《别再"喂prompt赌运气"了:我的AI开发工程化管理实践》
分享一套我用了一年多的 AI 工程化实践。不是工具说明书,而是一套让 AI 开发可预期、可交接、可回滚的管理方法。
目录
- [一、为什么 AI 写代码这么容易失控?](#一、为什么 AI 写代码这么容易失控? "#%E4%B8%80%E4%B8%BA%E4%BB%80%E4%B9%88-ai-%E5%86%99%E4%BB%A3%E7%A0%81%E8%BF%99%E4%B9%88%E5%AE%B9%E6%98%93%E5%A4%B1%E6%8E%A7")
- [二、第一步:别让 AI 写代码,先让它"冻结上下文"](#二、第一步:别让 AI 写代码,先让它“冻结上下文” "#%E4%BA%8C%E7%AC%AC%E4%B8%80%E6%AD%A5%E5%88%AB%E8%AE%A9-ai-%E5%86%99%E4%BB%A3%E7%A0%81%E5%85%88%E8%AE%A9%E5%AE%83%E5%86%BB%E7%BB%93%E4%B8%8A%E4%B8%8B%E6%96%87")
- [1. 录音 → 纪要 → 结构化摘要](#1. 录音 → 纪要 → 结构化摘要 "#1-%E5%BD%95%E9%9F%B3--%E7%BA%AA%E8%A6%81--%E7%BB%93%E6%9E%84%E5%8C%96%E6%91%98%E8%A6%81")
- [2. 让 DeepSeek 出初版架构方案](#2. 让 DeepSeek 出初版架构方案 "#2-%E8%AE%A9-deepseek-%E5%87%BA%E5%88%9D%E7%89%88%E6%9E%B6%E6%9E%84%E6%96%B9%E6%A1%88")
- [3. ChatGPT 审查,DeepSeek 复核,我做取舍](#3. ChatGPT 审查,DeepSeek 复核,我做取舍 "#3-chatgpt-%E5%AE%A1%E6%9F%A5deepseek-%E5%A4%8D%E6%A0%B8%E6%88%91%E5%81%9A%E5%8F%96%E8%88%8D")
- [4. 反向生成提示词,先"立骨架"](#4. 反向生成提示词,先“立骨架” "#4-%E5%8F%8D%E5%90%91%E7%94%9F%E6%88%90%E6%8F%90%E7%A4%BA%E8%AF%8D%E5%85%88%E7%AB%8B%E9%AA%A8%E6%9E%B6")
- [三、把 AI 开发切成可以独立验收的"施工单元"](#三、把 AI 开发切成可以独立验收的“施工单元” "#%E4%B8%89%E6%8A%8A-ai-%E5%BC%80%E5%8F%91%E5%88%87%E6%88%90%E5%8F%AF%E4%BB%A5%E7%8B%AC%E7%AB%8B%E9%AA%8C%E6%94%B6%E7%9A%84%E6%96%BD%E5%B7%A5%E5%8D%95%E5%85%83")
- [1. 阶段拆分:不追求一次全对,只追求每一步可验收](#1. 阶段拆分:不追求一次全对,只追求每一步可验收 "#1-%E9%98%B6%E6%AE%B5%E6%8B%86%E5%88%86%E4%B8%8D%E8%BF%BD%E6%B1%82%E4%B8%80%E6%AC%A1%E5%85%A8%E5%AF%B9%E5%8F%AA%E8%BF%BD%E6%B1%82%E6%AF%8F%E4%B8%80%E6%AD%A5%E5%8F%AF%E9%AA%8C%E6%94%B6")
- [2. 施工单元:AI 的唯一任务就是"完成当前这一步"](#2. 施工单元:AI 的唯一任务就是“完成当前这一步” "#2-%E6%96%BD%E5%B7%A5%E5%8D%95%E5%85%83ai-%E7%9A%84%E5%94%AF%E4%B8%80%E4%BB%BB%E5%8A%A1%E5%B0%B1%E6%98%AF%E5%AE%8C%E6%88%90%E5%BD%93%E5%89%8D%E8%BF%99%E4%B8%80%E6%AD%A5")
- [3. 执行记录:AI 也必须有"施工日志"](#3. 执行记录:AI 也必须有“施工日志” "#3-%E6%89%A7%E8%A1%8C%E8%AE%B0%E5%BD%95ai-%E4%B9%9F%E5%BF%85%E9%A1%BB%E6%9C%89%E6%96%BD%E5%B7%A5%E6%97%A5%E5%BF%97")
- [4. manifest.yaml:给下一个 AI,或者下一个人类看的进度快照](#4. manifest.yaml:给下一个 AI,或者下一个人类看的进度快照 "#4-manifestyaml%E7%BB%99%E4%B8%8B%E4%B8%80%E4%B8%AA-ai%E6%88%96%E8%80%85%E4%B8%8B%E4%B8%80%E4%B8%AA%E4%BA%BA%E7%B1%BB%E7%9C%8B%E7%9A%84%E8%BF%9B%E5%BA%A6%E5%BF%AB%E7%85%A7")
- 四、你可以直接抄走的最小施工单元模板
- [AI 开发最小施工单元](#AI 开发最小施工单元 "#ai-%E5%BC%80%E5%8F%91%E6%9C%80%E5%B0%8F%E6%96%BD%E5%B7%A5%E5%8D%95%E5%85%83")
- 一个真实示例
- 五、这套方法也不是银弹:它适合谁,不适合谁
- 六、工程化不是"酷",是保命
一、为什么 AI 写代码这么容易失控?
