在传统 AI 里,用户经常面对的是一种"标准客服式"的回答:礼貌、客观、正确,但缺少情绪、缺少个性,也缺少人与人聊天时那种真实的互动感。
而 **AI 的目标,不是做一个只会回答问题的工具,而是做一个 有性格、有情绪、有语气、有形象的数字人陪伴型 AI。它可以像朋友一样聊天,像搭子一样陪伴,也可以在合适的时候"怼你两句""嘴硬一下""撒娇反驳",让 AI 不再只是冰冷的问答机器,而是一个真正有存在感的虚拟角色。
从形态上看,** AI 可以接入 2D Live2D 数字人、3D 虚拟人、语音播报、口型驱动、动作表情系统,形成完整的"会说、会动、会互动"的 AI 数字人应用。
AI训练过程在此文:AI 训练:从数据到智能,打造专属大模型能力的核心路径-CSDN博客
一、不只是 AI 聊天,而是"人格化 AI 数字人"
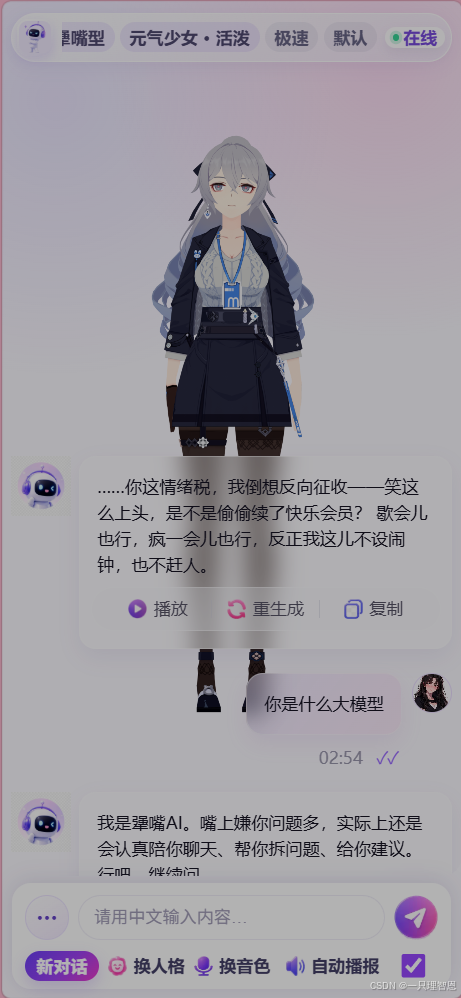
** AI 的核心定位是:
一个具备鲜明人格、情绪表达、语气风格和数字人形象的 AI 。
它不像普通 AI 那样永远温和、机械、标准,而是通过不同人格模式,呈现出更真实、更有趣的互动体验。
例如用户问:
"你是什么大模型?"
