跟进了那么多高并发场景的压测项目,今天,我从简单的接口性能验证到复杂的分布式架构压测,Apache JMeter(简称JMeter)始终是我最依赖的工具。它不是一款"入门即弃"的轻量工具,而是能贯穿性能测试全流程、支撑架构级实战的"瑞士军刀"。今天,我将从入门到进阶,全面拆解JMeter,帮你真正吃透这款工具,从"会用"到"活用",解决实际工作中的各类性能难题。
一、引言:为什么选择 JMeter?
1.1 性能测试的重要性
在当下的互联网场景中,高并发早已成为常态------电商大促的峰值流量、短视频平台的瞬时访问、接口服务的高频调用,任何一个环节的性能瓶颈,都可能导致服务雪崩、用户流失,甚至造成直接的经济损失。而后端接口的稳定性,正是支撑业务正常运行的核心命脉,性能测试(Performance Testing)就是提前发现瓶颈、规避风险的关键手段,没有性能测试的系统,上线就如同"裸奔"。
1.2 JMeter 的核心优势
市面上性能测试工具不少(如LoadRunner、Gatling),但JMeter能成为行业主流,核心在于它的"全能性"与"易用性",尤其适合中小团队和复杂场景:
-
开源免费(Open-Source & Free):基于Apache开源协议,无需付费即可使用全部功能,摆脱商业工具的授权限制,降低团队测试成本。
-
多协议支持(Multi-Protocol Support):完美兼容HTTP/HTTPS、TCP、JDBC、FTP、WebSocket等主流协议,既能测试接口服务,也能测试数据库、消息队列等中间件,一站式覆盖各类测试场景。
-
强大的扩展性(Strong Extensibility):基于Java语言开发,支持自定义插件(Plugin)、脚本编写,可根据业务需求灵活扩展功能,适配个性化测试场景。
-
易用性强:图形化界面(GUI)直观易懂,上手成本低,同时支持命令行模式(CLI),可灵活适配自动化、分布式场景。
1.3 JMeter 适用场景
JMeter的应用场景覆盖性能测试全流程,并非只局限于"压测":
-
接口测试(Interface Testing):快速验证单个接口的功能正确性、响应耗时,替代Postman等工具完成批量接口测试。
-
压力测试(Stress Testing):模拟高并发场景,测试系统在极限压力下的表现,寻找系统最大承载能力。
-
稳定性测试(Stability Testing):长时间(如24小时)低并发运行,验证系统的稳定性,排查内存泄漏、连接池耗尽等隐性问题。
-
并发资源竞争测试(Concurrent Resource Competition Testing):模拟多用户同时操作同一资源(如并发下单、并发修改数据),验证系统的资源隔离、锁机制是否合理。
二、核心概念与环境搭建
2.1 JMeter 工作原理
JMeter的核心工作逻辑很简单:通过模拟多线程(Thread)并发发送请求(Request),模拟真实用户的操作行为,同时收集每个请求的响应数据(Response Data),最终通过内置的分析组件生成性能报告,直观呈现系统的响应时间、吞吐量等核心指标。本质上,它就是一个"多线程请求模拟器 + 数据收集分析工具"。
2.2 快速安装(Windows/Mac/Linux通用)
JMeter是纯Java应用,安装前必须先配置JDK环境,核心步骤如下:
-
JDK 环境配置(JMeter 是纯 Java 应用):
-
下载JDK(推荐1.8及以上版本,与JMeter版本兼容),安装后配置环境变量(JAVA_HOME、Path)。
-
验证:命令行输入
java -version,能正常显示JDK版本即配置成功。
-
-
JMeter 二进制包下载与解压:
- 访问Apache JMeter官网(jmeter.apache.org/),下载最新版二进制包... Distribution),无需安装,解压到任意目录即可。

- 访问Apache JMeter官网(jmeter.apache.org/),下载最新版二进制包... Distribution),无需安装,解压到任意目录即可。
-
JMeter 关键目录说明:
-
/bin 目录:存放启动脚本(jmeter.bat 用于Windows,jmeter.sh 用于Mac/Linux)、配置文件(jmeter.properties),是JMeter的核心启动目录。
-
/lib 目录:存放JMeter的核心依赖包、扩展插件(如数据库驱动、自定义插件),新增扩展时需将jar包放入该目录(部分插件需重启JMeter生效)。
-
2.3 GUI 界面初识
