写在前面
打开一个电商首页时,浏览器表面上像是在拿一份 HTML。可真正发生的事远不止这一件:样式、脚本、图片、字体、接口数据,会一批批接着发出去。页面越复杂,请求越多;请求一多,协议的短板就会一起冒出来。
很多资料会直接给结论:HTTP/1.1 有长连接,HTTP/2 有多路复用,HTTP/3 基于 QUIC。这些话都对,但对初学者不够友好,因为它没有回答最关键的问题:上一代到底卡在哪里,下一代又到底只解决了什么。
这篇文章就按最朴素的思路来讲,不把你一开始就扔进术语堆里,而是只围绕一条主线往前走:
HTTP/1.1先解决"别每个请求都重新建连接",HTTP/2再解决"别继续靠堆连接来并发",HTTP/3最后解决"同一条连接里的不同请求不该因为一个丢包一起卡住"。
先看一张总览图,对全局先有个印象:
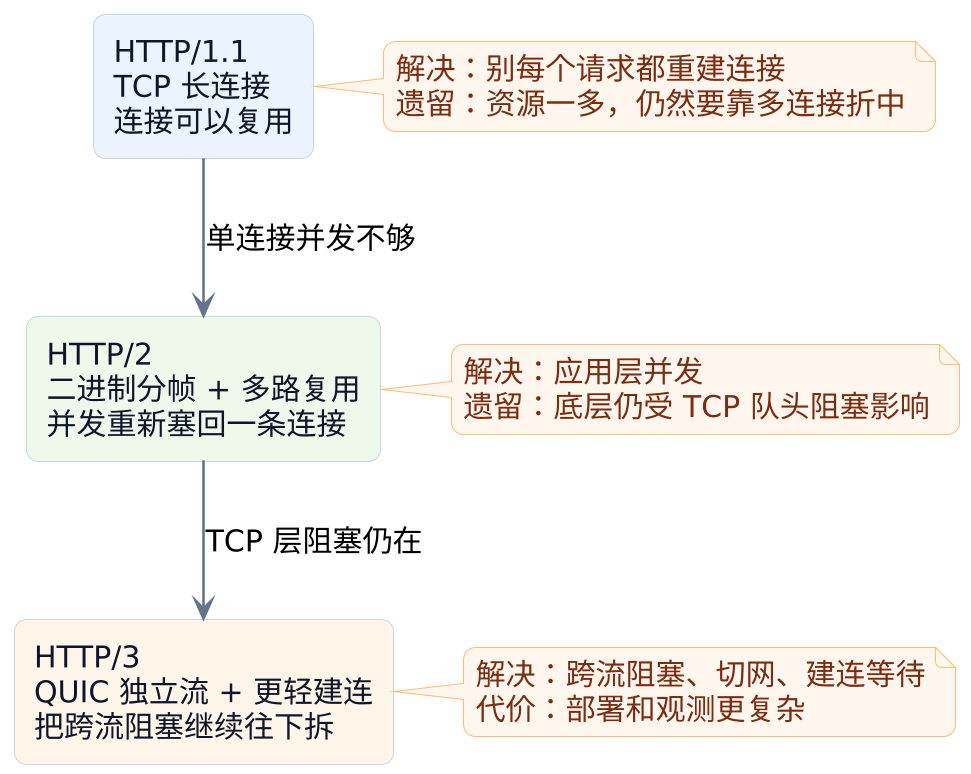
先把问题想简单一点
整篇文章的主线,其实就是三个问题:连接太贵怎么办、一条连接怎么并发、并发之后为什么还会一起卡。
你可以先把浏览器加载页面想成一条高速公路上的送货过程:
- 浏览器要的不是一件货,而是一大批货。
- 这些货大多都要送去同一个地方,也就是同一个站点。
- 用户又很敏感,不希望哪怕只是慢半拍。
所以问题很快就会变成三连问:
- 如果每发一个请求都重新建连接,代价是不是太大了?
- 如果只守着一条连接,几十个请求怎么一起往前走?
- 如果已经让它们在一条连接里并发了,为什么丢一个包还会把别的请求也拖住?
先别急着背术语
如果先不抠术语,可以把"消息、流、帧、数据包"都当成不同大小的"货物单位"。
第一次看这类文章,最容易被"连接""流""帧""数据包"绕晕。先把它们当成下面这组很朴素的概念:
| 词 | 先把它理解成什么 |
|---|---|
连接 |
一条真正拿来运东西的通信通道 |
消息 |
一次完整的请求或响应 |
流 |
一条连接里给某个请求单独留出来的逻辑车道 |
帧 |
比完整请求更小的一块块小货箱 |
数据包 |
网络里真正飞来飞去的一包数据 |
队头阻塞 |
前面的东西没补齐,后面的东西明明到了也得等 |
HPACK / QPACK |
头字段压缩机制,目的是别把重复的请求头一遍遍原样重发 |
这组概念收拢起来,其实就是一句话:
消息是"我要办的一件事",流是"这件事走哪条车道",帧是"在线路上真正一块块发送的东西"。
第一代:HTTP/1.1 先解决的是"别反复建连接"
如果换成更生活化的说法,HTTP/1.1 最重要的贡献,是把"每次都重新打电话"改成"电话接通后尽量别挂",但它还没解决"多人同时说话"这个问题。
先从最容易理解的一层开始。假设浏览器要拿一个页面和几十个资源。如果每个请求都经历一次"建连 -> 发请求 -> 收响应 -> 断开",这件事会非常浪费。
HTTP/1.1 的第一个重要改进,就是把长连接做起来。它想解决的是:
- 不要每次请求都重新建连接。
- 已经建好的连接,尽量接着用。
- 让握手和慢启动的代价别反复重来。
这一步很重要,但它只解决了"省连接",还没有真正解决"高并发"。
HTTP/1.1解决的是"少建连接",不是"单连接里高效并发很多请求"。
为什么一条连接很快就不够用
如果浏览器已经拿到 HTML,接下来还要继续拉 CSS、JS、图片和接口数据,而这些请求都挤在一条连接里排队,那么后面的请求天然要等前面的响应往前推。
