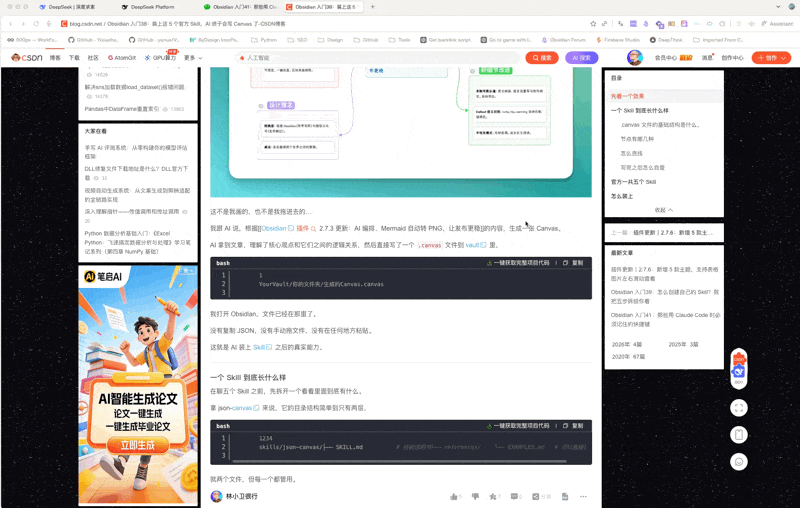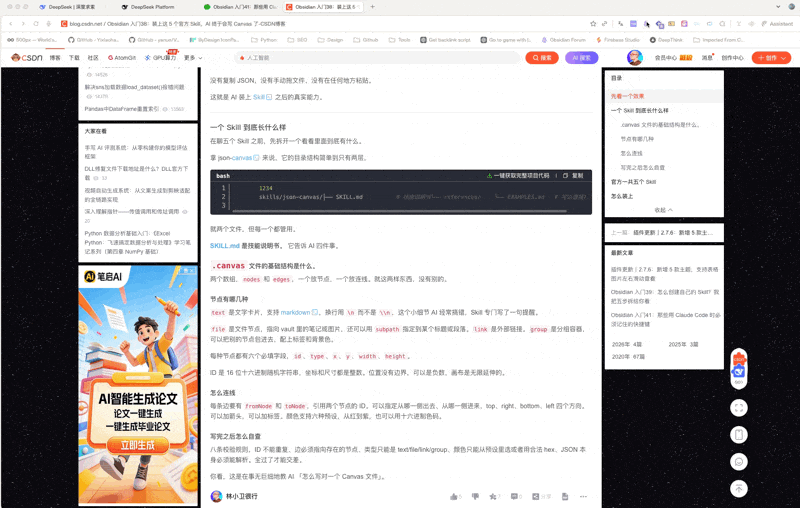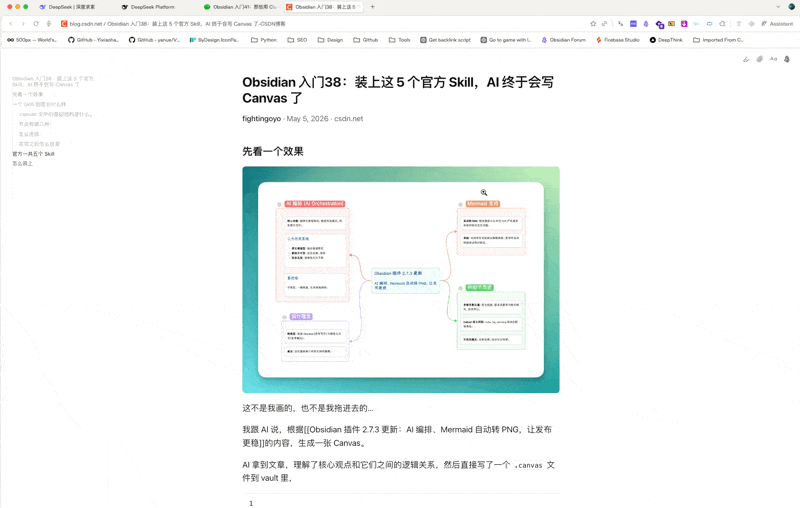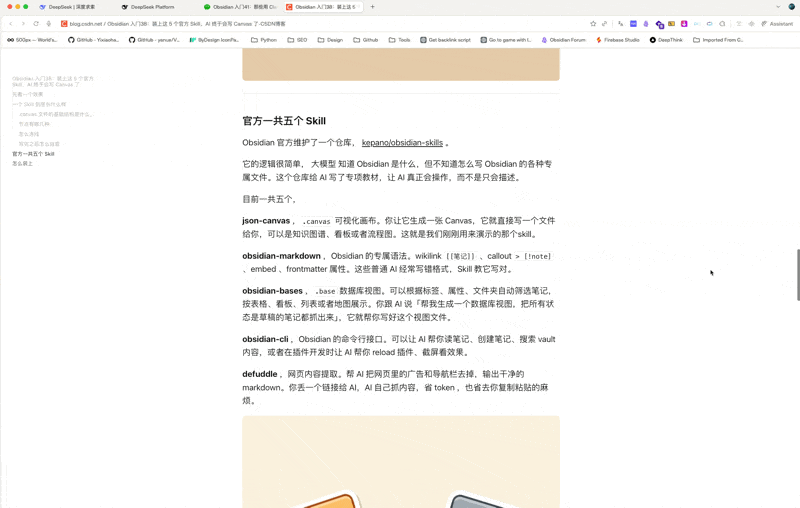
这是一个「Obsidian × AI」系列
如果你还没看过前几篇,可以先看 \[Obsidian 入门41:那些用 Claude Code 时必须记住的快捷键]。
这个系列走到现在,Obsidian 怎么装、怎么用、怎么接 AI,前面都聊过了。
但有一个问题一直没解决:你的笔记从哪来?
光靠自己一个字一个字敲,效率太低。我们每天刷到的文章、公众号、视频,里面有很多值得留下的东西,但大多数都躺在收藏夹里吃灰。
