YOLOv5 实战:从 GitHub 拉取到自定义数据集训练
系列说明:本篇为 YOLO 系列第四篇,聚焦 YOLOv5 的工程化实践------从 GitHub 拉取代码、准备 MaskDataSet 数据集,到完成模型训练与推理的完整流程。
一、YOLOv5 简介
GitHub 仓库 :https://github.com/ultralytics/yolov5
作者/组织 :Ultralytics
最新版本:v7.0(支持目标检测 + 实例分割 + 图像分类)
YOLOv5 与 YOLOv4 的核心区别在于工程化程度:
| 对比项 | YOLOv4 | YOLOv5 |
|---|---|---|
| 实现框架 | Darknet(纯C) | PyTorch(主流深度学习框架) |
| 代码质量 | 学术风格 | 工程化完善(模块化、自动化) |
| 部署支持 | 需手动转换 | 原生支持 ONNX/TensorRT/CoreML/TFLite |
| 训练体验 | 配置复杂 | 参数简洁、功能丰富 |
| 社区生态 | 一般 | 极其活跃(Star 4万+) |
💡 建议:学习目标检测首选 YOLOv5,生产部署可参考 YOLOv5 工程结构。
二、环境准备
2.1 系统要求
| 组件 | 最低要求 | 推荐配置 |
|---|---|---|
| Python | ≥ 3.8.0 | 3.9 / 3.10 |
| PyTorch | ≥ 1.8 | 2.0+ |
| GPU | 可选(CPU可训练但很慢) | NVIDIA GPU + CUDA 11.x |
| 内存 | 8GB | 16GB+ |
| 显存 | - | 8GB+(训练 YOLOv5s) |
2.2 安装 PyTorch(GPU 版本)
bash
# CUDA 11.8
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# CUDA 11.8 + cuDNN
pip install torch==2.0.0 torchvision==0.15.0 --index-url https://download.pytorch.org/whl/cu1182.3 验证 PyTorch 安装
python
import torch
print(f"PyTorch 版本: {torch.__version__}")
print(f"CUDA 可用: {torch.cuda.is_available()}")
print(f"CUDA 版本: {torch.version.cuda}")
