向量数据库是AI时代的专用数据库,核心用于存储、管理高维向量,实现相似性检索,是RAG、语义搜索等场景的核心底座。
一、向量数据库核心基础
1. 核心定义
向量数据库专门处理高维向量(文本、图片等非结构化数据的"语义指纹"),核心能力是相似性搜索,区别于传统数据库的精确匹配------传统数据库查"等于什么",向量数据库查"像什么"。
2. 数据转向量核心逻辑
核心公式:原始数据(文本/图片)+ 嵌入模型(BGE、CLIP等)= 高维浮点数组(向量)。无需手动设计算法,调用现成嵌入模型,即可完成非结构化数据到向量的转换,语义越相似,向量空间距离越近。
例如有以下四个文本:
- 最近哪家咖啡店评价最好?
- 附近有没有推荐的咖啡厅?
- 明天天气预报说会下雨。
- 北京是中国的首都。
在qwen3-embedding-8b进行嵌入后,使用PCA进行降维并进行可视化:
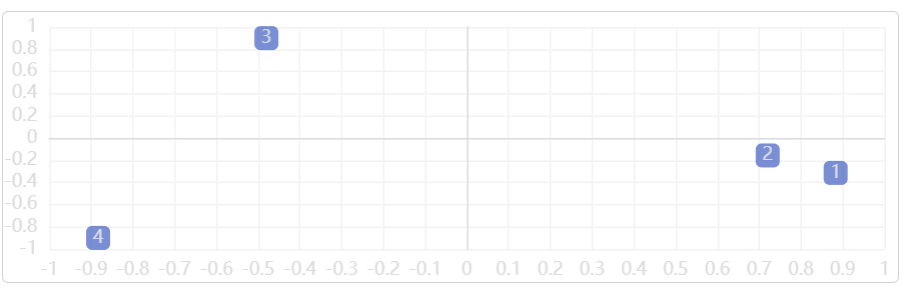
可以看到第1句和第2句语义相似度最高,而输出的json格式的数据如下:
html
[
{
"index": 0,
"object": "embedding",
"embedding": [
-0.025535166263580322,
-0.01879671961069107,
0.011999163776636124,
-0.039248496294021606,
0.009280141443014145,
...
]
},
{
"index": 1,
"object": "embedding",
"embedding": [
-0.0012547832448035479,
-0.02217756398022175,
0.015174122527241707,
-0.03875237703323364,
-0.0010359256993979216,
...
]
},
{
"index": 2,
"object": "embedding",
"embedding": [
0.010746041312813759,
-0.0031099277548491955,
0.027449127286672592,
-0.014191783033311367,
0.030369248241186142,
...
]
},
{
"index": 3,
"object": "embedding",
"embedding": [
-0.006637491285800934,
0.037313465029001236,
0.009388163685798645,
-0.006248809397220612,
-0.006637491285800934,
...
]
}
]3. 核心应用场景
重点场景包括:RAG知识库(企业问答、智能客服)、语义搜索、多模态检索(以图搜图)、推荐系统、人脸识别、风控反欺诈等,核心适配"按内容相似性查找"的需求。
4. 主流选型推荐
按场景分类推荐,简洁好记:
-
新手/个人:Chroma(零配置、开箱即用,Python友好)
-
已有PostgreSQL:pgvector(零成本升级向量能力)
-
企业级大规模:Milvus(分布式、国产适配好)、Qdrant(高并发、低延迟)
-
免运维:Zilliz Cloud(Milvus托管版)、阿里云/腾讯云向量库(国内合规)
5. 基本结构
向量数据库无传统"表",称为"集合(Collection)",每条数据包含3部分:唯一ID(主键)、向量字段(核心,如768维浮点数组)、普通属性字段(元数据,用于过滤),结构比传统数据库仅多一个向量字段。
二、ChromaDB实操:向量集合查看指南
ChromaDB作为新手首选的轻量向量数据库,查看集合操作简洁,以下是完整实操步骤。
1. 前置准备:连接ChromaDB
本地文件模式最常用,一行代码完成连接:
python
import chromadb # 连接本地ChromaDB,数据存储在./chroma_db目录
client = chromadb.PersistentClient(path="./chroma_db")2. 核心查看操作(3步搞定)
- 查看所有集合:快速列出当前数据库中所有向量集合
python
# 简洁查看
print(client.list_collections())
# 清晰列表展示
for coll in client.list_collections():
print("集合名称:", coll.name)- 查看单个集合基础信息:了解集合名称和数据规模
python
# 替换为你的集合名称
collection = client.get_collection(name="my_collection")
print("集合名称:", collection.name)
print("数据条数:", collection.count())- 查看集合内具体数据:默认返回ID、文本、元数据,需查看向量可添加对应参数
python
# 查看基础数据(ID+文本+元数据)
data = collection.get()
print("数据结构:", data.keys()) # 输出:ids, documents, metadatas
# 查看向量(添加include参数)
data_with_vec = collection.get(include=["embeddings", "documents"])
print("第一条向量维度:", len(data_with_vec['embeddings'][0]))三、总结
向量数据库是AI语义理解的核心基础设施,适配各类非结构化数据的相似性检索场景;ChromaDB作为新手友好型工具,可快速上手实操,助力快速跑通RAG等基础场景。