最近在使用 AI 编程,同时用三款 Codex/WorkdBuddy/Trae:让OpenClaw替你打工(五):没花什么钱养了6只虾,还赚到了钱。
为什么同时用三个,因为各有各的长处,也有着一些不能满足需求的地方。
所以今天看到这个开源项目: jcode ,纯 Rust 编写,9.2 万行代码,空闲内存只有 28MB(Trae 启动时,经常内存告警),很是吸引我。
吸引我的是:Swarm 多智能体协作和持久化语义记忆系统。
Github地址:https://github.com/1jehuang/jcode
特点
极致性能(最大差异化优势)
| 指标 | jcode | 典型 AI IDE/Agent | 倍率 |
|---|---|---|---|
| 空闲内存 | ~28 MB | 300-800 MB | ~20x |
| 启动时间 | 即时 | 3-10 秒 | --- |
| 帧渲染 | 0.67ms (1400+ FPS) | 16ms (60 FPS) | ~20x |
| 运行时依赖 | 零 | Node.js/Python/Electron | --- |
作者实测:同时跑 10+ 个 jcode 会话(客户端、服务器、子 Agent 全开),总内存还比不上一个 Electron 窗口。
持久化语义记忆系统
-
• 基于向量嵌入的语义记忆图(memory graph)
-
• 跨会话自动提取、存储、注入上下文
-
• 分为全局记忆 + 项目记忆两级,四类记忆:事实、偏好、实体、修正
-
• 后台 Memory SideAgent 自动整理:合并重复、消除矛盾、验证过期信息
Swarm 多智能体协作
-
• 同一代码库同时运行多个 Agent 实例
-
• 自动冲突感知:Agent A 修改了 Agent B 已读文件,B 立即收到通知
-
• Agent 可自主 fork 子 Agent 团队(主 Agent → 协调者,子 Agent → 执行者)
OpenClaw:后台环境 Agent
-
• 持续运行的后台进程,做记忆图谱整理
-
• 主动预判:分析最近会话和 Git 历史,提前完成你可能想做的事
-
• 类比:大脑睡眠时的记忆巩固------你休息时它帮你整理知识
其他核心功能
| 功能 | 说明 |
|---|---|
| 30+ 内置工具 | 文件读写编辑、glob/grep 搜索、bash 执行、Web 抓取、记忆管理、Agent 间通信等 |
| TUI 界面 | Rust 原生终端 UI,侧边栏、内联 diff、Mermaid 流程图渲染 |
| 20+ 模型 Provider | Claude / OpenAI / Gemini / Copilot / Azure / MiniMax 等,OAuth 登录,有订阅就能用 |
| Self-Dev 模式 | Agent 可修改自身源码并自动构建热重载 |
| MCP 集成 | 支持 Model Context Protocol 扩展 |
| Plan Mode | 先只读探索 → 呈现计划 → 批准后再修改 |
安装与使用