# 输出示例:
# PyTorch 版本: 2.0.0
# CUDA 可用: True
# CUDA 版本: 11.8三、从 GitHub 拉取 YOLOv5
3.1 克隆仓库
bash
# 方法一:Git 克隆(推荐)
git clone https://github.com/ultralytics/yolov5.git
cd yolov5
# 方法二:指定版本
git clone --branch v7.0 https://github.com/ultralytics/yolov5.git
cd yolov53.2 安装依赖
bash
# 进入项目目录
cd yolov5
# 安装所有依赖
pip install -r requirements.txtrequirements.txt 主要依赖:
txt
以YOLOv5 的v7.0版本为例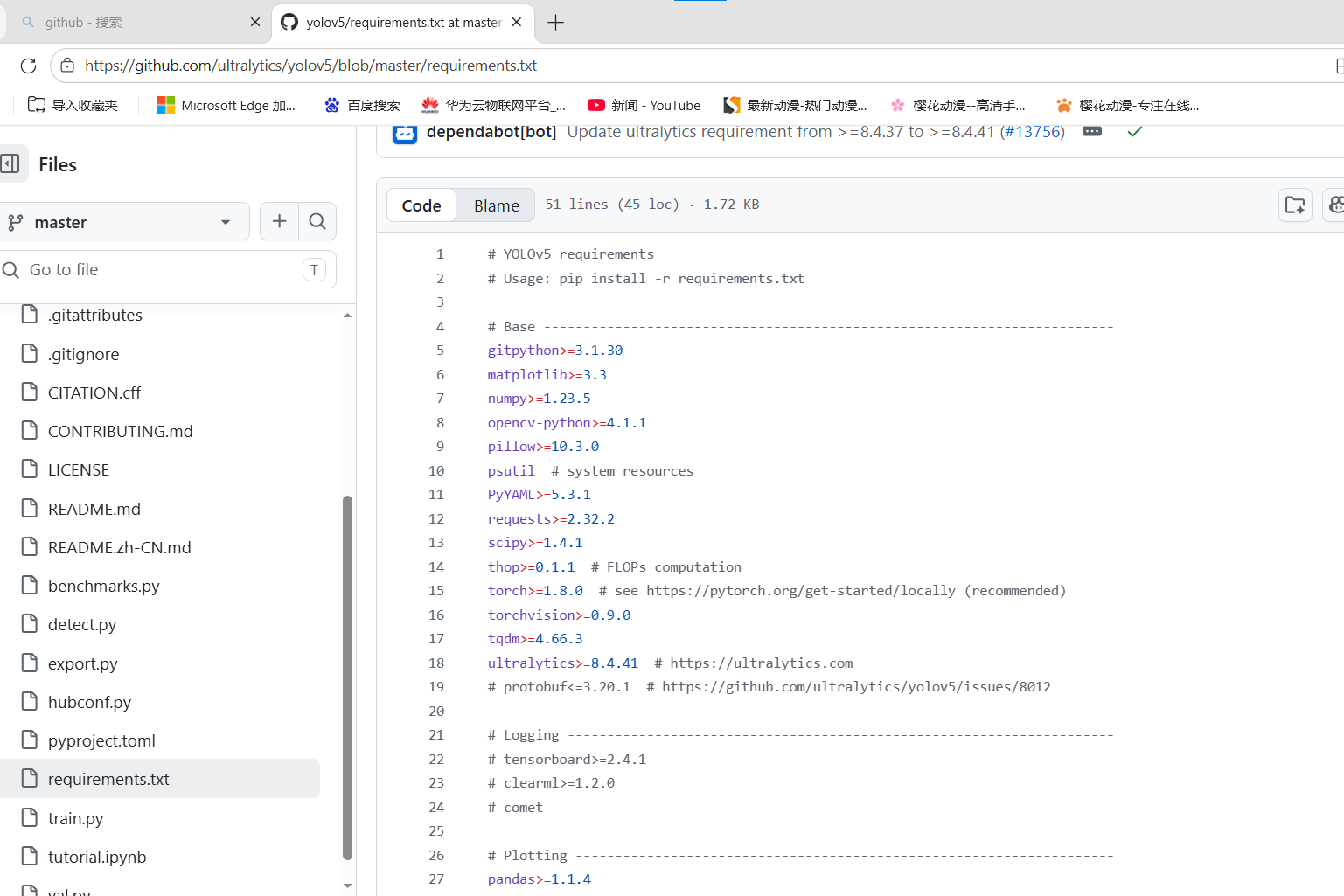
3.3 项目结构
yolov5/
├── train.py # 训练脚本(核心)
├── val.py # 验证脚本
├── detect.py # 推理/检测脚本
├── export.py # 模型导出脚本
├── segment/ # 实例分割模块
│ ├── train.py
│ ├── val.py
│ └── predict.py
├── classify/ # 图像分类模块
│ ├── train.py
│ ├── val.py
│ └── predict.py
├── models/ # 模型架构定义
│ ├── yolov5n.yaml
│ ├── yolov5s.yaml
│ ├── yolov5m.yaml
│ ├── yolov5l.yaml
│ └── yolov5x.yaml
├── data/ # 数据集配置
│ ├── images/ # 数据集图片(可选)
│ ├── coco.yaml # COCO 数据集配置
│ ├── coco128.yaml # COCO128 小数据集配置
│ └── hyps/ # 超参数文件
├── utils/ # 工具函数
├── runs/ # 训练输出目录
│ └── train/
│ └── exp/ # 每次训练的结果
└── tutorial.ipynb # Jupyter Notebook 教程四、数据集准备(MaskDataSet)
4.1 数据集格式要求
YOLOv5 使用 YOLO 格式的标注文件,目录结构如下:
MaskDataSet/ # 数据集根目录
├── images/
│ ├── train/ # 训练图片
│ │ ├── img001.jpg
│ │ ├── img002.jpg
│ │ └── ...