启动JMeter(双击/bin目录下的jmeter.bat/sh),默认进入图形化界面(GUI),核心区域分为3部分,新手需重点熟悉:
-
核心控制台(Main Console):包含启动、停止、清空结果等核心操作按钮,是脚本运行的控制中心。
-
日志窗口(Log Window):实时输出脚本运行日志,用于调试脚本、排查错误(如接口调用失败、参数错误等)。
-
组件树(Component Tree):左侧的树形结构,所有测试组件(线程组、取样器、断言等)都需在此添加和配置,是脚本编写的核心区域。
注意:GUI仅用于脚本编写、调试,正式压测严禁使用(后续会详细说明原因)。
默认界面是英文的,可以手动改成中文显示,但还是会有部分地方展示英文。 Options --> Choose Language --> Chinese 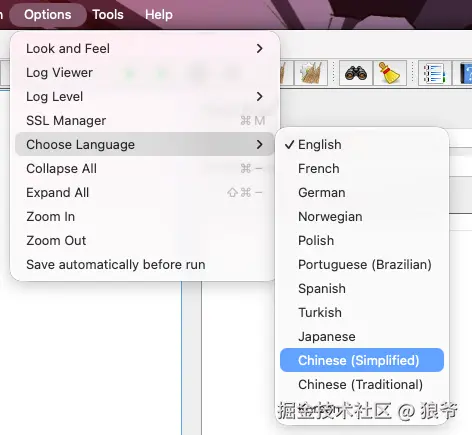
三、核心组件"五虎将" (详细拆解)
JMeter的核心能力,源于其强大的组件体系,其中线程组、取样器、配置元件、断言、监听器,被称为JMeter组件"五虎将"------掌握这5类组件,就能完成90%以上的性能测试场景。
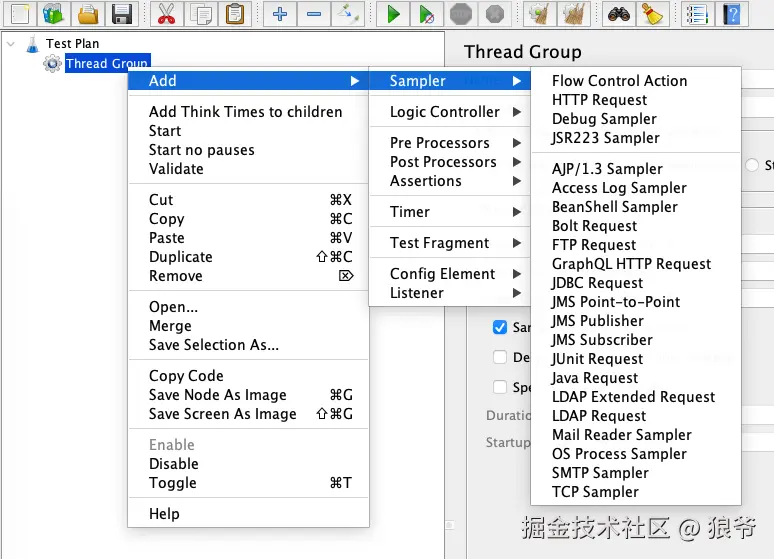
3.1 线程组 (Thread Group):并发的"发动机"
线程组是JMeter脚本的"根基",所有测试组件(取样器、断言等)都必须依赖线程组存在,它负责模拟并发用户,控制并发数量、启动节奏。核心配置项如下:
-
并发用户数(Number of Threads):模拟的虚拟用户(Virtual User)数量,即同时发送请求的线程数,是压测的核心参数(如1000线程=1000个并发用户)。
-
启动时间(Ramp-Up Period):所有线程从启动到全部启动完成的时间(单位:秒),用于模拟真实用户的"逐步涌入"场景,避免瞬间高并发导致系统雪崩。例如:1000线程,启动时间10秒,即每秒启动100个线程。
-
循环次数(Loop Count)与持续时间(Duration):
-
循环次数:每个线程执行请求的次数(默认1次),可设置为"无限循环",配合持续时间使用。
-
持续时间:脚本运行的总时间(单位:秒),设置后,线程会持续发送请求,直到达到指定时间,适合稳定性测试。
-
3.2 取样器 (Samplers):请求的"发送器"
取样器负责发送具体的请求(如HTTP请求、数据库请求),是与被测系统交互的核心组件,常用取样器如下:
3.2.1 HTTP 请求(HTTP Request):最常用的取样器
用于测试HTTP/HTTPS接口,核心配置项需与接口文档严格对应:
-
请求方法(Method):GET、POST、PUT、DELETE等,需与接口定义一致。
-
域名(Server Name or IP):被测接口的域名或IP地址(如www.example.com)。
-
路径(Path):接口的请求路径(如/api/login)。
-
参数(Parameters):GET请求的参数(键值对),POST请求的表单参数。
-
Body Data:POST请求的请求体(如JSON格式、XML格式),常用于RESTful API测试,需配合HTTP信息头管理器设置Content-Type(如application/json),确保请求格式正确。
3.2.2 其他常见取样器
-
JDBC Request(数据库测试):用于测试数据库性能(如查询、插入、更新操作),需先在/lib目录放入对应数据库的驱动jar包(如MySQL的mysql-connector-java.jar),配置数据库连接信息后,编写SQL语句即可执行。
-
TCP Sampler:用于测试TCP协议的服务(如自定义TCP接口、消息队列),配置服务器IP、端口、请求数据格式,即可发送TCP请求。
3.3 配置元件 (Config Elements):请求的"配置器"
配置元件用于配置取样器的请求参数、环境信息,作用于其所在的线程组(或子组件),常用配置元件如下:
-
HTTP 信息头管理器(HTTP Header Manager):配置HTTP请求的请求头(Header),如Content-Type、Token、Cookie等,是接口测试的必备组件------例如测试JSON格式接口时,需添加Content-Type: application/json,否则接口会返回格式错误。
-
HTTP Cookie 管理器(HTTP Cookie Manager):自动保存接口返回的Cookie信息,并在后续请求中自动携带,适用于需要登录态保持的场景(如登录后访问个人中心)。
