大家好!今天咱们不聊那些云里雾里的理论,直接上手实操 ------ 如何在 Next.js 项目中接入本地运行的 Ollama 大模型,做出和 ChatGPT 一样的流式输出效果(就是那种一个字一个字蹦出来的打字效果)。全程免费、数据不出本地,新手也能跟着做,看完就能落地!
🧩 先搞懂:整体架构到底是啥样?
在动手写代码前,咱们先画个简单的流程图,把核心逻辑捋清楚,不然写代码就像无头苍蝇:
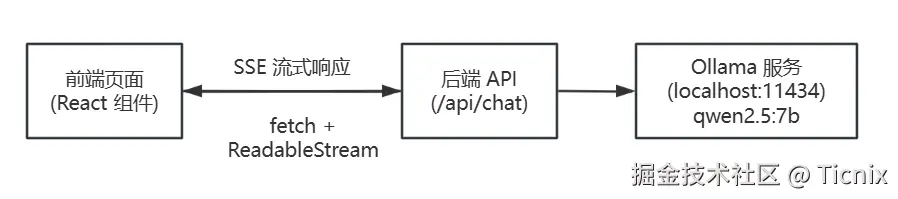
你可以把这个过程想象成:
- 你(用户) 对着前端页面说话(发消息)→ 前端把话传给后端 API(相当于传话的小助理);
- 后端助理 先看看本地的 Ollama 大模型(相当于你的私人智囊)有没有上班(服务是否运行);
- 助理 把你之前说的话 + 现在说的话 + 给智囊的提示词整理好,传给智囊;
- 智囊 不一次性把答案说完,而是一个字一个字地通过 "特殊通道"(SSE)传给助理;
- 助理 再把每个字实时传给前端,前端就显示出打字效果;
- 等智囊说完所有话,助理把完整答案存到数据库里,方便你之后看。
核心亮点:全程流式传输,不用等完整答案,用户体验和 ChatGPT 几乎一致,而且所有数据都在本地,隐私拉满!
🐑 第一步:搞定本地大模型 Ollama
为啥选 Ollama?咱们先唠唠这个 ------ 毕竟市面上能跑本地的大模型工具不少,但 Ollama 是真的 "傻瓜式友好":
| 特性 | 白话解读 |
|---|---|
| 完全免费 | 不用充钱、不用 API Key,白嫖到底 |
| 隐私安全 | 数据都在你自己电脑里跑,不怕泄露 |
| 模型超多 | 支持通义千问、Llama、DeepSeek 等,中文模型也贼好用 |
| 容易迁移 | API 格式和 OpenAI 差不多,以后想切云端模型也方便 |
🔧 安装 Ollama(3 步搞定,超简单)
不管你是 Windows、Mac 还是 Linux,跟着做就行:
bash
# 1. 下载安装包(直接戳链接,傻瓜式安装)
# macOS: https://ollama.ai/download
# Windows: https://ollama.ai/download
# Linux: 复制下面这行到终端回车
curl -fsSL https://ollama.ai/install.sh | sh
# 2. 下载中文模型(推荐通义千问7B,中文效果贼棒)
ollama pull qwen2.5:7b # 通义千问7B(主力推荐)
ollama pull llama3.2:3b # Llama 3.2(轻量款,低配电脑也能跑)
ollama pull deepseek-r1:7b # DeepSeek(推理能力强)
# 3. 启动服务(默认端口11434,不用改)
ollama serve这里插个小提醒:第一次下载模型可能要等一会儿(毕竟几个 G),但安装完成后启动贼快,而且模型只会加载一次,后续调用秒响应。
📦 封装 Ollama 服务(核心代码 + 白话讲解)
咱们把 Ollama 的调用逻辑封装成一个工具函数,方便后续复用。新建src/lib/ollama.ts文件,代码如下,每一行都给你讲明白:
ts
// 第一步:配置基础信息(可以通过环境变量改,灵活)
const OLLAMA_BASE_URL = process.env.OLLAMA_BASE_URL || "http://localhost:11434";
const DEFAULT_MODEL = process.env.OLLAMA_MODEL || "qwen2.5:7b";
// 定义消息格式(约束数据结构,避免传错参数)
export interface ChatMessage {
role: "system" | "user" | "assistant"; // 角色:系统/用户/助手
content: string; // 消息内容
}
// 流式调用的配置项(回调函数是核心)
export interface StreamOptions {
model?: string; // 要使用的模型
messages: ChatMessage[]; // 对话历史+当前消息
onToken: (token: string) => void; // 拿到每个字的回调(打字效果靠它)
onComplete: (fullResponse: string) => void; // 全部说完的回调
onError: (error: Error) => void; // 出错的回调
}
// 核心函数:流式调用Ollama
export async function streamChat(options: StreamOptions): Promise<void> {
const { model = DEFAULT_MODEL, messages, onToken, onComplete, onError } = options;
try {
// 1. 给Ollama发请求(重点:stream: true 开启流式输出)
const response = await fetch(`${OLLAMA_BASE_URL}/api/chat`, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
model,
messages,
stream: true, // ⭐ 关键中的关键:不开这个就是一次性返回所有内容
}),
});
if (!response.ok) {