│ ├── val/ # 验证图片
│ │ ├── img101.jpg
│ │ └── ...
│ └── test/ # 测试图片(可选)
│ └── ...
└── labels/
├── train/ # 训练标签(与图片一一对应)
│ ├── img001.txt
│ ├── img002.txt
│ └── ...
├── val/
│ ├── img101.txt
│ └── ...
└── test/
└── ...4.2 标签格式说明
每个 .txt 文件对应一张图片,每行描述一个目标:
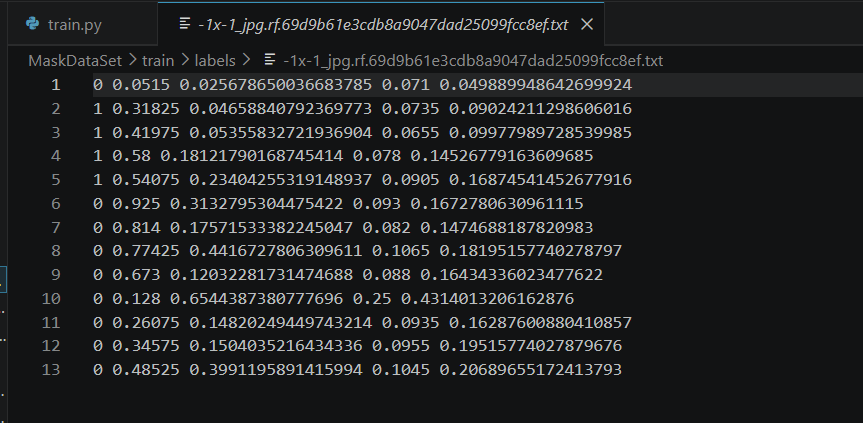
<class_id> <x_center> <y_center> <width> <height><class_id>:类别索引(从 0 开始)<x_center>、<y_center>:目标中心点相对图像的归一化坐标(0~1)<width>、<height>:目标宽高相对图像的归一化值(0~1)
示例 (假设 with_mask=0,without_mask=1,mask_weared_incorrect=2):
# img001.jpg 对应的 img001.txt
0 0.4167 0.3125 0.1667 0.1875 # 第一个目标:with_mask
1 0.6875 0.4375 0.1250 0.1563 # 第二个目标:without_mask⚠️ 注意 :如果图像中没有目标,
.txt文件为空或不存在该文件。
4.3 使用 LabelImg 标注数据集
如果还没有标注数据,可以使用 LabelImg 工具进行标注:
bash
# 安装 LabelImg
pip install labelimg
# 启动(设置为 YOLO 格式)
labelimg --BoundingBoxDir dataset/images/train --SaveDir dataset/labels/train --Format YOLO标注步骤:
- 打开图片文件夹
- 按
W键创建矩形框 - 绘制目标区域,输入类别名称
- 按
D键下一张,A键上一张 - 保存后自动生成同名的
.txt文件
图1:使用 LabelImg 进行目标检测标注
4.4 数据集划分脚本
python
import os
import shutil
import random
from pathlib import Path
def split_dataset(image_dir, output_dir, train_ratio=0.8, val_ratio=0.1):
"""
将数据集划分为训练集、验证集、测试集
Args:
image_dir: 原始图片目录
output_dir: 输出目录
train_ratio: 训练集比例
val_ratio: 验证集比例
"""
# 创建输出目录
for split in ['images/train', 'images/val', 'images/test',
'labels/train', 'labels/val', 'labels/test']:
Path(f"{output_dir}/{split}").mkdir(parents=True, exist_ok=True)
# 获取所有图片文件
image_files = [f for f in os.listdir(image_dir)
if f.endswith(('.jpg', '.jpeg', '.png'))]
# 打乱顺序
random.shuffle(image_files)
# 计算分割点
n_train = int(len(image_files) * train_ratio)
n_val = int(len(image_files) * val_ratio)
splits = {
'train': image_files[:n_train],
'val': image_files[n_train:n_train + n_val],
'test': image_files[n_train + n_val:]
}
# 复制文件
for split_name, files in splits.items():
for filename in files:
# 复制图片
src_img = f"{image_dir}/{filename}"
dst_img = f"{output_dir}/images/{split_name}/{filename}"
shutil.copy(src_img, dst_img)
# 复制标签(如果有)
label_file = Path(image_dir).parent / 'labels' / f"{Path(filename).stem}.txt"
if label_file.exists():
dst_label = f"{output_dir}/labels/{split_name}/{Path(filename).stem}.txt"
shutil.copy(label_file, dst_label)
print(f"数据集划分完成!")