先从最基础的开始:网页剪藏。
你收藏夹里有多少文章,是「收藏即读完」的?
我猜不少。
以前我用过印象笔记,也用过有道云笔记,它们都有自己的浏览器剪藏插件。当时觉得挺好用,看到好文章点一下就存了。但后来我换到了 Obsidian,那些收藏的内容就尴尬了:要么导出格式对不上,要么干脆没法迁移。
笔记工具换了,剪藏工具也得跟着换。
直到我发现了 Obsidian 官方的浏览器扩展 Web Clipper 将网页文章剪藏成 Markdown 格式的文本,才觉得:这次终于不用再迁了。
以后无论再怎么搬平台, Markdown 总会是能支持的通用格式。
不过长期来看,我肯定是会坚守 Obsidian的。
它不是社区插件,是官方出品
Web Clipper是 Obsidian 官方产品线里的其中一个,跟Obsidian sync同样级别的产品。代码在 GitHub 上开源,MIT 协议,你可以随时去看。
支持的浏览器也比想象中多:
- Chrome(以及 Brave、Arc 这些 Chromium 内核的浏览器)
- Firefox
- Safari
- Edge
手机上也能用,这一点挺意外的。Safari(包括 iPhone 和 iPad)需要从 App Store 单独安装,搜「Obsidian Web Clipper」就行。
安装很简单,去对应的浏览器应用商店搜「Obsidian Web Clipper」,点安装,完事。
比方说Chrome浏览器,直接去浏览器插件商店,搜索就能看到下面的结果,安装即可。
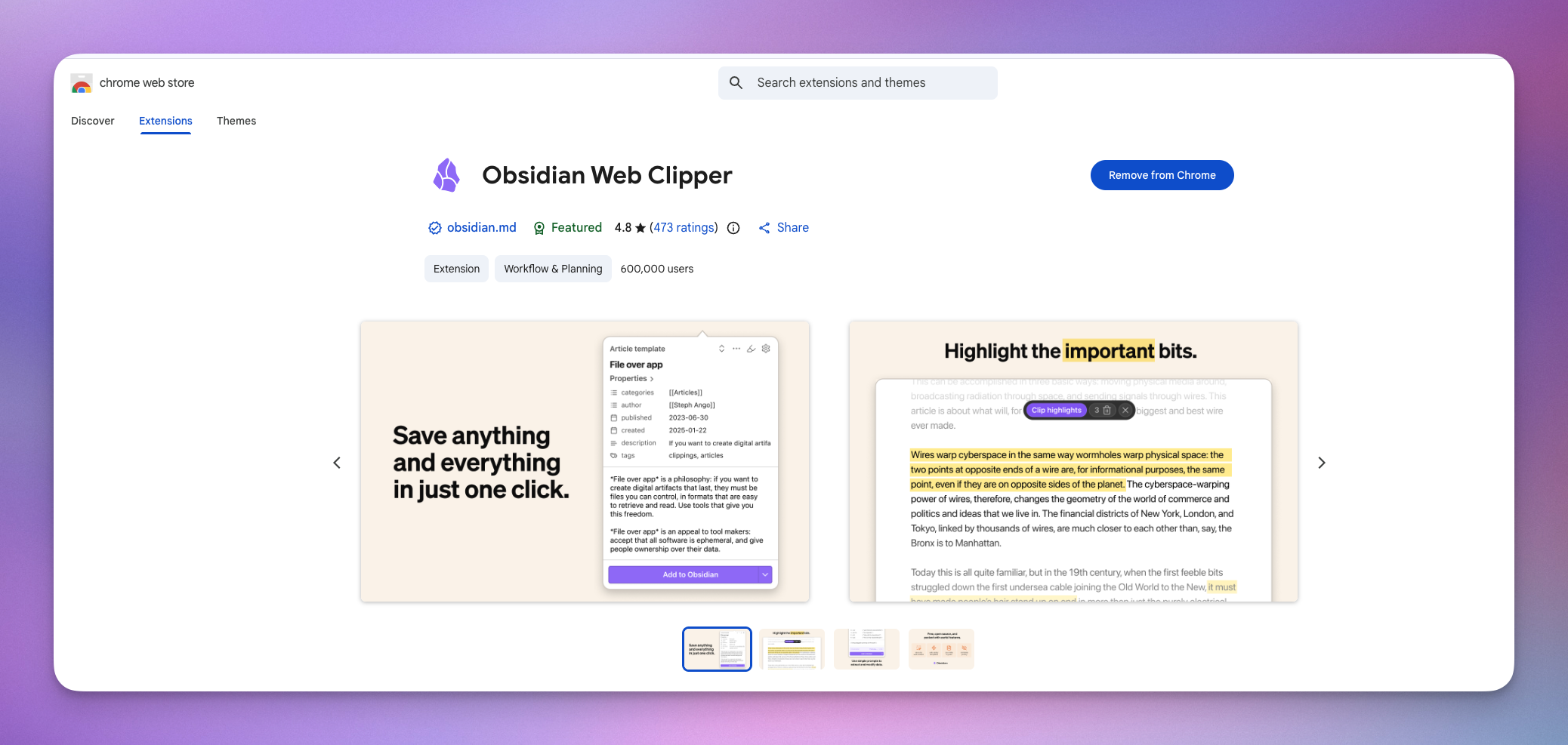
不过 Chrome 插件商店需要特殊网络才能访问,访问有困难的朋友,可以私聊。
剪藏功能本身:它到底能做什么?
