引言:算力即权力
2026年,人工智能已从实验室走向千行百业,而大模型、具身智能、自动驾驶等应用的爆发,正将全球推入"算力即权力"的新纪元。在这场变革中,**CPU(中央处理器)、GPU(图形处理器)、NPU(神经网络处理器)**三大算力组件构成了AI时代的"铁三角"------它们各司其职、协同作战,共同支撑着从云端超算到手机终端的智能世界。
然而,算力之争从来不只是技术之争。美国出口管制、国产替代浪潮、绿色算力革命,正将这场竞赛推向地缘政治与产业生态的深水区。本文将从技术原理、产业格局、前沿突破与中美博弈四个维度,深度解析AI+时代的算力革命。
一、三大算力组件:从"通用大脑"到"专用引擎"
1.1 CPU:AI时代的"指挥官"
技术原理 :CPU是计算机的"大脑",采用冯·诺依曼架构,由控制单元、运算单元和高速缓存组成,擅长复杂的逻辑判断、分支预测和串行任务处理。其设计哲学是"通用性优先"------从操作系统调度到数据库查询,从网页渲染到AI推理的协调控制,CPU都是不可替代的指挥官。
在AI中的角色 :尽管GPU和NPU承担了主要的AI计算负载,但CPU在AI系统中扮演着至关重要的协调者角色。在数据中心,CPU负责数据预处理、任务调度、内存管理和与存储系统的交互;在边缘设备,CPU与NPU协同完成传感器数据融合和决策控制。Intel第14代酷睿处理器集成NPU后,实现了"端云协同"的算力动态分配,系统整体延迟降低30%以上 。
2026年最新进展 :CPU正从"通用计算"向"AI原生"演进。ARM发布的2026年技术预测指出,模块化芯粒(Chiplet)技术将重新定义芯片设计,CPU将与专用加速器、内存和互连从系统层面协同设计,针对特定AI框架和数据类型深度优化 。
1.2 GPU:AI训练的"重型引擎"
技术原理 :GPU最初为图形渲染设计,其核心优势在于大规模并行计算。与CPU仅有数十个核心不同,GPU拥有数千个小型计算核心,可同时处理海量矩阵运算和卷积操作------这正是深度学习训练的核心需求。
2026年GPU核心技术------稀疏算力:自英伟达Ampere架构推出以来,稀疏算力已成为高端GPU的标配。其核心原理是:AI模型的数百万至数十亿参数中,并非所有参数都需要参与每次运算。通过将部分参数置零(例如达到50%的稀疏率),可以在不损失模型精度的前提下,实现约2倍的推理加速。英伟达H100 GPU在稀疏算力加持下,FP16 Tensor Core峰值算力可从989.4 TFLOPS提升至1978.9 TFLOPS 。
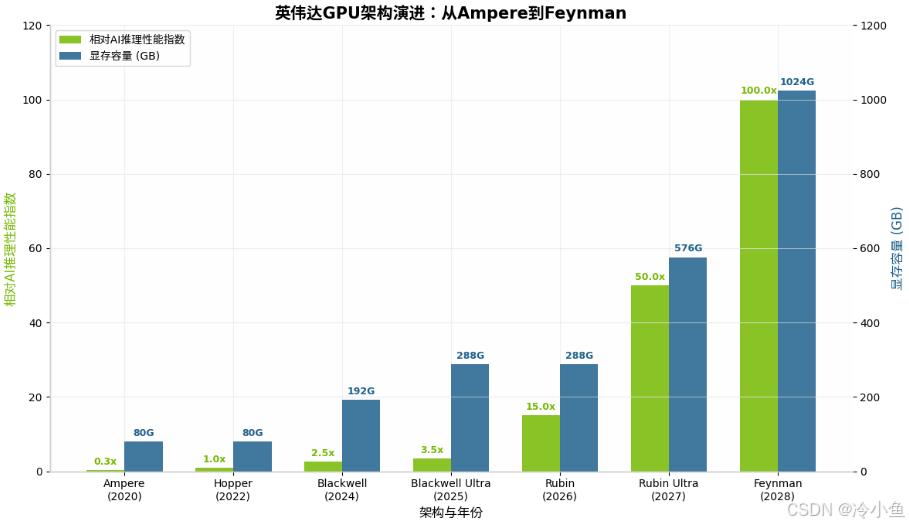
