TL;DR
直接结论:优先看三个数字------BSR集中度(<50%)、平均评论数(<300条)、CPC(<$1.5)。三个都达标再深入调研。
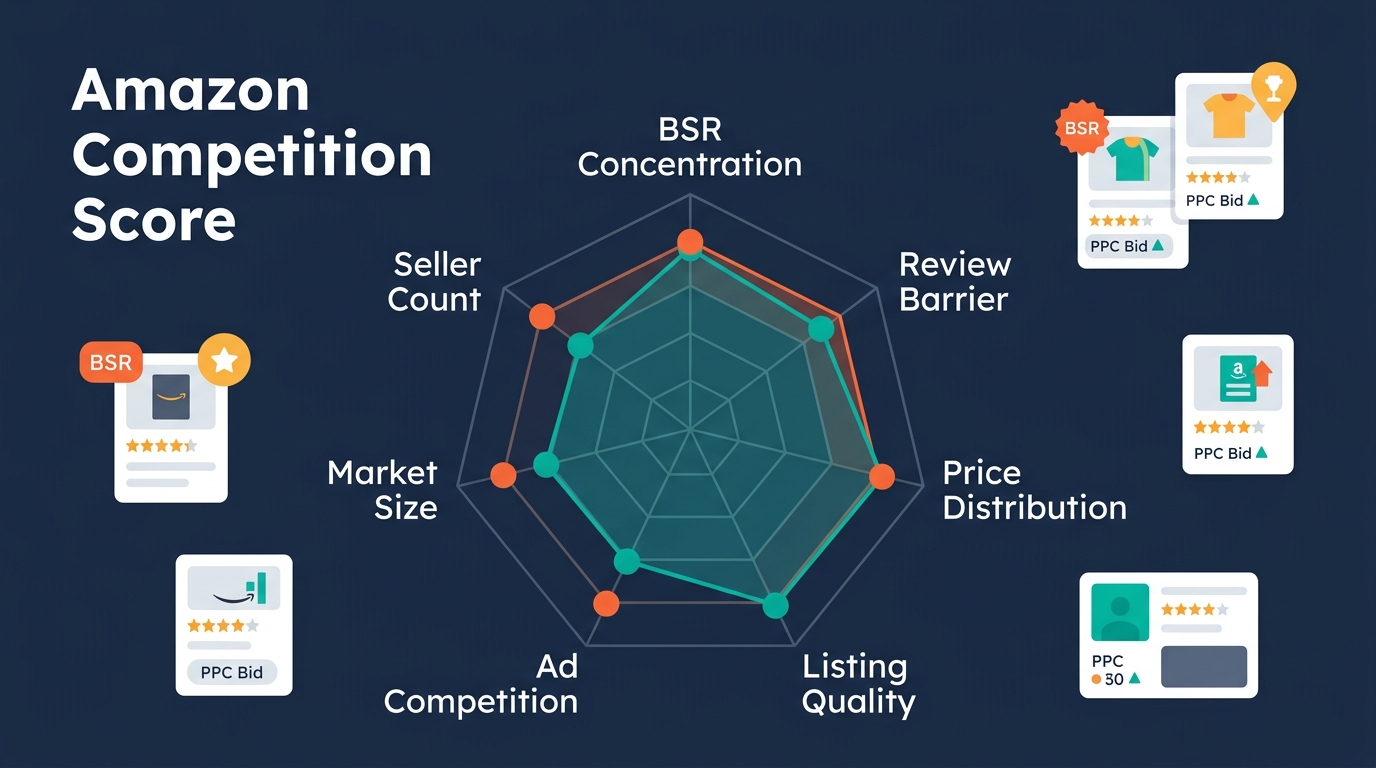
为什么需要7维度而不是1个数字?
