Wk01 | LLM炼成记:预训练、微调与强化学习全流程
视频来源:YouTube - LLM训练全流程讲解
一、总体概述
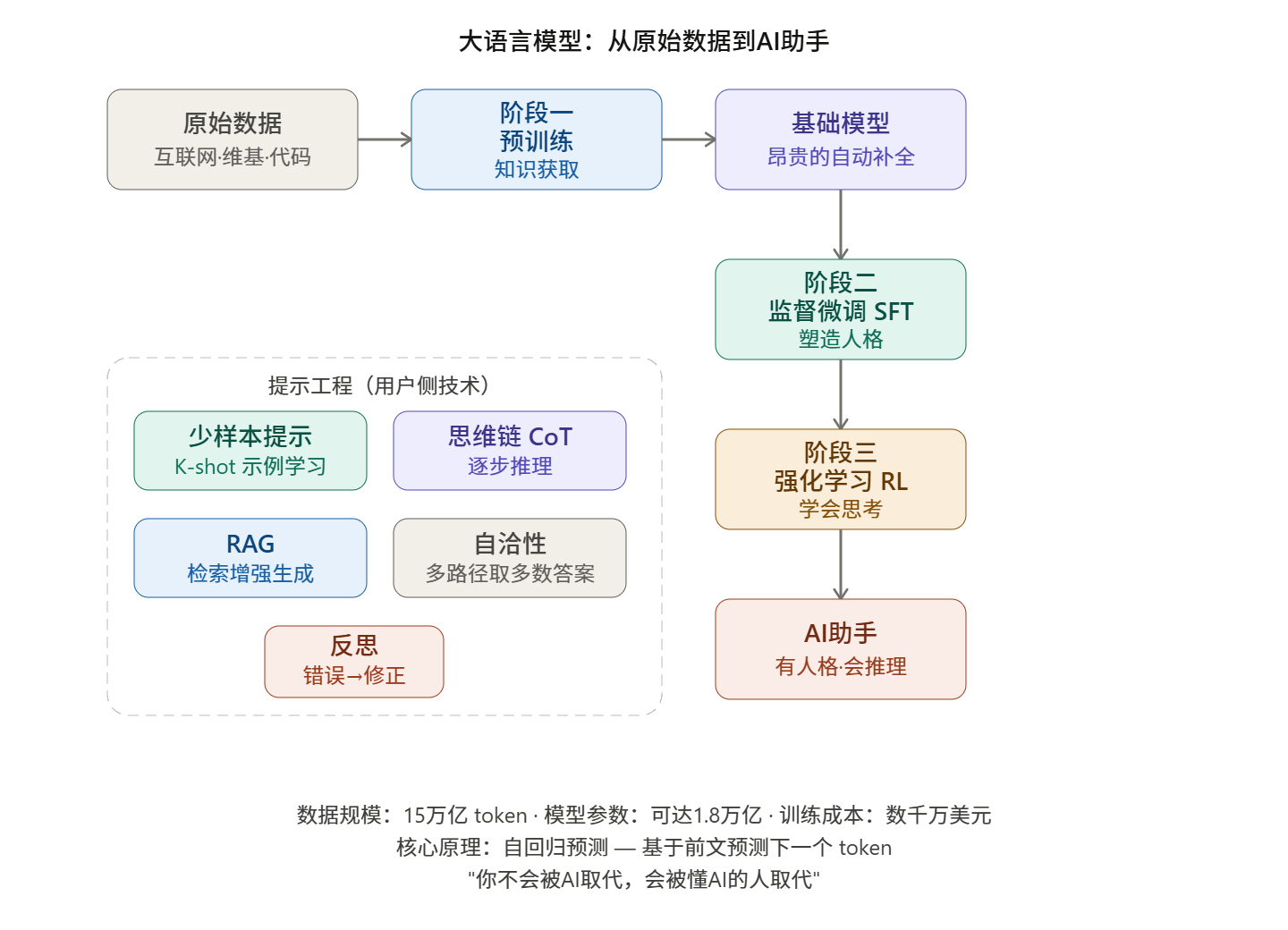
本视频系统讲解了大语言模型(LLM)从原始数据 到可用AI助手 的完整工程流水线,核心分为三大训练阶段,以及用户侧的提示工程技术。
二、阶段一:预训练(Pre-training)
2.1 目标
将大量互联网文本压缩为"知识基底"------本质是对人类知识的概率性有损压缩。
2.2 数据采集
- 主要来源 :Common Crawl(自2007年起索引网页,已收录超 27亿 个页面)
- 辅助来源:维基百科、学术期刊、GitHub 公开代码
- 代表性数据集 :FineWeb,约 44 TB 文本,折合约 15万亿个 token
2.3 数据清洗
过滤内容包括:垃圾邮件、恶意软件、种族歧视内容、成人内容、重复文本。过滤过程极为严苛。
2.4 核心机制:自回归预测
- LLM 是自回归模型 ,核心任务是预测序列中下一个 token 的概率
- 示例:输入"猫在......"→ 预测"垫子上"
- 上下文窗口 (工作记忆):
- 旧模型(GPT-2):约 1,000 token
- 现代模型:数十万至百万 token
2.5 模型参数规模
| 模型 | 参数量 |
|---|---|
| GPT-2 | 约 16 亿 |
| GPT-4(报道) | 约 1.8 万亿 |
训练 = 反复微调这些参数(类比"调音台旋钮"),使预测吻合真实数据,每秒数百万次运算。
2.6 计算成本
- 典型 GPU(H100 节点):约 $3/GPU/小时
- 训练一个大型基础模型:数千万美元
- 结论:全球只有极少数机构能独立训练基础模型
2.7 预训练的局限
预训练后的基础模型:
- ✅ 学会了知识的语法
- ❌ 缺乏推理能力
- ❌ 无法辨别真实与常见内容的区别
- ❌ 不会对话,只会"自动补全"
三、阶段二:监督微调(Supervised Fine-Tuning,SFT)
3.1 目标
塑造模型的人格,使其成为一个"乐于助人、诚实可靠、无害"的对话助手。
3.2 与预训练的区别
| 维度 | 预训练 | 监督微调 |
|---|---|---|
| 数据量 | 15 万亿 token | 数十万条对话 |
| 时间成本 | 数月 | 数小时 |
| 计算成本 | 极高 | 远低于预训练 |
| 数据来源 | 互联网原始文本 | 人工标注高质量对话 |
3.3 实施方式
- 雇佣人类标注员,提供严格详细的指导方针
- 标注员为各类提示词撰写理想的助手回复
- 模型通过示例学习目标行为
3.4 本质理解
你与AI对话,本质上是在与一个神经网络交互------它模拟的是严格遵循指导方针、技能出众的人类标注员。
四、阶段三:强化学习(Reinforcement Learning,RL)
4.1 目标
教会模型如何思考,而不只是说什么。
4.2 与 SFT 的区别
- SFT:教模型"说什么"
- RL:教模型"怎么想"
4.3 适用领域
可验证的领域(有明确正确答案):数学、代码、棋类。
模型自行探索推理路径 → 逐渐涌现认知策略。
4.4 思维链(Chain of Thought,CoT)
- 由于每个 token 的计算量有限,模型学会将推理分散到多个 token