throw new Error(`Ollama罢工了:${response.status}`);
}
// 2. 获取流读取器(相当于接水管,把Ollama的输出一点点接过来)
const reader = response.body?.getReader();
if (!reader) {
throw new Error("没接到水管,拿不到数据");
}
const decoder = new TextDecoder(); // 把二进制数据转成咱们能看懂的字符串
let fullResponse = ""; // 存完整的回答
// 3. 循环读取每个字(核心循环,直到读完所有内容)
while (true) {
const { done, value } = await reader.read();
if (done) break; // 读完了就退出循环
// 4. 解码数据块(把二进制转字符串)
const chunk = decoder.decode(value, { stream: true });
// 按行分割(Ollama每行返回一个JSON,方便解析)
const lines = chunk.split("\n").filter((line) => line.trim());
// 5. 解析每一行,拿到单个字
for (const line of lines) {
try {
const data = JSON.parse(line);
if (data.message?.content) {
const token = data.message.content; // 这就是单个字/词
fullResponse += token; // 拼完整回答
onToken(token); // 触发回调,把这个字传给前端
}
} catch {
// 忽略解析错误(偶尔会有空行,不影响)
}
}
}
// 6. 全部读完,触发完成回调
onComplete(fullResponse);
} catch (error) {
// 出错了,触发错误回调
onError(error instanceof Error ? error : new Error("未知错误,反正就是错了"));
}
}
// 辅助函数:检查Ollama是否在运行,以及有哪些模型可用
export async function checkOllamaStatus(): Promise<{ running: boolean; models: string[] }> {
try {
const response = await fetch(`${OLLAMA_BASE_URL}/api/tags`);
if (!response.ok) {
return { running: false, models: [] };
}
const data = await response.json();
return {
running: true,
models: data.models?.map((m: { name: string }) => m.name) || [],
};
} catch {
return { running: false, models: [] };
}
}这里重点强调两个点:
stream: true:Ollama 的 API 开关,开了之后才会 "一个字一个字" 返回,关了就是一次性返回完整回答;ReadableStream:浏览器原生 API,相当于给数据装了个 "水龙头",打开之后水(数据)一点点流出来,而不是一次性泼给你。
🚀 第二步:写后端 API(SSE 流式响应)
前端发请求总得有个接收的地方,咱们在 Next.js 里写个 API 路由src/app/api/chat/route.ts,核心是返回 SSE 格式的响应(SSE 就是服务器主动给前端推数据的标准格式)。
先唠唠 SSE 是啥:你可以把它理解成 "服务器给前端发的专属短信",格式必须是:
plaintext
data: {"type":"token","content":"你"}\n\n
data: {"type":"token","content":"好"}\n\n
data: {"type":"done","chatId":"xxx"}\n\n- 每条 "短信" 以
data:开头,\n\n结尾; - 内容是 JSON 字符串,前端能直接解析。
接下来上代码,还是白话讲解版:
typescript
import { NextResponse } from "next/server";
import { prisma } from "@/lib/prisma"; // 假设你用Prisma操作数据库
import { streamChat, ChatMessage, checkOllamaStatus } from "@/lib/ollama";
export async function POST(request: Request) {
const body = await request.json();
const { appId, message, chatId } = body;
// 1. 检查智能体是否存在(你可以理解成"检查这个对话的专属配置是否存在")
const app = await prisma.app.findUnique({ where: { id: appId } });
if (!app) {
return NextResponse.json({ error: "智能体不存在" }, { status: 404 });
}
// 2. 检查Ollama是否在运行(没运行就返回模拟数据,避免用户白等)
