引言
字符引用(Character References)是 HTML 和 XML 中用于表示无法直接输入或具有特殊含义的字符的转义序列。通过字符引用,开发者可以确保文档中的字符得到正确解析并且不会被误解为 HTML 标记。字符引用对于保证跨浏览器兼容性和避免编码问题至关重要。
本文将详细介绍字符引用的类型、语法以及常见应用,并列出前端开发中经常使用的字符引用。
什么是字符引用?
字符引用(Character Reference) 是 HTML 和 XML 标记语言中的一种转义机制,用于通过 ASCII 字符序列来表示那些无法直接输入、具有特殊语法含义或当前编码不支持的字符。
它的本质是一个替换规则:当解析器遇到特定的字符序列时,将其替换为对应的 Unicode 字符。
字符引用的分类

HTML 规范明确定义了两种字符引用类型:
命名字符引用(Named Character Reference)
使用预定义的英文名称来引用字符。
html
& <!-- & 符号 -->
< <!-- < 小于号 -->
> <!-- > 大于号 -->
" <!-- " 双引号 -->
' <!-- ' 单引号 -->
<!-- 不间断空格 -->
© <!-- © 版权符号 -->语法规则:
- 以
&开头 - 后跟预定义的实体名称(区分大小写)
- 以
;结尾(在 HTML5 中,某些情况下可省略,但强烈建议保留)
数字字符引用(Numeric Character Reference)
数字字符引用根据进制表示方式,分为以下两类:
十进制数字字符引用(Decimal Numeric Character Reference)
使用十进制数字表示 Unicode 码点值。
语法结构:
txt
&# + 十进制数字 + ;示例:
html
& <!-- & 符号,Unicode U+0026 -->
< <!-- < 小于号,Unicode U+003C -->
  <!-- 不间断空格,Unicode U+00A0 -->
© <!-- © 版权符号,Unicode U+00A9 -->
€ <!-- € 欧元符号,Unicode U+20AC -->十六进制数字字符引用(Hexadecimal Numeric Character Reference)
使用十六进制数字表示 Unicode 码点值,以 x 或 X 前缀标识进制。
语法结构:
txt
&#x + 十六进制数字 + ; (小写 x)
&#X + 十六进制数字 + ; (大写 X,同样有效)示例:
html
& <!-- & 符号,十六进制 0x26 -->
< <!-- < 小于号,十六进制 0x3C -->
  <!-- 不间断空格,十六进制 0xA0 -->
© <!-- © 版权符号,十六进制 0xA9 -->
€ <!-- € 欧元符号,十六进制 0x20AC -->
😀 <!-- 😀 Emoji,十六进制 0x1F600 -->分类对比表
| 特性 | 命名字符引用 | 数字字符引用 |
|---|---|---|
| 可读性 | 高(© 直观) |
低(© 不直观) |
| 覆盖范围 | 仅预定义列表 | 所有 Unicode 字符 |