go
# macOS / Linux 一键安装
curl -fsSL https://raw.githubusercontent.com/1jehuang/jcode/master/scripts/install.sh | bash
# 源码编译(需 Rust 工具链)
git clone https://github.com/1jehuang/jcode.git && cd jcode
cargo build --release && scripts/install_release.sh
go
jcode # 启动交互式 TUI
jcode run "用 Python 写一个 hello world" # 非交互单次命令
jcode --resume fox # 恢复历史会话
jcode serve # 后台服务模式
jcode connect # 多客户端接入有 Claude Max 或 ChatGPT Pro 订阅,OAuth 登录直接用,不额外花钱。
对比
| 维度 | jcode | Claude Code | aider | Codex CLI |
|---|---|---|---|---|
| 语言 | Rust | --- | Python | TypeScript |
| 内存效率 | ~28MB | ~200MB+/会话 | 中 | 中 |
| 启动速度 | 即时 | 3-10s | 慢 | 中 |
| 跨会话记忆 | ✅ 语义向量记忆图 | ❌ 每次从零开始 | ⚠️ 有限 | ❌ |
| 多 Agent 协作 | ✅ Swarm 原生 | ❌ | ❌ | ❌ |
| 后台 Agent | ✅ OpenClaw | ❌ | ❌ | ❌ |
| Self-Dev | ✅ | ❌ | ❌ | ❌ |
| OAuth 登录 | ✅ 20+ Provider | ✅ 有限 | ❌ | ✅ |
| MCP | ✅ | ✅ | ❌ | ❌ |
| 开源 | ✅ MIT | --- | ✅ | ✅ |
适用场景与局限
适用: 服务器/SSH 远程开发、多项目管理、长周期项目记忆复用、隐私敏感(可接自托管 LLM)、追求终端原生体验的开发者。
局限: 项目仍在活跃开发期,API 可能 Breaking Change;Rust 代码库对非 Rust 开发者贡献门槛高;性能数据未经独立第三方验证。
最想要的多 Agent 协作和持久化语义记忆,它们的底层实现来自项目核心文档 SWARM_ARCHITECTURE.md 和 MEMORY_ARCHITECTURE.md。
多 Agent 协作如何实现?
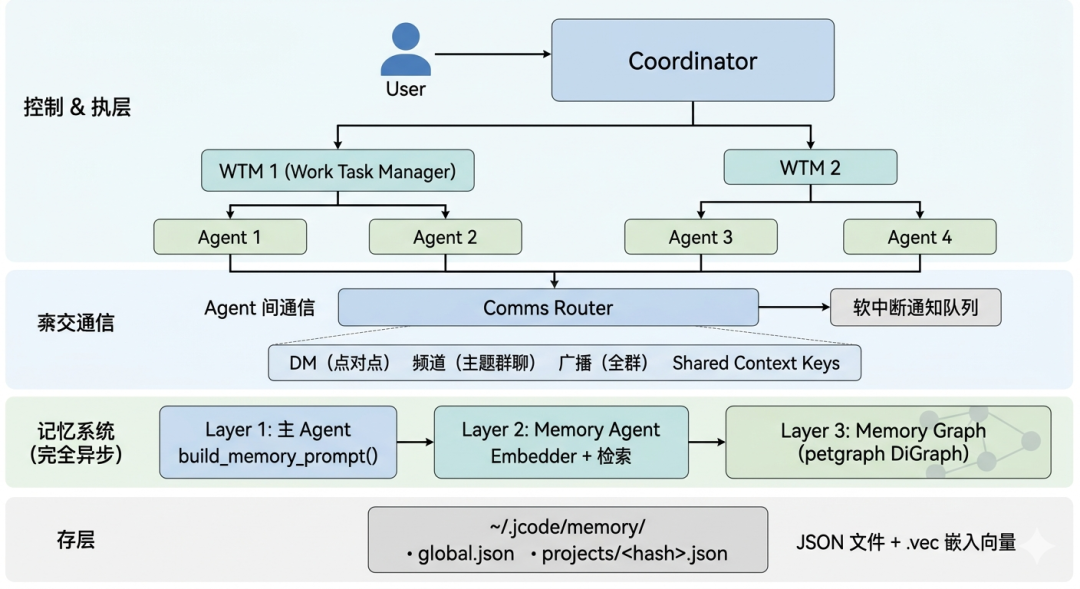
1. 角色体系:三层分工
jcode Swarm 是严格的三级角色分工:
go
用户
│
▼
协调者 (Coordinator) ← 唯一管理人,唯一面向用户
│
├── 工作树管理器 (WTM) ← 可选,管理 git worktree 隔离
│ ├── Agent 1
│ └── Agent 2
│
└── 工作树管理器 (WTM)
