导读
铁路安全是交通运输的重中之重,但相比于自动驾驶,铁路环境感知研究因数据稀缺、标注困难而进展缓慢。
意大利圣安娜高等研究学院团队提出了一套模块化、多传感器融合的障碍物检测框架,整合了轨道分割、目标检测与单目深度估计,并利用LiDAR点云对深度图进行校正,实现了在200米范围内平均绝对误差仅0.63米的距离估计。该框架在合成数据集SynDRA上取得了YOLOv11x分割模型mAP@50=0.78、轨道分割IoU=0.94的优异性能,为铁路安全预警提供了灵活可扩展的解决方案。
论文信息
- 标题:Integrating Object Detection, LiDAR-Enhanced Depth Estimation, and Segmentation Models for Railway Environments
- 作者:Enrico F. Giannico, Federico Nesti, Gianluca D'Amico, Mauro Marinoni, Edoardo Carosio, Filippo Salotti, Salvatore Sabina, Giorgio Buttazzo
- 机构:意大利圣安娜高等研究学院(Scuola Superiore Sant'Anna)及Progress Rail Signaling
- 论文链接:arxiv.org/pdf/2604.14...
一、铁路环境感知的独特挑战
铁路事故统计(Eurostat)表明,碰撞主要源于晚检测而非基础设施或车辆故障。列车高速行驶时制动距离常超过传感器可视范围,但在低速场景(车站、调车场、平交道口),车载障碍物检测可有效提醒驾驶员,提升安全性。
然而,铁路领域面临三大瓶颈:
- 数据稀缺:绝大多数数据集未公开,且缺乏距离真值标注;
- 任务孤立:现有工作大多仅处理检测、轨道识别或距离估计中的单个任务;
- 精度瓶颈:基于边界框的距离估计易混入背景像素,且单目深度估计常为相对值,难以直接应用。
为解决上述问题,团队提出了一个模块化、异构网络可替换的多传感器融合框架,统一完成轨道分割、障碍物检测和绝对距离估计,并使用合成数据集SynDRA提供密集深度真值进行定量评估。
二、模块化多传感器融合框架
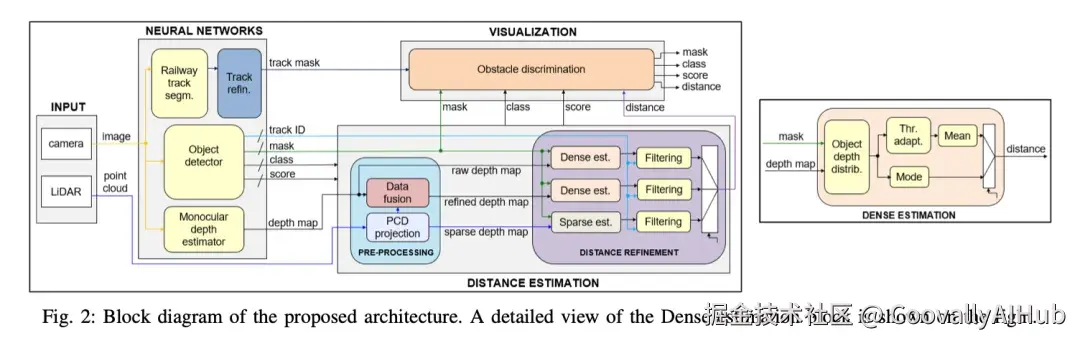
2.1 系统架构概览
系统包含四个主要模块:
- 输入模块:单目相机 + 多个LiDAR(左、中、右),提供RGB图像和点云。
- 神经网络模块:三个并行网络(轨道分割、目标检测与分割、单目深度估计)处理同一帧RGB图像。
- 距离估计模块:融合深度图与LiDAR点云,计算每个分割掩膜内目标的绝对距离。
- 可视化模块:在驾驶室显示潜在障碍物及其类别、置信度和距离。
 图片来源于原论文
图片来源于原论文
2.2 关键神经网络
| 任务 | 选用模型 | 说明 |
|---|---|---|
| 轨道分割 | DDRNet23-Slim | 轻量级双分辨率架构,微调后输出二值掩膜(轨道/非轨道) |
| 目标检测+分割 | YOLOv11x-seg | 输出实例分割掩膜而非边界框;配合BoT-SORT跟踪器获得时序ID |
| 单目深度估计 | MiDaS v3.1 (Swin2L-384) | 原为相对深度,通过SynDRA数据集微调转化为绝对深度 |
2.3 距离估计模块
LiDAR点云投影到图像平面,生成稀疏深度图。首先计算每个投影点的深度残差:
其中 (d_i) 为LiDAR测量深度,(D_m) 为单目深度估计值。稀疏残差通过线性插值得到稠密残差图 (R(x,y)),最终得到修正深度图:
对于每个物体的分割掩膜 R,距离估计算法如下:
- 稀疏估计(仅LiDAR):取掩膜内深度值的众数(mode)。
- 稠密估计 (单目或修正图):可采用众数,或更保守的阈值均值------取掩膜内最小的 (k%) 深度值的均值。
最后,利用YOLO跟踪器提供的ID,对每个物体维持一个滑动窗口,对窗口内的距离估计进行加权平均(较新帧权重更高),从而滤除时序噪声。
三、实验设置与数据集
3.1 使用的数据集
| 数据集 | 用途 | 备注 |
|---|---|---|
| RailSem19 | 轨道分割微调与评估 | 转换为二值掩膜 |
| OSDaR23 | 轨道分割评估 | 真实场景 |
| COCO | 目标检测微调 | 原始80类映射为6个铁路相关超类 |
| OSDaR-AR | 目标检测评估 | 增强现实插入外部物体(牛、象、马、行人) |
| SynDRA (depth split) | 深度估计微调 | 1339帧 + 密集深度真值 |
