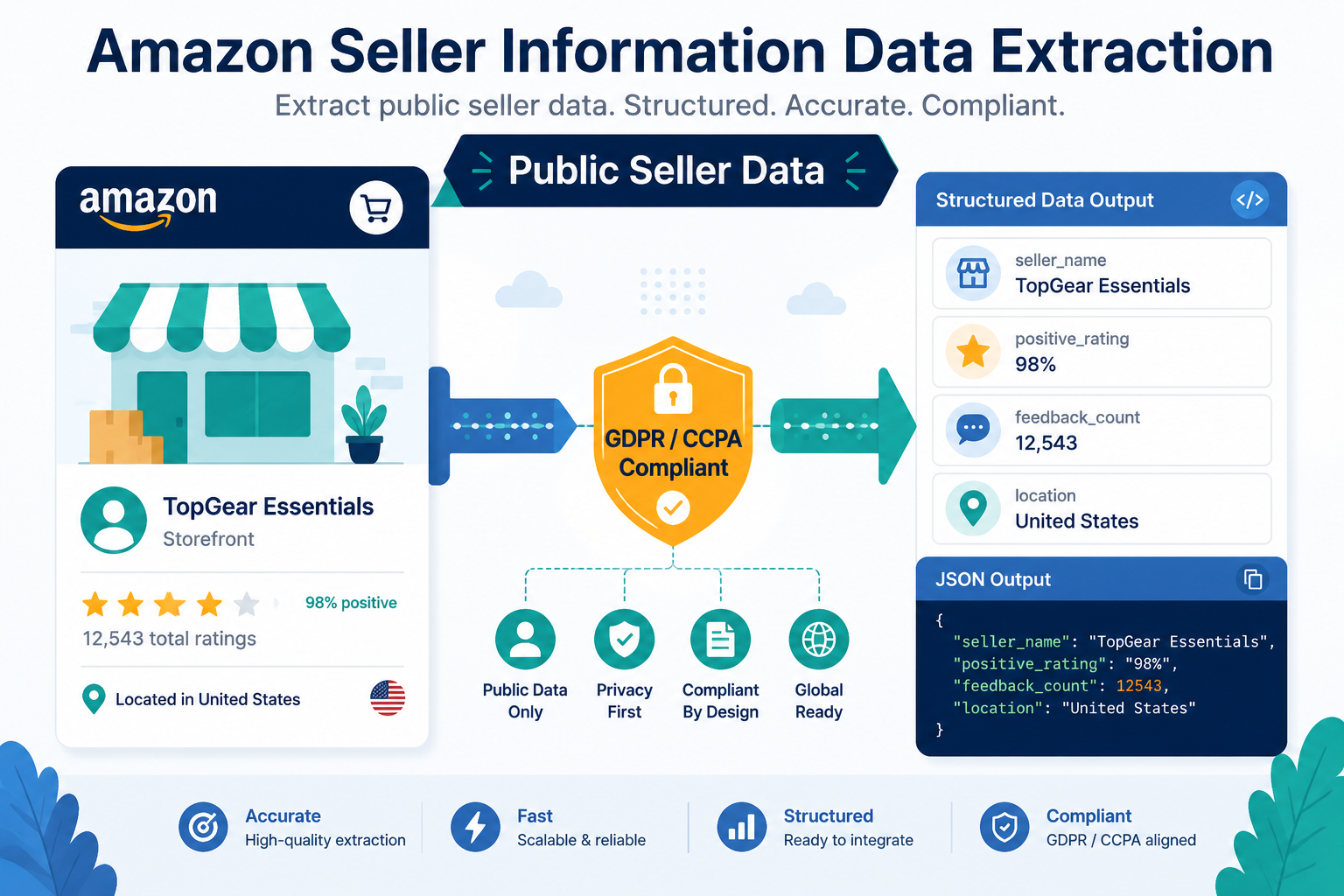
摘要:
批量获取亚马逊(Amazon)第三方卖家的商业名称、信用代码和注册地址等信息,对于跨境 B2B 拓客和供应链分析具有重要意义。然而,亚马逊的 Cloudflare 盾和 Robot 验证码构成了极高的反爬门槛。本文将深度解析亚马逊前台卖家 profile 页面的数据结构,揭示反爬封禁的根本原因,并提供基于 Python 的自建爬虫与第三方专业 Scrape API 的多维度实战方案,同时提供数据脱敏以符合 GDPR 与中国个人信息保护法(PIPL)的工程落地建议。
一、 为什么提取亚马逊卖家公开数据如此艰难?
