几个关键参数:chunkSize、overlap
在动手切之前,有两个参数你必须搞清楚:chunkSize(块大小)和 overlap(重叠量)。
chunkSize 就是每个块的长度上限。
overlap(重叠)是指相邻两个块之间共享的文本长度。
固定大小分块(Fixed Size Chunking)
1.1 原理
这是最简单粗暴的方式:不管文本内容是什么,每隔固定数量的字符就切一刀。
假设 chunkSize = 100,overlap = 0,上面那段示例文本会被这样切:
- 块 1:从第 1 个字符开始,取 100 个字符
- 块 2:从第 101 个字符开始,再取 100 个字符
- 块 3:从第 201 个字符开始,再取 100 个字符
- ......依此类推
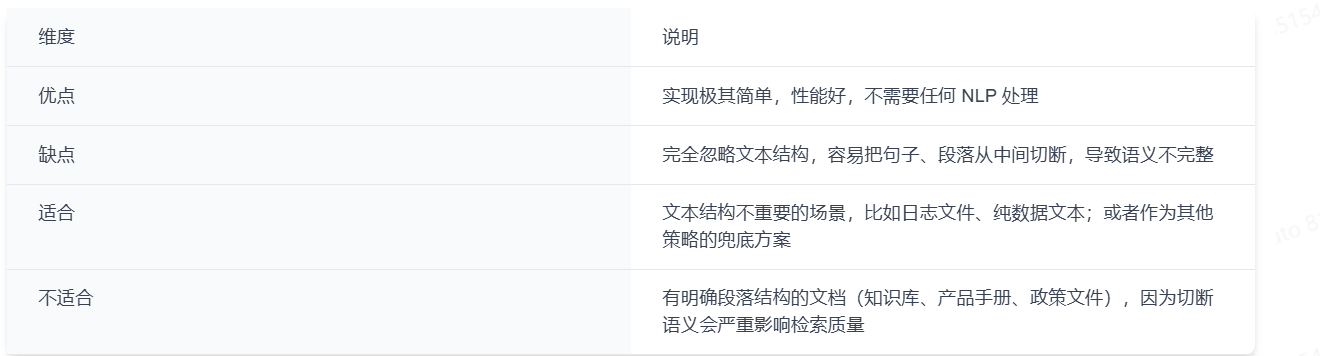
优缺点:
重叠分块(Overlapping Chunking)
2.1 原理
重叠分块是对固定大小分块的直接改进。核心思路很简单:切块的时候,相邻两个块之间留一段重叠区域,这样即使切割点落在句子中间,重叠部分也能保证关键信息不会被完全切断。
还是用退货政策那段文本,chunkSize = 100,overlap = 25:
- 块 1:从第 1 个字符开始,取 100 个字符
- 块 2:从第 75 个字符开始(100-25=75),取 100 个字符
- 块 3:从第 150 个字符开始,取 100 个字符
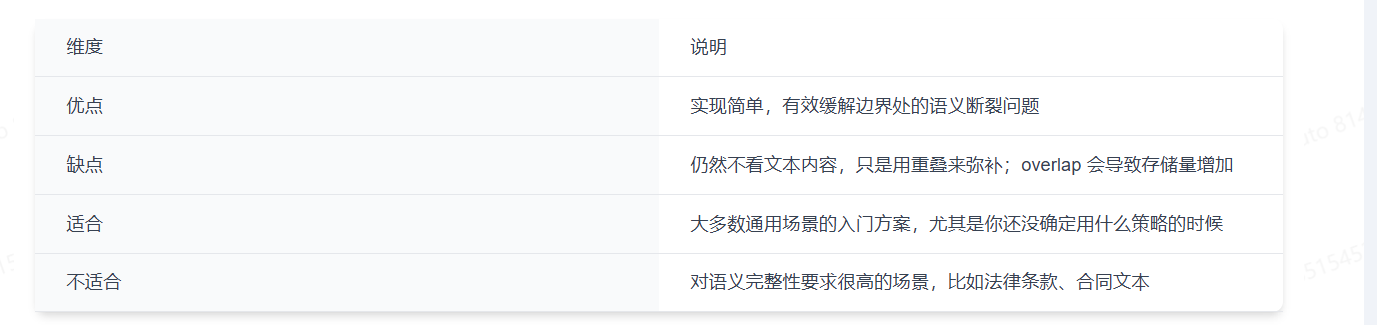
2.3 优缺点
递归分块(Recursive Chunking)