const ollamaStatus = await checkOllamaStatus();
if (!ollamaStatus.running) {
return handleMockResponse(appId, message, chatId); // 模拟响应函数,后面可以自己写
}
// 3. 获取对话历史(如果是续聊,要把之前的话传给模型)
let chat;
let previousMessages: ChatMessage[] = [];
if (chatId) {
chat = await prisma.chat.findUnique({
where: { id: chatId },
include: { messages: { orderBy: { createdAt: "asc" } } },
});
if (chat) {
// 把数据库里的消息转成模型能识别的格式
previousMessages = chat.messages.map((m) => ({
role: m.role as "user" | "assistant",
content: m.content,
}));
}
}
// 4. 新建对话(如果是第一次聊,没有chatId)
if (!chat) {
const title = message.slice(0, 20) + (message.length > 20 ? "..." : "");
chat = await prisma.chat.create({
data: { appId, title, tokens: 0 },
});
}
// 5. 保存用户的消息到数据库(先存下来,方便后续看历史)
await prisma.message.create({
data: { chatId: chat.id, role: "user", content: message },
});
// 6. 构建传给模型的消息数组(系统提示词+历史消息+当前消息)
const messages: ChatMessage[] = [];
if (app.prompt) {
// 系统提示词:告诉模型"你是干啥的",比如"你是一个前端开发助手,说话要通俗易懂"
messages.push({ role: "system", content: app.prompt });
}
messages.push(...previousMessages); // 历史消息
messages.push({ role: "user", content: message }); // 当前用户消息
// 7. 创建流式响应(⭐ 核心中的核心)
const encoder = new TextEncoder(); // 把字符串转成二进制(SSE要二进制格式)
const readable = new ReadableStream({
async start(controller) {
try {
await streamChat({
// 自动选择模型:如果智能体指定的模型可用就用,否则用默认的
model: ollamaStatus.models.includes(app.model || "")
? app.model || undefined
: undefined,
messages,
// 拿到每个字的回调:把字通过SSE发给前端
onToken: (token) => {
controller.enqueue(
encoder.encode(`data: ${JSON.stringify({ type: "token", content: token })}\n\n`)
);
},
// 全部完成的回调:保存AI的回答到数据库,然后告诉前端"说完了"
onComplete: async (response) => {
await prisma.message.create({
data: { chatId: chat!.id, role: "assistant", content: response },
});
// 统计token(简单估算:每个字算0.25个token)
await prisma.chat.update({
where: { id: chat!.id },
data: { tokens: { increment: Math.ceil(response.length / 4) } },
});
// 发送完成信号
controller.enqueue(
encoder.encode(`data: ${JSON.stringify({ type: "done", chatId: chat!.id })}\n\n`)
);
controller.close(); // 关闭流
},
// 出错的回调:告诉前端出错了
onError: (error) => {
controller.enqueue(
encoder.encode(`data: ${JSON.stringify({ type: "error", error: error.message })}\n\n`)
);
controller.close();
},
});
} catch {
controller.enqueue(
encoder.encode(`data: ${JSON.stringify({ type: "error", error: "流式处理失败" })}\n\n`)
);
controller.close();
}
},
});
// 8. 返回SSE响应(关键Headers不能少!)
