文章目录
-
- 前言
- [1. YOLOv11 训练完成后常见结果文件](#1. YOLOv11 训练完成后常见结果文件)
- [2. Precision:预测出来的目标有多少是真的?](#2. Precision:预测出来的目标有多少是真的?)
- [3. Recall:真实目标中有多少被找出来了?](#3. Recall:真实目标中有多少被找出来了?)
- [4. Precision 和 Recall 的关系](#4. Precision 和 Recall 的关系)
- [5. mAP@50 是什么?](#5. mAP@50 是什么?)
- [6. mAP@50:95 是什么?](#6. mAP@50:95 是什么?)
- [7. 如何结合指标判断模型好坏?](#7. 如何结合指标判断模型好坏?)
-
- [7.1 Precision 高,Recall 低](#7.1 Precision 高,Recall 低)
- [7.2 Precision 低,Recall 高](#7.2 Precision 低,Recall 高)
- [7.3 mAP@50 高,mAP@50:95 低](#7.3 mAP@50 高,mAP@50:95 低)
- [7.4 Precision、Recall、mAP 都较高](#7.4 Precision、Recall、mAP 都较高)
- [8. 示例:如何分析一组 YOLOv11 实验结果?](#8. 示例:如何分析一组 YOLOv11 实验结果?)
- [9. PR 曲线怎么看?](#9. PR 曲线怎么看?)
- [10. results.png 怎么看?](#10. results.png 怎么看?)
- [11. 常见误区总结](#11. 常见误区总结)
- [12. 总结](#12. 总结)
前言
使用 YOLOv11 训练目标检测模型后,通常会看到 Precision、Recall、mAP@50、mAP@50:95、PR 曲线、results.png 等结果文件。
很多初学者刚跑完模型时,可能会有这些疑问:
- Precision 高是不是模型就一定好?
- Recall 低说明什么?
- mAP@50 和 mAP@50:95 有什么区别?
- 为什么 mAP 看起来不错,但实际检测仍然会漏检?
results.png、PR_curve.png应该怎么看?
本文主要结合 YOLOv11 目标检测任务,对这些常见指标进行解释,帮助大家快速判断模型效果。
1. YOLOv11 训练完成后常见结果文件
使用 Ultralytics YOLOv11 训练后,通常会在 runs/detect/train 或自定义实验目录下生成以下文件:
results.png:训练过程中 loss 和评价指标变化曲线results.csv:每个 epoch 的详细结果记录PR_curve.png:Precision-Recall 曲线P_curve.png:Precision 随置信度变化曲线R_curve.png:Recall 随置信度变化曲线F1_curve.png:F1 分数随置信度变化曲线confusion_matrix.png:混淆矩阵weights/best.pt:验证集上表现最好的模型权重weights/last.pt:最后一个 epoch 的模型权重
(是不是觉得有点多?没关系)初学者可以先重点关注:
- Precision
- Recall
- mAP@50
- mAP@50:95
这几个指标基本可以帮助我们判断模型是否存在误检、漏检,以及整体检测效果如何。
目录结构一般类似:
text
runs/detect/train/
├── results.png
├── results.csv
├── PR_curve.png
├── P_curve.png
├── R_curve.png
├── F1_curve.png
├── confusion_matrix.png
└── weights/
├── best.pt
└── last.pt2. Precision:预测出来的目标有多少是真的?
Precision 通常翻译为"精确率",它关注的是:
模型预测出来的目标中,有多少是真正预测正确的。
公式为:
text
Precision = TP / (TP + FP)其中:
- TP:True Positive,检测正确的目标
- FP:False Positive,误检出来的目标
例如,模型预测出了 100 个目标框,其中 80 个是正确的,20 个是误检,那么:
text
Precision = 80 / 100 = 0.8也就是说,模型预测出来的框有 80% 是正确的。
在目标检测任务中,如果 Precision 较低,说明模型容易把背景、噪声或其他类别误认为目标。
简单理解:
Precision 关注的是:模型报出来的结果准不准。
3. Recall:真实目标中有多少被找出来了?
Recall 通常翻译为"召回率",它关注的是:
所有真实存在的目标中,模型成功检测出了多少。
公式为:
text
Recall = TP / (TP + FN)其中:
- TP:检测正确的目标
- FN:False Negative,真实存在但被漏检的目标
例如,图片中实际有 100 个目标,模型只检测出了 70 个,那么:
text
Recall = 70 / 100 = 0.7也就是说,模型找出了 70% 的真实目标。
在病害检测、缺陷检测、医学检测等任务中,Recall 往往很重要,因为漏检意味着真实存在的问题没有被发现。
简单理解:
Recall 关注的是:真实目标有没有被尽量找全。
4. Precision 和 Recall 的关系
Precision 和 Recall 关注角度不同:
- Precision:预测出来的框准不准
- Recall:真实目标有没有被找全
在目标检测中,二者经常会互相牵制。
如果提高置信度阈值,模型只保留更有把握的预测框,Precision 往往会上升,但一些置信度较低的正确目标可能被过滤掉,导致 Recall 下降。
如果降低置信度阈值,模型会保留更多预测框,Recall 可能上升,但误检框也可能增加,导致 Precision 下降。
可以简单理解为:
- Precision 高:模型更"谨慎",报出来的大多是对的
- Recall 高:模型更"积极",尽量把可能的目标都找出来
所以,模型好不好不能只看 Precision 或 Recall,而要结合任务需求判断。
例如:
- 如果误检代价高,更关注 Precision;
- 如果漏检代价高,更关注 Recall。
对于病害检测、缺陷检测等任务,漏检通常比较严重,因此 Recall 是一个很重要的指标。
5. mAP@50 是什么?
mAP 是 mean Average Precision 的缩写,可以理解为"平均精度均值"。
在目标检测中,模型不仅要判断类别是否正确,还要判断预测框位置是否足够准确。因此,mAP 和 IoU 有关。
IoU 表示预测框和真实框的重叠程度:
text
IoU = 预测框和真实框的交集面积 / 预测框和真实框的并集面积mAP@50 表示:
当 IoU 阈值为 0.5 时计算得到的 mAP。
也就是说,如果预测框和真实框的 IoU 大于等于 0.5,并且类别预测正确,那么这个预测框就可以被认为是一次正确检测。
因此,mAP@50 可以理解为:
在相对宽松的定位要求下,模型的整体检测能力。
mAP@50 越高,通常说明模型在目标分类和大致定位方面表现越好。
6. mAP@50:95 是什么?
mAP@50:95 是一个比 mAP@50 更严格的指标。
它表示在多个 IoU 阈值下分别计算 AP,然后取平均值。这些 IoU 阈值通常包括:
text
0.50, 0.55, 0.60, 0.65, ..., 0.95相比 mAP@50,mAP@50:95 对预测框位置更加敏感。
如果一个模型的 mAP@50 较高,但 mAP@50:95 明显偏低,可能说明:
模型能找到目标的大概位置,但预测框和真实框贴合得不够精确。
两者区别如下:
| 指标 | 关注点 | 特点 |
|---|---|---|
| mAP@50 | IoU=0.5 时的检测效果 | 相对宽松 |
| mAP@50:95 | 多个 IoU 阈值下的平均效果 | 更严格,更关注定位质量 |
因此,分析目标检测模型时,不能只看 mAP@50,也要结合 mAP@50:95 判断模型定位能力。
7. 如何结合指标判断模型好坏?
实际实验中,不建议只看单一指标,而应该结合任务需求分析。
7.1 Precision 高,Recall 低
说明模型预测比较谨慎,误检较少,但可能漏检较多。
这种模型更适合误检代价较高的任务。
7.2 Precision 低,Recall 高
说明模型比较积极,能找出更多真实目标,但也可能带来更多误检。
这种模型更适合漏检代价较高的任务,例如病害筛查、缺陷检测等。
7.3 mAP@50 高,mAP@50:95 低
说明模型能够大致找到目标,但定位不够精细,预测框可能不够贴合真实目标边界。
7.4 Precision、Recall、mAP 都较高
说明模型在误检控制、漏检控制和整体检测效果上都比较均衡。
不过,指标只能反映整体统计结果,最终还需要结合实际预测图片进行观察。
8. 示例:如何分析一组 YOLOv11 实验结果?