| 记忆难度 | 需要记忆名称 | 需要查询码点 |
| HTML5 支持 | 完整 | 完整 |
字符与 Unicode 码点的双向转换
JavaScript 提供了几个内置方法来实现字符与 Unicode 码点之间的双向转换。
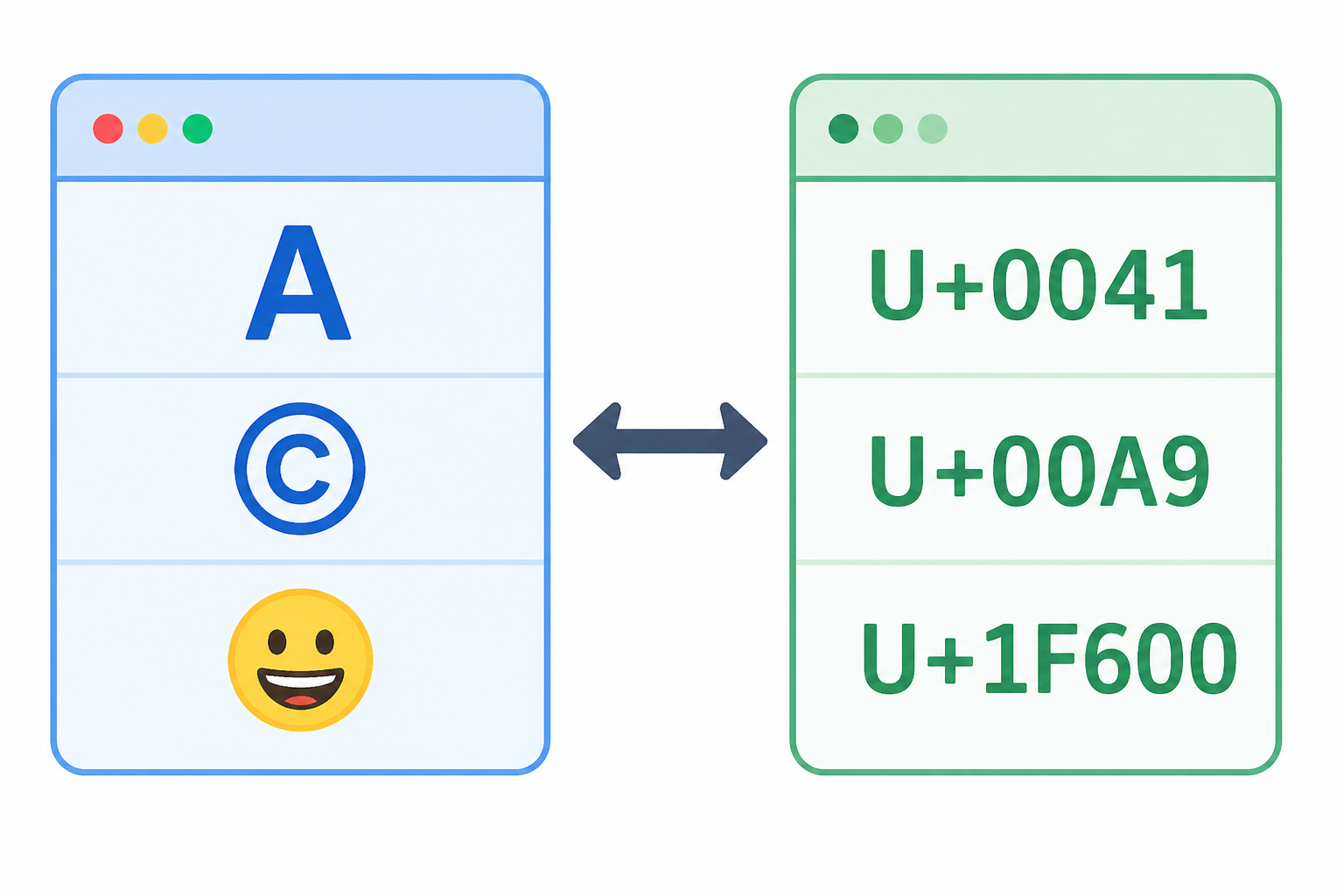
字符 → Unicode 码点
方法1:charCodeAt()
适用于基本多文种平面(BMP)的字符,即绝大部分常用字符。
js
// 基本用法
const char = 'A';
const codePoint = char.charCodeAt(0);
const hex = codePoint.toString(16);
console.log(`字符 "${char}" 的码点:`);
console.log(`十进制:${codePoint}`);
console.log(`十六进制:${codePoint.toString(16).toUpperCase()}`);
console.log(`HTML实体:&#${codePoint};`);
js
// 封装为函数
function getUnicodeInfo(char) {
const dec = char.charCodeAt(0);
const hex = dec.toString(16).toUpperCase().padStart(4, '0');
return {
char: char,
decimal: dec,
hexadecimal: hex,
htmlEntity: `&#${dec};`,
unicodeNotation: `U+${hex}`
};
}
console.log(getUnicodeInfo('<'));
console.log(getUnicodeInfo('©'));方法2:codePointAt()
ES6 引入的方法,正确支持所有 Unicode 字符(包括 Emoji 和罕见汉字)。
js
// 正确处理 Emoji
const emoji = '😀';
const codePoint = emoji.codePointAt(0);
const hex = codePoint.toString(16).toUpperCase();
console.log(`Emoji "${emoji}" 的码点:`);
console.log(`十进制:${codePoint}`);
console.log(`十六进制:U+${hex}`);
console.log(`HTML实体:&#${codePoint};`);
js
// 通用封装函数(支持任意字符)
function getCodePoint(char) {
const code = char.codePointAt(0);
const hexRaw = code.toString(16).toUpperCase();
// 规则:少于 4 位补到 4 位;4 位以上保持原样
const hexFormatted = hexRaw.length < 4 ? hexRaw.padStart(4, '0') : hexRaw;
