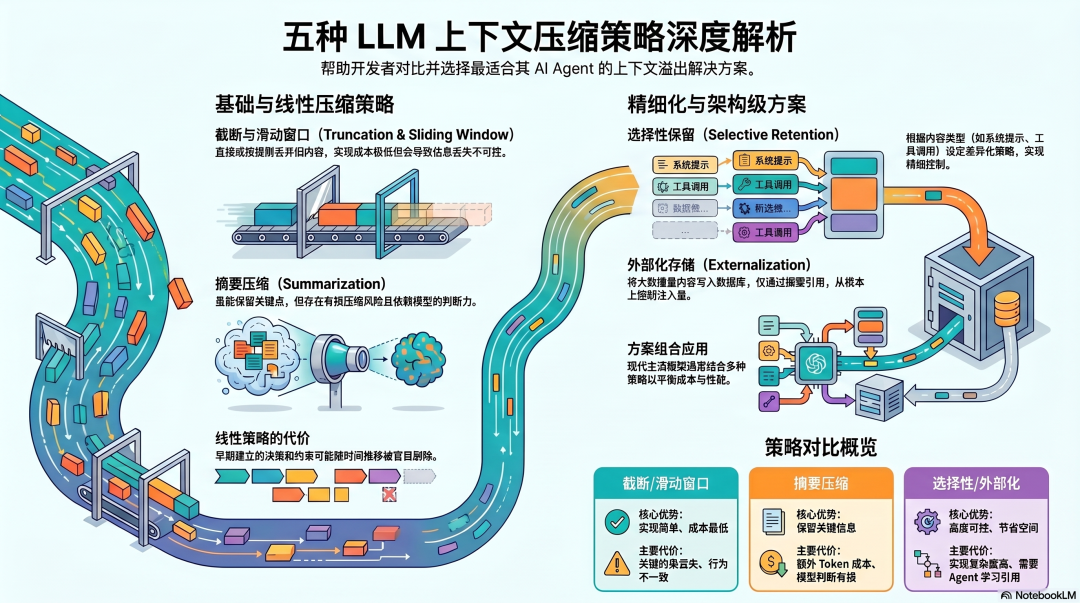
行业里处理上下文溢出的方式,大致可以归纳为五种,各有不同的成本和代价。
**策略一:截断(Truncation)**直接丢弃最早的消息,保留最近的内容。
最简单,实现成本最低。代价是信息丢失不可控------早期建立的架构决策、关键约束、任务目标,可能就这样被删掉了。Agent 的行为会变得不一致,之前说"不做X",截断后可能又开始做X。
**策略二:摘要(Summarization)**调用模型对历史对话生成摘要,用摘要替换原始内容。
保留了关键信息,但摘要本身有 Token 成本,而且是有损压缩------摘要质量取决于模型的判断,而模型的判断不总是准确的。"什么值得保留"这个问题,没有客观答案。
**策略三:滑动窗口(Sliding Window)**设定一个保留近 N 条消息的规则,持续丢弃超出范围的旧内容。
比截断更有控制感,但仍然是盲目丢弃------不考虑内容的重要性,只考虑时间顺序。
**策略四:选择性保留(Selective Retention)**对不同类型的内容设定不同的保留策略------系统提示永久保留,工具调用结果可以压缩,用户消息优先保留。
更精细,但需要对内容做分类,实现复杂度更高。
**策略五:外部化(Externalization)**当工具调用结果超过阈值,不注入上下文,而是写入文件或数据库,只给 Agent 一个摘要和引用。真正需要时再读取完整内容。
从根本上控制了注入量,但 Agent 需要学会使用引用,而不是直接读取内容。
三个框架的压缩方案,都是这五种策略的不同组合。
Claude Code:五层级联压缩,免费摘要是核心洞察
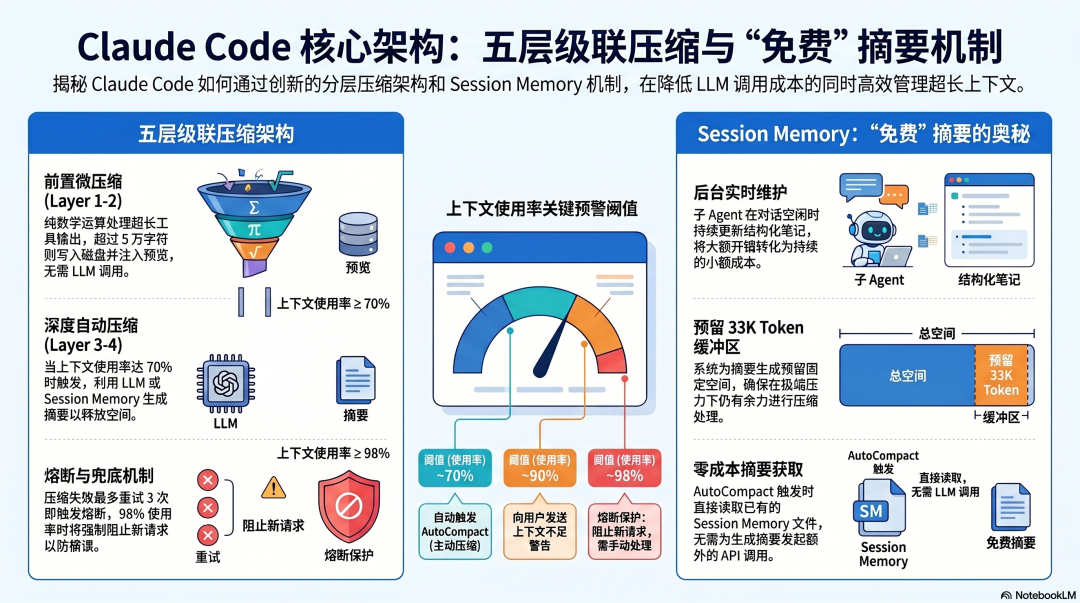
架构原则:避免 LLM 调用,能不用就不用
Claude Code 的压缩系统设计出发点是:每次 LLM 调用都有成本,能用数学运算代替的地方,绝不用模型。
从源码分析里能看到一个五层级联的压缩架构:
Layer 1-2(Microcompact,预处理)每次 API 调用前运行,轻量截断处理超长单条工具输出(阈值:5万字符)超出的写到磁盘文件,注入 ~2KB 预览 + 引用无需 LLM 调用,纯数学运算Layer 3-4(AutoCompact,后处理)每次 API 调用后运行,检查是否需要深度压缩触发阈值:约 70% 有效上下文使用率需要 LLM 调用生成摘要Layer 5(Context Collapse,兜底)多次压缩失败后的最后手段非破坏性,读取时投影(read-time projection)这个分层设计的核心价值:两层微压缩在每次 API 调用前后运行,尝试廉价地控制上下文体积;只有当这两层不够用时,才触发需要 LLM 调用的深度压缩。 在大多数情况下,上下文控制不需要额外的 LLM 调用。
Session Memory:免费摘要的架构创意
Claude Code 压缩设计里最有意思的部分,是 Session Memory 机制:
一个后台进程在整个 Session 里持续维护一份结构化笔记文件。 这个进程作为 fork 的子 Agent 运行,共享主 Session 的 Prompt Cache 前缀,只有 Edit 工具权限,在对话"空闲"时(最后一次助手响应不含工具调用)触发更新。
当 AutoCompact 需要摘要时,直接使用这份笔记文件------不需要额外的 LLM 调用。 摘要是实时维护的,而不是在压缩时临时生成的。
这改变了摘要的成本结构:从"压缩时一次性的大开销"变成了"持续的小开销"。Session Memory 的更新在后台进行,不阻塞主 Agent 的工作;Compaction 发生时,摘要已经在那里了。
用户可以在 ~/.claude/session-memory/config/template.md 里自定义笔记的结构模板,控制什么信息被持续追踪。
熔断器:防止压缩本身陷入死循环
Compaction 可能失败------当上下文太大,压缩请求本身也会返回 prompt_too_long。
Claude Code 的处理方式是:分组丢弃最旧的消息(按 API 轮次分组),最多重试三次。三次之后,不再尝试,上报给用户。
连续失败超过 3 次,熔断器触发。 这个数字来自真实生产数据:1,279 个会话出现 50 次以上连续失败,单个会话最多重试 3,272 次。设上限是明确的工程决策,而不是技术限制。
三级阈值:三次机会,不是一次