return new NextResponse(readable, {
headers: {
"Content-Type": "text/event-stream", // ⭐ 告诉浏览器:这是SSE格式
"Cache-Control": "no-cache, no-transform", // 禁用缓存,要实时数据
"Connection": "keep-alive", // 保持连接,别断
"X-Accel-Buffering": "no", // 禁用nginx缓冲(部署到服务器要加这个,否则会卡顿)
},
});
}
// 模拟响应函数(Ollama没运行时用)
async function handleMockResponse(appId: string, message: string, chatId: string | undefined) {
// 逻辑和上面类似,只是返回固定的模拟数据
const encoder = new TextEncoder();
const readable = new ReadableStream({
async start(controller) {
const mockResponse = "抱歉,本地模型服务暂时未启动,这是模拟回复~";
// 模拟打字效果,每隔50ms发一个字
for (let i = 0; i < mockResponse.length; i++) {
await new Promise(resolve => setTimeout(resolve, 50));
controller.enqueue(
encoder.encode(`data: ${JSON.stringify({ type: "token", content: mockResponse[i] })}\n\n`)
);
}
// 发送完成信号
let chatIdToUse = chatId;
if (!chatIdToUse) {
const chat = await prisma.chat.create({
data: { appId, title: message.slice(0, 20), tokens: 0 },
});
chatIdToUse = chat.id;
}
controller.enqueue(
encoder.encode(`data: ${JSON.stringify({ type: "done", chatId: chatIdToUse })}\n\n`)
);
controller.close();
},
});
return new NextResponse(readable, {
headers: {
"Content-Type": "text/event-stream",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
},
});
}这里重点说一下 Headers:
Content-Type: text/event-stream:浏览器看到这个头,就知道要按 SSE 格式处理,会一直保持连接,等服务器推数据;X-Accel-Buffering: no:如果你部署到用 nginx 的服务器(比如 Vercel、阿里云),不加这个会导致数据被缓冲,打字效果变成 "一次性蹦出来",巨影响体验!
🎨 第三步:前端接收流式数据(实现打字效果)
后端搞定了,前端要做的就是:发请求→接数据→实时更新页面。咱们以src/app/(main)/chats/new/page.tsx为例,写核心逻辑:
3.1 核心函数:发送消息并接收流式响应
typescript
import { useState } from "react";
import { message as antMessage } from "antd"; // 假设你用AntD的提示组件
// 定义消息类型
interface Message {
id: string;
role: "user" | "assistant";
content: string;
createdAt: string;
isStreaming?: boolean; // 是否正在流式输出
}
export default function ChatPage() {
const [messages, setMessages] = useState<Message[]>([]);
const [sendingMessage, setSendingMessage] = useState(false);
const [currentChatId, setCurrentChatId] = useState<string | null>(null);
const [selectedAppId, setSelectedAppId] = useState<string | null>(null);
// 流式发送消息的核心函数
const handleSendMessage = async (content: string) => {
if (!selectedAppId) {
antMessage.warning("请先选一个智能体~");
return;
}
if (!content.trim()) {
antMessage.warning("消息不能为空哦~");
return;
}
// 1. 乐观更新:先把用户消息显示到页面(不用等服务器响应,体验更好)
const userMessage: Message = {
id: `user-${Date.now()}`,
role: "user",
content,
createdAt: new Date().toISOString(),
};
setMessages((prev) => [...prev, userMessage]);
// 2. 先加一个空的AI消息(等着流式填充内容)
const aiMessageId = `ai-${Date.now()}`;
const aiMessage: Message = {
id: aiMessageId,
role: "assistant",
content: "", // 初始为空
createdAt: new Date().toISOString(),
isStreaming: true, // 标记正在打字