return {
char: char,
decimal: code,
hex: hexRaw,
htmlDecimal: `&#${code};`,
htmlHex: `&#x${hexRaw};`,
unicodeNotation: `U+${hexFormatted}`
};
}
// 测试
console.log(getCodePoint('A'));
console.log(getCodePoint('<'));
console.log(getCodePoint('汉'));
console.log(getCodePoint('😀'));
console.log(getCodePoint('𠮷'));Unicode 码点 → 字符
方法1:String.fromCharCode()
仅适用于码点 ≤ 0xFFFF 的字符。
js
const char1 = String.fromCharCode(65);
const char2 = String.fromCharCode(0x41);
const char3 = String.fromCharCode(27721);
console.log(char1);
console.log(char2);
console.log(char3);方法2:String.fromCodePoint()
ES6 引入,支持全部 Unicode 码点。
js
// 正确转换所有字符
const emoji = String.fromCodePoint(128512);
const rareChar = String.fromCodePoint(0x20BB7);
console.log(emoji); // 😀
console.log(rareChar); // 𠮷
// 批量转换
const codePoints = [65, 27721, 128512, 0x20BB7];
const chars = String.fromCodePoint(...codePoints);
console.log(chars); // "A汉😀𠮷"命名字符引用详解
历史渊源
命名字符引用的概念借鉴自 SGML 的实体机制,但仅保留了其中用于字符表示的内部实体形式。HTML 4.01 定义了 252 个命名字符引用。HTML5 进一步扩展至 2,231 个,新增内容主要为数学符号、希腊字母及其大小写变体。
必须转义的字符
以下五个字符在 HTML 中具有特殊语义,需要根据场景使用字符引用:

| 字符 | 名称 | 命名字符引用 | 数字引用 | 必须转义的场景 |
|---|---|---|---|---|
& |
AND 符号 | & |
& |
所有场景(字符引用起始符) |
< |
小于号 | < |
< |
所有场景(标签起始符) |
> |
大于号 | > |
> |
建议在所有场景中转义以确保安全 |
" |
双引号 | " |
" |
双引号包裹的属性值中 |
' |
单引号 | ' |
' |
单引号包裹的属性值中 |
常见命名字符引用

空格类
html
<!-- U+00A0 不间断空格 (Non-Breaking Space) -->
