很多人已经开始感觉到,面试的画风变了。
以前问的是"Selenium怎么定位元素",后来问"接口自动化框架怎么设计"。现在,字节跳动、阿里的面试官手里拿着一张架构图,指着其中一个节点问你:"如果Agent在这里调用工具失败,你的重试和兜底机制是什么?"
那一刻,空气突然安静。
这不是段子,这是2026年测试工程师面试的真实切片。当你还在用AI生成脚本的时候,大厂已经在考察你构建AI系统的工程能力了。
一、 现象:从"生成代码"到"构建系统"
Cursor、Claude Code、Trae这些工具太强了,强到让我们产生一种幻觉:只要Prompt写得好,AI就能搞定一切。
但在大厂的面试现场,这种幻觉会被瞬间击碎。
面试官不看你生成的代码有多漂亮,他们看的是你的Agent运行时(Runtime) 是否健壮。所谓的"调了三个工具就死循环",本质上是缺乏工程化的控制面(Control Plane)。
二、 本质:Agent不是魔法,是状态机
为什么以前的自动化测试不需要考虑这个问题,现在的Agent必须考虑?
本质是执行模式的改变。 传统自动化是图灵完备的确定性程序,每一步都在预期内。而基于LLM的Agent是非确定性的概率程序。
Agent的工作流不是线性的,而是一个状态机(State Machine)。
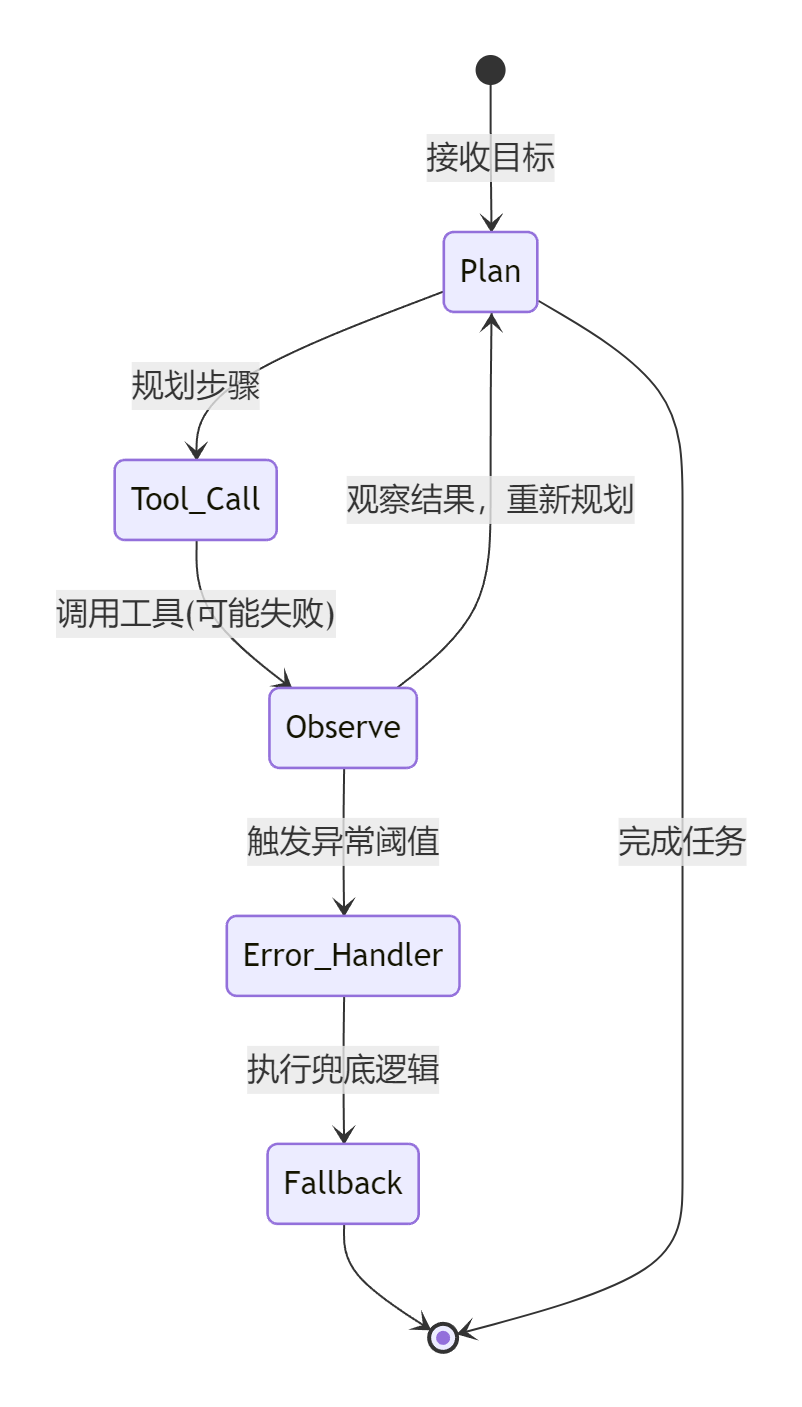
核心在于,当"Observe(观察)"这一步出现异常时,系统必须有能力跳出循环,而不是让LLM陷入无限的"尝试-失败-再尝试"的怪圈。
三、 机制拆解:Agent的三重异常处理
字节面试官问的那个问题,实际上是在拷问你对Agentic Engineering的理解。在工程落地中,我们需要三层防御机制:
1. 工具层的硬隔离(Hard Guardrails) 这是最基础的。在Agent调用外部API(Tool)时,必须包裹try-catch。 不仅仅是捕获异常,还要返回结构化的错误信息给LLM。比如:{"status": "failed", "error_type": "Timeout", "retry_after": 5}。
2. 推理层的熔断机制(Circuit Breaker) 这才是面试官的考点。如果同一个工具连续失败3次,或者Agent在"调用工具A -> 失败 -> 调用工具A"之间循环,系统必须强制中断。 你需要实现一个Max Iteration Check 或者Loop Detection模块。一旦触发,立即终止当前Reasoning Chain,并返回给用户:"任务失败,原因:XXX"。