print(f" 训练集: {len(splits['train'])} 张")
print(f" 验证集: {len(splits['val'])} 张")
print(f" 测试集: {len(splits['test'])} 张")
# 使用示例
split_dataset(
image_dir='dataset/raw_images',
output_dir='MaskDataSet',
train_ratio=0.8,
val_ratio=0.1
)五、创建数据集配置文件
在 yolov5/data/ 目录下创建 data.yaml:
可以参考yolov5\data\coco128.yaml来创建自己的data.yaml
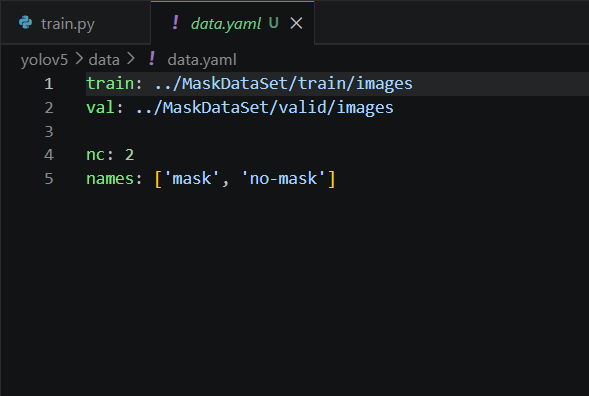
---
**关键点**:
`names` 中的类别顺序必须与标注时的类别 ID 一致
`nc` 必须等于类别总数
`path` 可以使用绝对路径或相对路径六、模型选择与下载
6.1 YOLOv5 模型系列
| 模型 | 参数量 (M) | FLOPs (B) | mAP@50 | 速度 (V100) | 适用场景 |
|---|---|---|---|---|---|
| YOLOv5n | 1.9 | 4.5 | 45.7 | 6.3ms | 边缘设备、实时性要求极高 |
| YOLOv5s | 7.2 | 16.5 | 56.8 | 6.4ms | 通用场景(推荐入门) |
| YOLOv5m | 21.2 | 49.0 | 64.1 | 8.2ms | 需要更高精度 |
| YOLOv5l | 46.5 | 109.1 | 67.3 | 10.1ms | 高精度需求 |
| YOLOv5x | 86.7 | 205.7 | 68.9 | 12.1ms | 最高精度 |
💡 新手推荐 :从
YOLOv5s开始,显存需求较低(6GB+),训练速度快。
6.2 下载预训练权重
YOLOv5 会自动下载预训练权重,也可以手动下载:
bash
# 方式一:训练时自动下载(首次训练会自动下载)
python train.py --data data/mask_data.yaml --weights yolov5s.pt
# 方式二:手动下载(更快)
# YOLOv5s
curl -L -o yolov5s.pt https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s.pt
# YOLOv5m
curl -L -o yolov5m.pt https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m.pt
# YOLOv5n(最小模型)
curl -L -o yolov5n.pt https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5n.pt预训练权重下载位置:https://github.com/ultralytics/yolov5/releases
七、训练配置与运行
7.1 基础训练命令
bash
python train.py \
--data data/data.yaml \
--weights yolov5s.pt \
--epochs 100 \
--batch-size 16 \
--img 640 \
--device 07.2 完整训练参数配置
根据实际硬件配置和需求调整 train.py 参数:
| 参数 | 默认值 | 说明 | 推荐值(6GB显存) |
|---|---|---|---|
--data |