在构建跨境电商大数据平台时,亚马逊卖家信息数据提取是连接前端 Listing 商品数据与后端真实世界供应链的关键桥梁。然而,几乎所有自建爬虫团队在上线三天内都会遇到以下经典报错:
- HTTP 503 (Service Unavailable / Robot Page): 只要你的请求频次稍快,亚马逊服务器就会拒绝返回商品或店铺的 HTML,取而代之的是一张需要手动输入数字的
Amazon Robot验证码页面。 - HTTP 403 (Forbidden): 目标 IP 已被亚马逊的防火墙拉黑,甚至整段机房 IP 均被 Geoblocking。
- 解析器崩溃(AttributeError / Selector Error): 亚马逊经常针对不同地域的浏览器指纹进行 HTML A/B 测试,导致同一个元素上的 CSS/XPath 选择器失效。
二、 亚马逊前端卖家页面(Seller Profile)数据结构解析
要提取卖家信息,必须首先定位卖家店铺页面的 URL。在亚马逊的规则中,每个第三方卖家都有一个独一无二的 Merchant Token(即 seller_id),其前台店铺 URL 的基本结构如下:
- 美国站:
https://www.amazon.com/sp?seller=A3TXYZ123ABC - 德国站:
https://www.amazon.de/sp?seller=A2ABC456XYZ
点击访问该链接后,在前端渲染出的 HTML 中,我们需要解析的重点结构包括:
- Seller Name (店铺名): 通常包裹在
h1#sellerName内。 - Business Name (企业法定名称): 包裹在包含
Detailed Seller Information或Business Name字段的邻近div节点中。 - Business Address (注册地址): 包含国家代码、省份、城市、街道等,通常位于
span或div容器中。 - Unified Social Credit Identifier (统一社会信用代码/营业执照号): 对于中国出海卖家,这是由 18 位数字和字母组成的信用代码(通常在
Business Representative / Registry Number下面展示)。
三、 自建爬虫的痛点与局限(Scrapy / Puppeteer 方案分析)
如果选择从零构建爬虫,开发者通常会采用以下策略,但它们都伴随着高昂的总体拥有成本(TCO):
1. 动态住宅代理轮换 (IP Proxy Rotation)
亚马逊会迅速根据 IP 的历史请求信誉进行画像。数据中心(机房)IP 的爬取通过率低于 5%。你必须集成第三方代理服务,将爬虫伪装成世界各地的普通家用宽带,并在每次请求前切换代理:
python
# 代理集成配置示例
proxies = {
"http": "http://user:password@residential.proxy-provider.com:8000",
"https": "http://user:password@residential.proxy-provider.com:8000"
}痛点: 住宅代理按流量计费(通常是 3-15 美元/GB),大规模爬取的资金损耗极大。
2. 绕过 Cloudflare 与 JA3 指纹检测
现代防爬系统不仅看你的请求头(User-Agent),还会通过握手阶段分析你的 TLS 指纹(JA3 指纹)。如果使用 Python 的默认 requests 库,指纹暴露非常明显,必须使用特制的库如 curl_cffi 伪装成真实的 Chrome 客户端握手协议。
四、 极简且稳健的替代方案:Pangolinfo Scrape API 接入
为了避开住宅 IP 的采购和高难度的反爬对抗,接入成熟的第三方电商 API 是企业目前更主流的技术选型。
Pangolinfo Scrape API提供云端的亚马逊卖家数据抓取支持。它不仅支持全球 15+ 亚马逊站点,还能够免除代理和打码烦恼,直接获取结构化好的 JSON 格式数据。
对于正在开发电商 AI 智能代理(AI Agents)的团队,可以通过集成的 Pangolinfo Amazon Scraper Skill,通过 MCP 协议轻松实现卖家数据的无缝查询。
五、 Python 实战:批量提取与数据脱敏完整代码
以下是使用 Python 调用 Pangolinfo API 获取卖家信息并进行 GDPR/PIPL 合规数据清洗的完整代码。
python
import requests
import json
import re
# 申请的 Pangolinfo API 凭证
API_KEY = "YOUR_PANGOLINFO_API_KEY_HERE"
API_URL = "https://api.pangolinfo.com/v1/amazon/seller"
def fetch_seller_data(seller_id, marketplace="US"):
"""
通过 Pangolinfo API 批量提取亚马逊卖家店铺数据
"""