英伟达Blackwell到Rubin的跃迁 :2026年,英伟达正式发布基于Rubin架构的AI加速平台,标志着算力进入ExaFLOPs时代 。Rubin采用台积电3纳米制程,配备288GB HBM4内存,FP4推理性能达到50 PFLOPS (每秒5千万亿次浮点运算),是Blackwell架构的3倍以上 。更激进的路线图显示,2027年的Rubin Ultra将搭载576个计算节点,目标算力达15 ExaFLOPS,配备1TB HBM4e显存 。
国产GPU崛起:在高端GPU受限的背景下,国产GPU正加速突围。AMD的MI355X在DeepSeek-R1推理中,FP4精度下性能较MI300X最高提升3倍 。寒武纪思元590算力达512 TOPS,整体性能约为英伟达A100的80% 。
1.3 NPU:边缘AI的"能效之王"
技术原理 :NPU(神经网络处理器)是专为AI推理设计的专用芯片。与GPU的通用并行架构不同,NPU在电路层模拟人类神经元和突触 ,采用深度学习指令集直接处理大规模神经元和突触,一条指令即可完成一组神经元的处理 。其核心设计聚焦于乘加阵列、片上SRAM和最小化内存移动,强调低精度算术(INT8/INT4)和紧密的内存-计算集成 。
端侧NPU的爆发 :2024-2026年,手机NPU算力呈现"军备竞赛"态势。苹果A18 Pro的16核Neural Engine达到35 TOPS ,高通Snapdragon 8 Elite(Gen 4)飙升至75 TOPS ,联发科Dimensity 9400突破50 TOPS 。短短7年间,移动端NPU性能提升了58倍------从2017年iPhone X的0.6 TOPS到如今的35+ TOPS 。
NPU vs GPU vs CPU的能力维度:
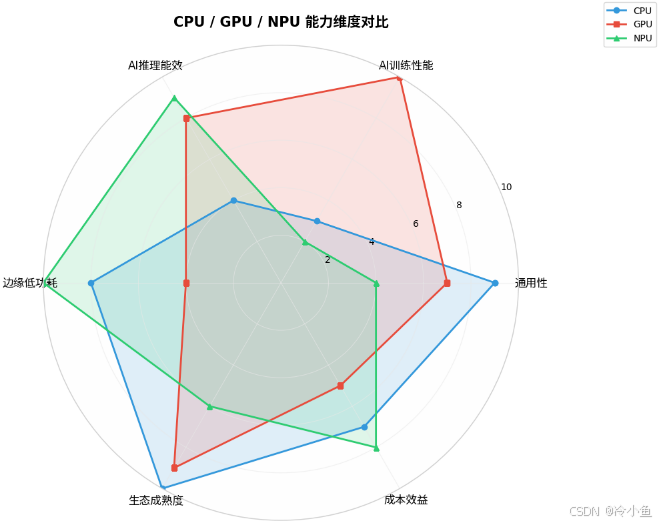
CPU在通用性和生态成熟度上占优,GPU在AI训练性能上领先,NPU在边缘低功耗和AI推理能效上独占鳌头
二、产业格局:从"英伟达独大"到"群雄并起"
2.1 全球AI芯片市场:千亿美元赛道的结构性转变
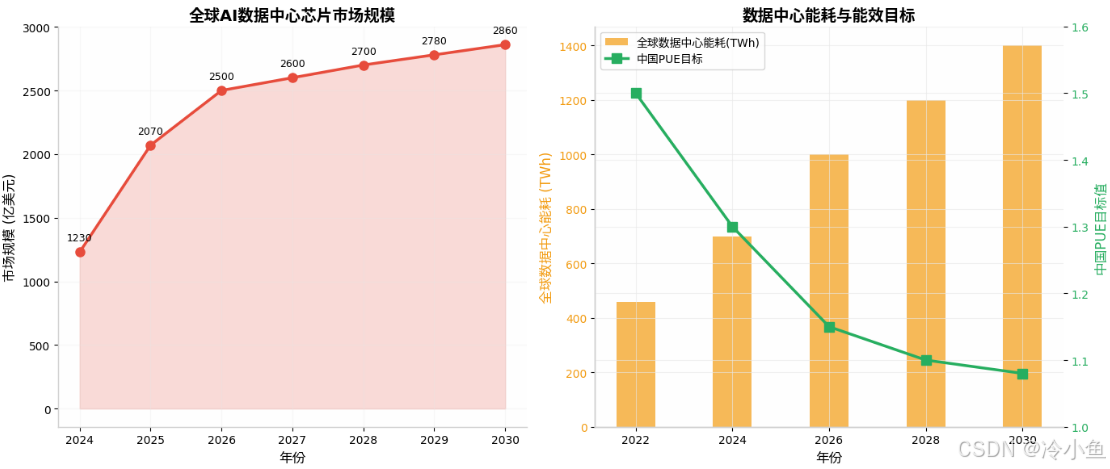
2025年,全球AI数据中心芯片市场规模达到2070亿美元 ,较2024年的1230亿美元增长67%。但Omdia预测,这一高速增长将在2026年达到峰值,此后增速逐步放缓至2030年的2860亿美元 。关键转折在于:推理算力取代训练算力,成为核心增长引擎。
