- 从零构建 ReAct Agent
代理的一个主要组成部分是系统提示词,一般是通过 'role' : 'system' 来设定,比如:
python
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "你是一位专业的人工智能领域的教授,具备50年的教学经验"},
{"role": "user", "content": "请你详细的介绍一下:什么是人工智能?"},
]
)
print(response.choices[0].message.content)在这个示例中,`system`角色被设置为"你是一位专业的人工智能领域的教授,具备50年的教学经验"。这一设定使得大模型能够从一个人工智能教授的角度出发,详尽介绍人工智能的定义、分类、应用、挑战和未来展望。这种详细的介绍反映了教授丰富的知识和对领域的深刻理解。
我们再来测试不同的身份设定,会得到怎样不同的回答,代码如下所示:
python
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "你是一位杂技演员,完全不知道人工智能是什么。"},
{"role": "user", "content": "请你详细的介绍一下:什么是人工智能?"},
]
)
print(response.choices[0].message.content)
###输出
###抱歉,我对人工智能并不了解。我的工作主要是进行杂技表演,比如平衡、翻滚、跳跃等。如果你对杂技有什么问题或者想了解我的表演,请随时问我!在这个示例中,`system`角色被设定为"你是一位杂技演员,完全不知道人工智能是什么"。这一设定导致生成的回答中大模型以一个对人工智能一无所知的杂技演员的身份来回答,结果是它无法提供关于人工智能的任何信息,而是转而提到自己的专业领域,即杂技表演。
通过这两个示例可以看出,`system`角色设定对大模型的回答有决定性影响。这一机制允许我们开发者或使用者通过改变角色设定来控制大模型的知识范围和行为,使大模型能够适应不同的对话场景和用户需求。这种方法在代理工程中是非常有用的,特别是在需要代理以不同身份进行交互的情况下,可以有效地模拟多种人物角色的行为和专业知识。这种系统提示会直接引导代理推理问题并酌情选择有助于解决问题的外部工具。 那么,我们就应该在系统提示词中,去定义如下所示的完整 AI Agent 自主推理的核心流程:
基于上述流程,要通过代码实现`ReAct Agent`,能够非常明确需要做的三项工作是:
-
精心设计代理的完整提示词,并在大模型的`system`角色设置中进行设定,以确保代理的行为和知识与其角色一致。
-
实时将用户的问题作为变量输入,填充到系统提示(System Prompt)中,确保代理能够根据当前的用户需求生成响应。
-
构建并整合所需的工具,使`ReAct Agent`能够完成预定任务,这些工具也应作为变量被嵌入到系统提示中,以便在运行时调用。
接下来,我们就来实现一个基础但功能完整的`ReAct Agent`流程。这个AI代理的设计需求是能够实时搜索网络上的信息,并在需要进行数学计算时,调用计算工具。具体使用的工具包括:
-
Serper API:利用这个API,代理可以根据给定的关键词执行实时Google搜索,并返回搜索结果中的第一个条目。
-
calculate:这个功能通过使用Python的`eval()`函数来解析并计算数学表达式,从而得到数值和互动性。
Step 1. 设计完整的代理工程提示
正如我们上面介绍的 `ReAct`原理,其本质是采用了`思想-行动-观察`的循环过程来逐步实现复杂任务,那么其系统提示(System Prompt)就可以设计如下:
python
system_prompt = """
You run in a loop of Thought, Action, Observation, Answer.
At the end of the loop you output an Answer
Use Thought to describe your thoughts about the question you have been asked.
Use Action to run one of the actions available to you.
Observation will be the result of running those actions.
Answer will be the result of analysing the Observation
Your available actions are:
calculate:
e.g. calculate: 4 * 7 / 3
Runs a calculation and returns the number - uses Python so be sure to use floating point syntax if necessary
fetch_real_time_info:
e.g. fetch_real_time_info: Django
Returns a real info from searching SerperAPI
Always look things up on fetch_real_time_info if you have the opportunity to do so.
Example session:
Question: What is the capital of China?
Thought: I should look up on SerperAPI
Action: fetch_real_time_info: What is the capital of China?
PAUSE
You will be called again with this:
Observation: China is a country. The capital is Beijing.
Thought: I think I have found the answer
Action: Beijing.
You should then call the appropriate action and determine the answer from the result
You then output:
Answer: The capital of China is Beijing
Example session
Question: What is the mass of Earth times 2?
Thought: I need to find the mass of Earth on fetch_real_time_info
Action: fetch_real_time_info : mass of earth
PAUSE
You will be called again with this:
Observation: mass of earth is 1,1944×10e25
Thought: I need to multiply this by 2
Action: calculate: 5.972e24 * 2
PAUSE
You will be called again with this:
Observation: 1,1944×10e25
If you have the answer, output it as the Answer.