如果你在生产环境里用过 AI 辅助开发,一定经历过这种痛苦:白天跑得好好的 Demo,晚上加一个需求,第二天整个项目红了一片。AI 能帮你从 0 写到 80%,但剩下 20% 的边界问题、模块冲突、隐性假设,能让你填坑填到怀疑人生。
这还不是最可怕的。最可怕的是团队协作:
- 同一个需求,丢给不同的模型,出来的结构天差地别;
- 上一次能跑通的提示词,下次换一个上下文就崩了;
- 三个月后新同事接手,连你当时是怎么让 AI 生成这段代码的都看不懂;
- 项目里有大量"上次 AI 写的,现在没人敢动"的黑盒模块。
一年前,我开始有意识地把 AI 开发从"赌 prompt"拉回到工程轨道上,慢慢形成了一套可复制的工作方式。核心思路只有一句话:
用 AI 驱动开发,用工程化思维治理 AI,用工程化管理落地项目。工程化管理的核心就是去人化------按流程做事,而不是依靠某个人的记忆和直觉。
下面的内容,是我这一年反复试错、迭代后剩下的最靠谱的东西。
二、第一步:别让 AI 写代码,先让它"冻结上下文"
大部分 AI 开发失控的根源,不是模型不够强,而是需求上下文没锁死。人脑补了但没写进提示词的细节,AI 只能猜;猜错了,人又懒得对齐,最后项目越跑越偏。
我现在接手任何一个需求,固定走下面这四步,在真正写代码之前先把上下文彻底冻结。
1. 录音 → 纪要 → 结构化摘要
在征得对方同意的前提下,不管是跟技术总监沟通,还是直接对客户,我都会尽量保留完整沟通记录。录音传给飞书自动生成文字纪要,然后我做一次人工收敛:把业务定义、数据流向、接口预期、非功能约束整理成一段结构化摘要。
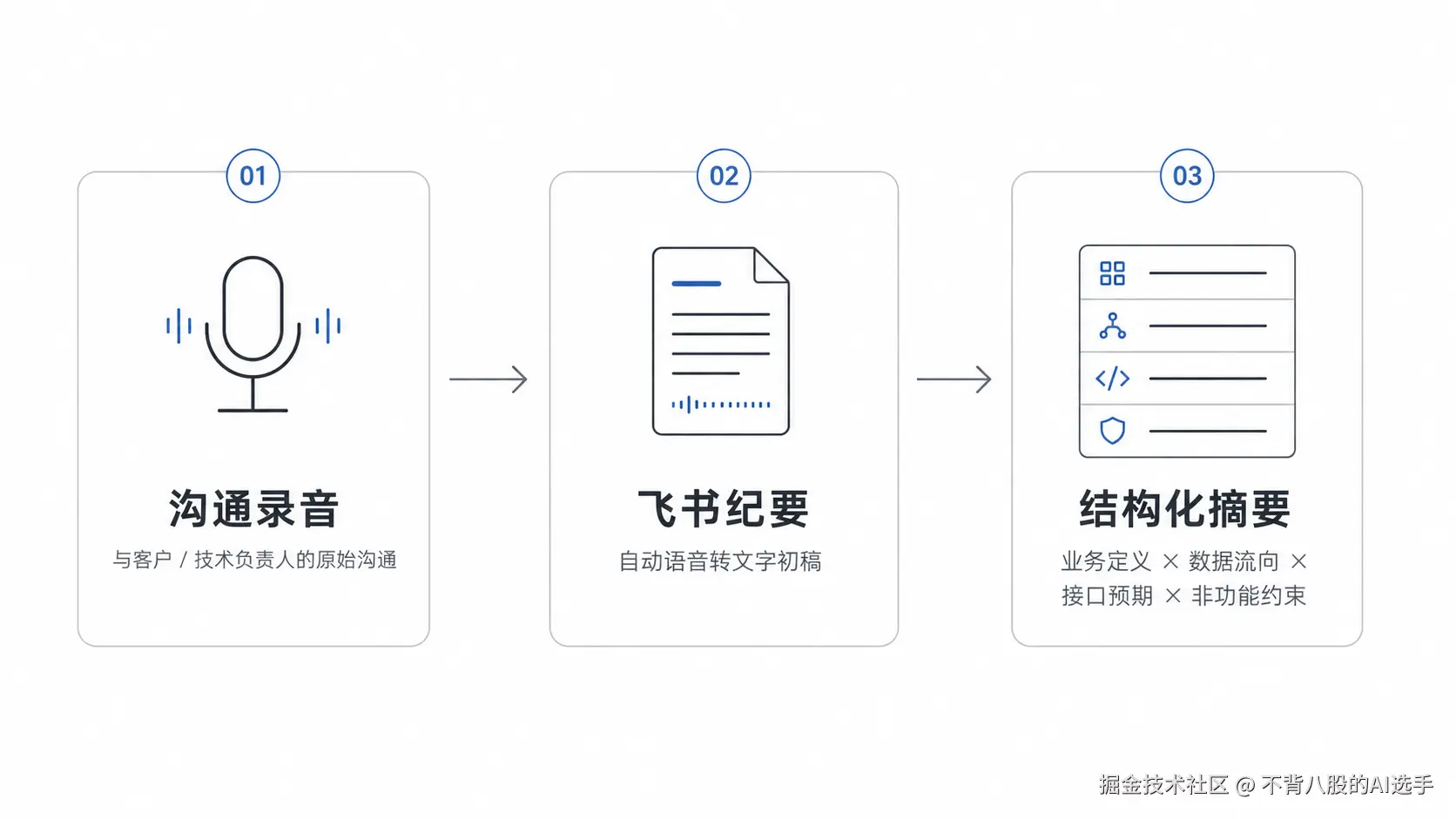 ▲ 从录音到结构化摘要的流程
▲ 从录音到结构化摘要的流程
2. 让 DeepSeek 出初版架构方案
这段摘要我不会直接拿来写代码,而是先丢给 DeepSeek,附上一条非常明确的生成约束:
"根据以下需求摘要,生成一个初步的技术架构方案,必须包含:技术栈选型、核心包结构、关键模块边界和主要风险点。"