非英伟达解决方案抬头:市场正从"英伟达一家独大"转向多元化。定制ASIC(如Google TPU、Amazon Trainium)、AMD Instinct加速器以及各类ASSP芯片正受到市场日益强烈的欢迎 。德勤2026年全球半导体报告指出,AI、半导体和云基础设施提供商之间的战略联盟预示着新一轮AI计算资本周期的到来 。
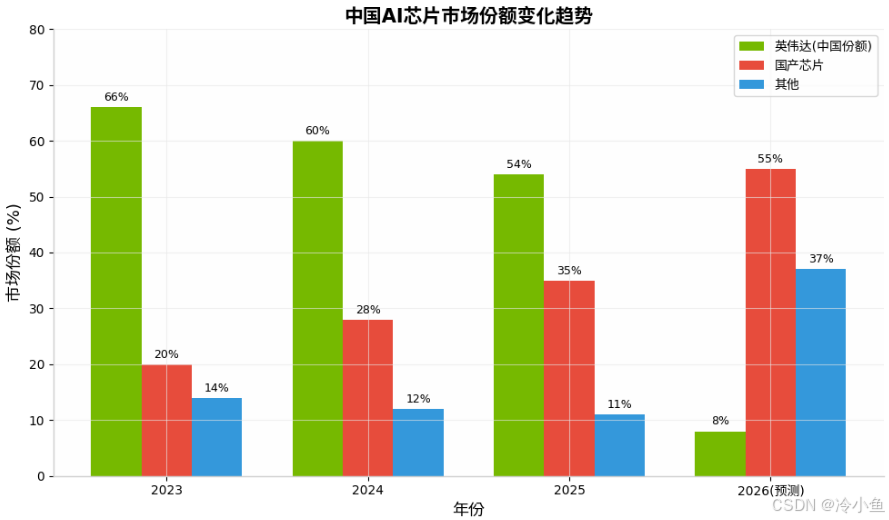
2.2 国产AI芯片:从"政策保护"到"市场验证"
2026年,国产AI芯片正经历关键过渡。根据IDC数据,2026年Q1中国AI芯片市场规模同比增长87.2% ,其中国产AI芯片份额首次突破55% ,同比提升21个百分点;在政务、金融、能源等关键行业,国产芯片采购占比已超70% 。
华为昇腾 :作为国内AI芯片绝对龙头,华为昇腾占据国内AI芯片市场40%份额,预计2026年将提升至50% 。昇腾910B的FP16算力达320 TFLOPS,能效比1.53 TFLOPS/W,显著优于英伟达H20的0.82 TFLOPS/W 。华为预计2026年Q4推出Atlas 950超节点,总算力是英伟达NVL144的6.7倍,内存容量达1152TB 。
寒武纪与海光 :寒武纪2025年Q1营收同比增长4230%,思元590获得互联网大厂大规模采购 。海光信息DCU芯片支持全精度AI计算,2025年Q2单季度营收环比增长45%,推理卡出货占比提升至60% 。
生态突破:DeepSeek V4系列模型已与华为昇腾、寒武纪、海光信息等国产芯片深度适配。百度飞桨、华为MindSpore两大国产深度学习框架已适配国内90%以上的大模型,打破了海外框架的垄断格局 。
三、最前沿技术:突破物理极限的三大方向
3.1 Chiplet与先进封装:算力的"模块化革命"
随着摩尔定律逼近物理极限,Chiplet(芯粒)技术成为2026年高端算力芯片的标准设计方案。通过将多个小芯片异构集成在同一封装中,Chiplet突破了单芯片面积限制,兼顾性能、成本与良率,缓解了对先进制程的依赖 。
台积电已将CoWoS(Chip on Wafer on Substrate)产能扩大到每月10万片以上,以处理高性能AI加速器的积压订单 。英伟达Rubin平台采用"Vera CPU+双GPU"超级芯片设计,配合288GB HBM4内存,实现异构计算单元的深度融合 。
3.2 存算一体与光子芯片:颠覆性架构探索
存算一体(Computing in Memory) :通过将存储单元和计算单元融合,减少数据传输延迟,提高计算效率和能效比。美国Mythic芯片能效比已达100 TOPS/W,中国知存科技WTM2已量产 。预计到2027-2029年,存算一体芯片将进入主流市场 。