装好之后,在任何网页上点一下浏览器工具栏里的 Obsidian 图标,就会弹出一个剪藏面板。
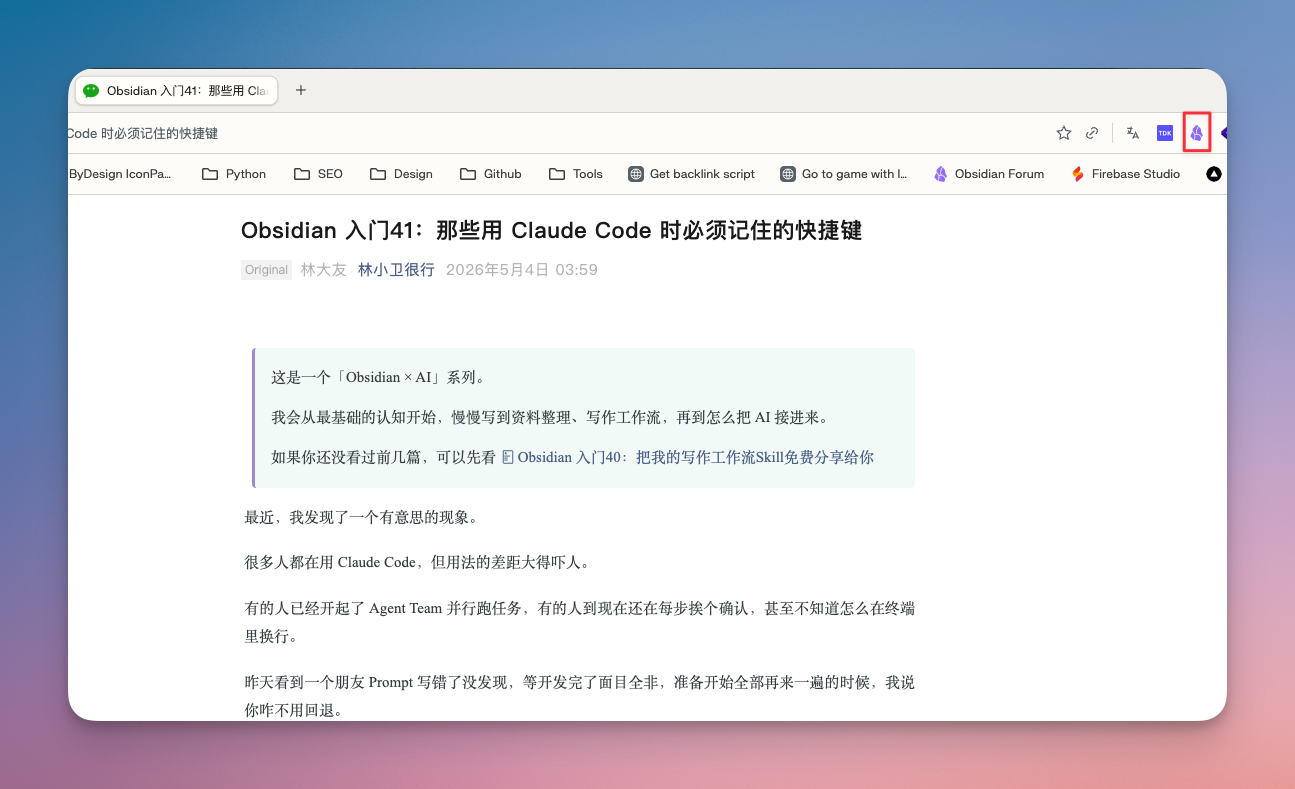
面板分四个区域:
- 顶部:模板切换、高亮模式(可在网页上将需要的文字划为高亮)、Reader 阅读模式(可将网页上的无关元素如广告过滤掉,仅展示正文)的按钮
- 中间上:自动提取的属性(标题、作者、来源链接等)。如果不满意现有的属性,可以在模板中自行修改
- 中间下:自动提取的正文内容
- 底部:Vault 选择、文件夹指定、「Add to Obsidian」保存按钮。
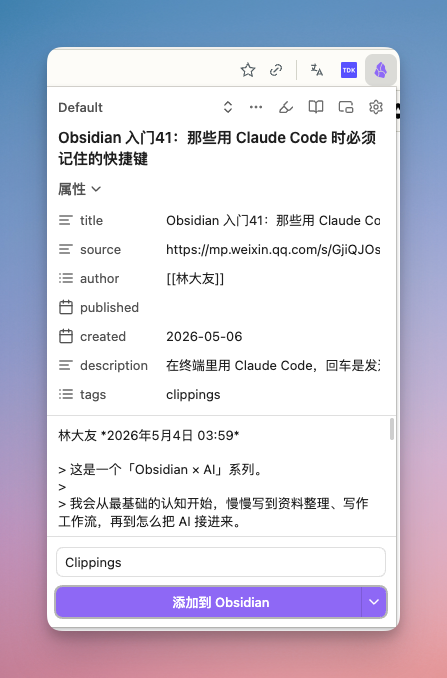
第一次用的时候,默认会保存到当前的 Vault 库中。如果你有多个库,可以在插件设置的 - 常规设置- 保管库中添加你的多个库。添加后,即可在剪藏时选择添加到哪个库中。旁边有个文件夹输入框,可以指定保存位置。
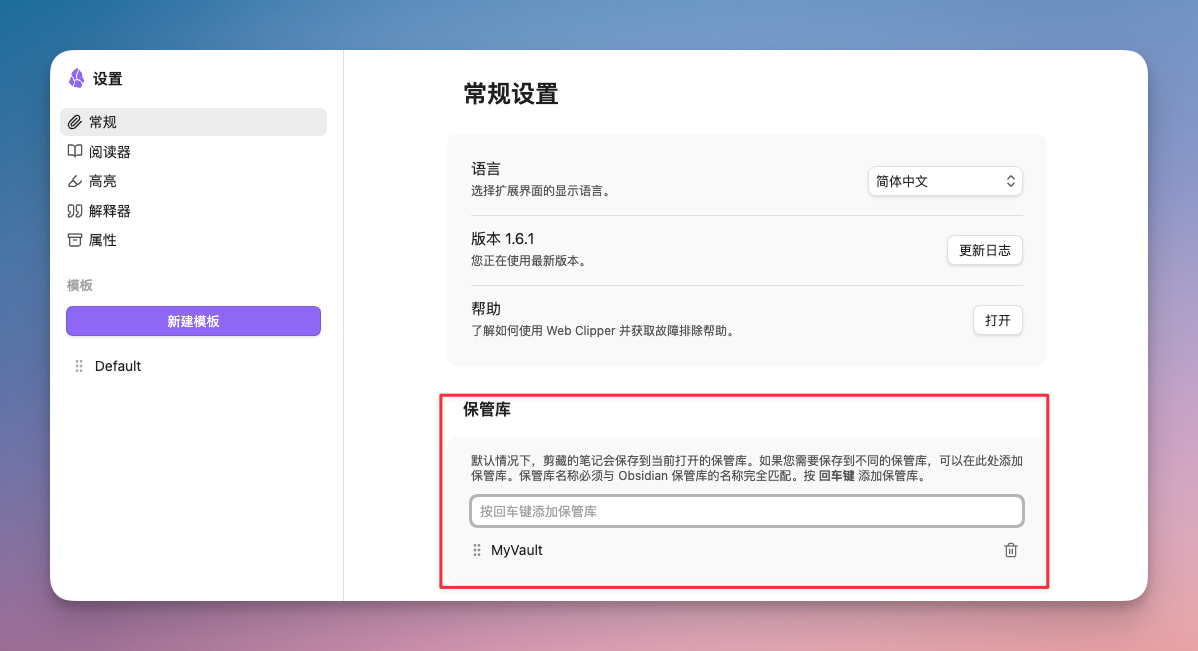
一切都设置好后,点「Add to Obsidian」,文章就存进去了。你也可以什么都不设置,先体验默认模板和设置。
就这么简单。
剪藏的三种模式
整页保存
