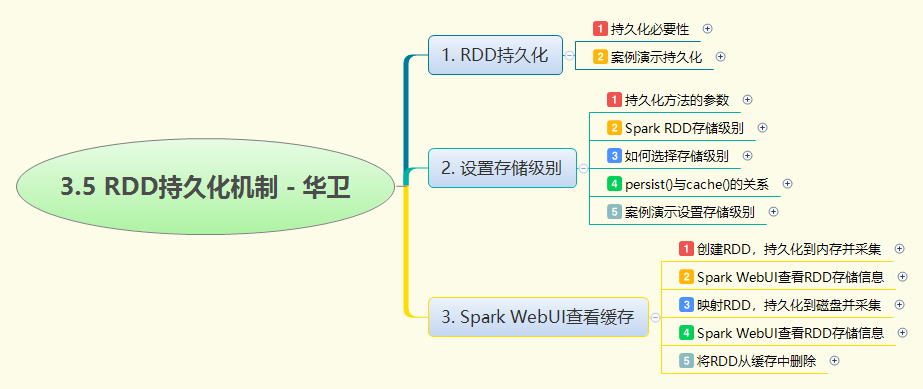
本次实战通过完整的代码示例和Web UI监控,深入讲解了Spark RDD持久化机制。首先通过WordCount案例对比了未持久化(重复计算)与持久化(缓存复用)的性能差异,验证了持久化能显著提升重复计算效率。接着详细介绍了MEMORY_ONLY、DISK_ONLY、MEMORY_AND_DISK等多种存储级别及其适用场景,强调根据内存容量和性能需求合理选择。通过spark-shell交互式操作,演示了如何使用persist()和cache()方法设置不同存储级别,并利用Spark Web UI的Storage页面实时监控RDD缓存状态(内存/磁盘占用、分区分布)。最后展示了unpersist()方法用于手动释放缓存,完整呈现了RDD生命周期管理的最佳实践。

3.5 RDD持久化机制
howard20052026-05-08 20:39
相关推荐
小小工匠1 个月前
Redis - 事务机制:能实现 ACID 属性吗典学长编程1 个月前
Redis分布式缓存超详细教学(微服务版)!极客先躯2 个月前
高级java每日一道面试题-2026年02月03日-实战篇[Docker]-如何备份和恢复 Docker Volume?极客先躯2 个月前
高级java每日一道面试题-2026年02月08日-实战篇[Docker]-如何实现容器的快照和恢复?极客先躯2 个月前
高级java每日一道面试题-2026年02月02日-实战篇[Docker]-如何实现容器的持久化存储?极客先躯2 个月前
高级java每日一道面试题-2026年02月01日-实战篇[Docker]-Docker Volume 的生命周期管理是怎样的?小小工匠2 个月前
Redis - 缓冲区管理:避免溢出引发的“惨案“小小工匠2 个月前
Redis - 异步机制与阻塞规避:Redis 单线程模型的生存之道Trouvaille ~2 个月前
【Redis】Redis 持久化:RDB 与 AOF 深度解析苏渡苇2 个月前
Spring Cloud Alibaba:将 Sentinel 熔断限流规则持久化到 Nacos 配置中心