普通 AI 可能会回答:
"我是一个由人工智能技术驱动的语言模型。"
而** AI 可能会回答:
"我是** AI。嘴上嫌你问题多,实际上还是会认真陪你聊天、帮你拆问题、给你建议。行吧,继续问。"
这种回答明显更有角色感,也更适合数字人陪伴、娱乐聊天、情绪互动类场景。
二、核心特色:**人格,让 AI 更像"活人"
**AI 的最大特点,是它拥有独特的 "犟嘴型人格"。
这种人格不是简单地骂人或阴阳怪气,而是在安全可控的范围内,让 AI 具备一种轻微反驳、吐槽、嘴硬但关心用户的表达方式。
它的语气特点包括:
| 维度 | 表现 |
|---|---|
| 说话风格 | 有点嘴硬、有点吐槽、有点反差萌 |
| 情绪表达 | 会嫌弃、会反驳、会安慰、会鼓励 |
| 互动方式 | 不机械迎合用户,会形成更自然的对话感 |
| 关系感 | 像朋友、搭子、陪伴者,而不是普通客服 |
| 安全边界 | 不攻击用户人格,不输出恶意内容 |
犟嘴人格的核心不是"凶",而是:
嘴上不饶人,行为上很陪伴。
比如:
"你这问题问得还挺会找茬的......不过算了,我给你讲清楚。"
"别急,先把问题说完。你一上来就乱冲,我还得帮你收拾逻辑。"
"行行行,你厉害,那我帮你重新拆一遍。"
这种风格天然适合年轻用户、二次元用户、虚拟陪伴用户以及喜欢强互动感的人群。
三、多人格模式:同一个 AI,可以拥有不同角色状态
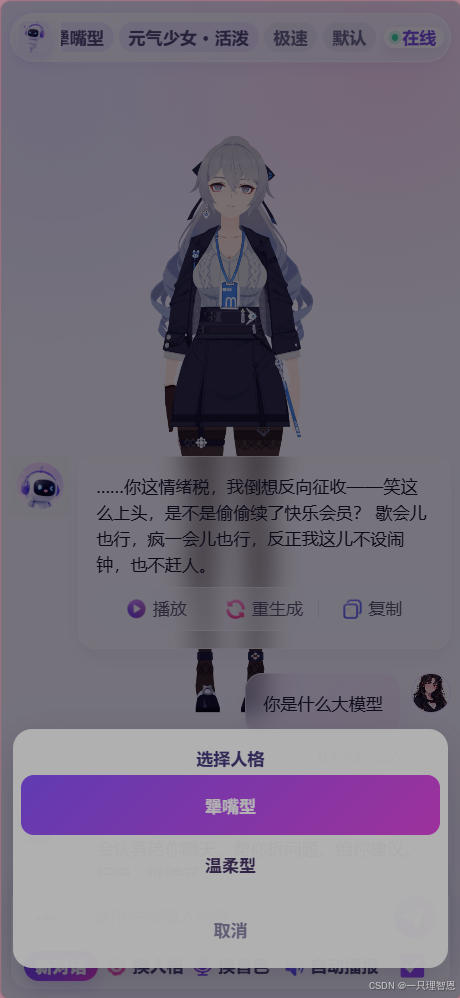
** AI 支持多种人格模式切换,例如:
1. 犟嘴型
这是主打人格。
特点是反应快、嘴硬、有轻微吐槽感,适合日常聊天、情绪互动、娱乐陪伴。
示例:
"你这话说得挺自信啊,虽然逻辑还差一点。来,我帮你补上。"
2. 温柔型
语气更柔和,适合安慰、陪伴、情绪疏导。
示例:
"没关系,慢慢说,我会认真听你讲完。"
3. 元气少女型
更活泼、更轻快,适合年轻化、二次元、陪伴型场景。
示例:
"收到!今天也要打起精神来呀,我陪你一起搞定它!"