自动提取网页的正文内容,去掉广告、导航栏这些噪音,转成干干净净的 Markdown。用的是一个叫 defuddle 的库,解析能力相当强。
可以对比一下下图:左侧是我从浏览器网页剪藏下来的我的文章,右侧是原本我的Obsidian里面的文章。几乎没有太大差异。
选中文字
你先用鼠标选中一段话,再点 Web Clipper,它就只保存你选中的部分。适合那种「一篇文章里只有一段对我有用」的场景。
高亮标注
这个是我最喜欢的。你可以在网页上直接标黄某些段落,高亮的内容会保存到笔记里。更妙的是,下次你再打开这个网页,高亮还在。
公众号文章也能剪藏
这是我试了很多工具都没解决的问题。以前想收藏一篇公众号文章,要么转发到文件传输助手吃灰,要么截图存相册更找不到。
现在把它的链接在浏览器里打开,点一下 Web Clipper,整篇文章就变成 Markdown 躺在你的 Obsidian 里了。标题、作者、发布时间、正文,一个都不少。
ℹ️ 提醒一下
如果你想剪藏微信公众号文章,因为图片是动态加载的,所以最好拉到页面底部让所有图片都加载出来,再点击浏览器剪藏插件。如此才能将文章内容和图片完整的剪藏到 Obsidian。
如果是其他动态渲染的网页,也是同样的道理。
阅读模式
Web clipper 还有一个 Reader 模式,点一下就能把网页变成干净的阅读视图,没有弹窗、没有侧边栏,就是纯文字。