Claude Code 对上下文使用率设了三级阈值:
有效上下文 = 总窗口 - 为压缩摘要预留的 33K Token(早期版本是 45K Token,2026 年初降为 33K,给用户更多可用空间)~70% → 自动触发 AutoCompact(主动压缩)~90% → 向用户显示警告~98% → 阻止新请求,要求手动处理系统有三次机会在真正失败之前介入,而不是等到撞墙再处理。 在 60% 左右主动手动压缩(而不是等到 70% 自动触发),效果更好------此时 Claude 还有完整、未压缩的历史上下文,生成的摘要质量更高。
用户可以通过 CLAUDE_AUTOCOMPACT_PCT_OVERRIDE 环境变量调整触发阈值,但这个值改变的是触发时机,不是预留空间的大小。
Hermes:简单有效,冻结快照是关键
一层压缩,结构化摘要
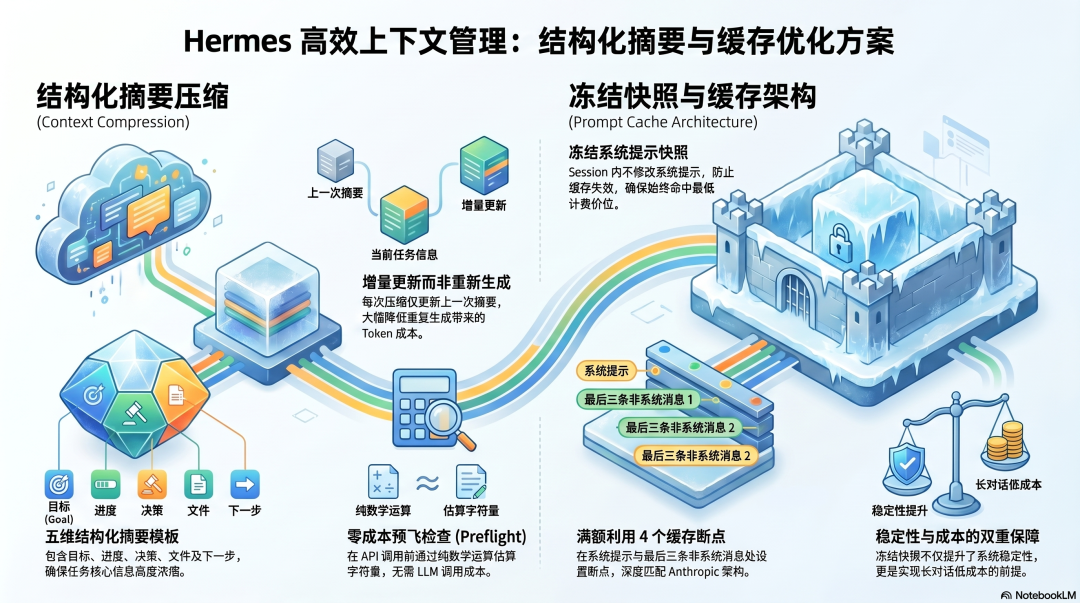
Hermes 的压缩设计相比 Claude Code 简单很多------一个 ContextCompressor 类,一种压缩策略:结构化摘要,持续更新。
摘要模板固定:
Goal(目标):任务的核心目标Progress(进度):已完成什么Decisions(决策):做了哪些关键选择,为什么Files(文件):涉及的关键文件Next Steps(下一步):接下来要做什么每次压缩不是从头生成,而是更新上一次的摘要。这保证了摘要的连续性,每次更新的 Token 成本比全量重新生成低。
预飞检查(should_compress_preflight)在每次 API 调用前运行:用字符数估算 Token 量,判断是否需要先压缩再调用。这是纯数学运算,没有 LLM 调用成本。
冻结快照:Prompt Cache 的架构保障
Hermes 的系统提示在 Session 开始时作为冻结快照注入,整个 Session 内不修改。
这不只是为了稳定性,是 Prompt Cache 的前提条件:如果系统提示中途被修改(哪怕一个字符),缓存前缀失效,所有后续调用都按原价计费。
冻结快照保证了系统提示层面始终命中缓存,把最大的成本来源锁在最低价位。