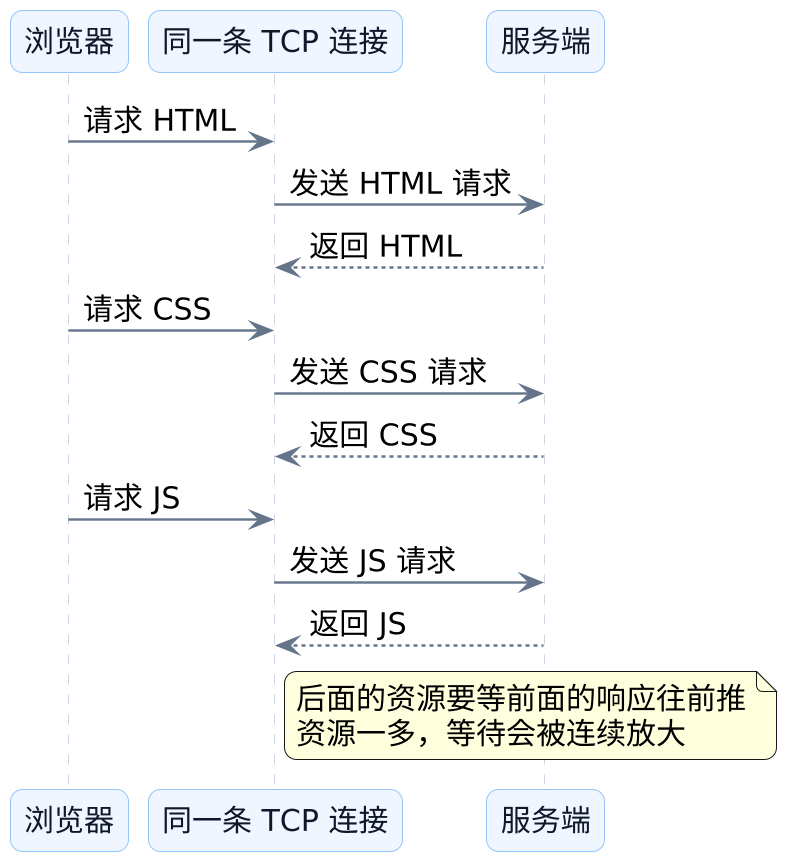
这时候你会发现,连接虽然复用了,但请求还是像在排长队。
pipelining 为什么没有真正救场
HTTP/1.1 并不是完全没尝试过并发。它提出过 pipelining,想法是:客户端可以先把多个请求连续发出去,不必严格等前一个响应完整结束后再发下一个。
它没有成为主流,主要不是因为"理论不好",而是因为"现实不稳":
- 前面的响应慢,后面的响应还是容易跟着等。
- 代理、服务器、网络设备的兼容性一直不够理想。
- 浏览器面对的是整个互联网,不能把主路径押在一套实现并不稳的机制上。
对于工程系统来说,理论能优化,但现实不稳定,往往就等于"不能作为主力方案"。
浏览器最后用了什么折中
现实世界里,浏览器最后采用的是一个非常朴素的办法:同一个站点不只守着一条 TCP 连接,而是并发开多条。
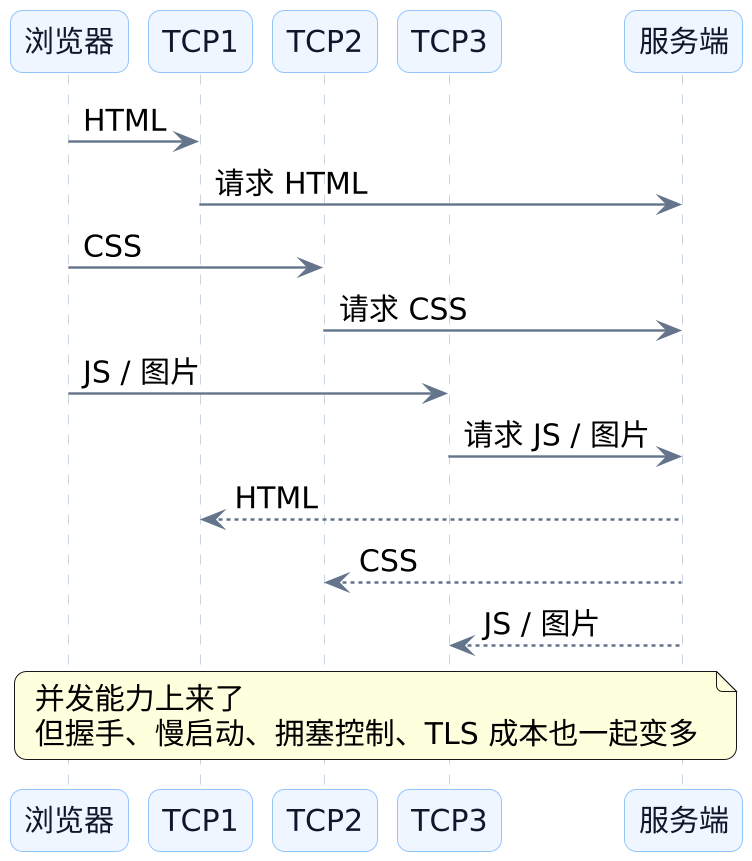
这很像收费站排队。只有一条车道时,车一多就会堆起来;多开几条车道,队伍确实会分散,但代价也会一起冒出来:
- 更多连接意味着更多握手。
- 每条连接都有自己的慢启动和拥塞控制。
HTTPS场景里还会重复承担加密协商成本。- 多条连接之间会竞争带宽,未必真能线性提速。
说到底,HTTP/1.1 的边界就在这里:
HTTP/1.1让"反复建连"没那么痛了,但它没有优雅地解决"同一条连接里怎么并发承载很多请求"。
这就是 HTTP/2 出场的原因。
第二代:HTTP/2 真正改的是"请求在连接里怎么排"
换个更生活化的说法,HTTP/2 真正厉害的地方,不是口号里的"多路复用",而是它先把大请求拆成了很多小块,之后这些小块才有机会交错前进。
很多人第一次学 HTTP/2,会把它记成"多路复用"。这当然没错,但如果只记这四个字,还是会觉得悬在空中,因为会立刻冒出一个追问:
为什么 HTTP/1.1 做不到,而 HTTP/2 做到了?
答案是:因为 HTTP/2 先把大块请求拆小了。
HTTP/2真正重写的,不是几个字段名,而是消息在连接里的组织方式。
先理解"消息、流、帧"这三层
HTTP/2 最值得先看懂的,就是"消息、流、帧"这三层关系。
| 层次 | 你可以先把它理解成什么 |
|---|---|
| 消息 | 一次完整请求或响应 |
| 流 | 这次请求在连接里的专属逻辑车道 |
| 帧 | 真正在线路上一块块发送的二进制单元 |
把这三层画出来,会更直观:
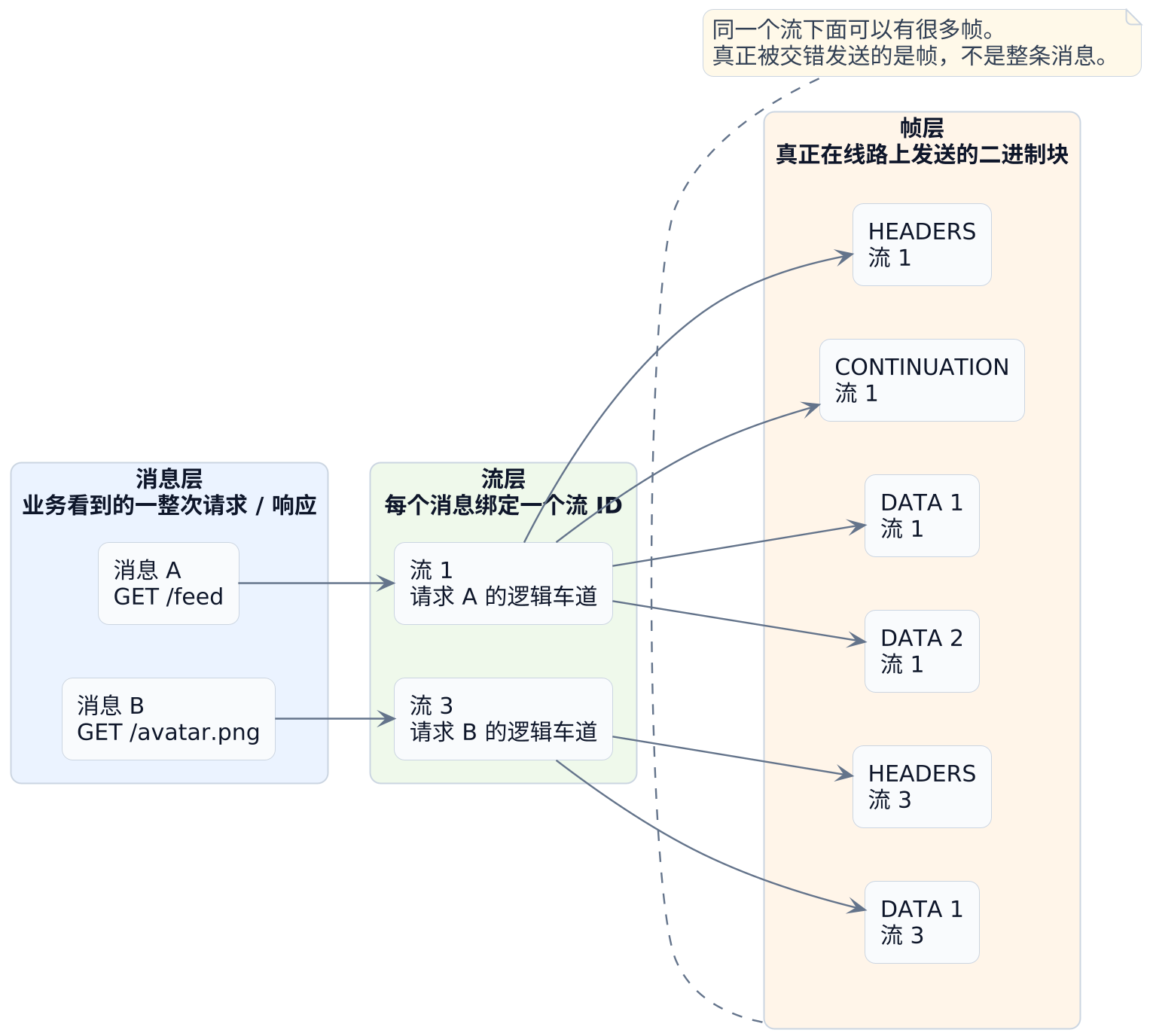
把它翻成白话就是:
- 消息层看到的是"我要发一个完整请求"。
- 流层看到的是"这个请求走流
1,另一个请求走流3"。 - 帧层看到的是"现在先发一小块头,再发一小块数据,之后还可以穿插发别的流"。
接收方不再靠"谁先发完"来区分请求,而是靠流标识把交织出现的帧重新拼回各自的消息。
为什么必须先把消息拆小
如果你不把消息拆小,那么一个请求还是一整大箱货,另一个请求也还是一整大箱货。就像两辆超长卡车要同时挤进一条窄路,它们几乎不可能优雅地交错通行。
所以 HTTP/2 的关键,不是一句"共用一条连接"就能说完,而是它先做了这件更基础的事:
HTTP/2先把完整请求拆成更小的帧,之后多路复用才真正有落脚点。