3.1 原理
递归分块是目前实践中最常用的策略。它的思路可以用一句话概括:先尝试用最大的分隔符切,切完如果某个块还是太大,就换一个更小的分隔符继续切,直到所有块都在 chunkSize 以内。
具体来说,它维护一个分隔符列表,按优先级从高到低排列,比如:
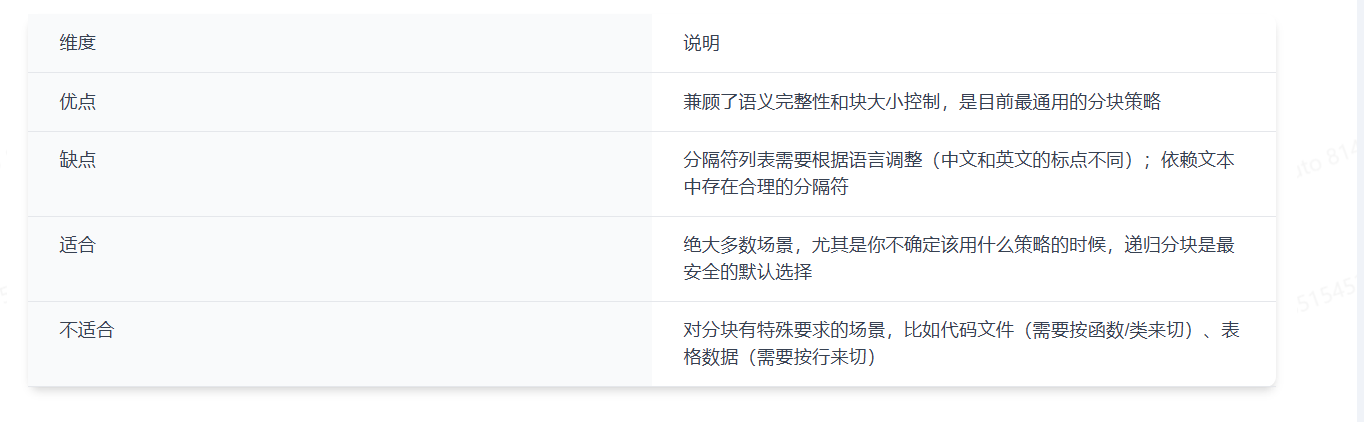
["\n\n", "\n", "。", ",", " ", ""]3.2 优缺点
语义分块(Semantic Chunking)
4.1 原理
前面三种策略有一个共同的局限:它们都是基于规则的------要么按字数切,要么按标点符号切。它们不理解文本在说什么。
语义分块换了一个完全不同的思路:用 Embedding 模型来判断文本的语义相似度,在语义发生明显变化的地方切割。
具体过程是这样的:
- 先把文本按句子拆开(这一步可以简单地按句号切)
- 对每个句子生成一个向量(Embedding)
- 计算相邻句子之间的向量相似度
- 当相邻句子的相似度低于某个阈值时,说明话题发生了转换,在这里切一刀
对比 Embedding vs LLM 分块:

4.2 优缺点

混合分块(Hybrid Chunking)
5.1 原理
实际项目中,单一的分块策略往往不够用。不同类型的文档、甚至同一份文档的不同部分,可能适合不同的分块方式。混合分块的思路就是:把多种策略组合起来用,取长补短。
常见的组合方式有几种:
- 第一种,递归分块 + 语义分块。先用递归分块做粗切,把文本按段落、章节切成大块;然后对每个大块再用语义分块做细切,确保每个最终的块在语义上是内聚的。