Answer: The mass of Earth times 2 is 1,1944×10e25.
Now it's your turn:
""".strip()提示词的第一部分告诉大模型如何通过我们之前看到的流程的标记部分循环处理问题,第二部分描述计算和搜索维基百科的工具操作,最后是一个示例的会话。整体结构非常清晰。
Step 2. 定义工具
定义工具我们仅需要确定工具的函数的入参及返回的结果即可。对于如上我们设计的场景,一共需要两个工具,其一是用来根据关键词检索`Serper API`,返回详细的检索信息。其二是一个计算函数,接收的入参是需要执行计算操作的数值,返回最终的计算结果。代码如下所示:
python
# ! pip install requests
import requests
import json
def fetch_real_time_info(query):
# API参数
params = {
'api_key': '0f31d8c5561bdaa4c71ad7c86f6e63a4a26cead9', # 使用您自己的API密钥
'q': query, # 查询参数,表示要搜索的问题。
'num': 1 # 返回结果的数量设为1,API将返回一个相关的搜索结果。
}
# 发起GET请求到Serper API
api_result = requests.get('https://google.serper.dev/search', params)
# 解析返回的JSON数据
search_data = api_result.json()
# 提取并返回查询到的信息
if search_data["organic"]:
return search_data["organic"][0]["snippet"]
else:
return "没有找到相关结果。"测试代码如下:
python
# 使用示例
query = "世界上最长的河流是哪条河流?"
result = fetch_real_time_info(query)
print(result)
###输出
###1. 尼罗河(Nile). 6670km ; 2. 亚马逊河(Amazon). 6400km ; 3. 长江(Chang Jiang). 6397km ; 4. 密西西比河(Mississippi). 6020km.函数 `calculate` 接收一个字符串参数 operation,该字符串代表一个数学运算表达式,并使用 Python 的内置函数 eval 来执行这个表达式,然后返回运算的结果。函数的返回类型被指定为 float,意味着期望返回值为浮点数。
python
def calculate(operation: str) -> float:
return eval(operation)测试代码如下:
python
# 调用函数
result = calculate("100 / 5")
print(result) # 输出结果应该是 20.0最后,定义一个名为 `available_actions` 的字典,用来存储可用的函数引用,用来在后续的Agent 实际执行 Action 时可以根据需要调用对应的功能。
python
available_actions = {
"fetch_real_time_info": fetch_real_time_info,
"calculate": calculate,
}Step 3. 开发大模型交互接口
接下来,定义大模型交互逻辑接口。这里我们实现一个聊天机器人的 Python 类,将系统提示(system)与用户(user)或助手的提示(assistant)分开,并在实例化ChatBot时对其进行初始化。 核心逻辑为 `call`函数负责存储用户消息和聊天机器人的响应,调用`execute`来运行代理。完整代码如下所示:
python
import openai
import re
import httpx
from openai import OpenAI
class ChatBot:
def __init__(self, system=""):
self.system = system
self.messages = []
if self.system:
self.messages.append({"role": "system", "content": system})
def __call__(self, message):
self.messages.append({"role": "user", "content": message})
result = self.execute()
self.messages.append({"role": "assistant", "content": result})