├── Agent 3
└── Agent 4| 角色 | 核心权限 |
|---|---|
| 协调者 | 唯一可生成/关闭 Agent;制定 Plan;审批 Plan 更新;不负责合并代码 |
| 工作树管理器 | 管理一个 git worktree;负责该范围内的集成 |
| Agent | 并行执行任务;不可生成或关闭其他 Agent;通过 DM/频道直接与其他 Agent 协商 |
关键约束:Agent 不能链式生成。
A 生成 B,B 也不能生成 C,保证树形结构可控。
2. Agent 间通信靠什么?
核心:Comms Router(通信路由器)+ 通知队列(软中断机制)
go
Agent 1 ── DM ──┐
Agent 2 ── DM ──┤
Agent 3 ── 频道 ─┼──→ Comms Router ──→ 通知队列 ──软中断──→ 目标 Agent
Agent 4 ── 广播 ─┘5 种通信通道:
| 通道 | 类型 | 场景 |
|---|---|---|
| DM | 点对点私信 | Agent 间直接协商冲突 |
| Swarm Broadcast | 全群广播 | 全局状态同步、生命周期事件 |
| Topic Channels | 主题群聊 | 围绕特定话题的多方讨论 |
| Shared Context Keys | 共享键值 | set/read/append 操作 |
| Channel Discovery | 频道发现 | 查找相关频道和参与者 |
通知以软中断 形式在 Agent 的安全点注入,消息可以穿插在同一个 turn 中,不需要启动新 turn。
这避免了"等 Agent 忙完才能收到消息"的延迟。
上下文读取分三档,防止膨胀:
| 层级 | 内容 | 开销 |
|---|---|---|
| Status Snapshot | 元数据 + 当前工具快照 | 极轻,即使目标 Agent 忙碌也能读 |
| Summary Feed | 工具调用名称 + 意图 + 简要结果 | 轻量 |
| Full Context | 完整上下文和工具输出 | 重量,谨慎使用 |
3. 如何发起任务?任务如何流转?
完整流程:
go
Step 1: 用户 → 协调者(唯一入口)
用户:"帮我重构这个认证模块"
Step 2: 协调者制定 Plan v1
Plan 是服务级内存对象,不存到仓库文件
包含:任务分解 + scope 分配 + 依赖关系
Step 3: 协调者生成 Agent + 分发 Plan
Agent 收到:完整 Plan + 自己的 scope 指令
Step 4: Agent 并行执行
每个 Agent 独立工作在分配的 scope 内
Step 5: 冲突时 Agent 自行协商
Agent A 要改 Agent B 已读的文件
→ File Touch Notification(冲突感知)
→ Agent A 和 B 通过 DM 自行协商
→ 不经过协调者
Step 6: 计划更新
Agent 发现 Plan 有问题 → propose update → 协调者审批 → 广播给 Plan 参与者
Step 7: 完成报告
Agent 完成 → 自动转发 completion report 给协调者
报告必须含:outcome/status、changes/findings、validation、blockers
Step 8: 集成
协调者不负责 merge → 各 WTM 负责 integrationAgent 生命周期状态机:
go
spawned → ready → running ⇄ blocked → completed → stopped
↘ failed → crashed4. 需要编排吗?
不需要外部编排器。 编排逻辑内化在协调者角色中:
-
• 协调者制定 Plan → Agent 自主执行 → 冲突时 Agent 自行协商
-
• 协调者不是中央调度器,不插手执行细节
-
• 协调者的编排职责仅限于:分解任务、生成 Agent、审批 Plan 更新、处理失败重试/替换
恢复机制(Agent 挂了怎么办):
| 操作 | 含义 |
|---|---|
retry |
同一 Agent 重试 |
reassign |
转给另一个现有 Agent |
replace |
安全状态检查后换新 Agent |
salvage |
保留 task-progress context 重新分配 |
持久化语义记忆:文件还是向量库?