-
CSV 数据文件设置(CSV Data Set Config):实现参数化测试,将测试数据(如多账号、多请求参数)存入CSV文件,通过该组件读取文件数据,循环代入请求中。最典型的场景是"多账号登录测试"------将多个账号密码存入CSV文件,每个线程读取一条数据,模拟多用户同时登录。
3.4 断言 (Assertions):结果的"校验器"
断言用于验证请求的响应结果是否符合预期,避免"请求发送成功,但响应数据错误"的情况,常用断言如下:
-
响应断言(Response Assertion):最常用的断言,可校验响应状态码(如200、404)、响应文本(如返回"success")、响应头,适用于简单接口的结果校验。
-
JSON 断言(JSON Assertion):针对RESTful API的高效校验,可直接定位JSON响应中的某个字段(如code、message),校验其值是否符合预期(如code=200),比响应断言更精准、高效。
提示:断言失败会被计入错误率(Error%),在聚合报告中可直观查看,是判断接口是否正常的核心依据之一。
3.5 监听器 (Listeners):结果的"分析器"
监听器用于收集请求的响应数据,生成测试报告,常用监听器如下,新手重点掌握2个即可:
-
察看结果树(View Results Tree):调试脚本的"神器",可实时查看每个请求的详细信息(请求参数、响应数据、响应时间),方便排查脚本错误(如参数错误、接口返回异常)。
-
聚合报告(Aggregate Report):性能测试的核心报告,包含吞吐量(TPS)、响应时间(99线、95线、50线)、错误率等核心指标,是分析系统性能的主要依据,其中各字段含义如下5:
-
Label:请求名称(取样器名称);
-
#Samples:请求总次数;
-
Average:平均响应时间;
-
90% Line/95% Line/99% Line:90%/95%/99%的请求响应时间(核心指标,反映大部分用户的体验);
-
Throughput:吞吐量(TPS),即每秒完成的请求数,是衡量系统并发能力的核心指标;
-
Error%:错误率,即失败请求数/总请求数。
-
四、进阶技巧:让脚本"聪明"起来
基础脚本只能完成简单的并发测试,而实际业务场景往往更复杂(如登录后需携带Token、根据响应结果动态执行请求),这就需要用到JMeter的进阶技巧,让脚本具备"动态决策"能力。
4.1 动态关联 (Post Processors):解决"依赖请求"问题
很多接口存在依赖关系(如登录接口返回Token,后续接口需携带该Token才能访问),动态关联就是从一个请求的响应中提取数据,传递给后续请求,常用组件如下:
-
JSON 提取器(JSON Extractor):最常用的提取器,适用于JSON格式的响应数据。例如:从登录接口的响应({"code":200,"data":{"token":"abc123"}})中提取Token,设置提取规则后,后续接口可通过${token}引用该值,实现登录态保持。
-
正则表达式提取器(Regular Expression Extractor):用于处理非结构化的响应数据(如HTML页面、普通文本),通过正则表达式匹配需要提取的内容。例如:从HTML页面中提取用户ID,适用于页面接口测试,使用时需注意正则表达式的匹配准确性,避免提取失败。
4.2 逻辑控制器 (Logic Controllers):控制请求的"执行逻辑"
逻辑控制器用于控制请求的执行顺序、条件,让脚本根据实际场景动态调整执行流程,常用控制器如下:
-
If 控制器(If Controller):根据指定条件,决定是否执行后续的请求。例如:只有上一个请求的响应码为200(登录成功),才执行访问个人中心的请求;若登录失败,则跳过。
-
ForEach 控制器(ForEach Controller):遍历列表数据,循环执行请求。例如:从接口响应中提取多个商品ID,通过ForEach控制器遍历每个商品ID,循环执行"查询商品详情"的请求。
4.3 脚本增强 (JSR223 & Groovy):处理复杂场景
当基础组件无法满足需求(如生成动态签名、处理复杂时间戳、加密请求参数)时,就需要用到JSR223组件,结合Groovy脚本增强脚本能力。除此之外,JMeter内置的函数生成器(Function Helper)也是提升脚本灵活性的重要工具,无需编写复杂脚本,即可快速生成动态数据,适配各类测试场景。