为了更直观地理解这些指标,下面给出一组示例实验结果。
假设我们在同一个数据集上训练了 3 个 YOLOv11 模型:
| Model | Precision | Recall | mAP@50 | mAP@50:95 |
|---|---|---|---|---|
| YOLOv11n | 68.42 | 61.35 | 66.80 | 45.27 |
| YOLOv11n + Module A | 72.18 | 59.46 | 67.12 | 46.03 |
| YOLOv11n + Module B | 66.75 | 65.82 | 69.54 | 48.36 |
从表中可以看到,三个模型的特点不同。
YOLOv11n + Module A 的 Precision 最高,达到 72.18%,说明它预测出来的目标框更可靠,误检相对更少。但它的 Recall 只有 59.46%,说明它可能漏掉了一部分真实目标。
YOLOv11n + Module B 的 Precision 不是最高,但 Recall 达到了 65.82%,说明它能检测出更多真实目标。同时,它的 mAP@50 和 mAP@50:95 也最高,说明整体检测效果和定位质量更好。
因此,如果当前任务更关注"尽量不要漏检",例如病害检测、缺陷检测、异常区域筛查等场景,那么 YOLOv11n + Module B 可能更合适。
如果当前任务更关注"检测结果必须足够准确",例如误检成本较高的场景,那么 Precision 更高的 YOLOv11n + Module A 可能更值得考虑。
所以,目标检测模型评价不能简单看哪个数字最大,而要结合具体任务需求:
- 更怕误检:重点关注 Precision;
- 更怕漏检:重点关注 Recall;
- 综合检测能力:关注 mAP@50;
- 定位是否精细:关注 mAP@50:95。
9. PR 曲线怎么看?
YOLO 训练结果中通常会生成 PR_curve.png,也就是 Precision-Recall 曲线。
PR 曲线展示的是模型在不同置信度阈值下 Precision 和 Recall 的变化关系。
一般来说:
- 曲线越靠近右上角,模型整体表现越好;
- 曲线下降越快,说明 Precision 和 Recall 的平衡可能不稳定;
- 不同类别的 PR 曲线可以反映模型在哪些类别上表现较好或较差。
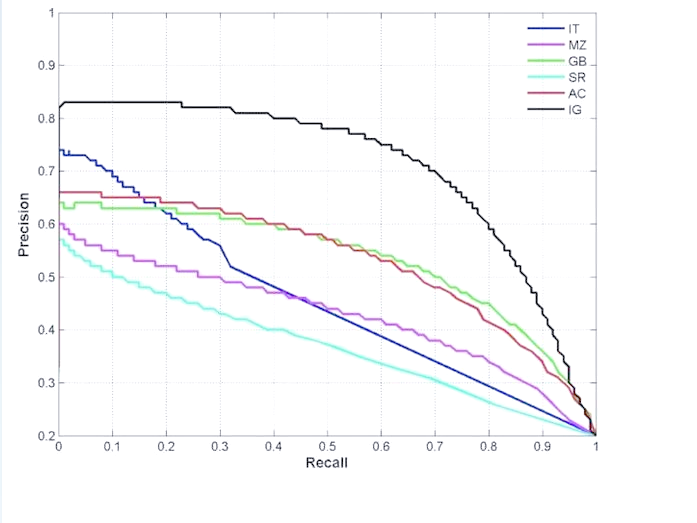
实际分析时,不要只看整体 mAP,也可以观察每个类别的 PR 曲线。如果某些类别曲线明显低于其他类别,说明模型在这些类别上可能存在识别困难。
10. results.png 怎么看?
results.png 一般展示训练过程中的 loss 和评价指标变化。