coco128.yaml |
数据集配置文件路径 | data/mask_data.yaml |
--weights |
yolov5s.pt |
预训练权重路径 | yolov5s.pt |
--cfg |
'' |
模型架构文件 | models/yolov5s.yaml |
--epochs |
100 | 训练轮数 | 100~300 |
--batch-size |
16 | 批次大小 | 8~16(根据显存调整) |
--img |
640 | 输入图像尺寸 | 640 |
--device |
'' |
计算设备 | 0(GPU0)或 cpu |
--workers |
8 | 数据加载线程数 | 4~8 |
--project |
runs/train |
输出目录 | 自定义 |
--name |
exp |
实验名称 | mask_train |
--hyp |
data/hyps/hyp.scratch-low.yaml |
超参数文件 | 默认 |
--optimizer |
SGD |
优化器 | SGD / Adam / AdamW |
--lr0 |
0.01 | 初始学习率 | 0.01 |
--momentum |
0.937 | SGD 动量 | 0.937 |
--weight-decay |
0.0005 | 权重衰减 | 0.0005 |
--freeze |
[0] |
冻结层数 | 可冻结 Backbone |
7.3 不同显存大小的批次大小建议
| GPU 显存 | YOLOv5n | YOLOv5s | YOLOv5m | YOLOv5l | YOLOv5x |
|---|---|---|---|---|---|
| 4GB | 64 | 16 | 8 | 4 | 2 |
| 6GB | 128 | 32 | 16 | 8 | 4 |
| 8GB | 256 | 64 | 32 | 16 | 8 |
| 12GB+ | 512 | 128 | 64 | 32 | 16 |
7.4 常用训练命令示例
bash
# 示例1:使用 YOLOv5s 训练口罩数据集(推荐配置)
python train.py \
--data data/data.yaml \
--weights yolov5s.pt \
--epochs 100 \
--batch-size 16 \
--img 640 \
--device 0 \
--name mask_yolov5s \
--project runs/train
# 示例2:从头训练(不使用预训练权重 不太建议)
python train.py \
--data data/data.yaml \
--weights '' \
--cfg models/yolov5s.yaml \
--epochs 200 \
--batch-size 16 \
--img 640
# 示例3:多尺度训练(提升小目标检测)
python train.py \
--data data/data.yaml \
--weights yolov5s.pt \
--epochs 100 \
--batch-size 8 \
--img 640 \
--multi-scale
# 示例4:冻结 Backbone 训练(加速收敛)
python train.py \
--data data/data.yaml \
--weights yolov5s.pt \
--epochs 50 \
--batch-size 32 \
--img 640 \
--freeze 107.5 修改模型配置文件(如需调整类别数)
如果修改了模型结构,编辑 models/yolov5s.yaml:
yaml
# YOLOv5s 模型配置(仅列出最后一层需要修改的地方)
# ...
# yolov5s.yaml 中的检测头部分
# 检测头(根据 nc 修改)
nc: 2 # 修改为你的类别数(这里口罩数据集有 2 类)八、训练过程监控
8.1 训练输出目录
训练完成后,结果保存在 runs/train/ 目录下:
runs/train/exp/
├── weights/
│ ├── best.pt # 验证集上 mAP 最高的模型
│ └── last.pt # 最后一轮的模型
├── results.csv # 训练指标记录(可用 Excel 打开)
├── results.png # 训练曲线图
├── args.yaml # 训练参数配置
└── ...8.2 训练曲线解读
训练完成后会生成 results.png,包含以下曲线:
| 曲线 | 含义 | 理想状态 |
|---|---|---|
| box_loss | 边界框定位损失 | 持续下降 |
| obj_loss | 目标置信度损失 | 持续下降 |
| cls_loss | 分类损失 | 持续下降 |
| precision | 精确率 | 持续上升趋于稳定 |
| recall | 召回率 | 持续上升趋于稳定 |
| mAP@0.5 | IoU=0.5 时的 mAP | 持续上升趋于稳定 |
| mAP@0.5:0.95 | 多 IoU 阈值平均 mAP | 持续上升趋于稳定 |
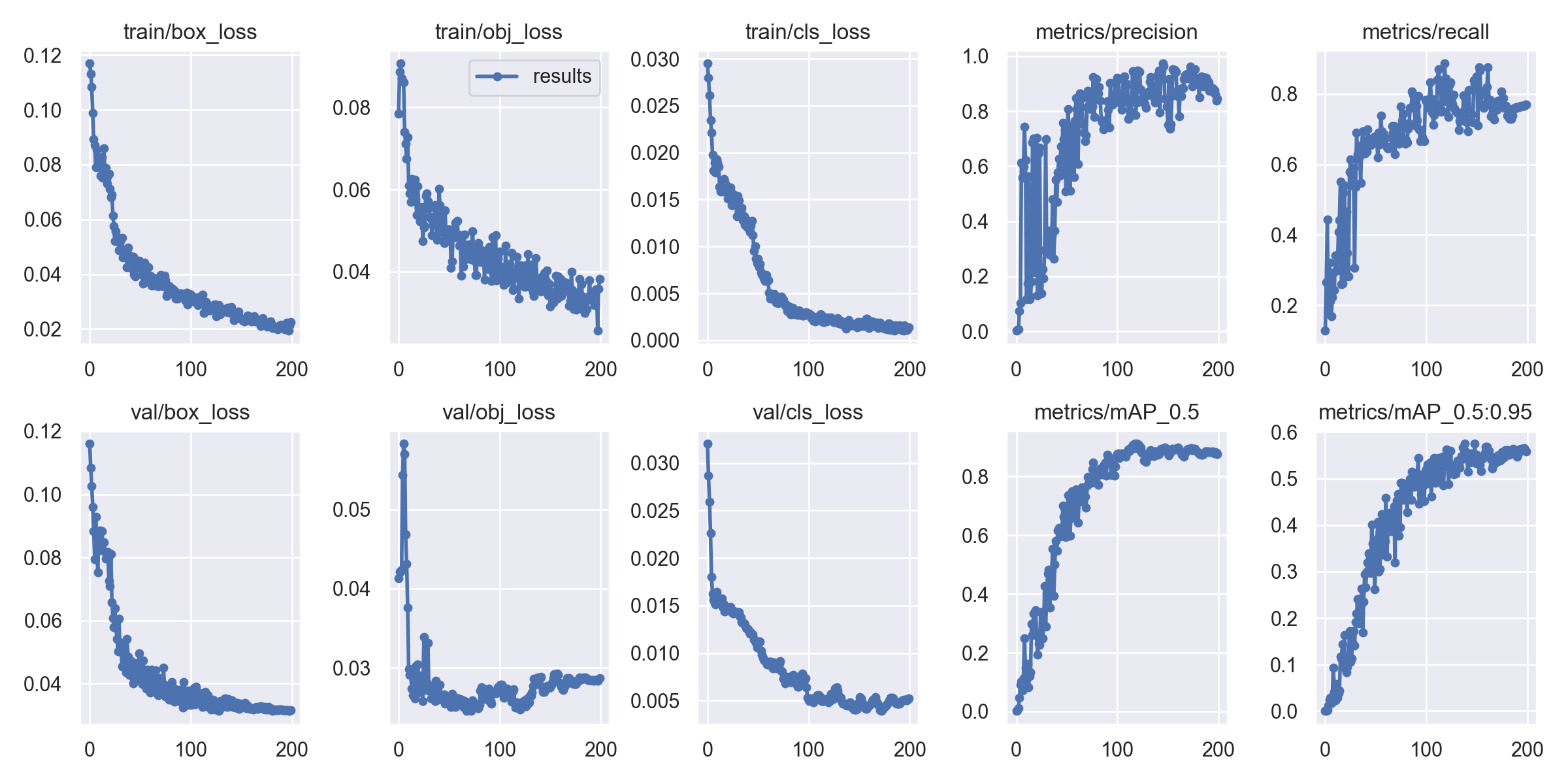
图2:训练过程曲线,监控各项指标的变化
8.3 TensorBoard 可视化
bash
# 安装 tensorboard
pip install tensorboard
# 启动 tensorboard
tensorboard --logdir runs/train
# 浏览器打开 http://localhost:6006九、模型推理与检测
9.1 使用 detect.py 推理
bash
# 检测单张图片
python detect.py \
--weights runs/train/exp/weights/best.pt \
--source data/images/test/img001.jpg \
--device 0
# 检测多张图片
python detect.py \
--weights runs/train/exp/weights/best.pt \
--source data/images/test/ \
--device 0 \
--save-img
# 检测视频
python detect.py \
--weights runs/train/exp/weights/best.pt \
--source video.mp4 \
--device 0 \
--save-video
# 摄像头实时检测
python detect.py \
--weights runs/train/exp/weights/best.pt \
--source 0 \
--device 0
# 批量检测并保存结果
python detect.py \
--weights runs/train/exp/weights/best.pt \
--source data/images/val/ \
--device 0 \
--project runs/detect \
--name exp \
--save-txt \
--save-conf检测结果保存在 runs/detect/ 目录。
9.2 Python API 推理
python
import torch
from pathlib import Path
# 方法一:使用 PyTorch Hub(最简洁)
model = torch.hub.load(
'ultralytics/yolov5',
'custom',
path='runs/train/mask_yolov5s/weights/best.pt'
)
# 设置置信度阈值
model.conf = 0.5 # 置信度阈值