帧到底能拆成几块
这里最容易产生的误解是:图里常画 HEADERS + DATA 两个框,于是很多人会以为"一个请求最多就拆成两块"。这不对。
真实世界里,一个请求完全可以拆成很多块。
先把规则记成三条就够了:
| 要发送的内容 | 常见帧类型 | 能不能拆成多块 |
|---|---|---|
| 头字段块 | HEADERS + CONTINUATION |
可以 |
| 消息体 | DATA |
可以 |
| 控制信息 | SETTINGS、WINDOW_UPDATE、RST_STREAM |
通常本身就是单独控制帧 |
把它翻成更口语的话,就是:
- 头可以拆成
1个HEADERS加N个CONTINUATION。 - 体可以拆成
N个DATA。 N没有"最多只能等于2"这种限制。
下面这个图,就是把"头字段块"和"消息体"怎么拆分画出来:
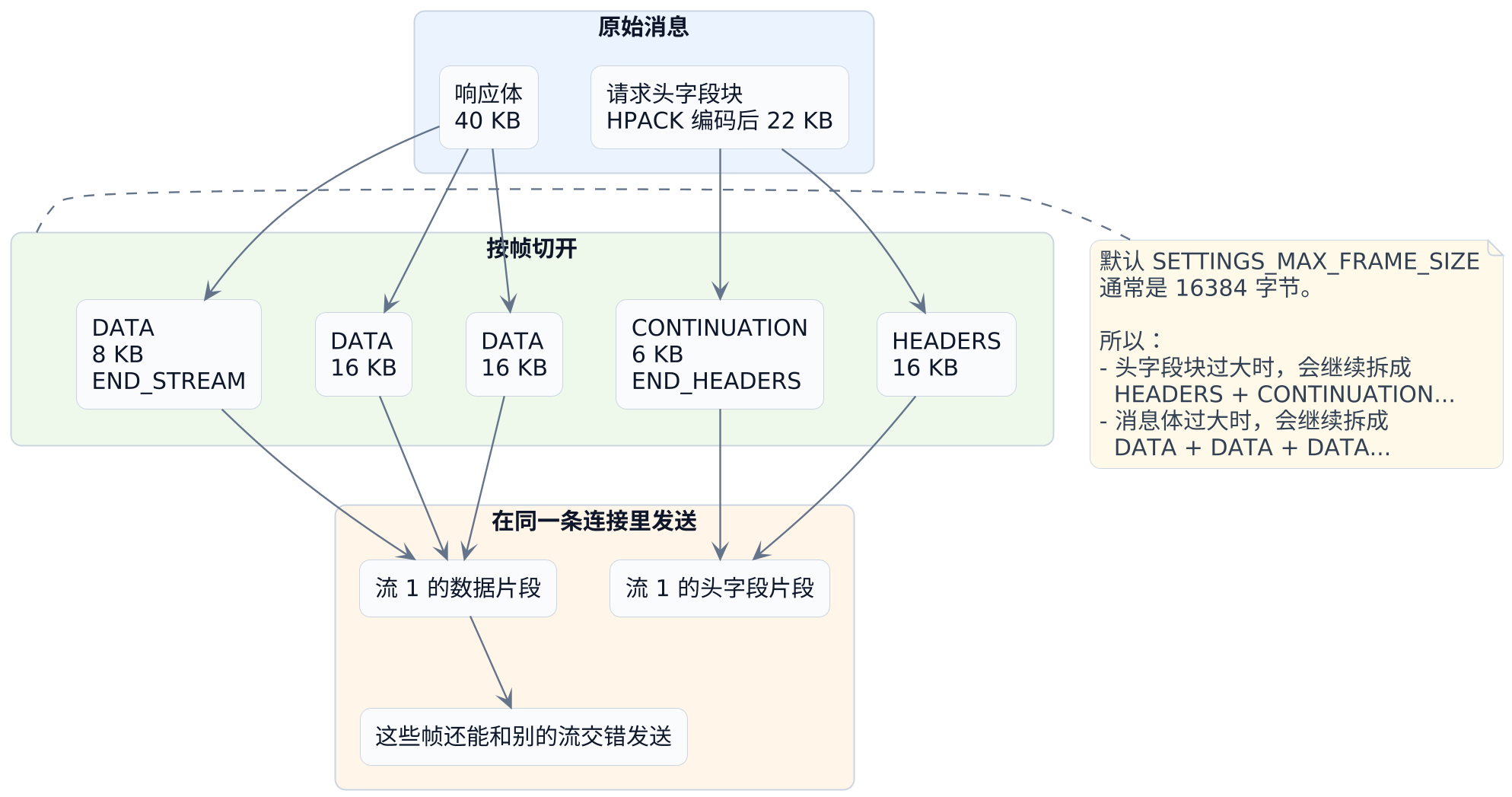
看一个很具体的例子。假设:
- 某次请求的头字段经过
HPACK压缩后是22 KB - 某次响应体是
40 KB - 协商后的
SETTINGS_MAX_FRAME_SIZE还是默认16384字节,也就是16 KB
那它很可能会被拆成:
| 部分 | 拆分结果 | 说明 |
|---|---|---|
头字段块 22 KB |
HEADERS 16 KB + CONTINUATION 6 KB |
最后一帧带 END_HEADERS |
响应体 40 KB |
DATA 16 KB + DATA 16 KB + DATA 8 KB |
最后一帧带 END_STREAM |
所以更稳妥的说法是:
一个
HTTP/2请求不是"一个头帧加一个数据帧",而是"一个消息会被拆成很多个更小的帧,再和别的流交错发送"。
多路复用到底长什么样
当请求被拆成帧以后,多路复用才真的开始成立。它不再是"请求 A 全发完,再轮到请求 B",而是可以变成"请求 A 发一点,请求 B 发一点,再回来发请求 A 的后半段"。这就像超市不再要求收银员把一整车货一次扫完,而是先扫几件 A 的,再扫几件 B 的,最后系统再按小票把它们各自归回原来的顾客。
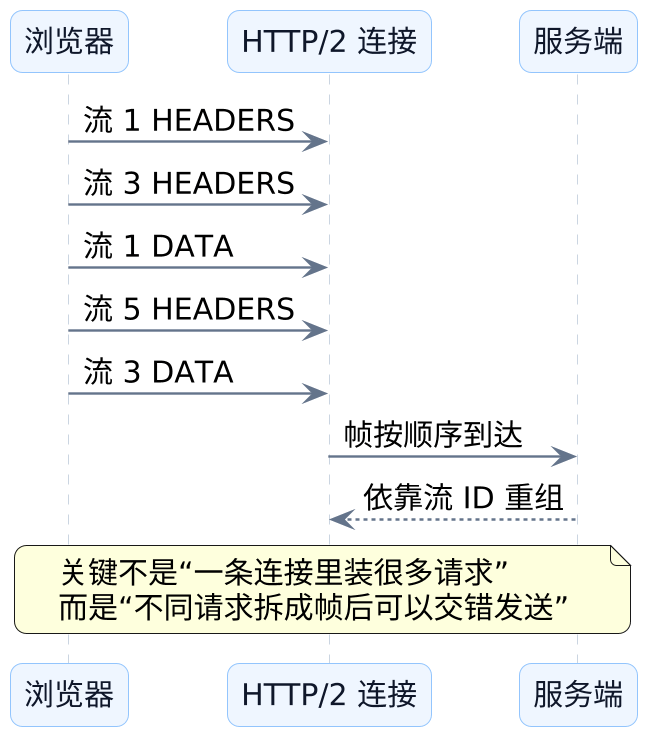
HTTP/2 的多路复用,不是简单地让很多请求共用一条连接,而是让不同请求拆成很多小帧后,在同一条连接里交错前进。
HPACK 到底是什么,压的又是什么
讲到这里,还剩下一个很现实的问题:请求头太重复了。
想象一下浏览器连续发两个请求:
| 第一次请求 | 第二次请求 |
|---|---|
:method: GET |
:method: GET |
:scheme: https |
:scheme: https |
:path: /feed |
:path: /profile |
accept-language: zh-CN |
accept-language: zh-CN |
cookie: sid=abc123; theme=dark |
cookie: sid=abc123; theme=dark |
如果每次都把这些字段原样重发,很浪费。于是 HTTP/2 引入了 HPACK。
HPACK压缩的不是整个请求体,而是头字段;它的目标是尽量别把重复的字段名和值一遍遍原样发送。