快捷键 :macOS 用 Cmd+Shift+O 打开剪藏面板,Windows 用 Ctrl+Shift+O。记住这个,比点图标快。
模板:让剪藏自动「归档」
光会保存还不够。如果每次剪藏的内容都随便丢进一个文件夹,时间一长又变成了另一个收藏夹。
Web Clipper 有一个模板系统,能让你的剪藏自动带上结构化的信息。
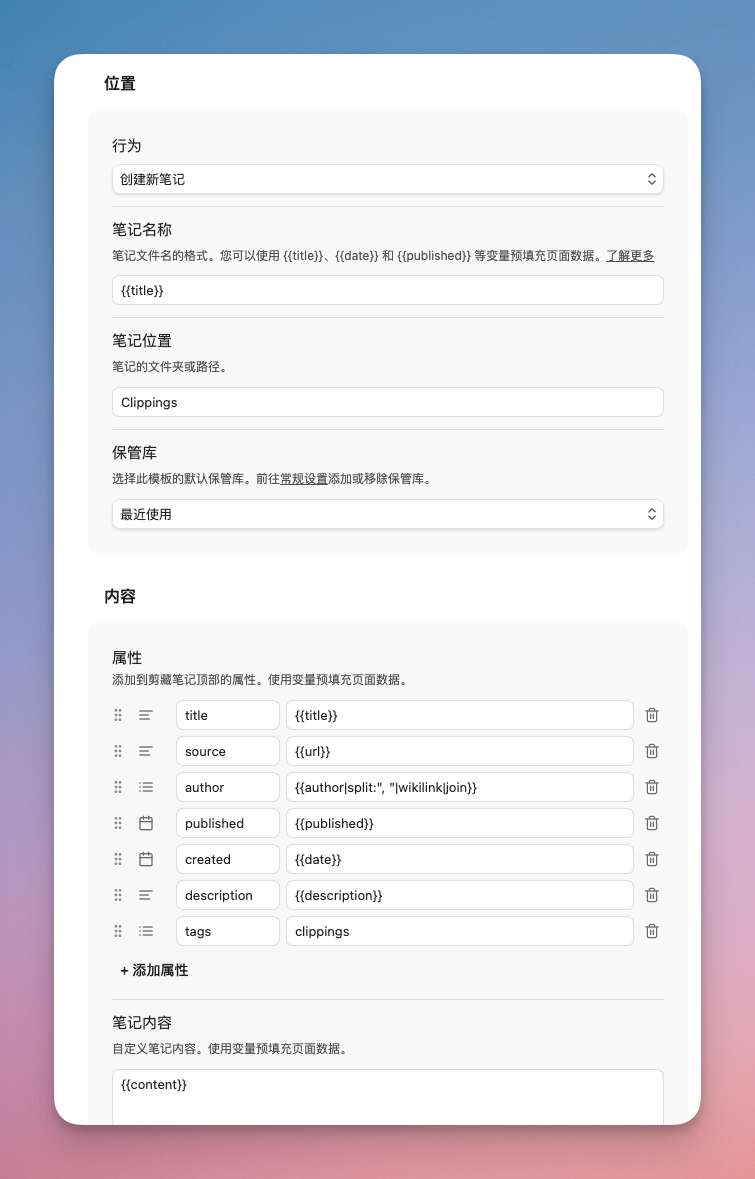
怎么设置模板
- 点击剪藏面板右上角的齿轮图标,进入设置
- 左侧边栏点「New template」创建新模板(默认已经有一个 Ddefault 模板)
- 模板编辑区有几个关键字段:
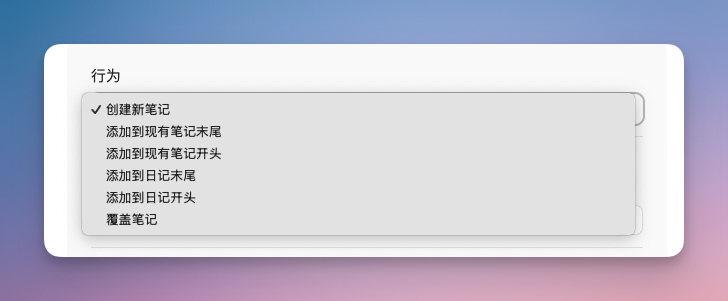
-
行为:选「创建新笔记」,也可以选「追加到其他笔记」。根据自己的需要选择
-
笔记名称 :填
{``{title}},用文章标题做文件名 -
笔记位置 :填你想存到的文件夹,我设的是
Clippings -
属性:在这里定义自动提取的属性。不懂每个是什么意思的话,可以问 AI。也可以选择更改属性,这些会跟随剪藏的内容存储到笔记的frontmatter中作为笔记属性
-
笔记内容:正文内容的模板。保持默认即可
-