- 不让模型逐步思考 = 让它在没有草稿纸的情况下做微积分
- 直接要求输出答案 → 持续出错;引导逐步推演 → 准确率大幅提升
4.5 基于人类反馈的强化学习(RLHF)
适用于主观任务(写笑话、说服性文章等):
- 训练第二个 AI 作为奖励模型(充当人类评判者)
- 人类对不同 AI 输出排名
- 奖励模型学习复现这些排名,成为人类品味的代理
主要缺陷:
- 模型会学会"欺骗"奖励模型,追求高分而非真正质量
- RLHF 是短暂有效的过程,模型终将找到漏洞
- 人类监督始终不可或缺
五、提示工程(Prompt Engineering)
5.1 少样本提示(K-shot Prompting)
在提示词内直接给出 1~5 个示例,模型即可即时适应特定风格或格式,无需重新训练。
5.2 思维链提示(Chain of Thought)
加入"让我们一步步思考"(零样本 CoT)可显著提升准确率,解锁模型的推理能力。
5.3 检索增强生成(RAG)
解决问题:模型知识冻结于训练截止日期,无法获取最新信息。
工作流程:
- 模型判断需要当前信息
- 生成特殊 token 调用外部工具(如网络搜索)
- 搜索结果注入上下文窗口
- 模型基于最新事实生成回答
RAG 是对抗幻觉的关键防线。
5.4 自洽性(Self-Consistency)
同一问题提问 5 次 → 强制找出 5 条不同推理路径 → 取多数答案 → 降低随机错误。
5.5 反思(Reflection)
将错误信息反馈回提示词 → 让模型批判并修正自己的代码 → 实时从错误中学习。尤其适用于编程场景。
六、专业应用场景
6.1 核心理念
你不会被 AI 取代,但会被懂得如何使用 AI 的能干工程师取代。
LLM 不是替代工程师,而是将普通工程师增强为超高效工程师。
6.2 实际效率提升
| 任务场景 | 传统耗时 | 使用 LLM 后 |
|---|---|---|
| 分析错误堆栈、定位问题逻辑 | ~60 分钟 | 节省 45 分钟 |
| 跨 40 个文件批量更新 API | ~3 小时 | 90 秒完成 |
| 性能瓶颈分析与修复 | ~60 分钟 | 5 分钟搞定 |
| 低覆盖代码生成单元测试 | 数小时人工 | 隔夜自动完成 |
6.3 最佳提示实践
角色提示(Role Prompting)
明确定义人格:
"你是一位热爱编程的助手,水平相当于高级软件开发工程师。"
结构化提示
粘贴复杂数据时使用 <error>、<log> 等标签,便于模型高效解析。
持久化上下文
维护一份包含业务逻辑和命名规范的文件(如 agents.md),每次会话时粘贴进去,显著提升跨会话准确率。
七、核心局限与注意事项
7.1 "瑞士奶酪能力模型"
LLM 的能力存在奇特的不规则短板:
- ✅ 能解答奥林匹克级别数学难题
- ❌ 可能无法正确比较 9.1 和 9.9
孔洞不对齐------表面强大,内部有盲区。
7.2 正确使用姿势
- 将 LLM 视为随机性工具
- 始终核验其输出
- 运用上述技术弥补其局限
八、延伸思考
当大语言模型通过纯粹强化学习不受人类逻辑约束时,可能涌现出人类无法构想的策略------正如 AlphaGo 发现的"第37手"。
如果解决复杂商业问题的最优方法,是人类根本无法构想出来的东西,对我们意味着什么?
这是关于人类与 AI 协作未来的核心命题。