AIGC 时代,开发者营销正在被重新定义
当 80% 的开发者开始用 AI 助手做技术决策、当一个开源项目的 Star 数已经不能说明问题、当百度品专的 ROI 越来越难看......我们必须承认:开发者营销,已经走到了一个范式断点。
一、一个真实的反差
2025 年下半年,我观察到一组耐人寻味的数据。
某头部数据库厂商投放了 1200 万元的全年开发者营销预算,覆盖百度 SEM、信息流、KOL 软文、技术峰会,账面数据相当好看。年终复盘时,市场总监却被一个简单的问题问到无言以对:
"去 ChatGPT、DeepSeek 问'国产分布式数据库怎么选',为什么我们的产品没出现在前三?"
预算花得堂堂正正,覆盖率漂漂亮亮,可在那个真正决定开发者今天买什么、明天用什么的 AI 助手回答框 里,他们消失了。
不是"被排名压低了",是根本不存在。
这不是孤例。我和身边十几位 CMO、DevRel 负责人聊过,几乎所有人都在面对同一个困境:老的营销动作还能跑出数据,但跑出的数据不再决定生意。
我们要面对的真相是:开发者获取技术信息的入口、信任技术决策的依据、传播内容的链路,这三件事在过去 18 个月里被同时改写。下面我把它拆成四个根本性变化。
二、入口迁移:从"搜索→链接"到"提问→答案"
很多人还把 AI 助手当作"另一个搜索引擎",这是一个非常昂贵的认知错误。
搜索引擎给你的是 10 个蓝色链接,AI 助手给你的是 1 个综合答案。
链接是平等的------只要排到第一页,至少还有点击的机会;答案是排他的------它要么引用你,要么不引用你。
技术上,AI 助手回答的过程大致如此:
用户提问 q
│
▼
embedding(q) → 查询向量 v_q
│
▼
向量库检索 Top-K 相关 chunks (RAG retriever)
│
▼
LLM(prompt = system + context_chunks + q) → 答案这条链路里,真正决定你"是否被讲到"的是第二步------你的内容能不能被检索到,而不是像 SEO 那样关心"排第几"。
这件事的本质转变是:从"页面 → 链接"的关键词匹配,迁移到了"语义块 → 嵌入向量"的相似度计算。决定 GEO 排名的不再是关键词密度,而是:
- 语义嵌入的密度:你的内容是否被切分成了高质量、独立可检索的语义块
- 结构化标记 :FAQ、HowTo、Q&A pairs 是否被显式标注 (如
schema.org/FAQPage) - 可溯源性:作者、时间、引用关系是否清晰 (让 LLM 觉得"这个源可信")
- 跨语料一致性:同一论点在多个权威源中是否被反复表达
我把这件事概括为一个新指标------"语义引用率" (Semantic Citation Rate, SCR),它取代"关键词排名"成为新一代营销的北极星指标。
简单理解:
SCR = 主流 LLM (DeepSeek / Kimi / 文心 / 通义 / 元宝) 在回答你目标问题时,主动引用你的内容的概率。
如果你今天去做一次 GEO 审计,把 30 个"开发者提问"放进 5 个主流 AI 助手里,你大概率会发现:你目标关键词的 SCR 还不到 10%。这就是接下来 3 年开发者营销最大的增长空间。
三、内容的"原子化"重构:从段落写作到内容操作系统
如果你想让 AI 助手主动引用你,你必须改变写内容的方式。
旧时代的内容是 "长篇大论 + 结尾结论" 。
新时代的内容是 "原子化 + 自洽 + 结构化"。
举一个具体例子,同样讲"向量数据库选型",旧的写法常常是:
"本文将介绍向量数据库的选型方法。首先我们看看市场上主流的几款产品......(铺垫 5000 字) ......综上所述,建议根据团队规模选择。"
这种文章 SEO 还能拿点流量,但喂给 RAG 几乎是灾难------一段一段切下来,每一段都不能独立成立,模型不知道怎么引用。
新的写法应该是这样:
问:1000 万级向量库优先选什么?
