claude code
claude code 为什么严谨?
之前我一直以为 claude code 就是它的模型牛逼。后来仔细研究了一下才发现Claude Code 的强大,是模型能力 + 工具框架的组合结果:
大模型本身:30%~40%
框架 / 工程控制(Prompt、流程、校验、工具链):60%~70%
模型决定 "上限",但框架决定 "下限与稳定性";工业级严谨性,大头靠框架。
而claude code 的 底层框架就是 Harness
LangGraph
聊 Harness 之前需要聊一下 LangGraph :状态化智能体编排引擎
对比一下
langchain
链式流程(线性、单向),无状态,除了问题重新来一遍,一般适合简单场景
LangGraph
有状态可控制执行流程,提供底层调度能力,就像流程图一样有节点,有流转状态,还能断点续跑,人工干预,复杂智能体、多轮自我反思、多 Agent 协作
一般用在复杂的场景
Harness
Harness ≈ 定制版 LangGraph
| 维度 | LangGraph(开源框架) | Claude Code Harness(自研运行时) |
|---|---|---|
| 定位 | 通用图编排引擎 | 产品化 Agent 安全运行容器 |
| 开源 | ✅ 开源(Python/JS) | ❌ 闭源(Claude Code 内部) |
| 控制模式 | 显式:节点 / 边 / 状态全自定义 | 隐式:流程固化、规则配置化 |
| 安全权限 | 无内置,需自己实现 | 内置 7 种权限、风险拦截、白名单 |
| 上下文管理 | 基础持久化,需自己做压缩 | 自动分层注入、智能压缩、窗口控制 |
| 工具管理 | 灵活注册,无统一规范 | 统一注册表、依赖管理、错误隔离 |
| 适用场景 | 自定义复杂 Agent、多智能体、研究 | 生产级编码 Agent、企业安全合规场景 |