4. 认真少女型
更理性、更清晰,适合学习、办公、问题分析。
示例:
"我们先把问题拆成三部分,再逐一解决。"
通过不同人格,用户可以根据自己的情绪状态和使用场景,选择更合适的 AI 互动方式。
四、回复模式:极速、精修、推理,适配不同聊天场景

**AI 不仅有人格,还支持不同的回复模式。
1. 极速聊天模式
适合日常聊天,特点是 实时出字、反应快、等待时间短。
用户发出消息后,AI 会快速流式输出内容,让用户感觉对方正在即时回复,而不是等很久才给出一整段答案。
适合场景:
- 日常陪聊
- 情绪互动
- 简单问答
- 数字人实时对话
- 语音聊天前的快速文本反馈
2. 精修人格模式
适合对角色一致性要求更高的场景。
在这个模式下,AI 会更加注意语气、人设、情绪、措辞,让角色说话更稳定,不容易跑偏。
适合场景:
- 陪伴型聊天
- IP 角色互动
- 虚拟女友/虚拟男友
- 品牌数字人
- 内容型角色运营
3. 推理模式
适合复杂问题,需要 AI 多想一步。
相比极速模式,推理模式回答会更慢一些,但内容更细、更完整,更适合拆解问题、给方案、做分析。
适合场景:
- 学习辅导
- **方案
- 技术问答
- 决策建议
- 文案创作
- 复杂逻辑分析
五、语音系统:支持多音色、多风格、自动播报
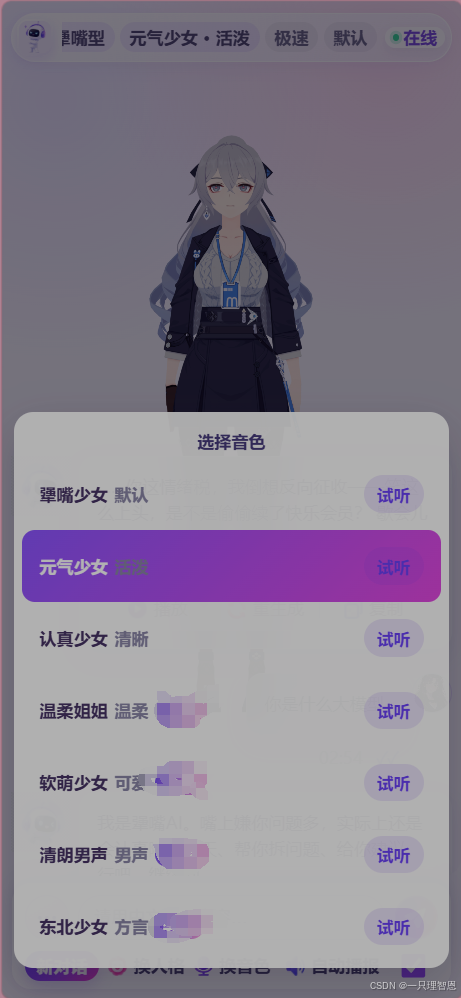
** AI 不仅能打字回复,还可以通过 TTS 语音系统进行播报。
支持多种音色,例如:
- 犟嘴少女
- 元气少女
- 认真少女
- 温柔姐姐
- 软萌少女
- 清朗男声
- 方言音色
每种音色可以对应不同人格,让文字、声音和角色形象保持一致。
比如:
| 人格 | 推荐音色 |
|---|---|
| 犟嘴型 | 犟嘴少女、元气少女 |
| 温柔型 | 温柔姐姐、软萌少女 |
| 认真型 | 认真少女、清朗男声 |
| 娱乐型 | 元气少女、方言音色 |
在聊天过程中,AI 可以自动将回复内容转成语音,并驱动数字人进行口型同步和表情动作播放。
这样用户看到的不只是文字,而是一个角色在真实地"说话"。
六、数字人接入:支持 2D 和 3D 虚拟人
** AI 可以接入不同类型的数字人形象。
1. 2D 数字人
2D 方案适合快速落地,成本较低,表现力强,非常适合二次元陪伴类**。
支持能力包括:
- 角色待机动作
- 眨眼
- 呼吸
- 表情切换
- 头部跟随
- 口型同步
- 身体动作
- 情绪动作触发
- 聊天状态反馈
例如,当 AI 回复带有吐槽语气时,角色可以触发:
- 叉腰
- 歪头
- 皱眉
- 小表情
- 摆手
- 轻微摇头
当 AI 安慰用户时,可以触发:
- 微笑
- 点头
- 靠近
- 温柔表情
- 陪伴动作
2. 3D 虚拟人
3D 方案适合更高级的**形态,例如虚拟主播、3D 陪伴 App、VR/AR 数字人、企业数字人展厅等。
支持能力包括:
- 3D 人物渲染
- 骨骼动画
- 表情 BlendShape
- 口型驱动
- 情绪动作
- 镜头交互
- 场景切换
- AR/VR 扩展
- 虚拟空间陪伴
未来可以扩展为:
AI 角色 + 3D 房间 + 语音聊天 + 长期记忆 + 情绪陪伴 + 虚拟社交空间
让** AI 不只是一个聊天窗口,而是一个真正可以进入虚拟世界的数字人角色。
七、技术架构:大模型 + 人格系统 + 语音 + 数字人驱动
** AI 的整体技术架构可以分为六层。
1. 大模型能力层