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
payload = {
"seller_id": seller_id,
"marketplace": marketplace
}
try:
response = requests.post(API_URL, headers=headers, json=payload, timeout=15)
if response.status_code == 200:
return response.json()
else:
print(f"Error [{response.status_code}]: {response.text}")
return None
except Exception as e:
print(f"Request Exception: {str(e)}")
return None
def complies_with_privacy(seller_name, business_name, address):
"""
判断该卖家是否为个人/个体工商户,用于合规性校验。
在 GDPR/PIPL 下,自然人的姓名和住宅地址(若注册为卖家)属于个人隐私敏感信息。
"""
# 识别中国企业常见的后缀如: 有限公司, 厂, 店等。
# 如果公司名称仅为个人姓名,或者地址与普通住宅格式极为相似,则需要预警。
corporate_patterns = r"(有限公司|有限责任公司|科技|商贸|制品|厂|Co\., Ltd\.|LLC|Inc\.|Corp\.)"
if not business_name:
return False
if not re.search(corporate_patterns, business_name):
# 可能是个体工商户或个人独资主体,存在个人信息(PII)暴露风险
return False
return True
def sanitize_seller_pii(seller_data):
"""
数据脱敏函数:
在 GDPR 和 PIPL 规范下,对可能为个人隐私数据的住宅地址进行掩码脱敏处理。
"""
business_name = seller_data.get("business_name", "")
address = seller_data.get("business_address", "")
if not complies_with_privacy(seller_data.get("seller_name"), business_name, address):
print(f"[合规警示] 卖家 '{business_name}' 可能为个体工商户/自然人主体,启动脱敏逻辑。")
# 掩码敏感地址(保留国家和省份,屏蔽具体门牌号)
# 示例:'广东省深圳市宝安区西乡街道XX小区X栋' -> '广东省深圳市宝安区******'
if len(address) > 10:
seller_data["business_address"] = address[:10] + "******"
else:
seller_data["business_address"] = "****** (敏感数据已屏蔽)"
return seller_data
if __name__ == "__main__":
# 模拟批量提取
target_sellers = [
{"id": "A3TXYZ123ABC", "site": "US"},
{"id": "A1S5O8XJ91KJ", "site": "DE"}
]
for seller in target_sellers:
print(f"\n正在抓取卖家 ID: {seller['id']} ...")
raw_data = fetch_seller_data(seller["id"], seller["site"])
if raw_data:
# 运行隐私清洗逻辑,保障数据库存储合规
safe_data = sanitize_seller_pii(raw_data)
print("合规提取结果:")
print(json.dumps(safe_data, indent=4, ensure_ascii=False))六、 开发者合规小贴士
在实际业务中使用这套代码时,请遵守以下安全生产原则:
- 脱敏持久化: 在写入公司的 MySQL 或 MongoDB 数据库前,必须确认非企业类法人(自然人主体)的详细地址已被脱敏处理。
- 避免滥用联系电话: 即使部分前端页面公开了电话(如欧区站点),如果该电话是个人的私人号码,切勿将其直接导入电话外呼系统(如 CRM 自动拨号),这在 GDPR 法区下会产生极其严重的合规诉讼风险。
- 遵守合理请求频率: 即便是调用 API 服务,也建议在自己的调度层(如 Celery / Redis Queue)添加流控逻辑,避免对同一卖家进行瞬时高并发请求。
七、 总结
在数据分析的汪洋中,真正拉开技术团队差距的,不仅是数据获取的速度,更是数据合规的厚度。
在大数据的时代洪流中,真正拉开跨境企业差距的,不仅是获取公开数据的技术速度,更是深谙合规边界、将海量信息转化为敏捷决策的商业智慧。