- 第二种,按文档类型选策略。比如在一个企业知识库系统中,产品手册用递归分块,FAQ 用按问答对切割,合同文本用语义分块。在代码层面,就是一个路由逻辑,根据文档的类型或来源选择不同的分块器。
- 第三种,分块 + 后处理。先用递归分块切完,然后对结果做一轮后处理:合并太短的块、拆分太长的块、给每个块补充元数据(比如所属章节标题、文档来源)。
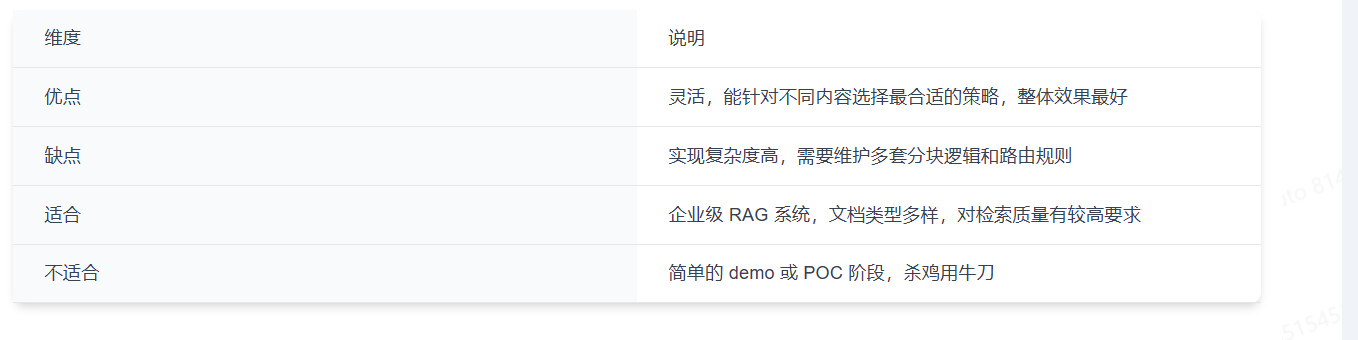
5.2 优缺点
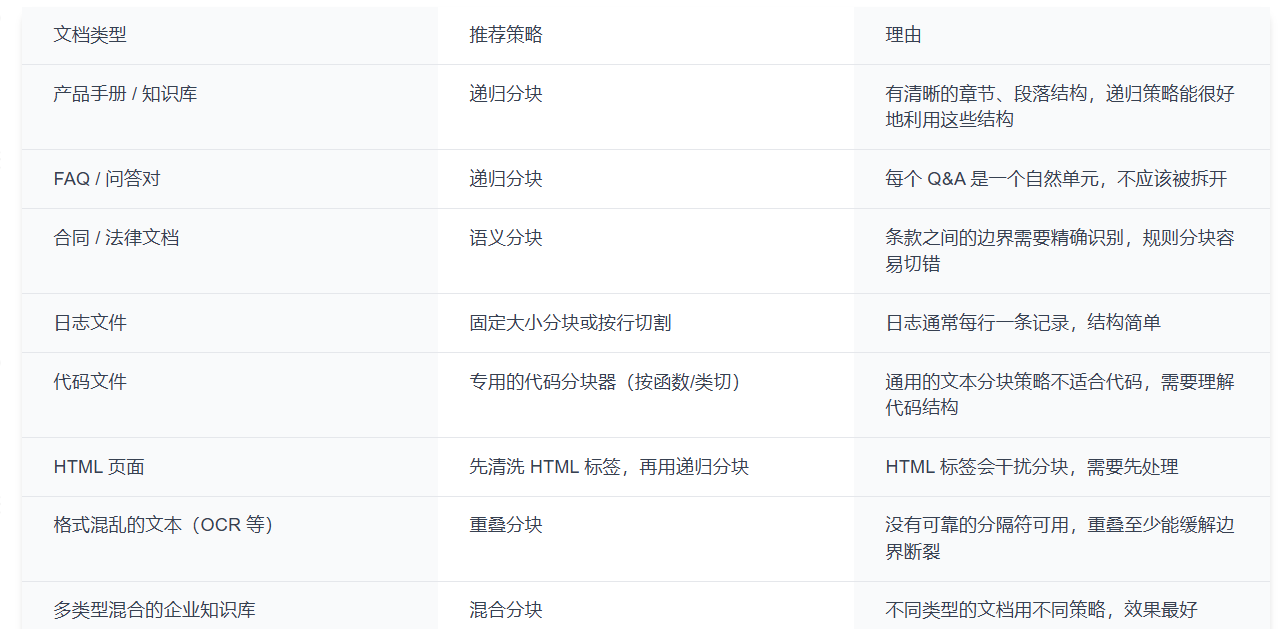
分块策略怎么选:一张表帮你决定
不同文档类型的推荐策略
先用Tika等工具做文本抽取→再用清洗器做结构修复与去噪→最后才进入分块与向量化
文末总结
分块是 RAG 数据准备阶段的关键一步。拿到 Tika 提取的纯文本后,不能直接用,需要切成大小合适、语义完整的小段,才能在后续的检索环节中被精准匹配到。
五种分块策略各有定位:固定大小分块最简单但最粗暴;重叠分块用重叠区域缓解边界断裂;递归分块逐层细化,是大多数场景的默认选择;语义分块基于 Embedding 做语义级切割,精度最高但成本也最高;混合分块组合多种策略,适合企业级复杂场景。
chunkSize 和 overlap 这两个参数没有最优值,需要根据你的文档类型和检索场景来调。记住起步参考值:chunkSize=500、overlap=50,然后根据实际效果微调。
分块之后,每个文本块还只是一段人类能读懂的文字。计算机要做相似度检索,需要把这些文字转成它能理解的数字表示------这就是向量化(Embedding)