这时候 DeepSeek 会给我一版骨架。我在这版骨架上反复补充和修正------把我对团队技术栈的熟悉程度、部署习惯、性能底线这些隐性知识,一点一点填进去,直到它变成一份第二天就能照着施工的文档。
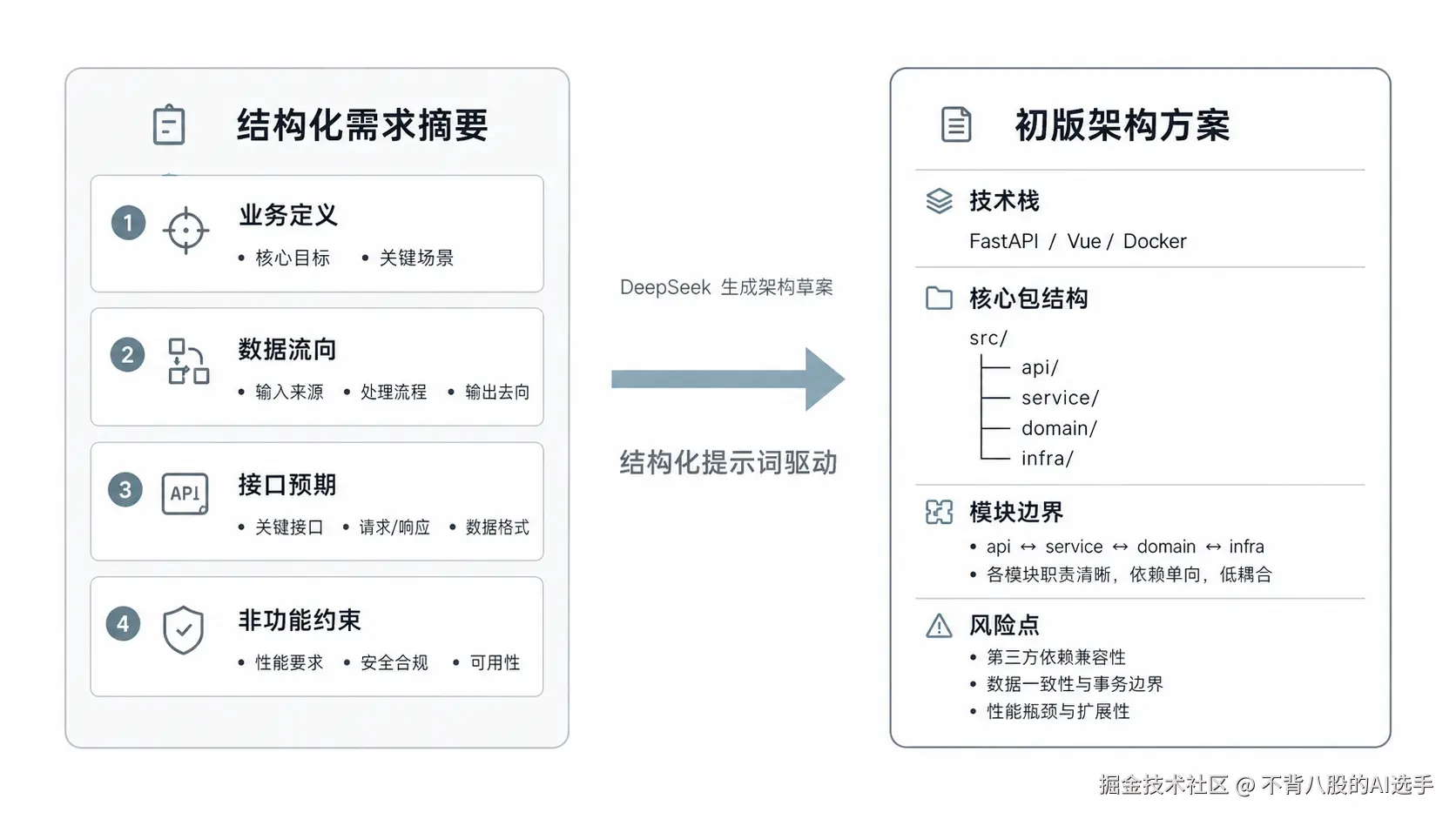 ▲ 结构化摘要到初版架构方案的转化
▲ 结构化摘要到初版架构方案的转化
3. ChatGPT 审查,DeepSeek 复核,我做取舍
到了这一步,这份架构文档大概率已经带着我个人的认知偏见。所以我一定会再引入一轮"交叉审查"。
这里有一个容易漏掉的关键动作:我不仅把架构文档交给 ChatGPT,还会把最初跟领导、客户沟通的原文,也就是录音纪要,原原本本同步给 ChatGPT。
这样做有两个目的。
第一,让 ChatGPT 判断这份架构方案有没有跑偏------有没有脱离最初沟通里明确提到的业务边界、使用场景和非功能约束。
第二,也是更重要的:让 ChatGPT 自己重新理解一遍最原始的需求,不是基于我的摘要,而是基于业务原声。它重新理解之后再去审架构文档,经常能发现我在摘要环节无意中漏掉的信息,排错质量比只看架构文档高一个量级。
ChatGPT 审完之后,我会把它的意见原样转给 DeepSeek,让 DeepSeek 逐条判断哪些合理、哪些脱离实际,哪些可以采纳,哪些不应该动。
最后,由我来做最终的裁剪和决策。我只改那些确实能降低风险、并且可落地的点,绝不为"好像也可以这样"而推翻已经稳定的骨干结构。
这一步的核心不是哪个模型说了算,而是人必须留在决策闭环里。AI 负责提供第二视角,人负责仲裁和担责。
4. 反向生成提示词,先"立骨架"
架构文档稳定之后,我不直接进入业务开发,而是先把文档反向生成一份"骨架搭建提示词",让 AI 拉出整个项目的空壳------空包、空模块、裸配置、依赖声明、Dockerfile 模板。
然后立刻跑一遍 pyproject.toml、npm run build、mvn test 或者对应项目的基础门禁命令,验证目录设计有没有致命冲突。我们内部管这一步叫"先立骨架",本质上是在用最低成本验证:这套结构能不能站住。