};
setMessages((prev) => [...prev, aiMessage]);
setSendingMessage(true);
try {
// 3. 发请求到后端API
const response = await fetch("/api/chat", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
appId: selectedAppId,
message: content,
chatId: currentChatId,
}),
});
if (!response.ok) throw new Error("请求失败,可能是服务器开小差了~");
// 4. 获取流读取器(和后端的reader对应)
const reader = response.body?.getReader();
if (!reader) throw new Error("拿不到响应流,没法显示打字效果~");
const decoder = new TextDecoder(); // 把二进制转字符串
// 5. 循环读取每个字
while (true) {
const { done, value } = await reader.read();
if (done) break;
// 6. 解码并解析SSE数据
const chunk = decoder.decode(value, { stream: true });
// 只处理以data:开头的行(SSE标准格式)
const lines = chunk.split("\n").filter((line) => line.startsWith("data: "));
for (const line of lines) {
try {
// 去掉data: 前缀,解析JSON
const data = JSON.parse(line.replace("data: ", ""));
if (data.type === "token") {
// 7. 实时更新AI消息内容(核心:找到对应的AI消息,追加字)
setMessages((prev) =>
prev.map((msg) =>
msg.id === aiMessageId
? { ...msg, content: msg.content + data.content }
: msg
)
);
} else if (data.type === "done") {
// 8. 流式完成:去掉打字光标
setCurrentChatId(data.chatId);
setMessages((prev) =>
prev.map((msg) =>
msg.id === aiMessageId ? { ...msg, isStreaming: false } : msg
)
);
} else if (data.type === "error") {
// 9. 出错处理:提示用户,删掉空的AI消息
antMessage.error(data.error);
setMessages((prev) => prev.filter((msg) => msg.id !== aiMessageId));
}
} catch (e) {
// 忽略解析错误(偶尔有脏数据,不影响)
}
}
}
} catch (err) {
antMessage.error(err instanceof Error ? err.message : "发送失败啦~");
setMessages((prev) => prev.filter((msg) => msg.id !== aiMessageId));
} finally {
setSendingMessage(false);
}
};
// 页面渲染逻辑(省略,重点是消息列表)
return (
<div>
{/* 消息列表 */}
<div className="message-list">
{messages.map((msg) => (
<div key={msg.id} className={`message ${msg.role}`}>
<p style={{ whiteSpace: "pre-wrap" }}>
{msg.content}
{/* 打字光标:isStreaming为true时显示 */}
{msg.isStreaming && <span className="typing-cursor">▊</span>}
</p>
</div>
))}
</div>
{/* 输入框 */}
<div className="input-area">
<input
type="text"
placeholder="输入消息按回车发送..."
onKeyDown={(e) => {
if (e.key === "Enter" && !sendingMessage) {
handleSendMessage(e.target.value);
e.target.value = "";
}
}}
disabled={sendingMessage}
/>
</div>
</div>
);
}3.2 打字光标动画(CSS 加持)
光有文字还不够,得加个闪烁的光标,才像真的在打字!在src/app/globals.css里加这段 CSS:
css
/* 打字光标样式 */
.typing-cursor {
display: inline-block;
color: #00ffaa; /* 科技感的绿色 */
font-weight: bold;
animation: cursor-blink 0.8s infinite; /* 闪烁动画 */
margin-left: 2px;
}
/* 闪烁动画:0-50%显示,51-100%隐藏 */
@keyframes cursor-blink {
0%, 50% {
opacity: 1;
}
51%, 100% {
opacity: 0;
}
}
/* 日间模式适配(可选) */
.light-mode .typing-cursor {
color: #1890ff; /* 蓝色,适配浅色背景 */
}
/* 消息列表样式(可选,美化一下) */
.message-list {
max-width: 800px;