常见内容包括:
- train/box_loss
- train/cls_loss
- train/dfl_loss
- val/box_loss
- val/cls_loss
- val/dfl_loss
- metrics/precision
- metrics/recall
- metrics/mAP50
- metrics/mAP50-95
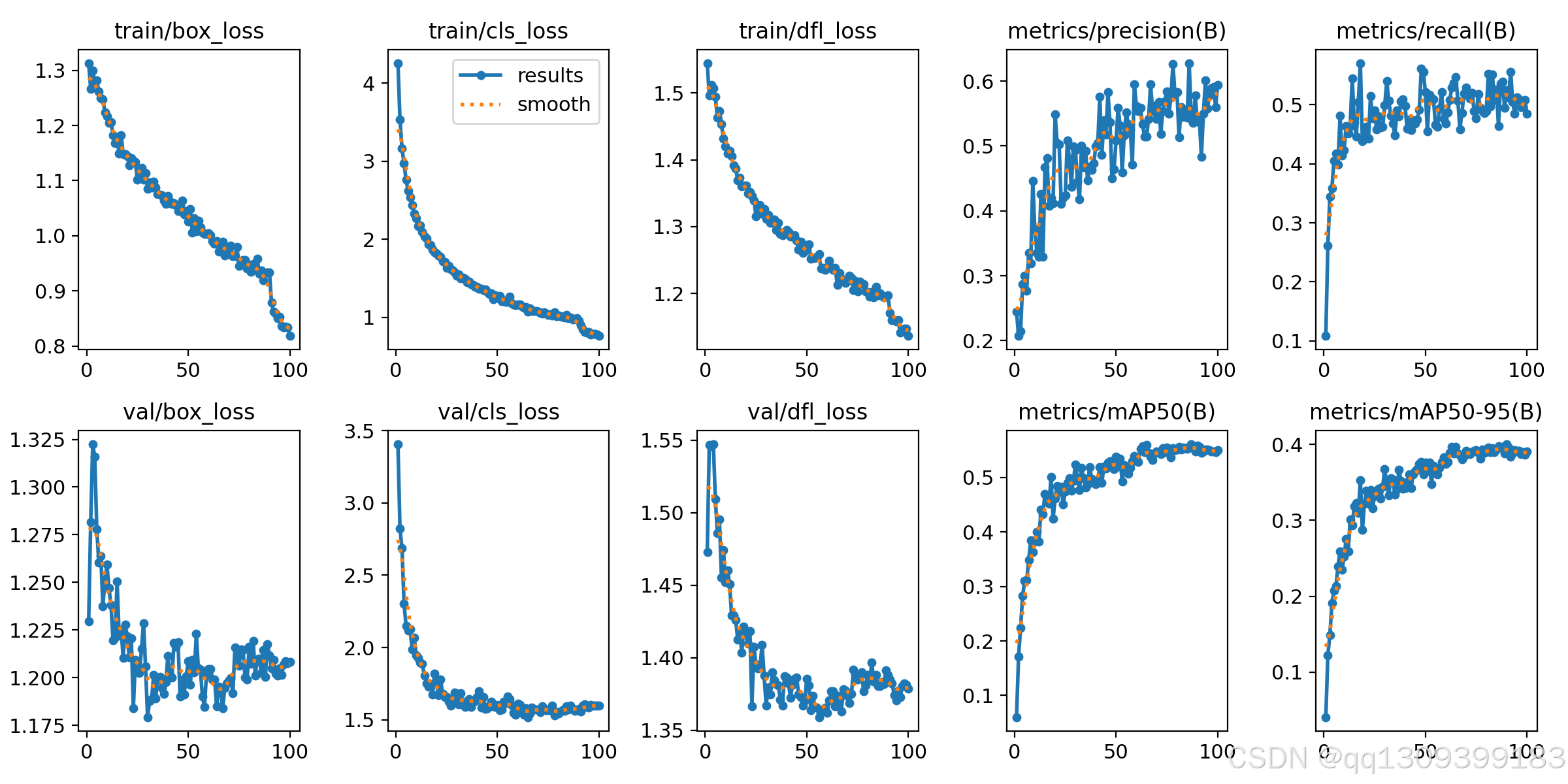
一般来说:
- loss 逐渐下降,说明模型在学习;
- Precision、Recall、mAP 逐渐上升,说明模型性能在提升;
- 如果训练 loss 下降,但验证集指标不提升,可能出现过拟合;
- 如果指标波动较大,可能与数据集规模、学习率、batch size 等因素有关。
需要注意的是,训练曲线只是分析模型的一部分,最终效果还要结合测试集结果和实际预测图像综合判断。
11. 常见误区总结
误区 1:Precision 高就代表模型一定好
Precision 高只能说明预测出来的目标比较准,但不能说明模型没有漏检。如果 Recall 很低,说明很多真实目标没有被检测出来。
误区 2:Recall 高就代表模型一定好
Recall 高说明模型找出了更多真实目标,但如果 Precision 很低,说明误检也可能比较多。
误区 3:mAP@50 高就说明定位很准
mAP@50 的 IoU 阈值只有 0.5,相对宽松。如果想判断模型定位是否更精细,需要同时关注 mAP@50:95。
误区 4:只看 best.pt,不看具体指标
YOLO 训练完成后通常会保存 best.pt,但不同任务关注点不同。如果任务更重视 Recall,可以额外记录和比较 Recall,而不是只看默认保存的 best.pt。
误区 5:验证集指标高,测试集效果一定好
验证集和测试集可能存在分布差异。验证集指标高不代表模型在所有新数据上都表现很好,最终还需要结合独立测试集和实际预测图片观察。
12. 总结
本文介绍了 YOLOv11 目标检测训练结果中常见的 Precision、Recall、mAP@50 和 mAP@50:95 指标。
简单总结:
- Precision 关注预测结果准不准;
- Recall 关注真实目标有没有找全;
- mAP@50 反映较宽松 IoU 条件下的检测能力;
- mAP@50:95 更严格,更能反映预测框定位质量;
- PR 曲线可以观察 Precision 和 Recall 的整体平衡;
- results.png 可以观察训练过程中 loss 和指标变化趋势。
最终,评价一个 YOLOv11 模型不能只看某一个数字,而应该结合 Precision、Recall、mAP、PR 曲线、混淆矩阵和实际预测结果进行综合分析。