可以先把 HPACK 想成一个很会省话的记录员,它主要做三件事:
- 常见字段先编号,能直接报编号就不再报全文。
- 这条连接里刚出现过、之后大概率还会再出现的字段,记进动态表。
- 还得发送的字符串,再想办法压得更短。
下面这张图,把这个过程画出来:
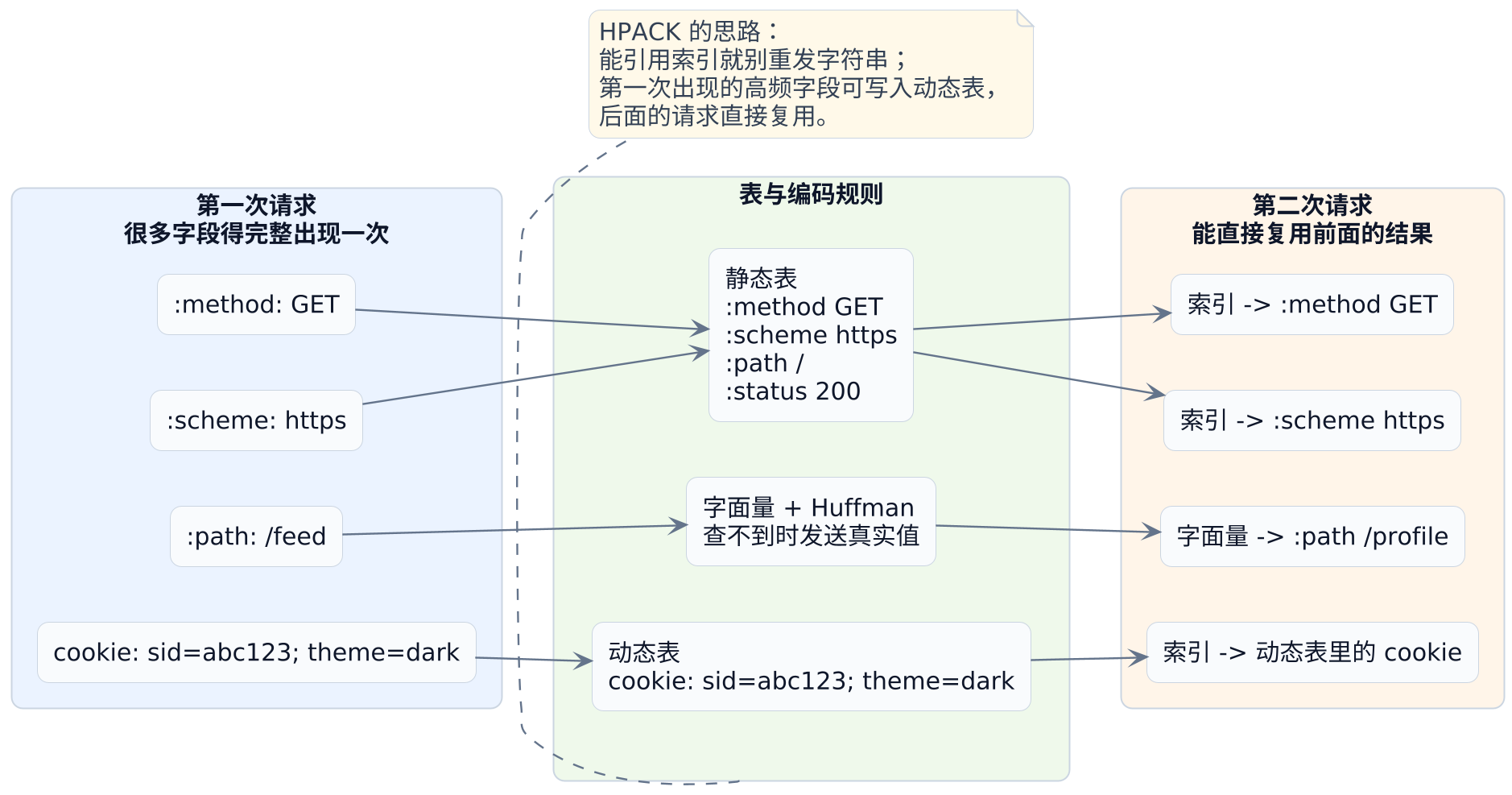
第一步:静态表
HPACK 自带一张静态表,里面放着一些非常高频的字段,比如 :method: GET、:scheme: https、:path: / 这样的常见组合。
这就意味着,像 :method: GET 这样的字段,很多时候不用再把字符串原样发一遍,而是可以直接发"索引 2"。接收方一查表,就知道你在说什么。
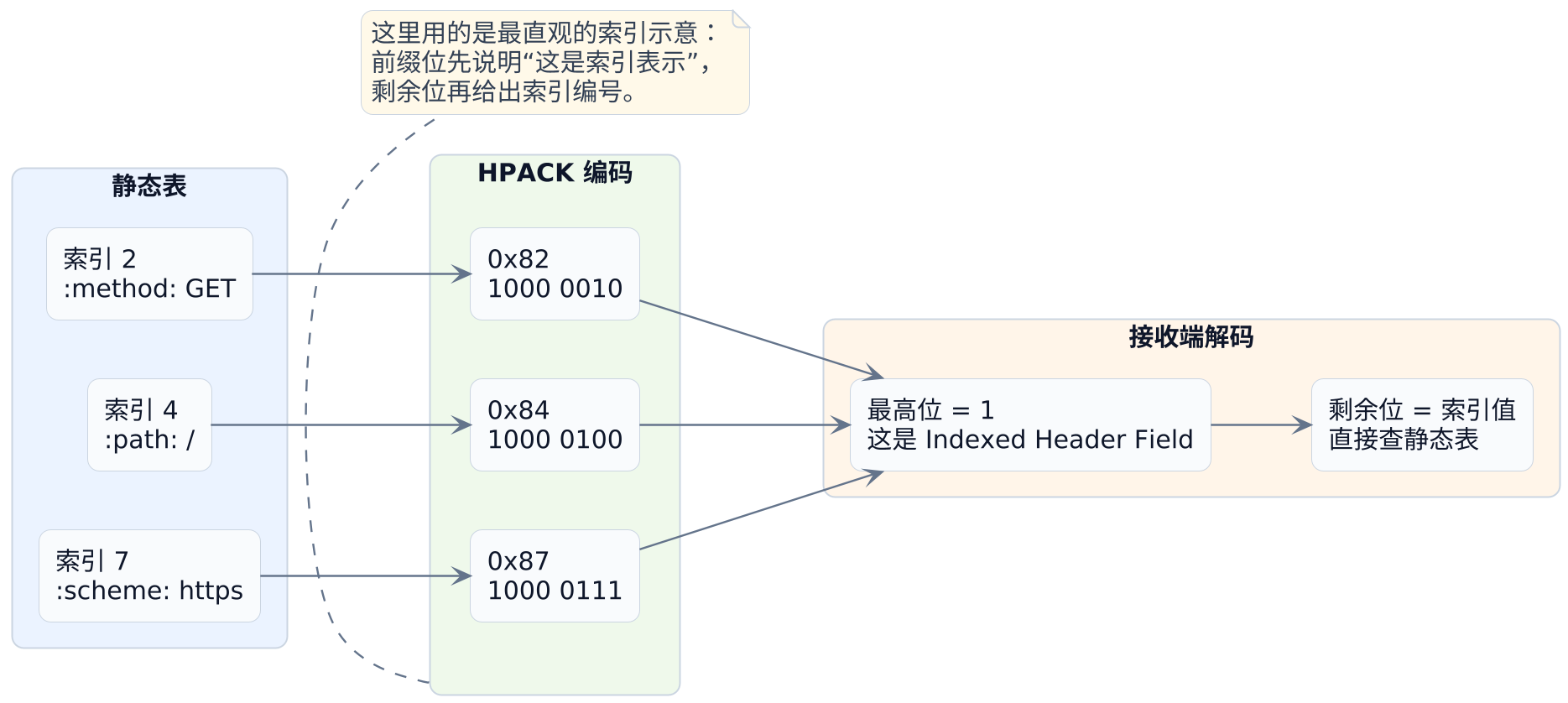
索引在编码里到底长什么样
这里很多人都会觉得抽象:索引到底是不是只存在于概念里?不是。
它在编码里就是实打实的位模式。比如:
| 要表达的字段 | 静态表索引 | 可能的编码字节(十六进制) | 你应该怎么理解 |
|---|---|---|---|
:method: GET |
2 |
0x82 |
最高位说明"这是索引表示",后面的位给出索引 2 |
:scheme: https |
7 |
0x87 |
同理,索引 7 对应 :scheme: https |
:path: / |
4 |
0x84 |
索引 4 对应 :path: / |
"索引"不是一个抽象词,它在编码里就是具体的位模式:前缀位先告诉你这是什么表示法,后面的位再给出索引或长度。
下面这张图把"字段 -> 索引 -> 字节 -> 解码"的过程画了出来:
第二步:动态表
静态表只能覆盖"大家都很常见"的字段。像 cookie: sid=abc123; theme=dark 这种更偏当前会话的内容,静态表事先不可能知道。
于是 HPACK 还准备了动态表。第一次出现时,它会把字段作为字面量发出去;如果这个字段后面大概率还会再出现,就顺手把它记进动态表。下次再遇到同样字段,就可以直接引用新索引。
第三步:不是所有字段都值得进表
HPACK 不是"见到什么都塞进动态表"。更像一个会算账的压缩员:
- 重复概率高的,记下来。
- 偶发的,临时发送,不一定入表。
- 敏感的,尽量不要走容易复用的路径。
第四步:Huffman 编码
就算某个字段不能直接用索引表示,HPACK 仍然可以继续把要发送的字符串做 Huffman 编码,让它更短。
把这四步合在一起,HPACK 的思路其实很朴素:
能编号的就编号,值得记住的就记进表,实在要原样发的字符串再继续压短。
讲到这里,HTTP/2 的核心就差不多完整了:
- 它把请求拆成流和帧。
- 它让这些帧可以在一条连接里交错发送。
- 它还顺手把重复头字段压短了。
讲到这里,HTTP/2 的阶段性成果可以压成一句:
到了
HTTP/2,浏览器终于不必主要依赖"多开 TCP 连接"来获得并发,单连接复用第一次真正变得划算。
但是,HTTP/2 为什么还是会卡
这里先抓一句最关键的:HTTP/2 已经把应用层的并发做出来了,但底层还是 TCP,而 TCP 仍然要求"前面的字节没补齐,后面的字节不能先交付"。
学到这里,很多人会产生一个很自然的误解:既然都已经多路复用了,是不是以后所有请求就互不影响了?