margin: 0 auto;
padding: 20px;
}
.message {
margin: 10px 0;
padding: 10px 15px;
border-radius: 8px;
max-width: 70%;
}
.message.user {
background-color: #e6f7ff;
margin-left: auto;
}
.message.assistant {
background-color: #f5f5f5;
margin-right: auto;
}这里的动画逻辑超简单:光标 0.8 秒闪一次,50% 的时间显示,50% 的时间隐藏,和真实的打字光标几乎一样~
🧠 第四步:进阶优化(让你的应用更丝滑)
咱们做的东西能跑了,但还可以更完善,分享几个实用的优化点:
4.1 模型自动选择
用户可能在配置里选了一个不存在的模型(比如选了 gpt-4,但本地只有 qwen2.5:7b),这时候要自动降级到默认模型:
typescript
// 先获取Ollama的可用模型列表
const ollamaStatus = await checkOllamaStatus();
// 检查配置的模型是否在可用列表里,不在就用默认的
const modelToUse = ollamaStatus.models.includes(app.model || "")
? app.model
: undefined;4.2 取消请求(用户不想等了)
加个 "停止生成" 按钮,让用户可以中断流式响应:
typescript
// 定义一个AbortController
const abortController = new AbortController();
// 发请求时传入signal
const response = await fetch("/api/chat", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ appId, message, chatId }),
signal: abortController.signal, // 关联控制器
});
// 停止生成的函数
const handleStopGeneration = () => {
abortController.abort(); // 中断请求
setMessages((prev) =>
prev.map((msg) => (msg.isStreaming ? { ...msg, isStreaming: false } : msg))
);
};
// 页面上加个按钮
<button onClick={handleStopGeneration} disabled={!sendingMessage}>
停止生成
</button>4.3 预热模型(首次调用不卡顿)
Ollama 首次调用模型会加载到内存,有点慢,咱们可以在项目启动时预热:
bash
# 终端执行,给模型发个空请求
ollama run qwen2.5:7b "hello"或者在代码里加个预热接口,项目启动时调用一次:
typescript
// 预热函数
export async function warmupOllama() {
const ollamaStatus = await checkOllamaStatus();
if (ollamaStatus.running) {
await fetch(`${OLLAMA_BASE_URL}/api/chat`, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
model: DEFAULT_MODEL,
messages: [{ role: "user", content: "hello" }],
stream: false,
}),
});
}
}📝 数据库设计(简单易懂版)
最后提一下数据库设计,用 Prisma 举例,核心就三张表,关系很简单:
prisma
// 智能体表(每个智能体有自己的提示词和模型配置)
model App {
id String @id @default(uuid())
name String // 智能体名称,比如"前端助手"
description String? // 描述
prompt String? // 系统提示词,比如"你是一个前端开发专家"
model String? // 指定的模型,比如"qwen2.5:7b"
chats Chat[] // 关联的对话
}
// 对话表(一次聊天就是一个Chat)
model Chat {
id String @id @default(uuid())
appId String // 关联的智能体ID
title String // 对话标题(用第一条消息生成)
tokens Int @default(0) // 统计token数
messages Message[] // 关联的消息
}
// 消息表(每句话都是一个Message)
model Message {
id String @id @default(uuid())
chatId String // 关联的对话ID
role String // 角色:user/assistant
content String // 消息内容
createdAt DateTime @default(now()) // 创建时间
}🎯 总结 & 扩展方向
咱们今天从头到尾实现了 "Next.js + Ollama" 的流式对话,核心技术点就这几个:
- SSE:服务器推数据给前端的标准格式;
- ReadableStream:处理流式数据的原生 API;
- 乐观更新:提升用户体验的小技巧;
- Ollama 封装:本地大模型的调用逻辑。
如果想继续扩展,可以试试:
- 接入 OpenAI/DeepSeek 等云端模型(只需要改封装层,前端不用动);
- 支持图片输入(多模态模型,比如 qwen-vl);
- 加对话分支、历史收藏功能;
- 部署到服务器(注意配置 nginx 的 X-Accel-Buffering)。
整个过程下来,你会发现 "流式对话" 其实一点都不神秘,核心就是 "把数据拆成一个个字,一点点传"。希望这篇文章能帮到你,动手试试吧,有问题欢迎评论区交流~