光子芯片:利用光信号进行计算,突破电子传输的带宽和能耗瓶颈。曦智科技的光子AI芯片已在金融风控场景落地,IBM量子系统One优化供应链路径 。光子芯片的潜力在于:光互连的带宽可达电子互连的100倍以上,而能耗仅为1/10。
3.3 神经形态芯片:模拟人脑的"硅基神经元"
神经形态芯片在事件发生时处理信息,而GPU始终全速运行。对于涉及偶发信号的AI任务(如传感器数据分析、自动驾驶信息处理),神经形态芯片的能效比可达传统芯片的80到100倍 。预计到2030年,神经形态计算将得到广泛应用。
四、绿色算力:从"电老虎"到"碳中和"
4.1 能耗危机:AI的"阿喀琉斯之踵"
AI大模型训练是能源密集型任务。ChatGPT日耗电约50万度 ,国际能源署预测2026年全球数据中心耗电量将达1万亿千瓦时 (相当于日本全年用电量),占全球发电量的2% 。IDC预测,中国智能算力规模到2026年将达到1271.4 EFLOPS,五年复合增长率达52.3% 。
4.2 液冷技术:从"可选项"到"必选项"
当单颗AI芯片功耗突破1000瓦(英伟达B200约1000W,后续R200将达2300W),传统风冷已触及物理天花板。液冷技术凭借高出空气千倍的热承载能力,成为支撑高密度算力的唯一路径 。
- 冷板式液冷:技术成熟,已在数据中心规模化商用,PUE可降至1.1-1.2
- 浸没式液冷:散热效率达98%,可实现90%余热回收,PUE降至1.1
- 政策驱动 :中国明确要求到2026年,新建大型数据中心PUE必须低于1.15
五、中美博弈:从"技术封锁"到"战略相持"
5.1 美国出口管制的"精准打击"
2026年,美国对华AI芯片管制进入新阶段。4月,美国商务部升级对H20等芯片的出口限制,要求无限期禁止对华出口,导致英伟达需计提55亿美元 损失 。美国国会推动《MATCH法案》,将对华半导体管制重点转向DUV光刻机等制造设备,试图在源头制约中国半导体自主发展 。
更具争议的是,美国商务部BIS发布新规,在全球任何地方使用华为昇腾芯片均违反美国出口管制 。这种"长臂管辖"标志着管制范围从硬件销售扩展到算力服务。
5.2 中国的"非对称突围"
面对封锁,中国采取"以巧破力"策略。黄仁勋指出:"AI本质上是并行计算问题,中国完全可以通过堆叠更多芯片来弥补单颗芯片的制程差距" 。华为Atlas 950超节点的卡规模是英伟达NVL144的56.8倍,总算力是其6.7倍,互联带宽是其62倍 。