  <!-- U+2002 半角空格 (En Space) -->
  <!-- U+2003 全角空格 (Em Space) -->
  <!-- U+2009 窄空格 (Thin Space) -->引号类
html
" <!-- U+0022 直双引号 -->
' <!-- U+0027 直单引号 -->
" <!-- U+201C 左双引号 " -->
" <!-- U+201D 右双引号 " -->
' <!-- U+2018 左单引号 ' -->
' <!-- U+2019 右单引号 ' -->
<< <!-- U+00AB 左书名号 << -->
>> <!-- U+00BB 右书名号 >> -->数学符号
html
× <!-- U+00D7 乘号 × -->
÷ <!-- U+00F7 除号 ÷ -->
± <!-- U+00B1 正负号 ± -->
∞ <!-- U+221E 无穷 ∞ -->
∑ <!-- U+2211 求和 ∑ -->
∏ <!-- U+220F 求积 ∏ -->
∫ <!-- U+222B 积分 ∫ -->
√ <!-- U+221A 根号 √ -->货币符号
html
¢ <!-- U+00A2 美分 ¢ -->
£ <!-- U+00A3 英镑 £ -->
€ <!-- U+20AC 欧元 € -->
¥ <!-- U+00A5 日元 ¥ -->箭头
html
← <!-- U+2190 左箭头 ← -->
↑ <!-- U+2191 上箭头 ↑ -->
→ <!-- U+2192 右箭头 → -->
↓ <!-- U+2193 下箭头 ↓ -->
↔ <!-- U+2194 左右箭头 ↔ -->
↵ <!-- U+21B5 回车箭头 ↵ -->数字字符引用详解
十进制与十六进制
html
<!-- 十进制表示 -->
© <!-- © -->
€ <!-- € -->
<!-- 十六进制表示(x 前缀) -->
© <!-- © -->
€ <!-- € -->
<!-- 十六进制表示(X 前缀,同样有效) -->
© <!-- © -->Unicode 码点范围
HTML5 支持所有有效的 Unicode 码点(除控制字符和替换字符外):
- 基本多文种平面(BMP) :
U+0000到U+FFFF - 辅助平面 :
U+10000到U+10FFFF
html
<!-- Emoji 字符(超出 BMP) -->
😀 <!-- 😀 -->
🎉 <!-- 🎉 -->数字引用的优势
- 完整性:可表示任何 Unicode 字符,包括最新 Emoji
- 精确性:避免名称记忆错误
- 跨语言:不受 HTML 版本限制
为什么需要字符引用
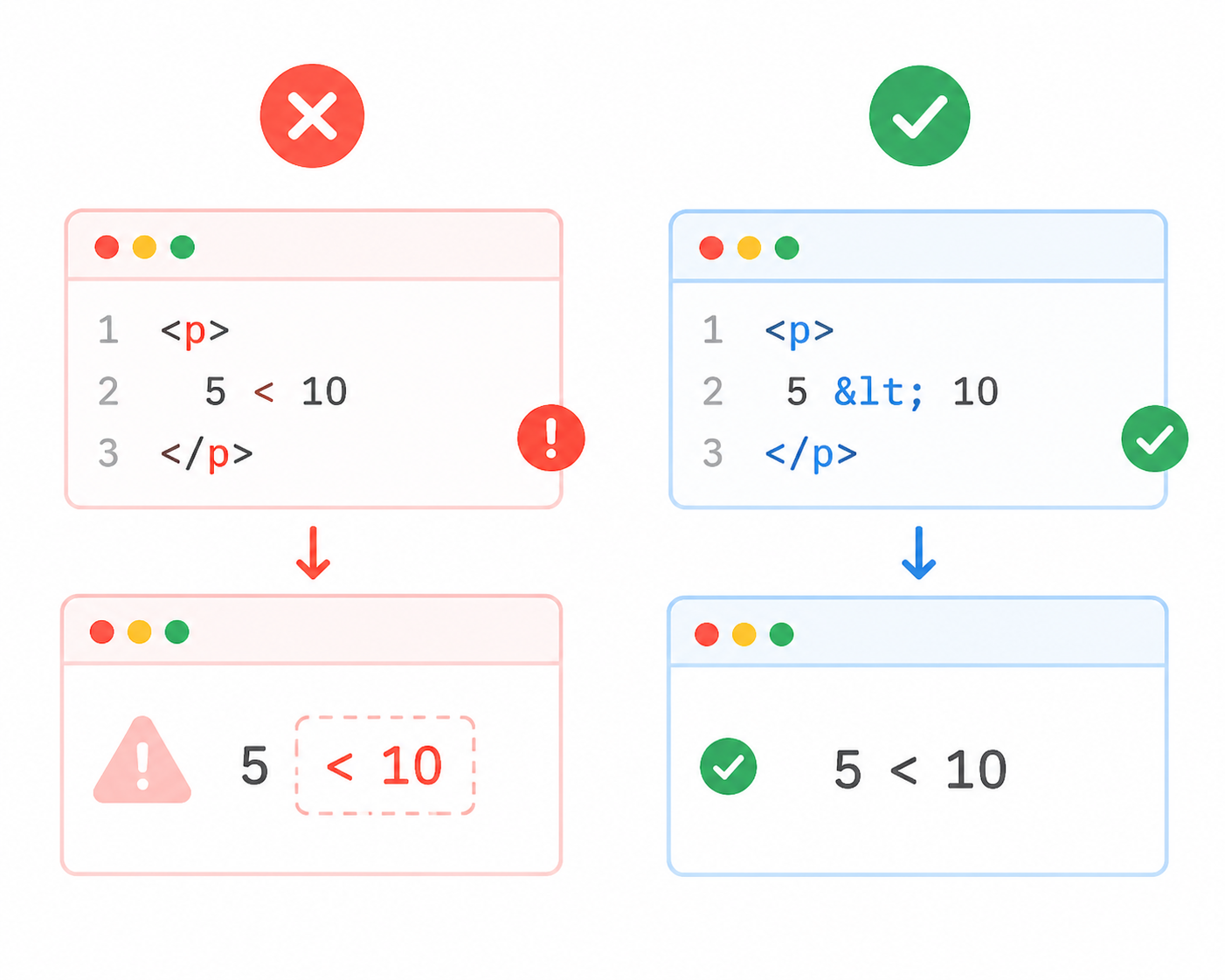
保留字符冲突
HTML 使用特定字符作为标记语法的一部分:
html
<!-- 错误:浏览器会解析为标签 -->
<p>开始学习 <p> 元素</p>
<!-- 正确:使用字符引用 -->
<p>开始学习 <p> 元素</p>编码限制
当文档使用 ASCII 或 ISO-8859-1 编码时,无法直接表示非 ASCII 字符:
html
<!-- 在 ASCII 编码文档中 -->
<p>版权所有 © 2026</p> <!-- 正确 -->
<p>版权所有 © 2026</p> <!-- 可能显示为乱码 -->不可见字符
某些控制字符或特殊空格无法直接输入:
html
<p>A&bsp; B</p>键盘不可输入字符
html
<!-- 键盘上没有的符号 -->
<p>温度:25°C</p> <!-- 25°C -->最佳实践
始终使用分号
html
<!-- 推荐 -->
<tag>
<!-- 不推荐 -->
<tag>在属性值中转义引号
html
<!-- 双引号包裹的属性 -->
<p title="He said "Hello"">test</p>
<!-- 单引号包裹的属性 -->
<p title='It's working'>test</p>优先使用名称
html
<!-- 推荐:可读性好 -->
© > <
<!-- 不推荐:难以辨认 -->
© > <双重转义
html
<p>&lt;</p> <!-- 显示为 < 而不是 < -->大小写敏感
HTML5 中命名字符引用区分大小写:
html
© <!-- 正确:© -->
© <!-- 正确:HTML5 支持大写变体 -->
&Copy; <!-- 错误:不存在 -->JS 中不要使用字符引用
html
<!-- 错误:在 script 中使用字符引用 -->
<script>
var text = "5 < 10"; // 实际字符串包含 "<" 而不是 "<"
</script>
<!-- 正确:在 script 中使用 Unicode 转义或直接字符 -->
<script>
var text = "5 < 10"; // 直接字符(如果编码支持)
var text = "5 \u003C 10"; // JavaScript Unicode 转义
</script>提示 :字符引用在 HTML 解析阶段被替换,
<script>和<style>元素的内容被视为原始文本,不解析字符引用。
URL 中的字符引用
html
<!-- 错误:在 href 中使用字符引用 -->
<a href="https://example.com?foo=1&bar=2">
<!-- 正确:URL 中应使用 URL 编码 -->
<a href="https://example.com?foo=1&bar=2">
<!-- 或 -->
<a href="https://example.com?foo=1%26bar=2">注意 :在 HTML 属性中,
&必须转义为&,但浏览器会在发送到服务器前将其解码回&。在 URL 路径或查询参数中,应使用 URL 编码(%26)而非 HTML 字符引用。
总结

字符引用是 HTML 解析器的内置替换机制,用 ASCII 序列表示任意 Unicode 字符。它分为命名字符引用与数字字符引用两种形式,分别解决可读性与覆盖范围的需求。& 与 < 在所有场景下必须转义,>、"、' 在特定上下文中需要转义。理解字符引用的本质,就是理解 HTML 如何在纯文本层面安全地表达任意字符------这是编写兼容、健壮网页的基础。