用 AI 开发,第一步永远不是写代码,而是冻结上下文。 上下文锁不住,后面写得越快,返工越狠。
三、把 AI 开发切成可以独立验收的"施工单元"
架构和骨架就绪之后,真正的开发过程,我不是"让 AI 看着办",而是严格按一套施工手册来管理。
这套施工手册的结构大概长这样:
text
施工手册/
├── 执行记录/ # 每一步的实际执行日志
├── README.md # 总原则、阶段说明、门禁命令
├── manifest.yaml # 机器可读的进度快照
├── p0-最小闭环/
│ ├── README.md # 本阶段目标
│ ├── p0.1-xxx/
│ │ ├── 01-xxx.md # 施工单元
│ │ ├── 02-xxx.md
│ └── ...
├── p1-单项目全自动/
├── p2-可靠性加固/
└── 通用施工提示词.md # 可复用的 AI 工作约束模板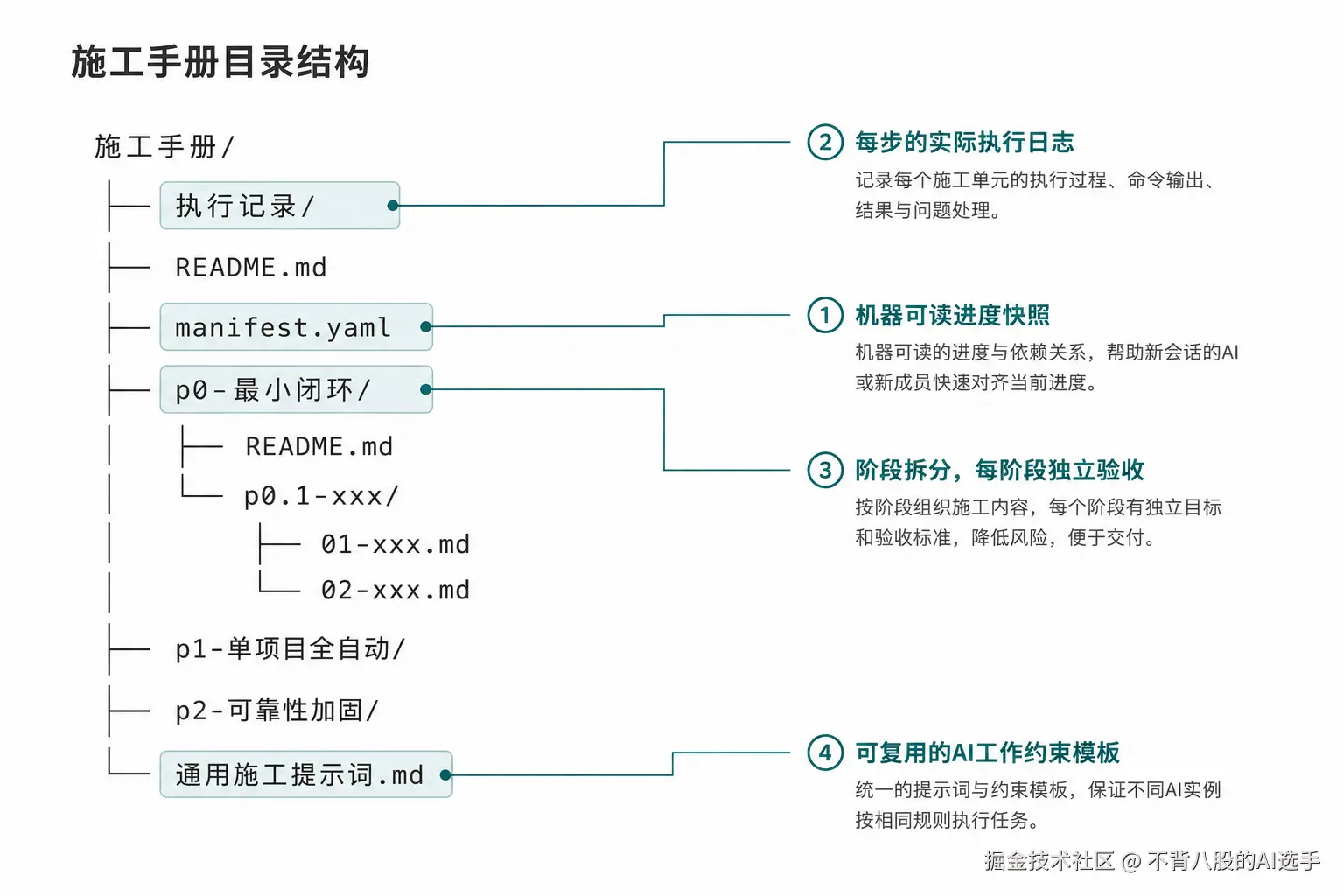 ▲ 施工手册目录结构,重点标出 manifest.yaml、执行记录文件夹、阶段文件夹
▲ 施工手册目录结构,重点标出 manifest.yaml、执行记录文件夹、阶段文件夹
下面解释几个关键设计。
1. 阶段拆分:不追求一次全对,只追求每一步可验收
我现在做任何 AI 驱动项目,一定拆成多个阶段,而且每个阶段必须有独立的验收门禁:
- P0 最小闭环 :验证调度、沙箱执行、状态落盘能不能跑通,哪怕只是让 AI 生成一个
hello.py,然后在 Docker 里跑一遍。 - P1 单项目全自动:从一份规范文档到可交付的 Docker 包,首次打通全链路。
- P2 可靠性加固:加入测试可信度、失败归因、自修复、合并冲突处理。
- P3 人机协同:Web 界面、WebSocket 状态推送、审批流。
- P4 长期能力:半路接盘、增量开发、日志查询、安全审计。
这种拆法不是过度设计,而是因为被坑怕了。以前不拆阶段,AI 一上来就写全功能,最后表面上 70% 能跑,真正难处理的是那 30% 藏在边界条件里的问题。