销量高不代表竞争度低。Jungle Scout 2025年报告显示,62%以上首年亏损的新卖家主因是高估了在现有竞争格局中能拿到的份额,而不是市场没需求。
7维度框架解决的是:这个竞争结构中,你靠什么维度的差异化赢?
| 维度 | 权重 | 优 (10分) | 中 (5分) | 差 (1分) |
|---|---|---|---|---|
| BSR集中度 | 20% | 前3名<40% | 40-60% | >60% |
| 评论壁垒 | 20% | 均值<200条 | 200-500条 | >500条 |
| 广告竞争 | 20% | CPC<$1.0 | $1-2 | >$2.0 |
| 价格利润 | 15% | 毛利>40% | 25-40% | <25% |
| Listing质量 | 10% | 竞品均分<3 | 3-4分 | >4分 |
| 新品生存率 | 10% | 新品>20% | 10-20% | <10% |
| 市场容量 | 5% | 月销>$500万 | $50-500万 | <$50万 |
异步批量采集实现
python
import asyncio, aiohttp, json
from statistics import mean
from datetime import datetime
from typing import Optional, List
from dataclasses import dataclass
API_KEY = "your_pangolinfo_api_key"
API_BASE = "https://api.pangolinfo.com/v1/amazon"
CONCURRENCY = 8
BSR_TABLE = {100:12000,500:4000,1000:2200,3000:900,5000:600,10000:300,30000:80}
def bsr_to_sales(bsr):
if not bsr: return 0
for k in sorted(BSR_TABLE):
if bsr <= k: return BSR_TABLE[k]
return 5
@dataclass
class Product:
asin: str
bsr: Optional[int]
sales: int
reviews: int
price: float
error: Optional[str] = None
async def fetch_product(session, asin, sem):
async with sem:
try:
async with session.post(f"{API_BASE}/product",
json={"asin": asin, "marketplace": "US"}) as r:
r.raise_for_status()
d = await r.json()
bsr_list = d.get("best_sellers_rank", [])
bsr = bsr_list[0]["rank"] if bsr_list else None
return Product(asin=asin, bsr=bsr, sales=bsr_to_sales(bsr),
reviews=d.get("review_count", 0), price=d.get("price", 0))
except Exception as e:
return Product(asin=asin, bsr=None, sales=0, reviews=0, price=0, error=str(e))
async def get_bestsellers(session, node_id, top_n=50):
async with session.post(f"{API_BASE}/bestsellers",
json={"node_id": node_id, "marketplace": "US"}) as r:
r.raise_for_status()
return [i["asin"] for i in (await r.json()).get("items", [])[:top_n]]
async def analyze(node_id: str) -> dict:
hdrs = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
sem = asyncio.Semaphore(CONCURRENCY)
async with aiohttp.ClientSession(headers=hdrs) as session:
asins = await get_bestsellers(session, node_id)
products: List[Product] = await asyncio.gather(
*[fetch_product(session, a, sem) for a in asins]
)
valid = [p for p in products if not p.error and p.price > 0]
by_s = sorted(valid, key=lambda x: x.sales, reverse=True)
top3 = sum(p.sales for p in by_s[:3])
top10 = sum(p.sales for p in by_s[:10])
conc = top3 / top10 if top10 else 1.0
rev10 = [p.reviews for p in by_s[:10] if p.reviews]
avg_rev = mean(rev10) if rev10 else 0
mkt = sum(p.sales * p.price for p in valid)
bsr_s = 10 if conc < 0.4 else (5 if conc < 0.6 else 1)
rev_s = 10 if avg_rev < 200 else (5 if avg_rev < 500 else 1)
mkt_s = 10 if mkt > 5_000_000 else (5 if mkt > 500_000 else 1)
return {
"node_id": node_id, "analyzed_at": datetime.now().isoformat(),
"bsr_concentration": f"{conc:.1%}", "bsr_score": bsr_s,
"avg_reviews_top10": round(avg_rev), "review_score": rev_s,
"market_usd": round(mkt), "market_score": mkt_s,
"success": f"{len(valid)}/{len(products)}"
}
async def main():
categories = {"Kitchen": "284507", "Sports": "3375251", "Health": "3760901"}
results = {}
for name, nid in categories.items():
results[name] = await analyze(nid)
r = results[name]
print(f"{name}: 集中度={r['bsr_concentration']}, 评论={r['avg_reviews_top10']}, 市场=${r['market_usd']:,}")
with open("competition_async.json", "w") as f:
json.dump(results, f, ensure_ascii=False, indent=2)
asyncio.run(main())关键设计要点
- 并发控制 :
asyncio.Semaphore(8)防止超出API rate limit - 错误隔离:每个ASIN独立try/except,单个失败不影响整体分析
- 多类目并行 :
asyncio.gather在单次event loop完成所有类目分析