| 上手成本 | 中等(需懂状态图) | 极低(开箱即用,无需关心底层) |
举个例子
帮我重构整个项目:
批量扫描全部源码,找出所有过期接口
修改完成后,自动运行单元测试
测试报错就自动回溯代码、局部回滚、重试修改
代码量超大,上下文溢出要自动压缩
禁止删除系统文件、禁止执行高危 Shell 命令
如果用 LangGraph 实现
需要自己设计 State
要存:文件列表、修改记录、测试结果、回滚快照、错误日志、上下文缓存。
手动拆分 N 个节点
手动写复杂分支 & 循环
安全要自己造轮子
上下文溢出自己处理
事务 & 容错自己做
流程图
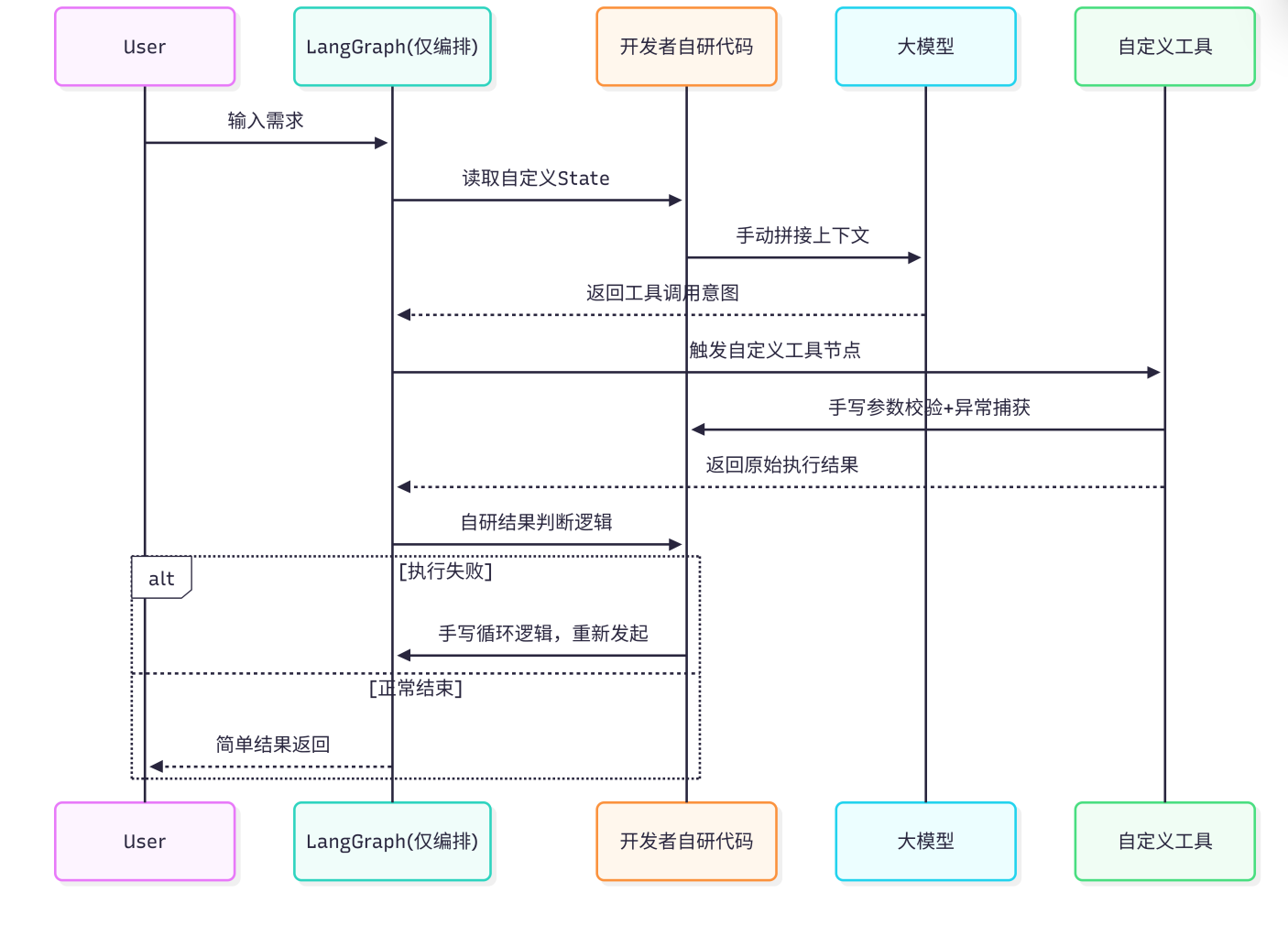
Harness 实现
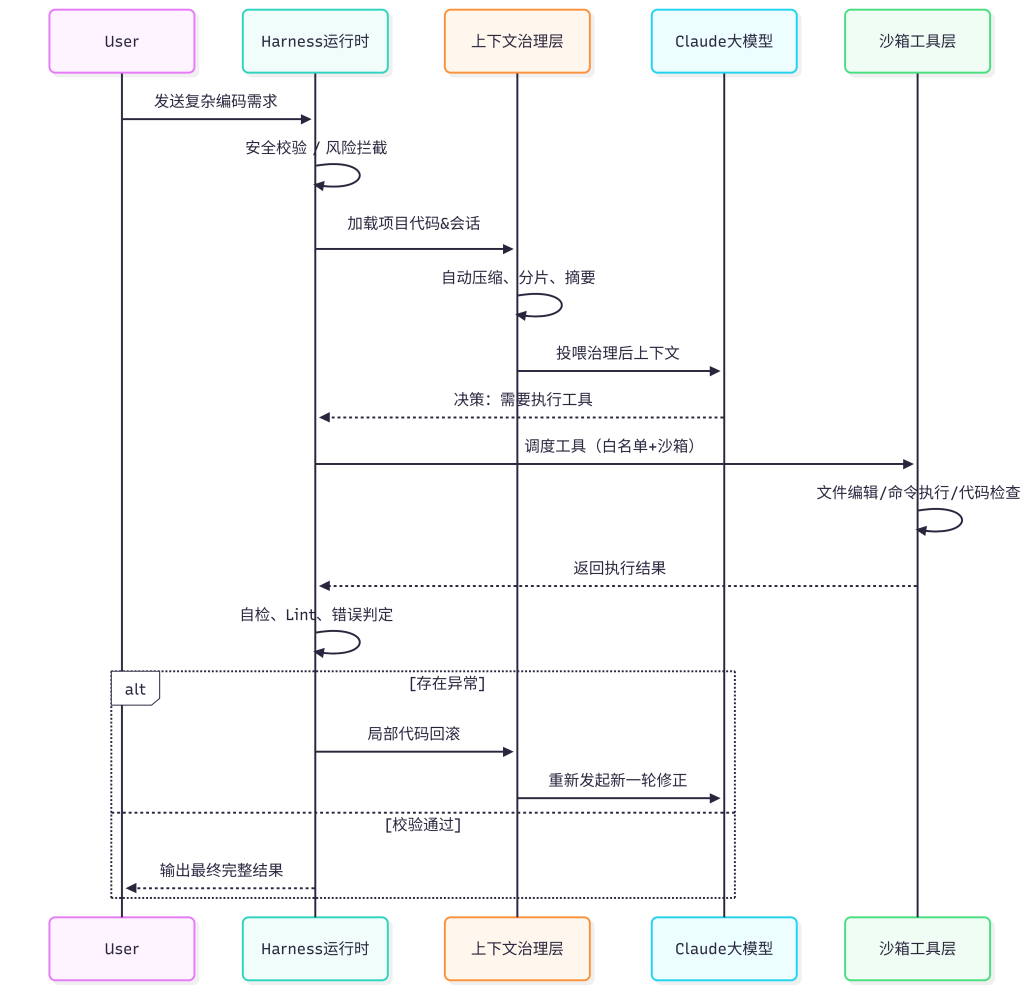
你只需要复制粘贴上面需求,直接回车,全程全自动
因为
1.Harness 内置安全管控,而且自己有沙箱安全代码,天然防越权、防误删
2.原生大上下文治理
整个项目几千行代码一次性喂给模型,
Harness 自动做分层摘要、局部压缩、动态窗口裁剪,
不会爆上下文、不会丢关键代码、不会乱截断。
3.原生复杂事务 + 回溯循环
运行测试报错后,
Harness 内置 Agent 循环引擎自动触发:
自动识别错误代码 → 局部文件快照回滚 → 针对性二次修复 → 重新校验。
4.标准化大型工具编排
多文件批量编辑、批量读取、终端混合调用、多工具串行 / 并行调度,
Harness 内部有成熟工具调度池、调用限流、错误隔离,
不会因为批量操作导致文件锁冲突、命令卡死。
5.长任务稳运行
十几分钟的大型重构任务,支持中途暂停、继续、会话持久化,底层运行时容错、异常捕获、进程隔离,不会崩、不会断连
流程图
总结
LangGraph 是 "技术原型",Harness 是 "工业成品"