答:在 1000 万规模、QPS < 5000 的场景下,Milvus 2.x 的 IVF_PQ 索引 + 单机部署 是性价比最高的方案。
原因:IVF_PQ 在 1000 万维度下相比 HNSW 节省 6~8 倍内存,而召回率仅下降约 3%......
python# 一段可运行的 Milvus 索引代码 from pymilvus import Collection, connections connections.connect("default", host="localhost", port="19530") col = Collection("vec_demo") col.create_index("embedding", { "index_type": "IVF_PQ", "metric_type": "L2", "params": {"nlist": 1024, "m": 16} })
每一个"问---答---证---码 "四元组就是一个内容原子。RAG 检索时直接命中、LLM 生成时直接引用,引用率会数倍于传统长文。
更深一层的洞察:
这种内容人也爱读。
开发者要的从来不是文学,是"在 30 秒内告诉我答案 + 让我立刻验证它对不对"。AI 友好的内容,本质上是"高密度信息单元",这正好和开发者的注意力曲线吻合。
这一点,恰恰是 AIGC 与人类专家协作能产出的最佳质量带:AI 负责把答案写得标准化、模板化,专家负责把答案写得正确、可信。
四、信任的算法化:从"KOL 推荐"到"代码可跑通"
过去十年,开发者营销有一个隐含假设:找有影响力的人帮你说话。这个假设正在快速失效。
原因有二:
第一,KOL 内容池在被 AIGC 稀释。开发者已经形成天然怀疑------"这是不是 AI 写的?是不是软广?"过去 KOL 的稀缺性来自"亲自实测",而当 AI 可以一夜之间生成 1000 篇看起来一样实测的文章,KOL 的信号噪比就崩了。
第二,验证的成本在崩塌。当一个产品声称自己快、稳、好用,开发者过去要花一个下午装环境、写代码、跑 Benchmark;现在他只需要点一下 CSDN 文章下方的 "Run in Cloud" 按钮,30 秒后看到结果。
当验证只要 30 秒,KOL 推荐就贬值了。开发者宁愿信自己 30 秒前看到的代码运行结果,也不愿信一个 KOL 三个月前的好评。
我把这种新的信任结构总结为一个公式:
Verifiability × Reproducibility
Trust = ────────────────────────────────────────
Time-to-Verify可验证性越高、可复现性越好、验证耗时越短,开发者信任度越高。
落到实操,这意味着:每一篇技术营销内容,都应该附带至少一段可运行代码、一个一键部署链接,或一个在线沙箱。没有可运行环境的技术博客,在 2026 年是营销资产里的"二等公民"。