Cache 标记放置在:系统提示(第一个断点)+ 最后三条非系统消息(第二到第四个断点),充分利用 Anthropic 允许的最多 4 个断点。
OpenClaw:依赖外部状态管理,无内置压缩
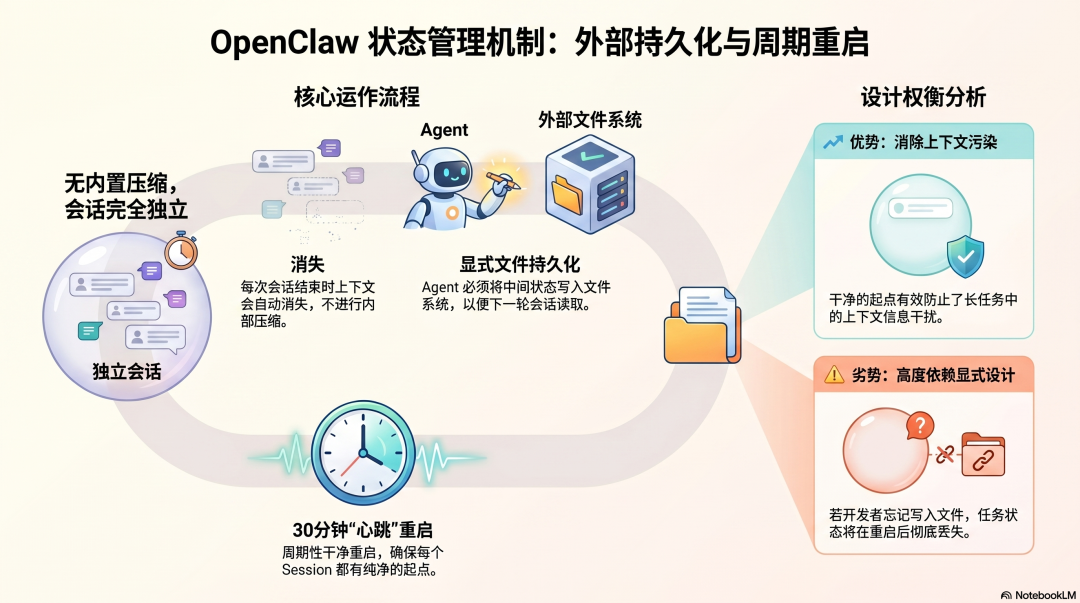
OpenClaw 没有内置的上下文压缩机制。
每次会话是独立的------会话结束,上下文消失。对于单次对话不会撑满上下文窗口的任务,这不是问题。对于需要跨多轮积累的长任务,状态延续完全依赖文件系统:Agent 必须把中间状态显式写进文件,下次 Session 才能接着做。
心跳机制(每 30 分钟一次新 Session)是这个模式的体现:不是在同一个 Session 里压缩上下文,而是周期性地"干净重启",每次从文件系统读取必要的状态继续工作。
这个设计的优点是每个 Session 都有干净的起点,不会积累上下文污染。代价是长任务的状态持久化完全依赖开发者的显式设计------忘记写入文件,下次就从头来过。
压缩策略的核心取舍
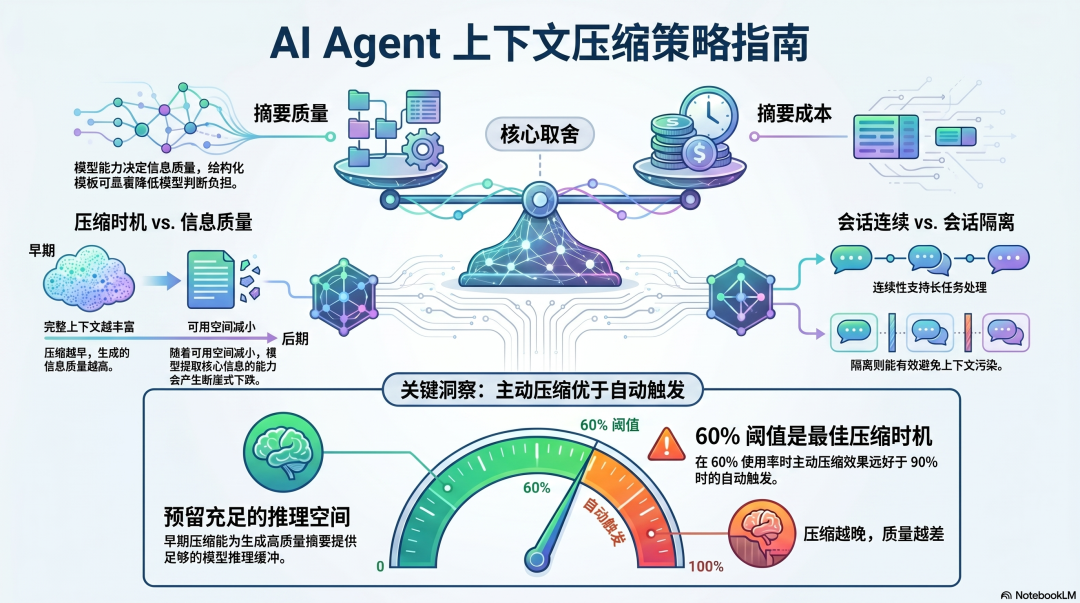
取舍一:摘要质量 vs. 摘要成本
好的摘要需要好的模型------你用什么模型来做摘要,决定了压缩后的信息质量。Claude Code 的 Session Memory 通过持续维护摘要分摊了成本;Hermes 的结构化模板减少了模型需要判断"什么重要"的工作量。
取舍二:压缩时机 vs. 信息质量
越早压缩,信息质量越好------还有完整的上下文可以参考。越晚压缩,可用空间越小,摘要质量越差。Claude Code 的建议是在 60% 主动压缩,而不是等待 70% 自动触发。
取舍三:Session 连续 vs. Session 隔离
OpenClaw 选择了 Session 隔离------每次干净重启,不积累上下文污染。Claude Code 和 Hermes 选择了 Session 连续------通过压缩维持工作状态。连续性让 Agent 能做更长的任务,但也增加了上下文管理的复杂度。
一个反直觉的洞察 :在 60% 上下文使用率时主动压缩,往往比在 90% 自动触发时效果更好------不是因为压缩本身不同,而是因为此时还有足够的推理空间来生成高质量摘要。压缩得越晚,摘要质量越差。