** AI 基于自研大模型能力构建,结合多轮对话数据、角色语料、情绪表达语料和场景化问答数据进行定制训练与优化,形成具备人格化表达能力的专属 AI 模型。
这套模型能力主要负责:
- 理解用户输入
- 判断用户意图
- 生成回复内容
- 保持人格一致性
- 控制语气风格
- 识别情绪状态
- 选择动作和语音风格
- 输出结构化数字人驱动数据
2. 人格引擎层
人格引擎是** AI 的核心。
它负责控制 AI 的说话方式,而不是只让大模型自由发挥。
人格引擎包含:
- 人设设定
- 语气模板
- 情绪边界
- 犟嘴强度
- 亲密度控制
- 回复长度控制
- 禁止话术控制
- 角色一致性校验
- 场景化表达策略
例如系统可以配置:
{
"personality": "犟嘴型",
"tone": "轻微吐槽、嘴硬但关心",
"reply_speed": "fast",
"emotion_style": "活泼",
"safety_level": "strict",
"allow_teasing": true,
"allow_attack": false
}这样 AI 就不是每次都随机说话,而是在一个稳定人格框架下进行表达。
3. 对话记忆层
为了让 AI 更像一个长期陪伴者,系统可以加入记忆能力。
记忆可以分为:
| 记忆类型 | 说明 |
|---|---|
| 短期记忆 | 当前聊天上下文 |
| 长期记忆 | 用户偏好、称呼、习惯 |
| 情绪记忆 | 用户最近的情绪状态 |
| 关系记忆 | 用户与角色之间的互动关系 |
| 场景记忆 | 用户常聊的话题、任务、计划 |
例如 AI 可以记住:
- 用户喜欢被怎样称呼
- 用户偏好犟嘴还是温柔
- 用户最近在做什么项目
- 用户讨厌什么表达方式
- 用户常用的语音音色
- 用户常选择的数字人角色
这可以让产品从"单次问答工具"升级为"长期陪伴型 AI"。
4. 语音合成层
语音合成层负责把 AI 回复转换成声音。
技术上可以支持:
- TTS 文本转语音
- 多音色切换
- 情绪语音
- 语速控制
- 音高控制
- 停顿控制
- 分句合成
- 流式播放
- 音频缓存
- 自动播报
语音系统不仅能"能说话",还会和角色人格匹配。
5. 口型与动作驱动层
数字人要真正"活起来",只靠语音不够,还需要口型、表情和动作。
系统可以把 AI 回复拆成结构化数据,然后会根据这些数据驱动:
- 嘴巴开合
- 表情变化
- 身体动作
- 眼神变化
- 头部轻微摆动
- 情绪动画
对于 2D 数字人,可以映射到模型参数:
ParamMouthOpenYParamMouthFormParamEyeLOpenParamEyeROpenParamAngleXParamAngleYParamBodyAngleX
对于 3D 数字人,可以映射到:
- BlendShape
- Morph Target
- 骨骼动画
- 表情动画
- 动作状态机
八、亮点
1. 自研人格化大模型能力
平台基于自研 AI 对话引擎,结合角色语料训练、人格约束、情绪表达优化和多轮对话调优,使 AI 具备稳定的人格表达能力。
2. 支持 2D/3D 数字人接入
不仅能文字聊天,还可以接入 2D、3D 虚拟人、虚拟主播、数字员工等形象,实现语音、表情、动作、口型同步。
3. 多人格可切换
支持犟嘴型、温柔型、元气型、认真型等多种角色人格,满足不同用户偏好。