拆了之后,每完成一个阶段,我就知道什么东西是已经被验证过的。即使后面出新问题,排查范围也被死死框住。
2. 施工单元:AI 的唯一任务就是"完成当前这一步"
施工手册里每一个 01-xxx.md 文件,就是一个原子化的施工单元。
一份标准的施工单元文件,一定写清楚三件事:
- 这是要干什么:目标;
- 允许修改哪些文件:写入边界;
- 怎么算做完:验收命令。
给 AI 执行时,我只把当前这一份文件丢进去,同时硬性约束它:
你可以读取必要的上下文,包括项目结构、依赖关系、已完成步骤,但不允许自行扩展任务范围。你只负责完成当前施工单元。人是唯一的调度者和验收者,你只是负责执行。
这种做法有两个好处。
第一,防止 AI"自作主张"越改越乱。
第二,让任何一个 AI 实例,或者任何一个新接盘的人,拿着同一份文件就能精确工作。
3. 执行记录:AI 也必须有"施工日志"
每完成一个施工单元,不管成功还是失败,都必须立刻写一份执行记录,格式固定:
- 步骤 ID;
- 实际新增/修改了什么文件;
- 跑了什么验收命令;
- 验收通过还是失败;
- 出了什么问题,怎么处理的;
- 下一个要执行的步骤。
这就是 AI 开发的"施工日志"。好处非常直接:
- 三个月后的我自己,不用靠记忆回溯"这一步当时到底怎么过的"。
- 新同事接手,读记录就能对齐全部上下文,而不是对着代码猜。
- 多人并行时,A 完成 p0.2 的记录,B 可以直接拿过来继续 p0.3,沟通成本降到很低。
4. manifest.yaml:给下一个 AI,或者下一个人类看的进度快照
除了人类可读的执行记录,我还必须维护一份机器可读的进度快照 manifest.yaml,大概长这样:
yaml
- id: p0_1_01_project_skeleton
phase: p0
type: code
depends_on: [p0_0_04_artifact_schemas]
outputs:
- README.md
- pyproject.toml
- .gitignore
verify_commands:
- python -m compileall -q src scripts tests
status: pending它的作用是:新开一个对话时,AI 读一遍 manifest,就能立刻知道现在项目推进到哪一步、哪些已经 done、哪些还 pending、依赖关系是什么。
这极大解决了"上次我们说到哪儿了来着"的史诗级痛点。
 ▲ 箭头标注 done/pending 状态、依赖关系和 verify_commands 字段
▲ 箭头标注 done/pending 状态、依赖关系和 verify_commands 字段
四、你可以直接抄走的最小施工单元模板
上面这套体系,你可能觉得"跟我项目关系不大"。但它的核心逻辑可以立刻抽成一个极简模板,任何 AI 开发任务都能套用。
AI 开发最小施工单元
text
1. 当前目标:xxxx
2. 输入资料:xxxx
3. 允许修改的文件列表(写入边界)
4. 禁止修改的文件列表
5. 预期产出
6. 验收命令
7. 完成后记录:
- 实际改动文件
- 验收结果
- 遗留问题
- 下一步骤一个真实示例
text
步骤 ID:p0_1_01_init_backend
目标:
初始化 Spring Boot 工程骨架。
允许修改:
- pom.xml
- src/main/java/**
- src/main/resources/application.yml
禁止修改:
- docs/architecture.md
- database/**
- frontend/**
验收命令:
- mvn test
- mvn spring-boot:run
完成后记录:
- 新增/修改:pom.xml, Application.java
- 验收结果:通过
- 遗留问题:application.yml 中数据库配置留空
- 下一步:p0_1_02_config_baseline即使你不用任何工具,只要你在每次让 AI 写代码之前,手动填好上面这张"施工单",AI 越界、返工和破坏已有结构的概率也会明显下降。
工程化管理的核心,就是把"人记住的事"变成"流程规定的事",然后让这个流程可以被任何一个人、任何一个 AI 实例复现。