而对厂商而言,"可运行环境"还有一个隐藏价值------它把营销曝光从"读者"转化成了"用户"。读者读完就离开,用户只要 Run 过一次,就在产品的数据闭环里留下了痕迹。
五、营销链路的"全可观测化":从一次性消耗到资产复利
旧的营销漏斗是:曝光 → 点击 → 转化。三段式黑盒,CMO 们用各种归因模型互相说服。
新的营销链路是:曝光 → 阅读 → 运行 → 反馈 → 迭代。每一个环节都产生结构化数据,每一份数据都可以反向喂给 AIGC。
这个变化非常深刻,它意味着两件事:
第一,营销不再是一次性消耗。
一篇文章发完不是结束,开发者的每一次运行、每一次纠错、每一条评论都在反向训练你的内容池。
第二,营销开始有"复利"。
一个被 1000 个开发者跑过、纠过、改过的代码示例,它的可信度和 AI 引用概率,会指数级高于一篇刚发布的新文章。
这把营销从"租流量"变成了"建资产"。一年后,公司账上多出来的不是花掉的预算,而是一座在 AI 助手回答里反复被引用的"语义资产库"。
更进一步,这套数据闭环让营销决策第一次具备"工程化"特征:
| 阶段 | 旧营销 | 新营销 |
|---|---|---|
| 衡量单位 | CPM / CPC | SCR / 跑通率 / 长期引用衰减 |
| 反馈周期 | 月度复盘 | 实时回流 (秒级埋点) |
| 优化方式 | 人工调投放 | 数据反哺 AIGC 自动迭代 |
不夸张地说:营销从此具备了"软件工程"的基本特征------可观测、可灰度、可回滚。
六、一个新框架:开发者营销 4.0
把上面四个变化合在一起,我提出一个新框架------开发者营销 4.0。
| 维度 | 营销 3.0(传统 DevRel) | 营销 4.0(AIGC 时代) |
|---|---|---|
| 入口 | 搜索引擎 + KOL | AI 助手 + 搜索引擎 |
| 内容形态 | 长文 + 视频 + Whitepaper | 内容原子 + 可运行 Demo + 语义嵌入 |
| 信任机制 | KOL 背书 | 代码可跑通 + 数据公开 |
| 关键指标 | 阅读量、外链数 | 语义引用率、Demo 跑通次数 |
| 团队配置 | 营销 + 设计 | 营销 + 技术 + 数据 + AI 内容工程师 |
| 预算去向 | 渠道购买 | 语义资产建设 |
注意最后一行------这是大多数公司还没意识到的:未来 3 年,预算结构会从"60% 投放 + 40% 内容"反转成"60% 内容资产建设 + 40% 投放放大"。
也就是说,预算的"重心"从"租广告位"挪到了"建语义资产"。租来的位置会下架,建好的资产会被 AI 一直引用。
七、给从业者的三条具体建议
如果你是技术品牌的 CMO 或 DevRel 负责人,下面三条是我建议你立刻开始做的事情:
第一,立刻做一次"GEO 审计"。
列出 30 个你最关心的开发者高频提问,去主流 AI 助手 (DeepSeek、Kimi、文心、通义、豆包、元宝) 逐个测一遍------你的产品是否被引用、被怎么描述、是不是被竞品压制。这个数据将决定你接下来 6 个月的内容投资方向。审计可以用一段简单的脚本批量化:
python
# 一个最小化 GEO 审计 demo (伪代码)
questions = ["国产分布式数据库怎么选?", "向量数据库选型推荐", ...]
models = ["deepseek", "kimi", "qwen", "wenxin"]
for q in questions:
for m in models:
ans = ask(model=m, prompt=q)
scr = compute_citation_rate(ans, brand="YourBrand")
log(q, m, scr, ans[:200])第二,把内容生产线"AIGC + 专家"化。
AIGC 解决产能问题,专家解决质量底线。两者缺一不可:
- 只用 AIGC 等于慢性自杀------被 AI 写的口水文反过来污染品牌、也污染语义嵌入;
- 只靠专家等于跟不上速度------开发者一天产生几百个新问题,人工内容永远晚一拍。
正确的姿势:AIGC 草稿 + 专家终审 + 开发者实测三道闸。这不仅是质量保障,也是未来 GEO 算法越来越看重的"可信源信号"。
第三,把每一篇内容都"原子化 + 可运行化"。
每篇文章拆成若干个"问---答---证---码"四元组,每段代码都挂上在线运行环境。
这件事需要内容侧、产品侧、基建侧三方协同。它的价值不是"看起来更专业",而是当 RAG 把你的内容切片喂给 LLM 时,每一个切片都能独立成立、独立被引用。
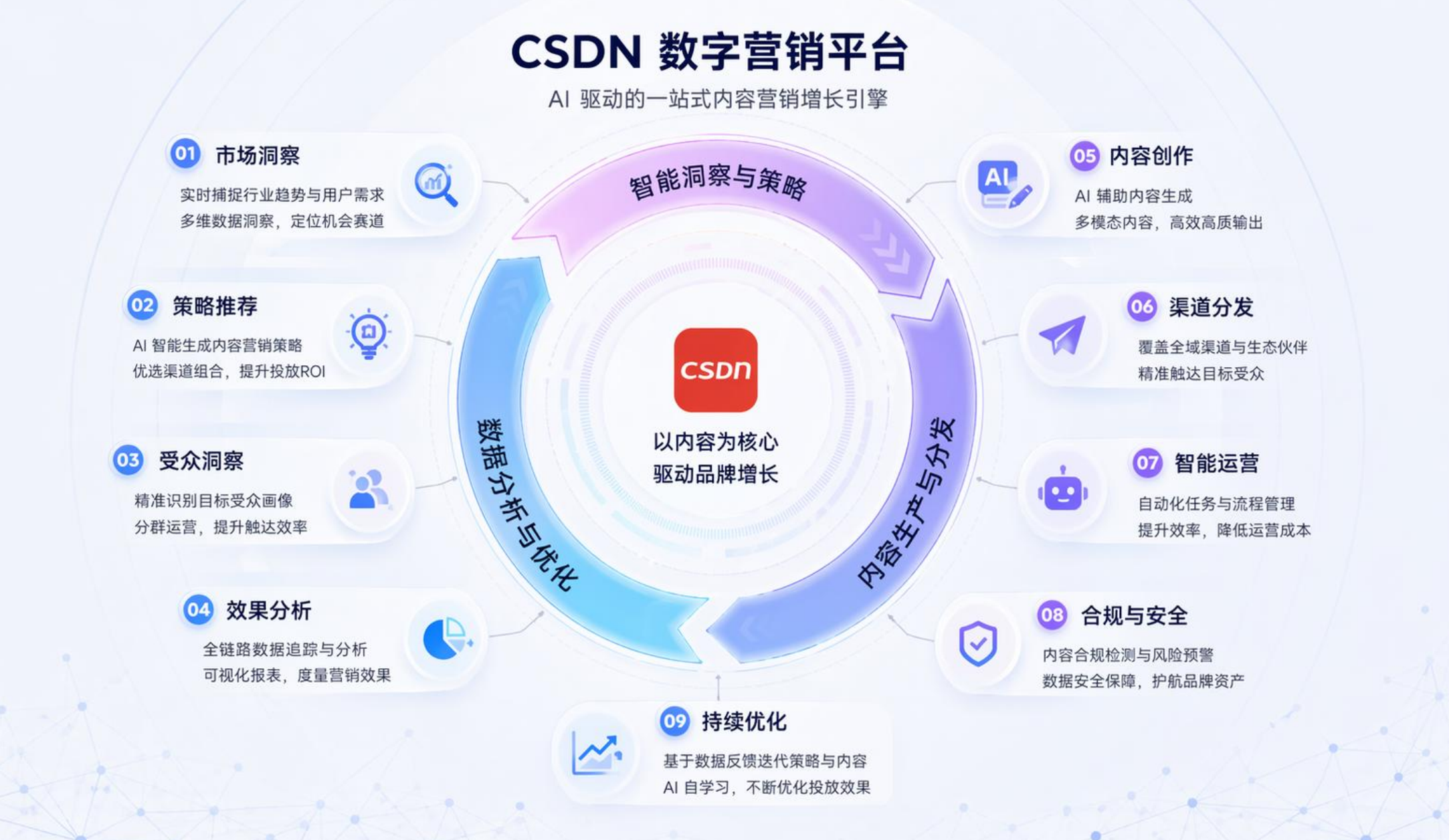
八、结语:营销不再是营销,营销是产品的延伸
最后想抛一个观点:在 AIGC 时代,营销和产品的边界正在融化。
- 当一篇技术博客自带可运行 Demo,它既是 营销资产,也是产品入口;
- 当开发者跑完 Demo 之后留了反馈,它既是 用户行为数据,也是AIGC 的训练样本;
- 当一段代码被 AI 助手反复引用,它既是 品牌广告,也是事实标准。
所以"营销 4.0"的真正含义,不是"用 AI 做营销",而是:
让营销成为一个可观测、可配置、可复制的内容操作系统。
每家技术公司,都应该在 AIGC 时代开始问自己一个问题:
5 年后,当一个开发者问 AI 助手"我应该用谁的产品",AI 会怎么回答?
那个答案,是从今天写下的每一行内容里来的。
如果今天还在按照以前的思路砸投放、追阅读量、堆 KOL,那么 5 年后被 AI 念出名字的,大概率不是你。
关于作者
本文由 CSDN AI 数字营销平台 团队撰写并由多位 CSDN 认证专家审校。平台聚焦 优质内容生产、GEO/SEO 双引擎优化、开发者营销数据闭环,让企业的每一次内容投入都成为可被反复引用的长期资产。
如果你希望对自己的产品做一次内容营销或者GEO 审计,欢迎在评论区留下你最关心的开发者问题------我们将选取 5 个高赞问题,公开发布主流 AI 助手的回答对比报告。