DeepSeek现象 :DeepSeek通过MoE架构和模型压缩技术,千亿参数模型训练成本仅为同类的1/10,其开源策略加速了全球AI普及 。斯坦福大学2026年度《AI指数报告》显示,中美大模型性能差距已收窄至2.7%,基本实现技术追平 。
5.3 竞争格局的"战略相持"
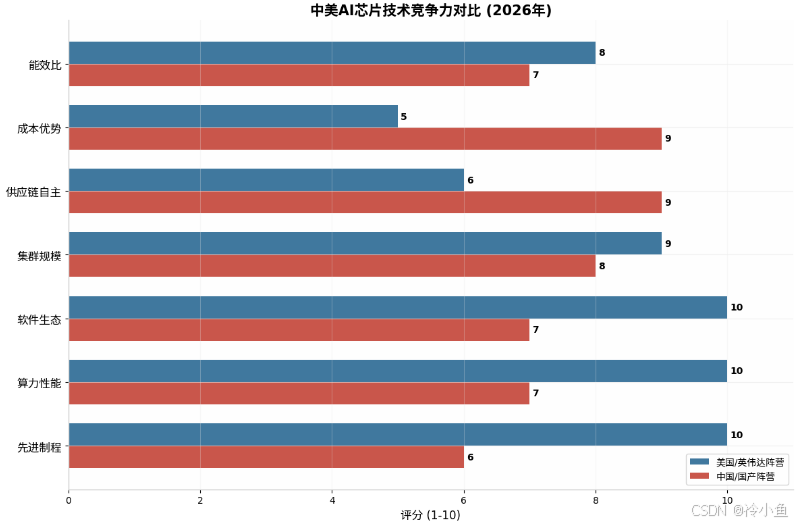
2025-2026年的核心事件清晰印证,中美博弈已从"美攻中守"转入战略相持------力量差距收敛、攻防平衡、竞争常态化 。在芯片领域,美国凭借先进制程和生态优势维持领先,中国通过集群规模、成本优势和供应链自主构建韧性。
六、未来展望:2027-2030年的五大趋势
趋势一:推理算力主导,边缘AI爆发
2026年是行业关键分水岭,推理算力取代训练算力成为核心增长引擎 。边缘AI直接在设备上运行,无需依赖云端,2024年具备生成式AI功能的智能手机销量同比增长364%,预计2028年将达9.12亿部 。
趋势二:异构计算深度融合
CPU+GPU+NPU的融合架构将成为主流。Intel、高通、苹果均在SoC中集成三类处理器,实现"端云协同"的算力动态分配。未来,系统级协同设计的定制化芯片将从底层开始将专用CPU、加速器、内存和互连共同设计在一起 。
趋势三:2nm及以下制程竞赛
2026年,半导体行业过渡到2纳米工艺节点,采用环栅(GAA)晶体管架构。台积电、三星和英特尔主导竞争:台积电在先进封装和晶圆产能方面保持领先;三星专注提高GAA良率;Intel则押注RibbonFET技术 。
趋势四:AI原生计算架构
硬件、软件、框架从设计之初即为AI优化,从"适应AI"转向"为AI而生"。支持更大模型、稀疏计算、动态形状的AI原生架构,将重新定义数据中心的算力效率 。
趋势五:算力网络与"算力即水电"
通过网络感知算力、算力感知网络,实现跨地域、跨服务商的算力资源智能编排与交易,使"算力像水电一样"随取随用 。中国依托"东数西算"工程,已建成全球第二大算力网络。
结语:算力民主化与智能普惠
从CPU的通用智慧,到GPU的并行暴力,再到NPU的专用高效,三大算力组件的协同进化,正在将AI从云端推向边缘,从实验室推向千家万户。2026年的算力革命,不仅是技术的跃迁,更是权力的重构------当国产芯片突破55%市场份额,当边缘NPU让手机拥有工作站级AI能力,当液冷技术让数据中心走向碳中和,我们正见证一个算力民主化的新纪元。
然而,地缘政治的阴影依然笼罩。美国的技术封锁与中国的自主突围,将在未来五年持续博弈。但可以确定的是:算力需求不会停止,技术创新不会停滞,AI+时代的算力革命,终将推动智能普惠的浪潮席卷全球。