不是。
因为 HTTP/2 的多路复用发生在应用层 ,而承载这些帧的底层,仍然是一条 TCP 连接。
TCP 的核心语义,不是"哪个流先准备好就先交给上层",而是:
- 它要保证可靠交付。
- 它要保证有序交付。
- 前面缺一段,后面即使到了,也不能随便越过去。
这就会带来一个很反直觉的结果:**应用层明明已经拆成多个流了,到了传输层仍然可能因为同一个丢包点一起等待。**这很像你在传送带上取行李,明明后面的箱子已经到了,可只要前面那个关键箱子还没到位,后面的箱子也不能先放行。
下面这个图,把这件事画得很清楚:
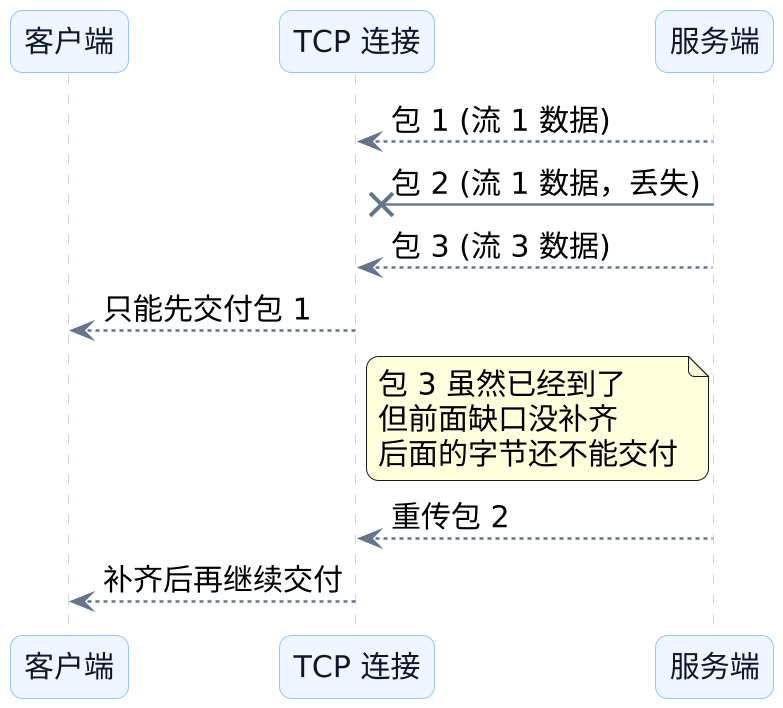
HTTP/2 卡住的根源,不是它不会拆流,而是 TCP 仍然把这些流当成同一条有序字节流来交付。
这样一来,问题就很清楚了:
HTTP/1.1的主要问题,是应用层并发不行。HTTP/2已经把应用层并发做出来了。- 现在剩下的主要矛盾,已经来到传输层。
也就是说,继续只在应用层补补丁,已经不够了。
第三代:HTTP/3 为什么不继续修 HTTP/2,而是直接换成 QUIC
从这里往下看,HTTP/3 不是把 HTTP/2 再补一补,而是干脆把"货物到底怎么运"这套底层规则换掉了。
当问题已经卡到 TCP 这一层时,HTTP/3 做了一个非常关键的决定:
HTTP/3最关键的决定,不是继续在 TCP 上补一个增强版,而是 直接把底层承载换成了QUIC。
第一次听到这里,很多人都会立刻问三件事:
QUIC跑在UDP上,那是不是不可靠?- 如果还要可靠,为什么不继续增强 TCP?
HTTP/3到底比HTTP/2真正多解决了什么?
这三个问题,正好可以顺着往下拆。
QUIC 跑在 UDP 上,为什么还能可靠
最容易让人误会的,其实是这一点。UDP 本身确实不保证可靠、有序、去重,但这不等于 QUIC 不可靠。更贴切的说法是:
UDP只负责"尽力送达",QUIC自己把编号、确认、重传、重组、拥塞控制这整套可靠机制补了回来。
如果想知道它到底怎么补,可以先看四步:
- 每个
QUIC数据包都有packet number。 - 接收方通过
ACK告诉发送方"哪些收到了,哪些没收到"。 - 发送方发现丢包后,不是死守旧包号,而是把缺的内容重新装进新的包号再发。
- 真正可靠的,不是某个旧包对象,而是流里的字节范围,也就是
offset。
你可以把这件事想成快递系统:UDP 更像"快递车只负责把包尽量送到",至于每个包有没有编号、丢了以后怎么补发、收件人怎么确认是不是少了一件、最后怎么按订单重新拼齐,都是 QUIC 自己在做。
下面这张图,把"丢包 -> ACK 缺口 -> 新包号重传 -> 按流偏移重组"连起来画了一遍:
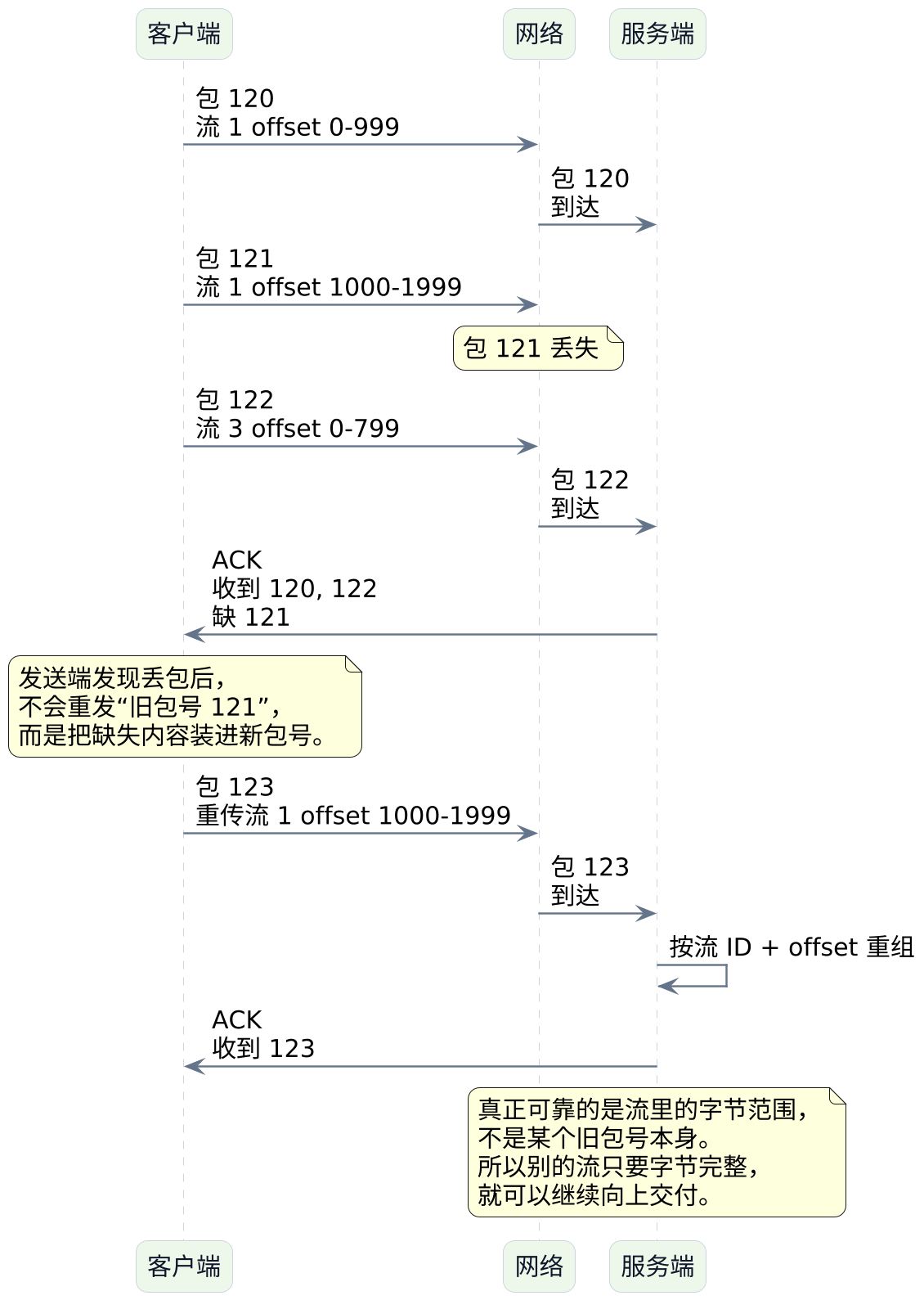
把这件事再收一下,可以落成一句话:
QUIC不是"不要可靠",而是"不再把所有可靠传输都写成一条大字节流"。
HTTP/3 真正多解决了什么
现在再回头看另一个关键问题,就容易多了。HTTP/3 真正想要的,不只是"建连更快一点",而是独立流。也就是:某个流丢一个包,主要影响这个流自己的重组,而不是把同一连接里的别的流也一起拖住。你可以把它理解成原来很多请求共用一条大传送带,现在更像每个窗口各自有自己的小传送带,一个窗口卡住了,不至于全大厅一起停摆。
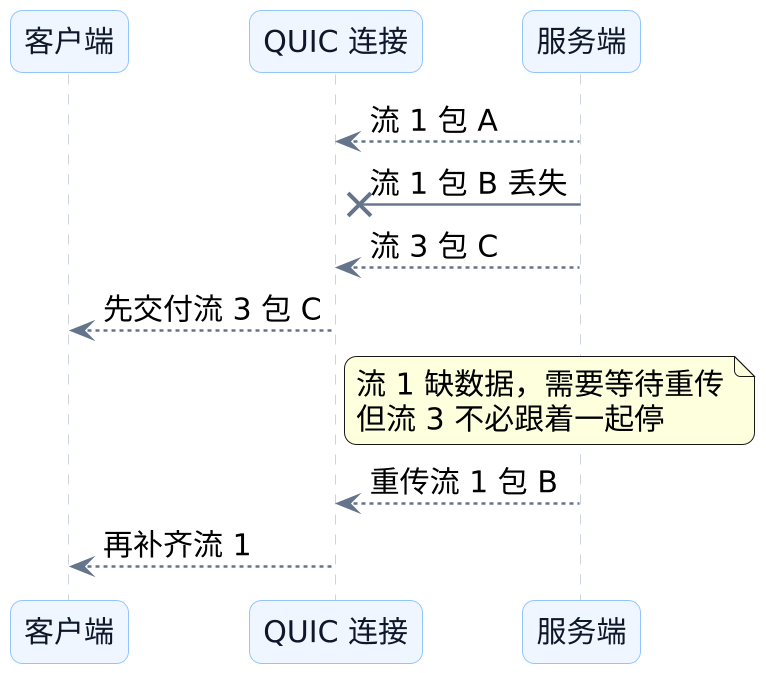
HTTP/3 不只是"再快一点",而是把 HTTP/2 没法越过去的那层阻塞边界重新划开了。
为什么不继续增强 TCP
这个问题的本质是:既然 TCP 也能做可靠传输,为什么不在 TCP 上继续补?
因为到这一步,问题已经不是"能不能补功能",而是"还能不能优雅地改模型"。
TCP 背后有很重的历史兼容包袱:
- 内核实现已经非常成熟,也很难大改。
- 各种中间设备、代理、网络路径里,都默认它是那一套语义。
- 它天生就是"一条有序字节流"的模型。
而 HTTP/3 想要的,是一套更适合独立流 的承载方式。QUIC 走 UDP,本质上是为了在用户态重新拿回传输层的演进速度和设计空间。
HTTP/3 的建连到底改了什么
HTTP/3 的建连,也可以这样理解:它更紧,不是因为它不做确认了,而是把原来分散在多层里的动作更早地压到了一起。
除了独立流,HTTP/3 另一个常被提起的好处是:建连更紧了。
先看总对照图:
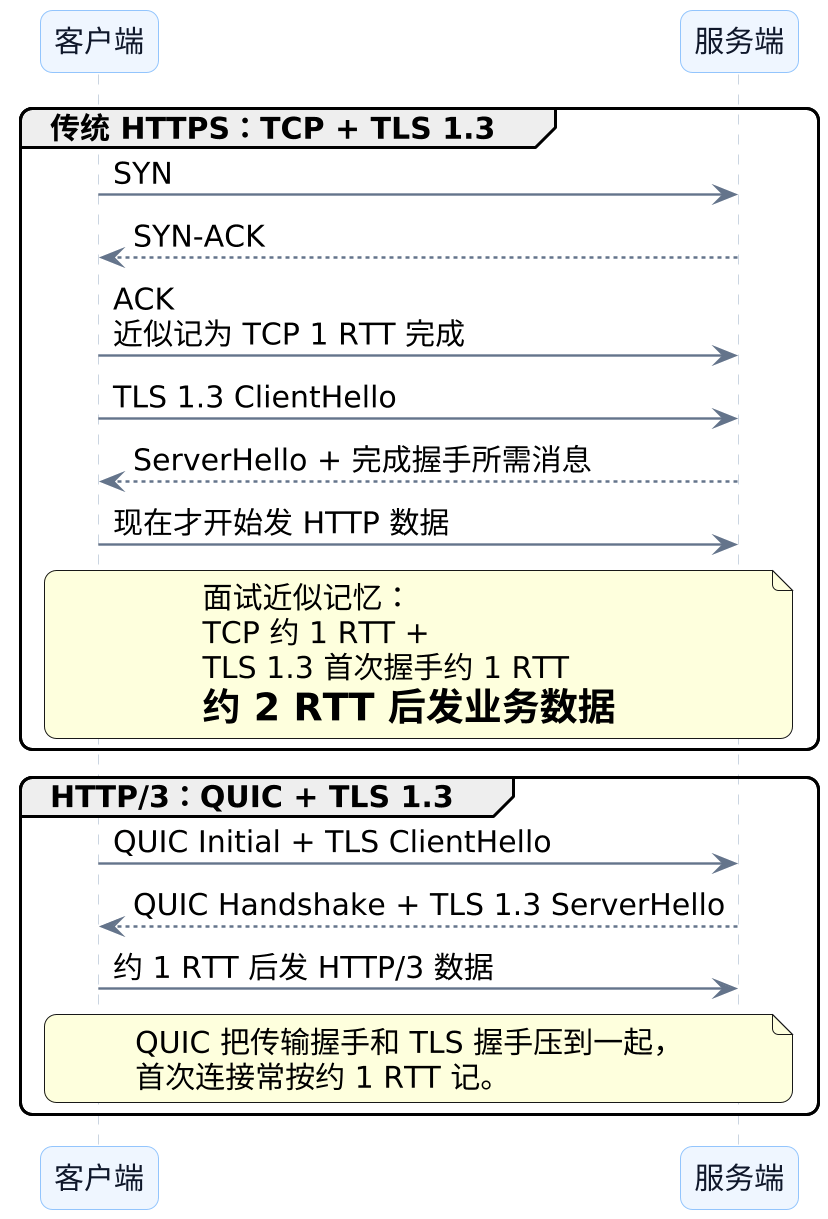
先把一个最容易混的边界放稳:
HTTP/1.1和HTTP/2在常见HTTPS场景下,底层一般都是TCP + TLS。HTTP/3则是QUIC + TLS 1.3一起推进。- 所以
HTTP/1.1和HTTP/2的主要差别,更多发生在握手之后;而HTTP/3连握手阶段的组织方式都一起改了。
HTTP/1.1和HTTP/2的主要差异发生在握手之后;HTTP/3连"连接怎么建立"这件事本身也一起重写了。
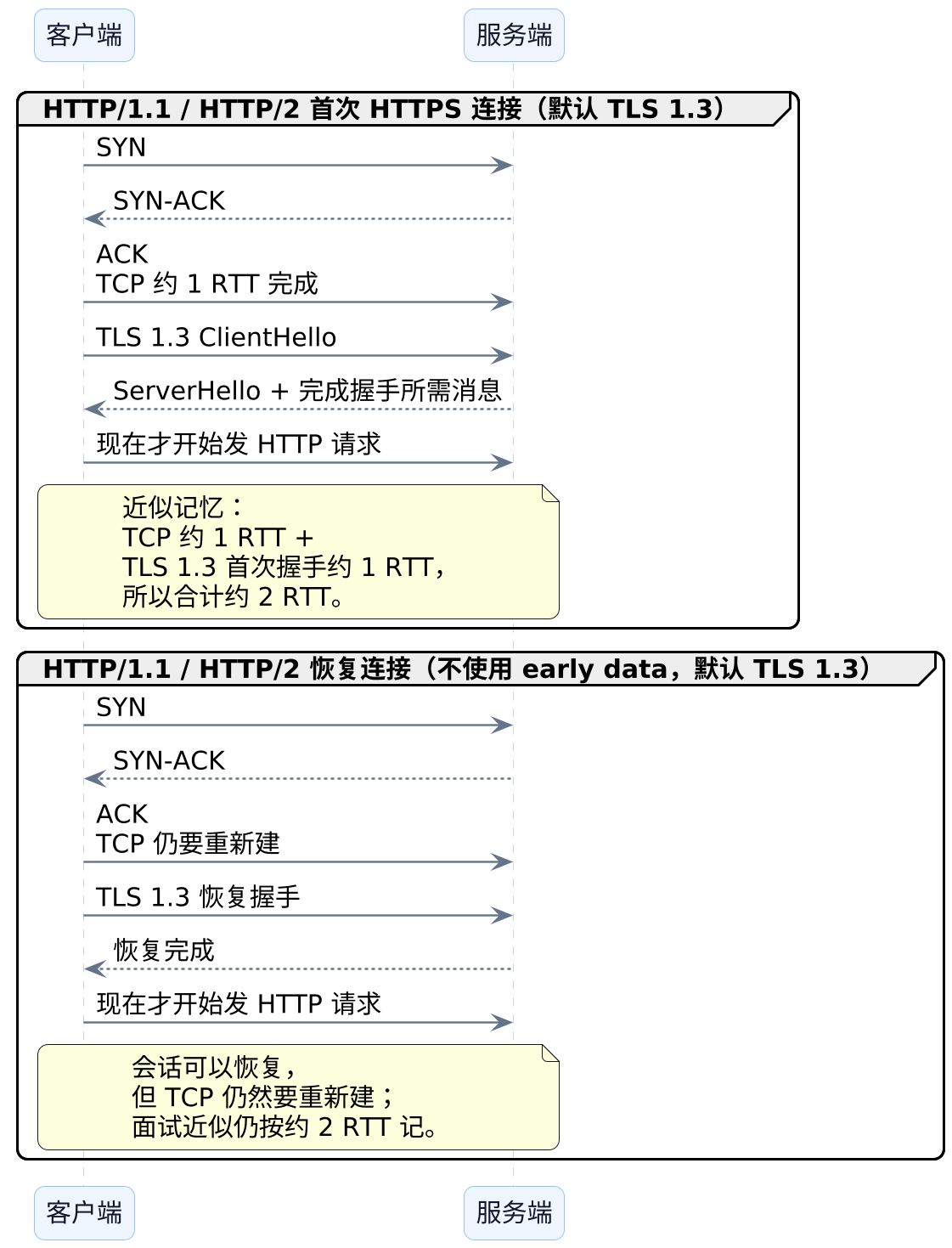
为什么有人说 TCP 是 1 RTT,有人又说是 1.5 RTT
这是一个特别容易吵起来的问题,但其实只是统计口径不同。
这里先固定两个口径:
- 客户端可发:客户端什么时候已经拿到对端回应,可以继续把业务数据发出去。
- 服务端收到:服务端什么时候真正收到客户端发出的首个业务请求。
这两个口径通常差了半个 RTT。所以:
- 纯
TCP首连,常说1 RTT,说的是"客户端可发"。 - 如果问"服务端什么时候收到客户端第一个请求",那通常是约
1.5 RTT。
同理,在默认 TLS 1.3 的常见近似口径下:
| 链路 | 客户端可发 | 服务端收到首个业务请求 |
|---|---|---|