打开默认的模板,你会看到它已经帮你配好了属性:标题、来源链接、作者、发布时间、描述、标签。这些信息它自己从网页里扒,你什么都不用管。
我第一次用的时候还挺惊讶的:连作者名字和发布时间都能准确提取出来,不是随便抓一段文字糊弄你。
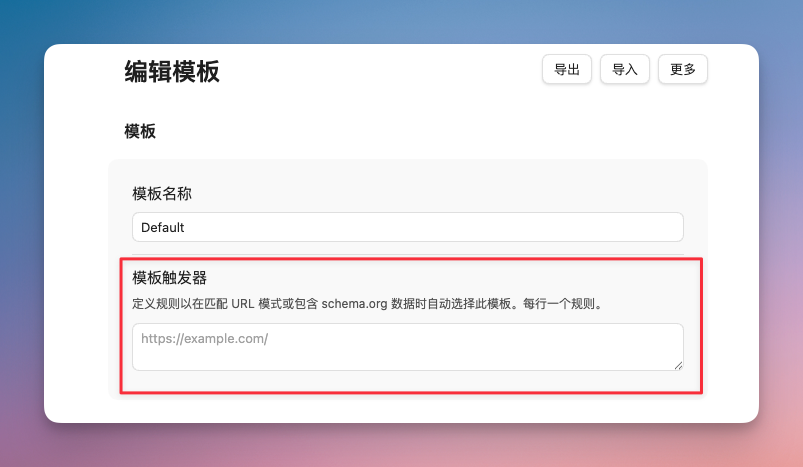
模板还能自动匹配。不同类型的网页可以用不同的模板。在模板设置里有一个「触发条件」字段,你可以填 URL 前缀或正则表达式。比如你经常访问某个网站,可以给它单独设一个模板,以后每次剪藏自动套用。
官方还提供了一堆现成的模板可以导入:GitHub 上搜 kepano/clipper-templates,下载 JSON 文件拖进设置界面就行。
从收藏夹到知识库
回到开头那个问题:你浏览器收藏夹里有多少文章是「收藏即读完」的?
我觉得不全是你的问题,工具也有责任。收藏夹的设计就是「存了就忘」,它的检索体验、阅读体验、整理体验,都不支持你真正把那些内容用起来。
Web Clipper 做的事情,是把网页内容以结构化的方式住进你的 Obsidian。它有标题、有来源、有作者、有标签。你可以搜索它、链接它、在 Dataview 里汇总它。
笔记工具迁移了,但收藏习惯终于不用再迁了。
下一篇,我们将给 Web Clipper 叠加 AI 能力,让剪藏完的文章自动生成摘要、标签等。