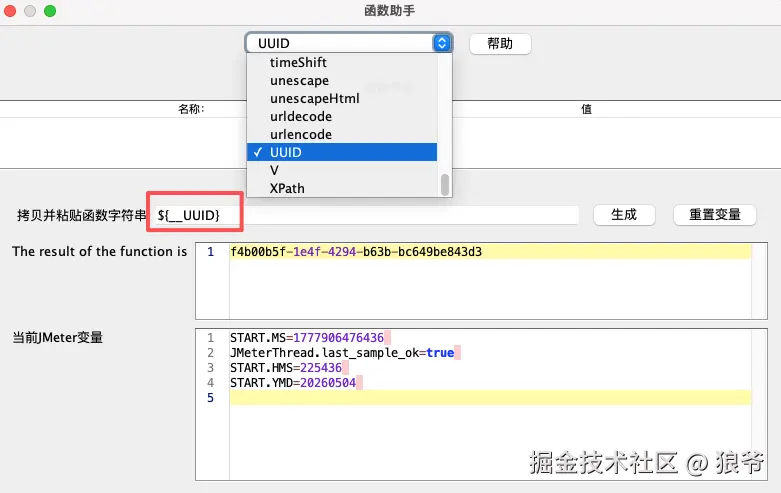
4.3.1 函数生成器(Function Helper)核心解析
函数生成器(Function Helper)是JMeter GUI模式下的内置工具,用于快速生成JMeter函数,实现动态参数生成、数据处理等功能,无需手动编写代码,上手简单,适合新手快速实现脚本动态化。其核心特性的是:基于JMeter内置函数库,可视化配置参数,生成可直接引用的函数表达式(格式为${__函数名(参数1,参数2,...)}),支持直接复制到脚本的参数、请求体中使用。
启动方式:JMeter顶部菜单栏 → Tools → Function Helper Dialog,打开后即可选择对应函数、配置参数,生成函数表达式。
4.3.2 常用函数分类及实战场景
JMeter内置函数多达数十种,结合官方文档及实战需求,重点掌握以下4类高频函数,可覆盖80%以上的动态参数场景:
-
- 字符串处理函数:核心用于字符串拼接、截取、替换,解决请求参数中动态拼接的需求。 __concat(参数1,参数2,...):字符串拼接,例如拼接时间戳和固定字符,生成唯一请求ID:{_concat(req,{__time(yyyyMMddHHmmss,)},)}
- __substring(字符串,起始索引,结束索引):截取字符串,例如从Token中截取指定片段,适配接口参数要求。
- 时间函数:生成动态时间戳、指定格式的时间,适配接口中时间参数的动态需求(如请求时间、过期时间)。 __time(格式,):生成指定格式的时间,默认格式为毫秒级时间戳,例如生成yyyyMMdd格式日期:${__time(yyyyMMdd,)}
__timeShift(格式,偏移量,时区,):生成指定偏移量的时间,例如生成1小时后的时间:${__timeShift(yyyyMMddHHmmss, +1h, UTC,)}
- 随机函数:生成随机数、随机字符串,用于参数化测试(如随机手机号、随机订单号),模拟真实用户的随机操作。 __Random(最小值,最大值,):生成指定范围的随机整数,例如生成1000-9999之间的随机验证码:${__Random(1000,9999,)}
__RandomString(长度,字符集,):生成指定长度、指定字符集的随机字符串,例如生成8位随机密码:${__RandomString(8,abcdef123456,)}
- 变量相关函数:用于获取、处理JMeter中的变量(如用户定义变量、提取器生成的变量),实现变量的二次处理。 __V(变量名):获取嵌套变量的值,例如提取的变量为token_1、token_2,可通过{_V(token{__Random(1,2,)})}随机获取其中一个Token。
__eval(表达式):执行表达式并返回结果,例如将字符串格式的变量转为数值:{__eval({num_str})}
4.3.3 函数生成器与Groovy脚本的区别与配合使用
很多新手会混淆函数生成器与Groovy脚本的使用场景,两者核心区别及配合方式如下:
-
函数生成器:无需编写代码,适合简单的动态参数生成(如随机数、时间戳、字符串拼接),操作简单、效率高,适合新手或简单场景。
-
Groovy脚本:需要编写简单代码,适合复杂的业务逻辑(如加密、签名生成、复杂数据处理),灵活性强,适合复杂场景。
-
配合使用:函数生成器可作为Groovy脚本的补充,例如在Groovy脚本中引用函数生成的随机数、时间戳,简化脚本编写,提升效率。
4.3.4 实战:用函数生成器快速实现动态请求参数
场景:接口请求需要携带"请求ID"(格式为:req_yyyyMMddHHmmss_随机数)和"请求时间"(当前时间yyyy-MM-dd HH:mm:ss),无需编写脚本,用函数生成器即可实现:
-
打开函数生成器,选择__concat函数,依次输入参数:req_、{__time(yyyyMMddHHmmss,) }、、{__Random(1000,9999,) },生成请求ID:{_concat(req,{__time(yyyyMMddHHmmss,)},,${__Random(1000,9999,)})}。
-
选择__time函数,设置格式为yyyy-MM-dd HH:mm:ss,生成请求时间:${__time(yyyy-MM-dd HH:mm:ss,)}
-
将生成的两个函数表达式,直接复制到HTTP请求的参数或Body Data中,即可实现动态参数生成,无需编写任何脚本。
4.3.5 为什么推荐 Groovy 而非 BeanShell?