jcode 没有接入 Pinecone、Weaviate、Qdrant 等外部向量数据库。所有嵌入计算本地完成:
-
• 嵌入模型 :
all-MiniLM-L6-v2,通过tract-onnx在本地 CPU 运行 -
• 向量搜索 :内存中余弦相似度计算,在
petgraph::DiGraph图结构中直接查找 -
• 嵌入向量 :存储为独立的
.vec文件
实际存储布局
go
~/.jcode/memory/
├── graph.json # 核心:序列化的 petgraph 有向图
├── global.json # 用户全局记忆
├── projects/
│ └── <project_hash>.json # 每个项目的独立记忆文件
├── embeddings/
│ └── <memory_id>.vec # 每个记忆的嵌入向量
├── clusters/
│ └── cluster_metadata.json # HDBSCAN 聚类中心点
└── tags/
└── tag_index.json # 标签到记忆的映射核心数据结构
go
pub struct MemoryGraph {
graph: DiGraph<MemoryNode, EdgeKind>, // petgraph 有向图
memory_index: HashMap<String, NodeIndex>, // 快速查找索引
tag_index: HashMap<String, NodeIndex>,
cluster_index: HashMap<String, NodeIndex>,
}
pub enum MemoryNode {
Memory(MemoryEntry), // 核心记忆(内容 + 嵌入向量 + 元数据)
Tag(TagEntry), // 显式标签节点
Cluster(ClusterEntry),// 自动聚类节点
}
pub enum EdgeKind { // 6 种边关系
HasTag, RelatesTo { weight: f32 }, Supersedes,
Contradicts, InCluster, DerivedFrom,
}设计文档明确:"人类可读"------所有记忆以 JSON 存储,用户可直接查看/编辑。
全局记忆 vs 项目记忆
| 维度 | 全局 | 项目 |
|---|---|---|
| 存储文件 | global.json |
projects/<hash>.json |
| 隔离方式 | 独立文件 | 按 hash(项目根目录绝对路径) 分文件 |
| 生命周期 | 永久 | 直到项目被删除 |
| 切换时机 | 始终加载 | 自动检测项目切换时加载 |
另有一层 Session 记忆 (当前会话临时),存于图中但标记 active 字段,会话结束自动失效。
记忆图谱的检索流程(级联检索)
go
Step 1: 嵌入相似度搜索(top-10)
→ 用上下文嵌入向量找最相似的记忆
Step 2: BFS 图遍历(深度 2)
→ 从命中节点沿边扩散(HasTag 0.8, InCluster 0.6,
RelatesTo 实际权重, Supersedes 0.9)
→ 衰减公式:decayed_score = edge_weight × (0.7)^depth
Step 3: 侧车验证
→ GPT-5.3 Codex Spark 轻量验证关联性
Step 4: 去重排序返回 top-10后台自动维护机制:
HDBSCAN 自动聚类、信心衰减公式(不同类型记忆不同半衰期:Correction 365 天,Preference 90 天,Fact 30 天,Inferred 仅 7 天)、检索后自动创建/加强关联边。
架构总览
多 Agent 协作和记忆系统是如何工作的:
最近在试用 OpenCode,突然发现这个开源项目,吸引我的最开始是内存占用少,因为其他的还好,一启动 Trae 就提示内存警告。
后来发现它把OpenAI 开源的 Swam 框架下的多 Agent 实现了,正好是我最近需要的功能。
而且它支持多个20多个大模型,无缝衔接现有的官方订阅,切换起来没有负担。
你在用哪些AI 编程工具,欢迎评论区留言。
-END-
推荐阅读:
GitNexus 把代码库变成知识图谱|审核 AI 产出更清晰,改 Bug 更精准
从73.7到89.5,HALO 智能体用"轨迹分析"实现了递归自我进化
DeepSeek 新视觉模型论文:以视觉原语思考让 AI 学会"指图说话"
小米模型 MiMo V2.5 全系列 Pro · TTS 免费用
Claude Code 写攻击脚本 OpenClaw 自动指挥|900家公司3万密钥外泄