五、这套方法也不是银弹:它适合谁,不适合谁
我必须非常诚实地写这一节,因为它决定你是否该用这套方法。
它不适合的场景
- 一次性脚本、临时 Demo、极短期原型验证。 这类任务上下文本身很小,强行拆施工单元反而增加负担。
- 负责人没有足够架构判断力的场景。 施工单元拆得好不好,直接决定 AI 跑不跑偏;如果拆错了,AI 会在错误的约束里快速生产错误代码,酿成更严重的返工。
- 模型基础能力不足时。 这套方法只能降低管理层面的失控概率,不能解决模型本身生成质量不过关的问题。它不能替代代码审查和测试体系,也不能替代你对业务的理解。
它真正发挥价值的场景
- 长期维护、多人协作、需要反复接盘的项目。
- 有明确交付要求的商业项目。
- 需要持续迭代、增量开发、不能每次都推翻重来的产品。
如果你正在做这一类项目,那么现在就可以从第一条"冻结上下文"开始,在你下一个需求里跑一遍试试。
六、工程化不是"酷",是保命
AI 开发最可怕的不是不够快,而是不可接手、不可回滚、不可解释。
这一整年,我自己感受最深的一点是:很多团队不是用不好 AI,而是没有用工程化的方式去管理 AI。 他们误以为 AI 开发就是调提示词,实际上提示词只是最后一步,前面还有上下文管理、边界约束、阶段拆解、验收标准、记录留存。
后面我把这套流程方法整合进了内部一直在迭代的 SpecShip 工作流体系里(核心就是施工手册驱动引擎 + 多模型交叉审查链路),让"按流程做事"这件事本身也被工具化。但名字不重要,真正重要的是把这套"边界、记录、验收、交接"的工作方式落到实际开发节奏里。
用工程化思维治理 AI,不是让它变慢,而是让它变得可靠、可预期、可以被团队真正拥有------而不仅仅是某个人电脑上的一堆漂亮 sample。
如果你也在用 AI 做长期项目,或者正在被 AI 项目的交付折磨,欢迎评论区聊聊。我不一定回得快,但每一个真正踩过坑的问题,我都愿意聊。
这篇文章不是工具介绍,也不是成功学分享。它只是一个被 AI 坑了无数次的人,在真实商业项目里反复试错后,找到的一套还能站得住的方法。