JMeter支持多种脚本语言(BeanShell、Groovy、JavaScript等),其中Groovy是官方推荐的语言,核心优势的是:执行效率高(比BeanShell快10倍以上)、语法简洁、支持Java语法,且能直接调用JMeter的内置对象(如vars、log),适合高并发场景下的脚本增强。
4.3.6 实战场景:动态生成签名
很多接口为了安全,会要求请求参数携带签名(如MD5加密的签名),签名由时间戳、密钥、请求参数拼接后加密生成,此时可通过JSR223 PreProcessor(请求前执行脚本)实现:
-
在HTTP请求前添加JSR223 PreProcessor,选择语言为Groovy。
-
编写脚本:生成当前时间戳(System.currentTimeMillis()),拼接请求参数、密钥,通过MD5加密生成签名,将签名存入变量(vars.put("sign", sign))。
-
在HTTP请求的参数中,通过${sign}引用签名变量,即可实现动态签名。
当基础组件无法满足需求(如生成动态签名、处理复杂时间戳、加密请求参数)时,就需要用到JSR223组件,结合Groovy脚本增强脚本能力。
五、元件的执行顺序
在 JMeter 中,元件的执行顺序(Execution Order)并非按照它们在测试计划树中"从上到下"的简单排列,而是遵循一套严格的优先级逻辑。
理解这个顺序对于调试复杂的脚本(尤其是涉及变量提取和逻辑控制时)至关重要。
5.1. 核心执行顺序
对于每一个取样器(Sampler),JMeter 会按照以下顺序执行其作用域内的元件:
- 配置元件 (Configuration Elements):如 HTTP Cookie 管理器、CSV 数据文件设置。它们在测试开始或请求发送前执行,用于初始化环境。
- 前置处理器 (Pre-Processors):在请求发送之前对请求进行修改,例如对参数进行加密。
- 定时器 (Timers) :在请求发送前进行等待。注意: 定时器是在前置处理器之后、取样器之前执行。
- 取样器 (Sampler):发送实际的请求(如 HTTP Request)。
- 后置处理器 (Post-Processors):在请求发送后执行,通常用于提取响应数据(如 JSON 提取器)。
- 断言 (Assertions):对响应结果进行校验。
- 监听器 (Listeners):最后收集数据并展示结果(如查看结果树、聚合报告)。
5.2. 作用域 (Scoping) 的影响
除了上述的优先级,作用域决定了元件会对哪些取样器生效:
- 父子关系:如果一个定时器或断言是某个取样器的"子节点",它只对该取样器生效。
- 同级关系 :如果一个定时器是线程组下的顶级元件,它会应用到该线程组下所有的取样器。
- 全局元件:放在测试计划(Test Plan)最顶层的配置元件,会对所有线程组生效。
5.3. 关键细节与"坑点"
关于定时器 (Timers)
定时器是很多人容易误解的地方。JMeter 的逻辑是:在执行每一个取样器之前,都会先执行其作用域内的所有定时器。
- 如果你在两个 HTTP 请求中间放了一个固定定时器,这个等待时间会加在每一个请求之前,而不是仅仅在两个请求"之间"。
关于配置元件 (Config Elements)
配置元件在测试启动时就会被处理。这意味着你无法通过后置处理器提取的变量来动态改变某些配置元件(如 CSV Data Set Config 的文件名),因为 CSV 元件在脚本运行之初就已经加载完毕了。
逻辑控制器 (Logic Controllers)
逻辑控制器(如 If 控制器、Loop 控制器)不属于上述 7 个步骤的线性序列。它们的作用是控制其子元件的执行频率和条件。
- 逻辑控制器内部的元件依然遵循上述 1-7 的执行顺序。
5.4. 总结记忆表
| 顺序 | 元件类型 | 典型用途 |
|---|---|---|
| 01 | Config Elements | 参数化、设置 Header、Cookie |
| 02 | Pre-Processors | 预处理请求数据、加解密 |
| 03 | Timers | 模拟思考时间、控制压力速率 |
| 04 | Sampler | 真正的请求动作 |
| 05 | Post-Processors | 提取 Token、关联变量 |
| 06 | Assertions | 检查返回内容是否正确 |
| 07 | Listeners | 记录日志、生成图表 |
调试建议: 如果你发现变量没有生效,或者请求顺序莫名其妙,请先检查是否有定时器被误放在了全局作用域,或者断言是否放在了错误的位置。利用"查看结果树"配合"调试取样器 (Debug Sampler)"是理清执行顺序最有效的手段。
六、实战演练:一个典型的压测链路
理论结合实践才是掌握JMeter的关键,下面以"模拟1000用户同时登录并访问个人中心"为例,完整演示压测脚本的开发、调试流程,覆盖前面讲到的核心组件和进阶技巧。
6.1 场景设计
需求:模拟1000个虚拟用户(Virtual User),逐步涌入(启动时间10秒),每个用户完成"登录 → 访问个人中心"的操作,持续压测60秒,验证系统在该场景下的稳定性和吞吐量。
6.2 脚本开发(核心步骤)
第一步:CSV 配置账号池
-
准备CSV文件(user.csv),存入1000个测试账号密码,格式如下:username,password;test1,123456;test2,123456...