纯 TCP 首连 |
约 1 RTT |
约 1.5 RTT |
TCP + TLS 1.3 首连 |
约 2 RTT |
约 2.5 RTT |
HTTP/3 首连 |
约 1 RTT |
约 1.5 RTT |
这件事换成更紧的一句话,就是:
"
TCP三次握手"说的是报文阶段;"约1 RTT"说的是客户端拿到回应后已经可以继续发数据的性能口径。
下面这张图把 HTTP/1.1 / HTTP/2 在 TCP + TLS 下的首次连接和恢复连接放在一起:
0-RTT 到底是什么,它又不是怎么回事
0-RTT 更像这样:它只属于"老访客再次回来",不属于"第一次见面";它也不是免检通行,而是拿着上次留下的回访凭条,边核验边先办一部分事。
很多人第一次听到 0-RTT,会下意识理解成"完全不用握手了"。这不对。
0-RTT 只属于恢复连接,不属于首次连接。它的意思也不是"跳过握手",而是:
- 上一次连接成功结束后,服务端给客户端留下一份恢复材料,可以理解成恢复票据。
- 客户端下次再连同一个服务端时,带着这份材料回来。
- 于是客户端可以在握手还没完全走完时,就先把一部分 early data 发出去。
所以它真正解决的是:让请求更早开始被处理。
0-RTT的本质不是"跳过握手",而是利用上一次连接留下的恢复材料,把一部分应用数据前移到握手阶段里发送。
如果把"没有 0-RTT"和"有 0-RTT"并排看,差异会更清楚:

还可以继续细一点,看 Initial、Handshake、0-RTT keys、1-RTT keys 这些阶段分别什么时候出现:
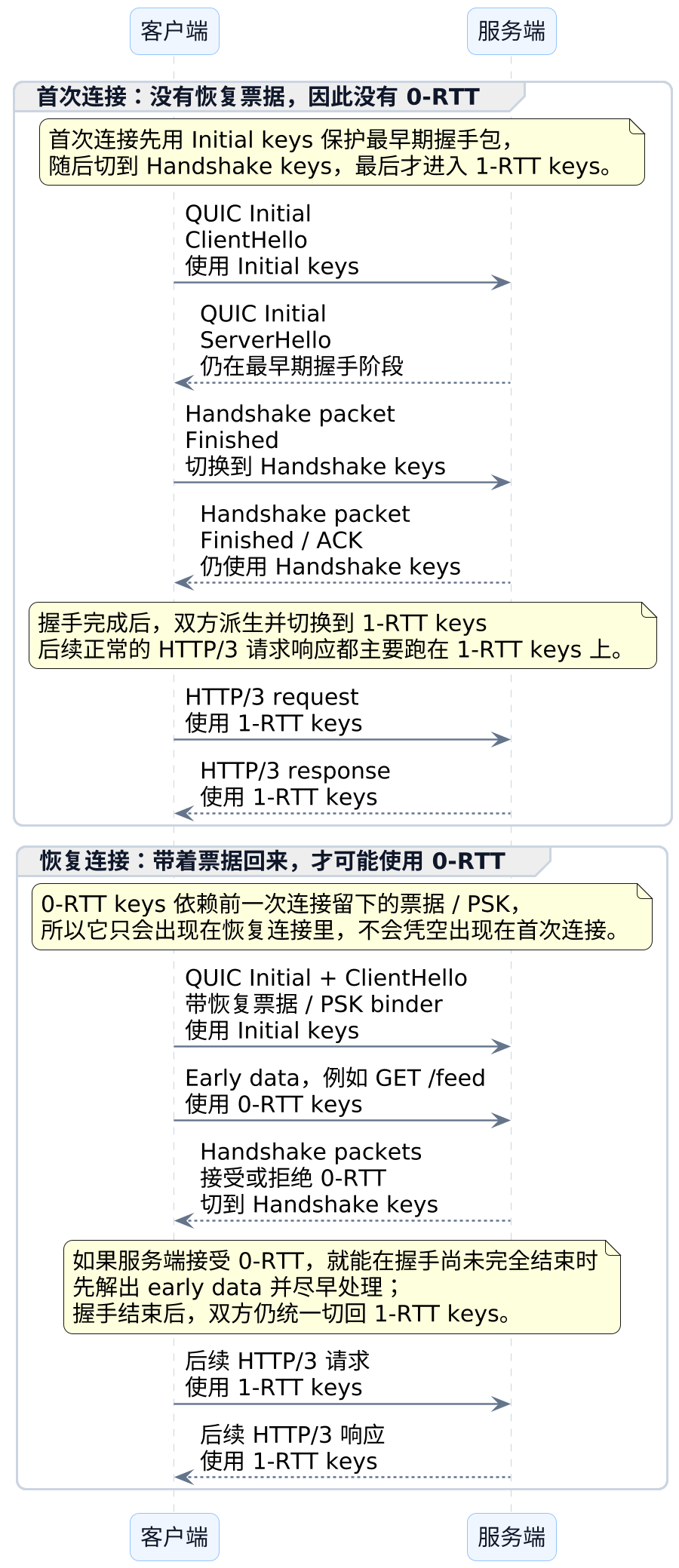
把这几类包并排放在一起看,会清楚很多:
| 包类型 | 什么时候会出现 | 典型能装什么 | 最该记住的一句话 |
|---|---|---|---|
Initial |
首次连接刚开始 | 最早期握手内容 | 它负责把连接和握手真正启动起来 |
Handshake |
握手推进阶段 | 继续完成握手所需内容 | 它负责把连接推进到稳定通信前夜 |
0-RTT |
只在恢复连接里可能出现 | early data,例如幂等读请求 | 它不属于首次连接,也不等于跳过握手 |
1-RTT |
稳定期 | 正常 HTTP/3 业务流量 |
平时真正稳定跑业务,主要靠它 |
把上面这张图和这张表合起来看,结论其实很简单:
首次连接走
Initial -> Handshake -> 1-RTT;只有恢复连接带着票据回来时,才可能额外出现0-RTT。
QPACK 为什么也得跟着变
这件事说白了就是:HTTP/3 想让每条流尽量各走各的路,所以连头部压缩都不能再轻易把"大家一起等"这种旧毛病带回来。
讲到这里,很多人会觉得:底层都换成 QUIC 了,头部压缩不就是把 HPACK 原样搬过来吗?