model.iou = 0.45 # NMS IoU 阈值
# 推理
img = 'data/images/test/img001.jpg'
results = model(img)
# 显示结果
results.show()
# 保存结果
results.save()
# 获取检测结果(DataFrame 格式)
df = results.pandas().xyxy[0]
print(df)
# 输出示例:
# xmin ymin xmax ymax confidence class name
# 0 100.5 80.3 250.4 300.2 0.92 0 with_mask
# 1 300.1 120.5 400.2 350.1 0.87 1 without_mask
# 方法二:使用 YOLOv5 模块
from models.common import DetectMultiBackend
from utils.general import non_max_suppression
# 加载模型
model = DetectMultiBackend('runs/train/mask_yolov5s/weights/best.pt')
img = torch.zeros((1, 3, 640, 640)) # 输入图像
# 推理
pred = model(img)
pred = non_max_suppression(pred)
print(f"检测到 {len(pred[0])} 个目标")十、模型验证
10.1 在验证集上评估模型
bash
python val.py \
--data data/data.yaml \
--weights runs/train/exp/weights/best.pt \
--img 640 \
--batch-size 32 \
--device 010.2 输出指标
验证完成后会输出以下指标:
| 指标 | 含义 |
|---|---|
| mAP@0.5 | IoU=0.5 时的平均精度 |
| mAP@0.5:0.95 | 多 IoU 阈值的平均精度 |
| Precision | 精确率 |
| Recall | 召回率 |
| FPS | 推理速度(帧/秒) |
十一、模型导出与部署
11.1 导出为不同格式
bash
# 导出为 ONNX(通用格式,推荐)
python export.py \
--weights runs/train/exp/weights/best.pt \
--include onnx \
--img 640
# 导出为 TensorRT(NVIDIA GPU 加速)
python export.py \
--weights runs/train/exp/weights/best.pt \
--include engine \
--device 0 \
--half
# 导出为 TFLite(移动端/嵌入式)
python export.py \
--weights runs/train/exp/weights/best.pt \
--include tflite \
--img 640
# 导出为 CoreML(iOS)
python export.py \
--weights runs/train/exp/weights/best.pt \
--include coreml \
--img 64011.2 导出格式对比
| 格式 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| ONNX | 跨平台部署 | 通用性强,工具链完善 | 推理速度一般 |
| TensorRT | NVIDIA GPU | 速度最快(3-5x 加速) | 仅支持 NVIDIA |
| TFLite | 移动端/嵌入式 | Android/iOS 友好 | 精度略有损失 |
| CoreML | iOS/macOS | Apple 生态原生支持 | 仅支持 Apple 设备 |
十二、常见问题与解决方案
Q1:训练时显存不足(OOM)
bash
# 解决方案:减小批次大小
python train.py \