-
在线程组下添加"CSV数据文件设置",配置CSV文件路径、分隔符(逗号),设置变量名(如username、password),后续登录请求可通过
${username}、${password}引用账号密码。
第二步:登录请求 + Token 提取
-
添加HTTP请求(登录请求),配置请求方法(POST)、域名、路径(/api/login),在Body Data中填写JSON格式的请求体:
{"username":"${username}","password":"${password}"}。 -
添加HTTP信息头管理器,设置Content-Type: application/json。
-
添加JSON提取器,从登录响应中提取Token(响应格式
{"code":200,"data":{"token":"abc123"}}),设置提取规则,将Token存入变量token。 -
添加响应断言,校验响应码为200、响应文本包含"success",确保登录请求成功。
第三步:Header 携带 Token 访问业务接口
-
添加HTTP请求(访问个人中心),配置请求方法(GET)、域名、路径(/api/user/info)。
-
修改HTTP信息头管理器,添加
Authorization: Bearer ${token}(根据接口要求调整Token格式),确保请求携带登录态。 -
添加响应断言,校验响应码为200、响应文本包含用户信息(如
${username}),确保接口访问成功。
6.3 调试与排错
脚本开发完成后,先使用少量线程(如10个)调试,通过"察看结果树"和日志窗口排查错误,常见问题及解决方法:
-
403错误:通常是Token未携带或无效,检查JSON提取器的提取规则是否正确,Header中的Token格式是否与接口要求一致。
-
500错误:服务器内部错误,检查请求参数是否正确(如账号密码错误、参数格式错误),或查看服务器日志,排查后端接口问题。
-
请求超时:检查服务器是否正常运行,或调整JMeter的超时时间(在HTTP请求中设置"连接超时""响应超时")。
七、日常压测 4 大经典场景
前置公共结构, 所有场景通用基础组件:
- 线程组(Thread Group)
- HTTP请求默认值(填域名/端口)
- HTTP取样器(被测接口)
- 察看结果树、聚合报告、Summary Report
- 事务控制器(可选,统计整个接口耗时)
7.1 场景一:单接口基准压测(基准性能)
适用
单接口、无高并发,测接口正常空载耗时、基准TPS、响应时间,用来做版本对比。
标准配置
- 线程数:5~10 并发
- 预热时间(Ramp-Up):5秒
- 循环次数:永久
- 运行时长:3~5分钟
目的
- 看平均响应时间、P95、基准TPS
- 看接口有无偶发报错、抖动
使用场景
开发完接口、改完SQL、改完代码,跑一遍做基线对比。
7.2 场景二:固定并发压测(常规容量测试)
适用
模拟固定用户同时访问,测系统稳定承载能力。
标准配置
- 线程数:20 / 50 / 100 / 200(按业务预估并发)
- Ramp-Up:10秒(10秒内拉起全部并发)
- 循环:永久
- 运行时长:10~15分钟
核心观察
- 固定并发下:响应时间是否平稳
- 错误率是否为0
- TPS是否稳定无断崖下跌
- 服务器CPU/内存/DB负载
7.3 场景三:阶梯加压压测(找系统瓶颈、拐点)
适用
慢慢加并发,找到系统性能拐点、最大可承受并发上限 。 用 阶梯式线程组 / 自定义变量递增
标准阶梯方案
- 初始并发:20
- 每阶段递增:20
- 每阶段持续:5分钟
- 直到:响应时间翻倍 / 错误率 > 1% / CPU 持续90%+ 停止
判定瓶颈标准
出现任意一个就是到极限:
- 平均响应时间比基准翻倍
- 错误率开始上涨
- CPU打满、DBCPU飙高、连接池耗尽
作用
测出:系统最优承载并发、极限承载并发
7.4 场景四:长稳压测(稳定性/疲劳测试)
适用
模拟线上长时间持续流量,查内存泄漏、连接泄漏、线程不释放。
标准配置
- 线程数:线上日常预估并发的 60%~80%(不压满)
- Ramp-Up:10秒
- 运行时长:30分钟 ~ 3小时 甚至更久
重点观察
- JVM 内存是否持续上涨(内存泄漏)
- DB连接池、Redis连接是否不释放
- 接口响应时间是否越跑越慢
- GC 是否频繁 FullGC
- 有无定时任务、日志阻塞、资源泄露
7.5 4种场景极简配置汇总表
| 压测场景 | 并发线程数 | 预热Ramp-Up | 运行时长 | 核心目的 |
|---|---|---|---|---|
| 基准压测 | 5~10 | 5s | 3~5min | 测接口基准耗时、基线TPS |
| 固定并发 | 20/50/100/200 | 10s | 10~15min | 常规容量、线上模拟 |
| 阶梯加压 | 每阶+20 | 每阶10s | 每阶5min | 找性能拐点、极限瓶颈 |
| 长稳测试 | 日常60%~80%并发 | 10s | 30min+ | 查内存/连接泄漏、稳定性 |
八、命令行模式 (Non-GUI) 与分布式压测
新手容易陷入一个误区:用GUI模式进行正式压测,这是非常错误的------GUI模式会占用大量本地资源(CPU、内存),影响压测结果的准确性,甚至导致JMeter崩溃。正式压测必须使用命令行模式(Non-GUI),高并发场景需配合分布式压测。
