关键词: AI、大模型、验证码识别、爬虫、通用识别
近年来 AI 与大模型能力快速提升,许多过去依赖专用 OCR 或小模型的场景,正在转向「理解图像 + 结构化输出」的一体化方案。日常遇到的验证码------无论是简单的英文字母与数字,还是滑块、点选、问答类交互------本质都是对「图像内容是什么、要点哪里」的判定;这正是视觉语言模型(VLM)等大模型擅长的方向。
传统思路与大模型的差别
- 传统流水线: 对每种题型单独训练一套模型。题型一变就要重做一套。
- 大模型思路: 把验证码当作「看图回答问题」:输入整张图(或截图),输出坐标、选项序号或文本答案,同一套接口可覆盖多种题型,更接近通用识别。
在需要程序化处理大量页面、且页面验证码形态不一的场景(例如合规的数据采集、自动化测试、无障碍辅助等),这种「一套 API 对接多种题型」的模式,往往比为每种验证码单独维护模型更省事。
示例平台:HyperCalc(无限识别)
下面介绍一个面向开发者的在线识别服务:HyperCalc (https://hypercalc.cn/)。
据其公开页面描述,该平台支持多种常见题型,例如:
- 英数验证码
- 滑块 / 双滑块
- 文字点选、图标点选
- AI 问答选图
- AI 六宫格、九宫格

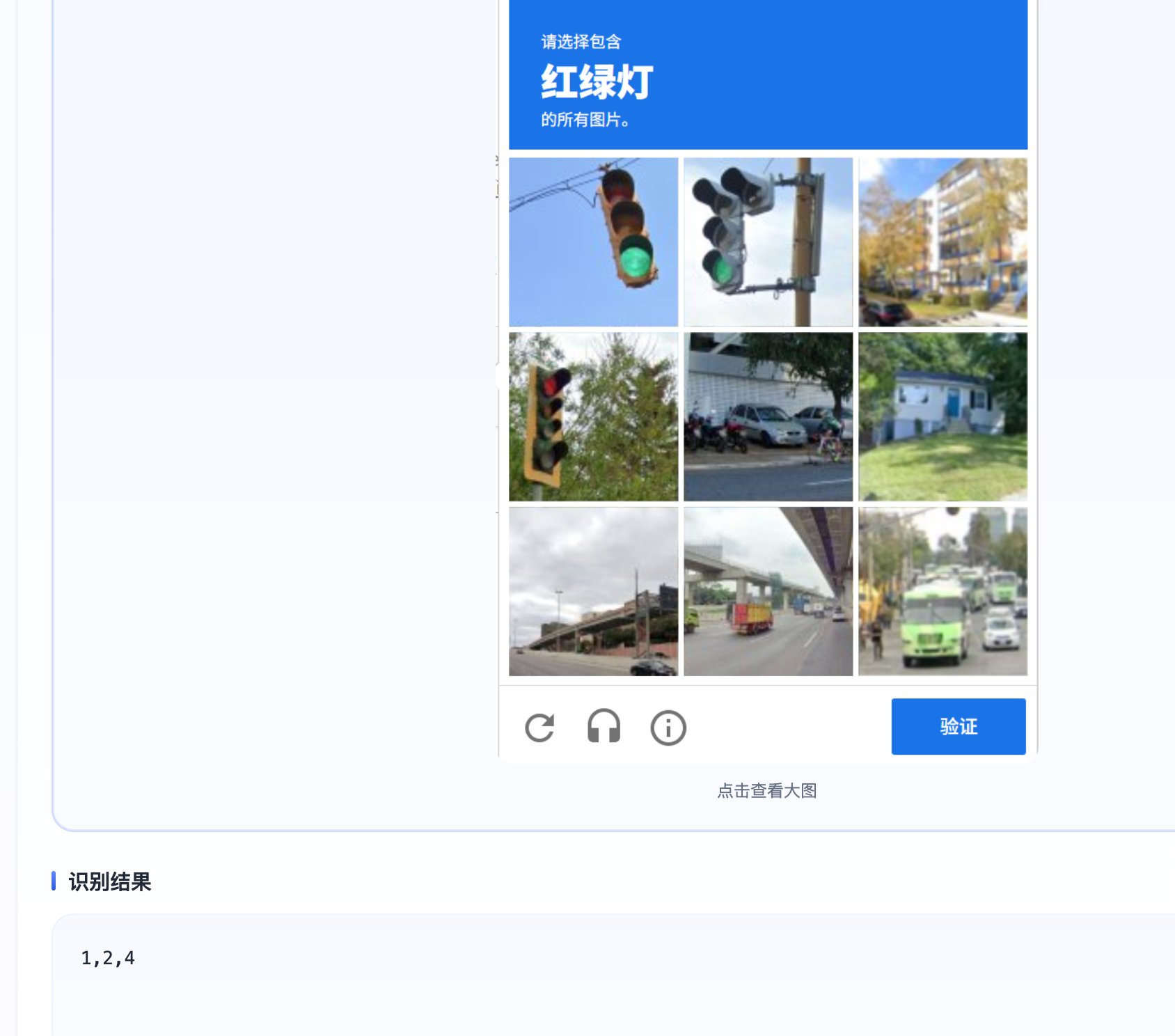
识别示例:


google二代,三代

对需要稳定对接「多种验证码形态」的脚本或业务系统来说,这类统一入口更像一种通用解决方案:不必为每种题型单独集邮式地对接不同服务商或自研模型。
合规提示: 任何自动化与识别能力都应限定在法律授权范围内使用(例如自有系统测试、已获授权的采集、无障碍场景等)。平台首页亦有使用者合规说明,使用前请阅读并遵守当地法规与站点服务条款。
调用示例(Python)
以下示例将本地验证码图片转为 Base64,调用公开预测接口(请将 secret 替换为你的 API Key,modelCode 按文档选用对应模型编号):
python
import requests
import base64
url = "https://hypercalc.cn/api/pub/model/predict"
with open("captcha.png", "rb") as f:
img_base64 = base64.b64encode(f.read()).decode()
resp = requests.post(url, json={
"secret": "your_api_key",
"modelCode": 1000,
"imageBase64": img_base64
})
data = resp.json()
print(data["data"]["recordId"]) # 预测记录 ID
print(data["data"]["result"]) # 识别结果实际接入时建议额外处理:HTTP 状态码与非 JSON 响应、超时与重试、modelCode 与各题型文档对齐,以及对返回结构做版本兼容。
小结
AI 与大模型 正在把验证码识别从「一种题型一套模型」推向「多题型统一接口」的通用识别 路径;在合法合规前提下,这对需要规模化自动化、又不愿被验证码形态牵着走的开发者(包括部分爬虫 与自动化场景)是一种务实的工程选择。若你希望快速验证多种题型,可到 HyperCalc 查看模型列表与文档,再结合上面的示例完成最小闭环。