--data data/data.yaml \
--weights yolov5s.pt \
--batch-size 8 # 减小批次
--img 416 # 减小输入尺寸Q2:训练中断,想恢复训练
bash
python train.py \
--data data/data.yaml \
--weights runs/train/exp/weights/last.pt \
--resume runs/train/exp/weights/last.pt \
--epochs 200Q3:GPU 利用率低,训练慢
bash
# 解决方案:增加数据加载线程数
python train.py \
--data data/data.yaml \
--weights yolov5s.pt \
--workers 8 \
--batch-size 16Q4:检测不到小目标
bash
# 解决方案:使用更高分辨率 + 多尺度训练
python train.py \
--data data/data.yaml \
--weights yolov5s.pt \
--img 1280 \
--batch-size 8 \
--multi-scaleQ5:模型过拟合
bash
# 解决方案:使用数据增强 + 正则化
python train.py \
--data data/data.yaml \
--weights yolov5s.pt \
--epochs 100 \
--hyp data/hyps/hyp.scratch.yaml \
--augment十三、完整工作流程总结
1. 环境准备
├── 安装 Python >= 3.8
├── 安装 PyTorch + CUDA
└── 安装 yolov5 依赖
↓
2. 代码拉取
└── git clone https://github.com/ultralytics/yolov5
↓
3. 数据集准备(MaskDataSet)
├── 收集图片
├── 使用 LabelImg 标注
├── 划分训练/验证/测试集
└── 生成 YOLO 格式标签
↓
4. 创建数据集配置
└── 编辑 data/mask_data.yaml
↓
5. 模型训练
├── 选择模型(yolov5s.pt)
├── 配置训练参数
└── python train.py --data data/mask_data.yaml --weights yolov5s.pt
↓
6. 训练监控
├── 观察 loss 曲线
├── 观察 mAP 指标
└── 使用 TensorBoard 可视化
↓
7. 模型推理
├── python detect.py
└── Python API 推理
↓
8. 模型部署
├── export.py 导出模型
└── 部署到目标平台十四、小结
本文详细介绍了 YOLOv5 的完整使用流程:
- 环境配置:PyTorch + CUDA 环境搭建
- 代码拉取:从 GitHub 克隆 YOLOv5 仓库
- 数据集准备:MaskDataSet 的 YOLO 格式标注与划分
- 配置文件 :创建
mask_data.yaml数据集配置 - 模型训练:完整的训练命令与参数调优
- 推理检测:使用 detect.py 和 Python API 进行目标检测
- 模型导出:导出为 ONNX/TensorRT/TFLite 等格式
YOLOv5 的工程化设计使得从研究到生产的路径非常顺畅,熟练掌握这套流程后,可以快速将目标检测技术应用到任何实际项目中。
参考资源
- YOLOv5 GitHub 仓库:https://github.com/ultralytics/yolov5
- YOLOv5 官方文档:https://docs.ultralytics.com
- YOLOv5 训练自定义数据教程:https://docs.ultralytics.com/yolov5/tutorials/train_custom_data/
- 预训练权重下载:https://github.com/ultralytics/yolov5/releases