3. 规划层的自我修正(Self-Correction) 更高级的做法是,当工具调用失败时,不仅报错,还要让Agent反思:"刚才哪里做错了?是不是参数不对?要不要换一个工具?" 这正是微软《AI Agents for Beginners》课程中提到的Reflection Pattern(反思模式)。
四、 对比:脚本思维 VS Agent思维
| 维度 | 传统自动化脚本 | AI测试智能体 (Test Agent) |
|---|---|---|
| 异常处理 | try-catch-fail | 反思-重试-兜底-熔断 |
| 失败归因 | 日志报错,脚本停止 | LLM分析错误,决定下一步 |
| 循环控制 | 代码逻辑控制 | Max Steps / Loop Detection |
| 健壮性 | 取决于代码覆盖率 | 取决于Prompt + Runtime逻辑 |
五、 落地启示:给你的Agent装上刹车
如果你现在正在做AI测试相关的项目,或者准备面试,请立刻检查你的代码里有没有以下几样东西:
-
Max Iteration Limit:一定要限制Agent的最大思考/行动步数。这是防止死循环的最有效手段。
-
Human-in-the-loop:在关键操作(如删除数据、发版)前,预留人工确认的接口。
-
Structured Output Parsing:不要让LLM自由发挥返回结果,强制它输出JSON。这样你才能用代码去解析它的状态,而不是靠正则去捞文本。
记住一句话:能被AI生成的代码不值钱,能控制AI不失控的工程能力才值钱。
六、 趋势:从Vibe Coding到Agentic Engineering
2025年是Vibe Coding(氛围编程),大家比拼谁Prompt写得溜。 2026年必然是Agentic Engineering(智能体工程),大家比拼谁的系统跑得稳。
OpenAI、微软、Anthropic都在推自己的Agent SDK,核心都在解决Orchestration(编排) 和**Safety(安全)**问题。
未来的测试工程师,不仅要懂测试,还要懂分布式系统的容错设计。
你的AI测试智能体,现在有熔断机制吗?