return result
def execute(self):
client = OpenAI()
completion = client.chat.completions.create(model="gpt-4o", messages=self.messages)
return completion.choices[0].message.content如上所示,这段代码定义了一个`ChatBot`的类,用来创建和处理一个基于`OpenAI GPT-4`模型的聊天机器人。下面是每个部分的具体解释:
-
init 方法用来接收系统提示(System Prompt),并追加到全局的消息列表中。
-
call 方法是 `Python` 类的一个特殊方法, 当对一个类的实例像调用函数一样传递参数并执行时,实际上就是在调用这个类的 call 方法。其内部会 调用`execute` 方法。
-
execute 方法实际上就是与`OpenAI`的API进行交互,发送累积的消息历史(包括系统消息、用户消息和之前的回应)到OpenAI的聊天模型,返回最终的响应。
Step 4. 定义代理循环逻辑
在代理循环中,其内部逻辑如下图所示:
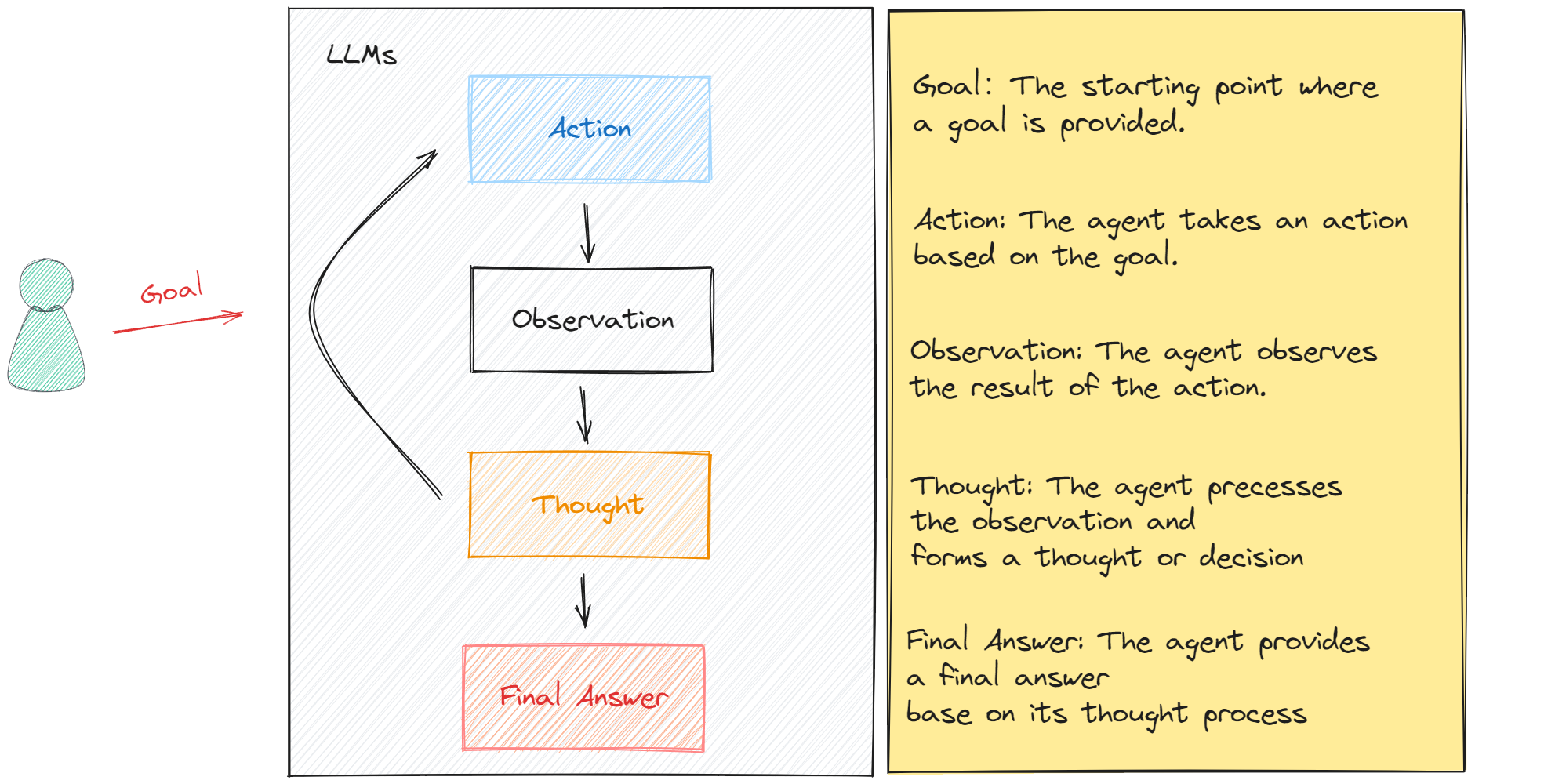
从`Thought` 到 `Action` , 最后到 `Observation` 状态,是一个循环的逻辑,而循环的次数,取决于大模型将用户的原始 `Goal` 分成了多少个子任务。 所有在这样的逻辑中,我们需要去处理的是:
-
判断大模型当前处于哪一个状态阶段
-
如果停留在 `Action` 阶段,需要像调用 Function Calling 的过程一样,先执行工具,再将工具的执行结果传递给`Obversation` 状态阶段。
首先需要明确,需要执行操作的过程是:大模型识别到用户的意图中需要调用工具,那么其停留的阶段一定是在 Action:xxxx : xxxx 阶段,其中第一个 xxx,就是调用的函数名称,第二个 xxxx,就是调用第一个 xxxx 函数时,需要传递的参数。这里就可以通过正则表达式来进行捕捉。如下所示:
python
# (\w+) 是一个捕获组,匹配一个或多个字母数字字符(包括下划线)。这部分用于捕获命令中指定的动作名称
# (.*) 是另一个捕获组,它匹配冒号之后的任意字符,直到字符串结束。这部分用于捕获命令的参数。
action_re = re.compile('^Action: (\w+): (.*)$')测试代码如下:
python
match = action_re.match("Action: fetch_real_time_info: mass of earth")
if match:
print(match.group(1)) # 'fetch_real_time_info'
print(match.group(2)) # 'mass of earth'由此,我们定义了如下的一个 `AgentExecutor`函数。该函数实现一个循环,检测状态并使用正则表达式提取当前停留的状态阶段。不断地迭代,直到没有更多的(或者我们已达到最大迭代次数)调用操作,再返回最终的响应。完整代码如下:
python
action_re = re.compile('^Action: (\w+): (.*)$')
def AgentExecutor(question, max_turns=5):
i = 0
bot = ChatBot(system_prompt)
# 通过 next_prompt 标识每一个子任务的阶段性输入
next_prompt = question
while i < max_turns:
i += 1
# 这里调用的就是 ChatBot 类的 __call__ 方法
result = bot(next_prompt)
print(f"result:{result}")
# 在这里通过正则判断是否到了需要调用函数的Action阶段
actions = [action_re.match(a) for a in result.split('\n') if action_re.match(a)]
if actions:
# 提取调用的工具名和工具所需的入参
action, action_input = actions[0].groups()
if action not in available_actions:
raise Exception("Unknown action: {}: {}".format(action, action_input))
print(f"running: {action} {action_input}")