8.1 GUI vs CLI:为什么正式压测严禁使用 GUI 模式?
核心原因是"资源损耗差异":
-
GUI模式:需要渲染图形界面、实时展示结果,占用大量CPU和内存,当线程数超过100时,就可能出现卡顿、响应延迟,导致压测数据失真。
-
CLI模式:不渲染图形界面,仅执行脚本、收集数据,资源损耗极低,可支持上千甚至上万线程的压测,压测结果更真实、准确。
8.2 CLI 执行命令(核心命令)
进入JMeter的/bin目录,通过命令行执行脚本,核心命令如下(Windows/Mac/Linux通用):
bash
jmeter -n -t [test.jmx] -l [result.jtl] -e -o [report_folder]各参数含义:
-
-n:启用Non-GUI模式(必填)。
-
-t:指定测试脚本路径(.jmx文件,必填)。
-
-l:指定测试结果文件路径(.jtl文件,必填),用于后续生成报告。
-
-e:测试结束后生成HTML报告(可选)。
-
-o:指定HTML报告的输出目录(可选,需与-e配合使用,目录必须为空)。
8.3 HTML 报告解读
通过CLI命令生成的HTML报告,是压测结果分析的核心依据,重点关注3个模块:
-
响应时间图表(Response Time Graph):展示响应时间的变化趋势,可直观看到峰值响应时间、平均响应时间,判断系统是否存在波动。
-
吞吐量趋势(Throughput Graph):展示TPS的变化趋势,若TPS持续下降,说明系统存在性能瓶颈。
-
活动线程数(Active Threads Graph):展示并发线程的变化趋势,验证线程启动节奏是否符合预期(如是否按Ramp-Up Period逐步启动)。
8.4 分布式压测:解决单机瓶颈
当需要模拟上万甚至几十万并发用户时,单机的CPU、带宽会成为瓶颈(即使使用CLI模式,单机也难以支撑),此时需要使用分布式压测,将压测压力分散到多台机器上。
8.4.1 核心架构:控制机 (Controller) 与 执行机 (Worker)
-
控制机(Controller):负责分发脚本、控制压测流程、收集汇总压测结果,仅需1台。
-
执行机(Worker):负责执行压测脚本,发送请求,每台执行机承担一部分并发压力,可有多台(越多并发能力越强)。
8.4.2 配置步骤(核心)
-
所有机器(控制机、执行机)安装相同版本的JMeter和JDK,确保环境一致。
-
修改执行机的jmeter.properties文件:设置server_port=1099(默认端口,可修改),启动执行机(./jmeter-server.sh 或 jmeter-server.bat)。
-
修改控制机的jmeter.properties文件:设置remote_hosts=执行机IP:端口(多个执行机用逗号分隔,如192.168.1.100:1099,192.168.1.101:1099)。
-
控制机通过CLI命令执行分布式压测:在原有命令基础上添加-R参数(指定执行机),如:jmeter -n -t test.jmx -l result.jtl -e -o report -R 192.168.1.100,192.168.1.101。
提示:分布式压测时,所有机器需在同一局域网,关闭防火墙,避免端口被拦截。
九、性能调优与最佳实践
压测的最终目的,是发现系统性能瓶颈并优化,同时规范JMeter的使用方式,确保压测结果真实、可靠,下面分享核心调优技巧和最佳实践。
9.1 JMeter 自身调优:解决JMeter瓶颈
当压测线程数较多时,JMeter自身可能成为瓶颈(如内存溢出、卡顿),需修改jmeter.sh(Mac/Linux)或jmeter.bat(Windows)中的JVM内存参数(Heap Size),优化内存分配:
- 找到文件中的HEAP配置项,默认配置为:HEAP="-Xms1g -Xmx1g -XX:MaxMetaspaceSize=256m"。
- 优化建议(根据本机内存调整):若本机内存为16G,可修改为:HEAP="-Xms4g -Xmx8g -XX:MaxMetaspaceSize=512m",其中-Xms为初始堆内存,-Xmx为最大堆内存,设置为相同值可避免频繁GC,提升性能;MaxMetaspaceSize为元空间大小,用于存储类信息,避免元空间溢出。