| SynDRA (evaluation split) | 全套系统评估 | 四种场景:乡村、城市、车站、调车场,约2000帧/场景,含RGB、深度、LiDAR、标注 |
3.2 模型微调关键参数
- DDRNet23-Slim:30 epochs,Adam lr=0.001,二分类。
- YOLOv11x-seg:5 epochs,lr=0.01,输入640×640,联合检测与分割。
- MiDaS v3.1 :若干epoch,Adam lr=0.001,采用加权MSE损失以强调近处精度。三种权重策略:
-
- 阈值加权:深度 < T=200m 时权重1.0,>200m 时权重0.1;
- 线性衰减:从 T=200m 处权重1.0线性衰减至最大深度655m处权重0.1;
- 频率加权:按深度区间像素频率倒数赋权。
损失函数形式为:
四、性能评估与结果分析
4.1 微调模型性能
| 模型 | 指标 | 数值 |
|---|---|---|
| DDRNet23-Slim (OSDaR23) | Accuracy / IoU / Precision / Recall | 0.99 / 0.94 / 0.99 / 0.95 |
| YOLOv11x-seg (COCO) | mAP@50 / mAP@50-95 | 0.78 / 0.51 |
| MiDaS v3.1 (SynDRA) | MAE (阈值法) 整体0-655m | 41.5m |
| MAE (阈值法) 0-200m / 200-300m / 300-655m | 12.2m/ 46.7m / 94.4m | |
| MAE (线性衰减) 200-300m 最优 | 33.7m | |
| MAE (频率加权) 300-655m 最优 | 42.8m |
4.2 检测性能(SynDRA场景,YOLOv11x无跟踪)
| 场景 | 类别 | TPR (%) | IoU@0.5 |
|---|---|---|---|
| 乡村 | 人 | 88.5 | 0.60 |
| 乡村 | 车辆 | 21.7 | 0.87 |
| 乡村 | 动物 | 47.7 | 0.69 |
| 调车场 | 人 | 78.5 | 0.68 |
| 调车场 | 列车 | 98.3 | 0.89 |
| 车站 | 人 | 72.6 | 0.64 |
| 车站 | 工具 | 4.9 | 0.83 |
| 城市 | 人 | 86.7 | 0.62 |
| 城市 | 车辆 | 67.0 | 0.75 |
| 城市 | 动物 | 58.5 | 0.67 |
列车检测率最高(98.7%),工具类因体积小、异质性强而检测困难。跟踪器(BoT-SORT)对TPR影响极小。
 图片来源于原论文
图片来源于原论文
4.3 距离估计精度对比
实验比较了三种深度源:LiDAR稀疏图、MiDaS原始稠密图、MiDaS+LiDAR修正稠密图。不同估计策略的MAE结果:
| 深度源 | 策略 | 整体MAE | 关键发现 |
|---|---|---|---|
| LiDAR稀疏(众数) | 众数 | 极低 | 最可靠,但稀疏 |
| MiDaS原始(众数) | 众数 | 高 | 噪声大,但绝对化后可用 |
| MiDaS+LiDAR修正(众数) | 众数 | 接近LiDAR | 精度与稠密兼具 |
| MiDaS+LiDAR修正(阈值均值 k=30%) | 均值(最小30%) | 略高于众数 | 保守估计,适合安全场景 |
最终,融合后系统在200米内的距离估计平均绝对误差可低至0.63米。
4.4 处理时间
| 配置 | 每帧时间 (ms) |
|---|---|
| 仅MiDaS原始深度 | 440.35 |
| + LiDAR点云投影+模拟噪声 | 855.05 |
| + 深度图修正(线性插值) | 1703.18 |
当前实现未做任何硬件级优化(如TensorRT、量化、流水线并行),为Python串行版本,具有较大优化空间。
五、总结与未来展望
本工作提出了一个面向铁路环境的模块化障碍物检测框架,具有以下亮点:
- 统一且灵活:可替换任意目标检测、深度估计或分割骨干网络;
- 深度融合:用LiDAR点云计算残差并线性插值,将相对深度转换为绝对深度,精度大幅提升;
- 时序稳定性:利用跟踪器对距离估计进行滑动窗口加权平均,减少帧间抖动;
- 可评估性:使用合成数据集SynDRA提供真值,首次在铁路场景下实现了距离估计的定量对比。
局限与未来方向:
- 当前处理速度约1.7秒/帧,需要优化以满足实时性要求;
- 轨道分割在急弯或陡坡时精度下降,需改进模型或引入惯性传感器;
- 仅对低速场景(<30km/h)有效,高速下制动距离超视距问题仍待解决;
- 可探索端到端联合训练、多模态Transformer以及更高效的深度细化方法。