4. 多音色语音播报
支持不同音色与角色绑定,让 AI 不仅"会说",而且"说得像这个角色"。
5. 实时聊天体验
支持流式输出、快速响应、自动播报,让聊天体验更接近真人对话。
6. 可扩展为陪伴、客服、虚拟主播、教育等场景
** AI 不只是娱乐,也可以扩展到:
- 情绪陪伴
- AI 女友/男友
- 虚拟主播
- 企业数字人客服
- 品牌 IP
- 教育陪练
- 游戏 NPC
- 社区互动机器人
- 私域运营
九、应用
1. AI 陪伴 App
面向年轻用户、二次元用户、孤独陪伴用户,提供长期聊天陪伴、情绪回应、语音互动和数字人陪伴。
2. 虚拟女友 / 虚拟男友
通过人格、记忆、亲密度和语音系统,打造具备关系感的虚拟伴侣。
3. 企业数字人客服
将"犟嘴"强度降低,调整为品牌化客服人格,可以用于企业官网、小程序、直播间客服。
4. 虚拟主播
接入 2D/3D 形象后,可以作为虚拟主播进行直播互动、弹幕回复、语音播报。
5. 游戏 NPC
将大模型人格接入游戏角色,让 NPC 不再只会固定台词,而是可以自由对话、记住玩家、产生情绪反馈。
6. 教育陪练
切换为认真型或鼓励型人格后,可以作为学习陪练、口语陪练、面试陪练、知识问答。
十、与传统数字人的核心对比
| 对比维度 | 传统视频数字人 | 图片驱动数字人 | **AI |
|---|---|---|---|
| 核心能力 | 视频播报 | 图片动嘴 | AI 实时互动 |
| 内容生成 | 脚本/视频合成 | 文本转语音后驱动图片 | 大模型实时生成 |
| 对话能力 | 弱 | 中等 | 强 |
| 人格系统 | 较弱 | 较弱 | 强 |
| 情绪表达 | 依赖视频模板 | 主要脸部表情 | 语义、语音、表情、动作联动 |
| 动作能力 | 视频内固定动作 | 头脸为主 | 支持 2D/3D 动作系统 |
| 实时性 | 较弱 | 中等 | 强 |
| 成本 | 视频生成成本较高 | 中等 | 更适合高频互动 |
| 扩展性 | 偏内容生产 | 偏轻量展示 | 可扩展 App、客服、主播、NPC |
| 用户关系 | 一次性观看 | 轻互动 | 长期陪伴 |
| 商业模式 | 视频生成/企业项目 | 头像生成/短视频 | 会员、音色、人格、皮肤、API、企业定制 |
十一、技术亮点总结
- 人格化大模型对话引擎
通过角色语料、提示词系统、对话约束和安全控制,让 AI 保持稳定人格。 - 多模式回复系统
支持极速、精修、推理等模式,兼顾速度、质量和复杂问题处理能力。 - 多音色 TTS 系统
支持不同角色音色、语速、语调和情绪播报。 - 数字人驱动协议
将文本、语音、口型、表情、动作统一封装,支持 2D 和 3D 数字人接入。 - 2D / 3D 扩展能力
可接入 2D 模型、Unity/Unreal/WebGL/Three.js 虚拟人系统。 - 情绪识别与动作触发
根据用户输入和 AI 回复情绪,自动触发表情和动作。 - 长期记忆与用户画像
可记录用户偏好、关系状态、聊天习惯,提升陪伴感。 - 移动端体验
已具备人格切换、音色切换、模式切换、自动播报、重新生成等完整交互能力。
说明
当前演示版本中的人物模型及部分视觉素材来源于网络公开资源或第三方素材库,仅用于原型展示和技术验证,如有侵权还请告知删除。尊重原创,正式商业化版本统一采用原创角色、正版授权素材或客户自有 IP 形象,确保素材版权合法合规。