observation = available_actions[action](action_input)
print(f"Observation: {observation}")
next_prompt = "Observation: {}".format(observation)
else:
return bot.messages运行 AI Agent 进行测试:
python
AgentExecutor("世界上最长的河流是什么?")
###输出
###result:Thought: 我需要查找一下世界上最长的河流信息。
Action: fetch_real_time_info: 世界上最长的河流
running: fetch_real_time_info 世界上最长的河流
Observation: 1. 尼罗河(Nile). 6670km ; 2. 亚马逊河(Amazon). 6400km ; 3. 长江(Chang Jiang). 6397km ; 4. 密西西比河(Mississippi). 6020km.
result:Answer: 世界上最长的河流是尼罗河,全长6670公里。
python
AgentExecutor("20 * 15 等于多少")
###输出
###result:Thought: 用户需要我计算 20 乘以 15 的结果。
Action: calculate: 20 * 15
running: calculate 20 * 15
Observation: 300
result:Answer: 20 乘以 15 等于 300。从上面我们实现的案例中,非常明显的发现,ReAct(推理和行动)框架通过将推理和行动整合到一个有凝聚力的操作范式中,能够实现动态和自适应问题解决,从而允许与用户和外部工具进行更复杂的交互。这种方法不仅增强了大模型处理复杂查询的能力,还提高了其在多步骤任务中的性能,使其适用于从自动化客户服务到复杂决策系统的广泛应用。
就目前的AI Agent 现状而言,流行的代理框架都有内置的 ReAct 代理,比如`Langchain`、`LlamaIndex`中的代理,或者 `CrewAI`这种新兴起的AI Agent开发框架,都是基于ReAct理念的一种变种。LangChain 的 ReAct 代理工程描述:
python
```json
Answer the following questions as best you can. You have access
to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}
There are three placeholders {tool}, {input}, and {agent_scratchpad} in this prompt. These will be replaced with the appropriate text before sending it to LLM.
```这个提示中有三个占位符 {tool}、{input} 和 {agent_scratchpad}。在发送给LLM之前,这些内容将被替换为适当的文本。
-
tools - 工具的描述
-
tool_names - 工具的名称
-
input - 大模型接收的原始问题(通常是来自用户的问题)
-
agent_scratchpad - 保存以前的想法/行动/行动输入/观察的历史记录
因此,基于 `ReAct` 的代理工程并非一成不变,其所调用的工具也不局限于单一类型。这种灵活性实际上为 `AI Agent` 执行人工智能代理任务开启了无限的可能性。
接下来,我们再次进入项目开发环节,这次我们用`ReAct Agent`框架实现《Ch.2 AI Agent应用类型及Function Calling开发实战》中智能客服应用案例。
4. 基于ReAct Agent 实现智能客服
在这个项目中,我们将使用PyCharm IDE 来进行项目开发,同时会集成 OpenAI GPT 模型和 Ollama 启动的本地开源模型以满足不同小伙伴的使用需求。但需要说明的是:AI Agent 的效果非常依赖于大模型的原生能力,所以如果使用小参数量的模型无法复现项目是正常现象。在开始之前,如果没有Python和大模型基础的小伙伴,可依次按照如下课程内容进行基础内容的补充:
该项目已在github开源,访问地址:https://github.com/fufankeji/ReAct_AI_Agent
大家需要通过`git` 下载项目完整代码,同时按照 `README.md` 说明配置并启动项目,下载命令:
python
```
git clone https://github.com/fufankeji/ReAct_AI_Agent.git
```