也不行。
因为 HTTP/3 想保住的是独立流。如果头部压缩本身又制造出跨流等待,那就等于把刚刚拆掉的堵点偷偷搬回来了。
所以 HTTP/3 用的是 QPACK。真正要紧的,是先抓住它和 HPACK 的核心差别:
| 项目 | HPACK |
QPACK |
|---|---|---|
| 所在协议 | HTTP/2 |
HTTP/3 |
| 更适合什么模型 | 一条 TCP 字节流上的压缩状态 | 尽量避免把跨流等待重新带回来 |
| 设计目标 | 压缩重复头字段 | 压缩重复头字段,同时尽量保住独立流 |
HTTP/3不是只把底层传输换掉就结束了,它连头部压缩机制也要重新检查,避免旧时代的阻塞假设被偷偷带回来。
讲到这里,把三代协议各自解决的问题再压一次
写到这里,这条演进线已经很清楚了:三代 HTTP 不是一起在解决同一个问题,而是一代解决完上一代最痛的点,再把新的瓶颈暴露出来。
把主线再收一遍,可以归成三句:
HTTP/1.1:少建连接。HTTP/2:单连接里多并发。HTTP/3:并发之后别再因为一个丢包把所有流一起拖住。
如果想稍微完整一点,可以看这张表:
| 版本 | 它主要解决什么 | 它靠什么解决 | 它还没解决什么 |
|---|---|---|---|
HTTP/1.1 |
别每个请求都重新建连接 | 长连接、多连接折中 | 单连接里高并发依然弱 |
HTTP/2 |
一条连接里怎么真正承载很多请求 | 流、帧、多路复用、HPACK |
底层还是 TCP,仍有传输层队头阻塞 |
HTTP/3 |
同一连接里的不同请求不该因一个丢包一起卡住 | QUIC 独立流、更紧的握手、QPACK |
部署和观测成本更高,不是所有场景都稳赚 |
为什么到了今天,三代 HTTP 还在长期共存
放到真实世界里看,协议世界不是"新的来了,旧的马上死",而是"谁在自己的场景里更划算,谁就继续活着"。
很多初学者看到这里,会自然产生另一个问题:既然 HTTP/3 看起来更先进,前两代是不是很快就没用了?
现实不是这样。
协议是否普及,从来不只看"理论上谁更强",还要看:
- 升级成本高不高
- 中间设备支不支持
- 链路是不是可控
- 这个场景到底值不值得为更复杂的协议买单
所以这三代协议更像是在围绕不同瓶颈长期共存:
| 协议 | 底层传输 | 最大优点 | 典型代价 | 常见场景 |
|---|---|---|---|---|
HTTP/1.1 |
TCP | 简单、成熟、兼容性最好 | 并发能力弱 | 大量传统系统、简单接口、回源链路 |
HTTP/2 |
TCP | 单连接多路复用,连接利用率高 | 仍受 TCP 队头阻塞影响 | 浏览器到站点、网关、很多内部服务 |
HTTP/3 |
QUIC |
丢包影响范围更小,切网和弱网体验更好 | UDP 部署、观测和调优更复杂 | 移动网络、弱网、对延迟更敏感的接入场景 |
最稳的理解方式不是"线性替代",而是:
三代
HTTP不是简单的一代淘汰一代,而是在不同场景里围绕不同瓶颈长期共存。
最后给一版面试速记总表
如果只是为了面试快速回忆,可以先背这张表:
| 版本 | 解决的核心问题 | 关键办法 | 仍然没解决什么 | 最适合怎么一句话概括 |
|---|---|---|---|---|
HTTP/1.1 |
减少每次请求都重建连接的开销 | 长连接、管线化尝试、多连接折中 | 单连接里并发能力弱,实践中常靠多 TCP 连接硬撑 | "HTTP/1.1 解决了反复建连,但没优雅解决同一连接里的高并发。" |
HTTP/2 |
让一条连接真正承载多个请求 | 二进制分帧、流、多路复用、HPACK |
底层还是 TCP,仍有传输层队头阻塞 | "HTTP/2 解决了应用层并发,但没摆脱 TCP 的字节流阻塞。" |
HTTP/3 |
把跨流等待问题继续往下拆 | 基于 QUIC 的独立流、更紧的握手、QPACK |
部署和观测成本更高,不是所有场景都稳赚 | "HTTP/3 不是小修小补,而是把承载层从 TCP 换成了 QUIC。" |
如果面试官继续追问"到底改了哪一层",可以再背第二张:
| 版本 | 主要改动层次 | 你最该提的关键词 | 最容易被问到的追问 |
|---|---|---|---|
HTTP/1.1 |
应用层连接复用策略 | 长连接、多连接、串行等待 | "为什么浏览器后来还是会并发开很多 TCP 连接?" |
HTTP/2 |
应用层消息组织方式 | 消息、流、帧、多路复用、HPACK |
"既然都多路复用了,为什么还会卡?" |
HTTP/3 |
传输层承载模型 | QUIC、独立流、0-RTT、连接迁移、QPACK |
"为什么不继续增强 TCP,而要换成 QUIC?" |
再给 10 张高频面试卡片
下面这组更适合拿来做背诵卡片。每一题先给一个最短答案,再顺手补一句展开。
卡片 1:HTTP/1.1 已经有长连接了,为什么还不够
- 短答:长连接只是减少反复建连,不等于同一条连接里已经能高效并发很多请求。
- 补一句:资源一多,单连接里仍然容易串行等待,所以浏览器后来常靠多 TCP 连接折中。
卡片 2:浏览器为什么会为同一站点开多条 TCP 连接
- 短答:因为
HTTP/1.1单连接并发能力弱,多开几条连接能换取更高吞吐。 - 补一句:但代价是更多握手、更多慢启动、更多拥塞控制状态,以及连接间带宽竞争。
卡片 3:HTTP/2 最核心的升级是什么
- 短答:把完整消息拆成了可编号、可交错发送的帧。
- 补一句:只有先把消息拆成更小的帧,才能稳定做流和多路复用。
卡片 4:为什么 HTTP/2 的多路复用必须建立在"流"和"帧"之上
- 短答:因为真正被调度和交错发送的是帧,流负责把这些帧重新归回各自请求。
- 补一句:消息是完整业务动作,流是逻辑车道,帧才是在线路上一块块发出去的单元。
卡片 5:一个 HTTP/2 请求是不是只能拆成 HEADERS + DATA 两块
- 短答:不是,可以拆成很多块。
- 补一句:头字段块可以跨
HEADERS + CONTINUATION + ...,消息体可以跨多个DATA。
卡片 6:HPACK 是什么
- 短答:
HPACK是HTTP/2的头字段压缩机制,不是压整个请求体。 - 补一句:它靠静态表、动态表、字面量表示和 Huffman 编码,减少重复头字段的浪费。
卡片 7:HTTP/2 都多路复用了,为什么还会卡
- 短答:因为底层还是 TCP。
- 补一句:
HTTP/2在应用层拆成了不同流,但 TCP 仍按有序字节流交付,只要前面缺一段,后面到的字节也不能先交给上层。
卡片 8:HTTP/3 为什么不继续增强 TCP,而要换成 QUIC
- 短答:因为
HTTP/2剩下的主要问题已经卡在传输层,继续只改应用层不够了。 - 补一句:
QUIC用独立流重写了承载模型,目的就是把"一个流丢包拖住所有流"的影响范围缩小。
卡片 9:HTTP/3 的核心收益是什么
- 短答:独立流、更紧的建连、更好的弱网和切网体验。
- 补一句:某个流丢包时主要影响这个流自己,再加上
QUIC + TLS把握手压得更紧,所以真实体验常比HTTP/2 over TCP更稳。
卡片 10:0-RTT 是什么
- 短答:
0-RTT只属于恢复连接,它让客户端可以更早发送 early data。 - 补一句:它不是跳过握手,也不适合有副作用的写请求,因为存在重放风险。
最后再压成一版 30 秒背诵稿:
HTTP/1.1解决的是少建连接,但并发还是弱。HTTP/2解决的是单连接多并发,但还会被 TCP 队头阻塞拖住。HTTP/3解决的是跨流一起等待,把承载层换成了有独立流的QUIC。
参考资料
RFC 9112: HTTP/1.1RFC 9113: HTTP/2RFC 9114: HTTP/3RFC 9000: QUIC: A UDP-Based Multiplexed and Secure TransportRFC 9001: Using TLS to Secure QUICRFC 9002: QUIC Loss Detection and Congestion ControlRFC 9204: QPACK: Field Compression for HTTP/3- MDN,
An overview of HTTP