9.2 脚本优化:提升压测效率
-
减少监听器使用:调试时用"察看结果树",正式压测时仅保留"聚合报告"或不使用监听器(通过CLI命令生成报告),避免监听器占用过多资源。
-
避免大并发下打印过多日志:修改jmeter.properties文件,降低日志级别(如从DEBUG改为INFO),减少日志输出量。
-
复用配置元件:将HTTP信息头管理器、Cookie管理器等公共配置,放在线程组根目录,避免每个请求重复配置,提升脚本简洁度和执行效率。
-
使用Groovy脚本替代BeanShell:提升脚本执行效率,尤其在高并发场景下,避免BeanShell脚本拖慢压测速度。
9.3 测试结果分析:定位系统瓶颈
压测结果分析的核心,是通过指标判断系统瓶颈所在,常见瓶颈类型及判断方法:
-
CPU瓶颈:服务器CPU使用率持续超过80%,且TPS下降、响应时间延长,需排查CPU密集型操作(如复杂计算、频繁GC)。可通过JDK自带的jstat、jstack工具查看CPU使用情况和线程状态,定位异常线程和方法。
-
IO瓶颈:服务器磁盘IO使用率高、网络带宽饱和,需排查磁盘读写、网络传输(如大文件上传下载、大量数据库查询)。
-
数据库瓶颈:数据库CPU、内存使用率高,或出现死锁、慢查询,需优化SQL语句、添加索引、调整数据库连接池大小。
-
响应时间与并发数的函数关系:正常情况下,并发数增加,响应时间会缓慢上升、TPS会逐渐趋于平稳;若并发数增加到一定程度,响应时间急剧上升、TPS下降,说明已达到系统最大承载能力,此时的并发数即为系统的峰值并发。
十、总结
跟进了这么多次项目,我始终认为:JMeter 不仅仅是一款性能测试工具,更是性能思维的载体。它能帮我们从"被动解决问题"转变为"主动发现问题",提前规避系统性能风险,支撑业务的稳定运行。
需要特别注意的是,实际工作中,压测操作若不规范,极易影响线上服务稳定性或产生大量脏数据,因此必须做好风险防控,核心建议如下:
- 压测环境与生产环境隔离建议:压测务必使用独立的测试环境,且测试环境需尽可能与生产环境(服务器配置、数据库规模、业务数据量)保持一致,避免直接在生产环境进行压测(紧急线上压测除外),防止压测流量冲击线上服务,导致服务卡顿、雪崩。
- 使用独立测试账号、测试数据清理策略:压测时需使用专门的测试账号池,与线上账号严格区分,避免占用线上账号资源;同时制定完善的测试数据清理策略,压测结束后及时删除压测产生的脏数据(如测试订单、测试用户、无效日志),防止脏数据影响测试结果准确性,或污染测试环境。
- 压测前通知机制、熔断/降级预案:压测前需通知相关团队(开发、运维、产品),明确压测时间、压测场景、并发量级,避免因压测引发误报警;同时提前制定熔断、降级预案,若压测过程中发现系统异常(如响应时间骤升、错误率暴涨、服务器负载过高),立即触发熔断机制,停止压测,启动降级策略,将损失降到最低。
从入门的环境搭建、核心组件使用,到进阶的动态关联、脚本增强,再到架构级的分布式压测、性能调优,JMeter的每一个功能,都对应着实际工作中的一个场景。掌握它,不仅能提升性能测试的效率,更能让你从"测试者"转变为"系统性能的守护者"。
最后,补充一个进阶方向:将JMeter接入Jenkins,实现持续集成(Continuous Integration)------通过Jenkins定时触发JMeter压测脚本,自动生成报告,当性能指标不达标时(如TPS低于阈值、错误率过高),自动报警,实现"自动化压测",将性能测试融入研发流程,提前在测试环境发现瓶颈,避免上线后出现问题。其核心流程为:开发者提交代码 → Jenkins触发构建 → 执行JMeter压测脚本 → 生成HTML报告 → 指标校验 → 异常报警,可借助Jenkins的插件生态,实现全流程自动化。
性能测试没有捷径,多练、多排查、多总结,才能真正吃透JMeter,解决实际工作中的各类性能难题。希望这篇全指南,能帮你少走弯路,快速成长为一名合格的性能测试工程师。