自动化测试概念
自动化: 自动代替人为完成操作 ; (例如: 自动化浇水, 自动开门..)
自动化的目的是为了进行 回归测试
回归测试
软件有多个版本需要进行功能的整体回归, 为了避免新增的功能影响 历史功能 需要进行功能的 回归 ;
例如: 1. 软件推出版本1=> 有很多功能 测试人员对版本1进行测试,=> 编写 自动化测试脚本1 (专门测试现在新功能的脚本) 2. 开发出版本2=> 有新功能 ; 只需要测试新功能, 旧功能交给自动化测试1=> 根据新功能又有 自动化测试2 ; 3. 开发出 版本2=> 有新功能 只需要测试新功能, 旧功能只需要交给自动化测试2 => 根据新功能又有 自动化测试3 ; .......
这样软件开发出新的功能, 那么旧的功能 不需要 人为手动去测试, 而是交给自动化测试 ;
面试题(重点)
1. 自动化测试 能取代人工测试码?
当然不能,自动化测试不一定比 人工测试 更能保证系统的可靠性 , 自动化测试是 测试人员编写的 , 后续也要随着功能的改变自动化有需要进行维护和更新 ;
2. 自动化测试可以大幅度降低工作量
错误的 , 大幅度(太绝对了) , 只是可以一定程度上 降低工作量(大部分还是需要人工来)
自动化分类
自动化是一个统称包含多种: 接口自动化 , UI自动化 web自动化 , 客户端自动化,移动端自动化 ...
接口自动化
测试 接口的请求,返回,URL等是否满足预期 ;
UI自动化
UI测试也称为 界面测试 (web界面 , 客户端界面) ; 常见的UI测试 包括: web自动化测试 , 移动端自动化测试 .....
这里我们主要用的也是 web界面自动化测试
web自动化测试
什么事web自动化测试: 我们使用浏览器来搜索东西的步骤 , web自动化能够帮我们自动实现 ;
(模拟人在浏览器上的操作: 打开浏览器=>访问搜索页面=> 进行搜索操作..)
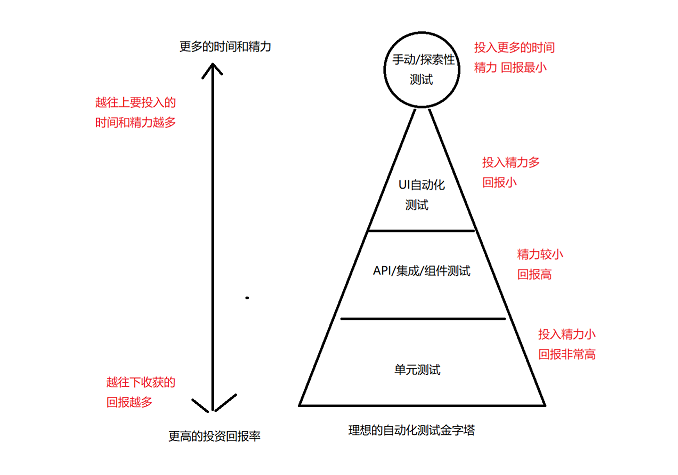
自动化测试金字塔
自动化测试有种, 什么类型的测试收益最好 ;
理想的自动化测试金字塔
理想的自动化测试金字塔: 在手动的探索测试, 投入时间更多,精力回报最小
而单元测试, 投入时间小, 但回报非常高 (单元: 人来规定的,可以是一个方法, 类, 接口....)
理想的自动化测试金字塔 只需要用较小的精力 就可以 通过 单元测试 发现更多有效的问题
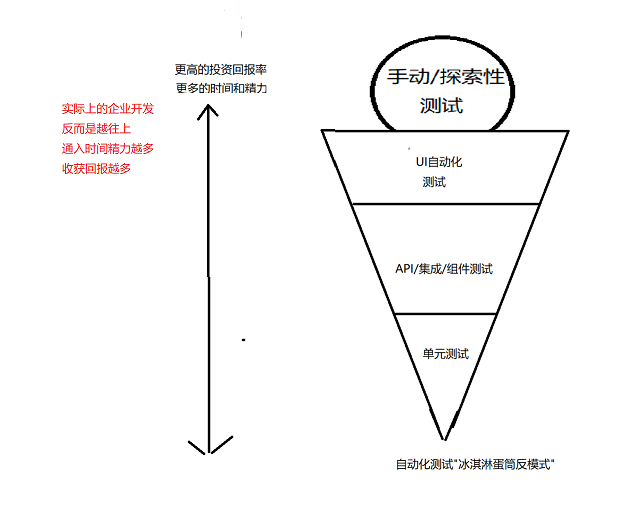
冰淇淋蛋筒反模式
-
在实际企业开发中 反而是 手工测试阶段 越能发现更多的问题,投入精力越大
-
其次是前端自动化, 可以发现的问题 相比与接口自动化发现问题 跟多 (因为后端的问题都会体现到前端上)
-
接口自动化(关注根据请求检查响应结果)
-
单元测试, 则基本是 走个形式 (因为开发人员,一般不能又关注开发,还要编写测试)
-
自动化,也需要大量的初始投资, 找到 "突破点" , 相比手动测试 ,在长期来说是积极的 , 所以 自动化和手工测试 都是完全兼容的
web自动化测试
通过 web自动化 来模拟 人工做的 操作 ;
驱动
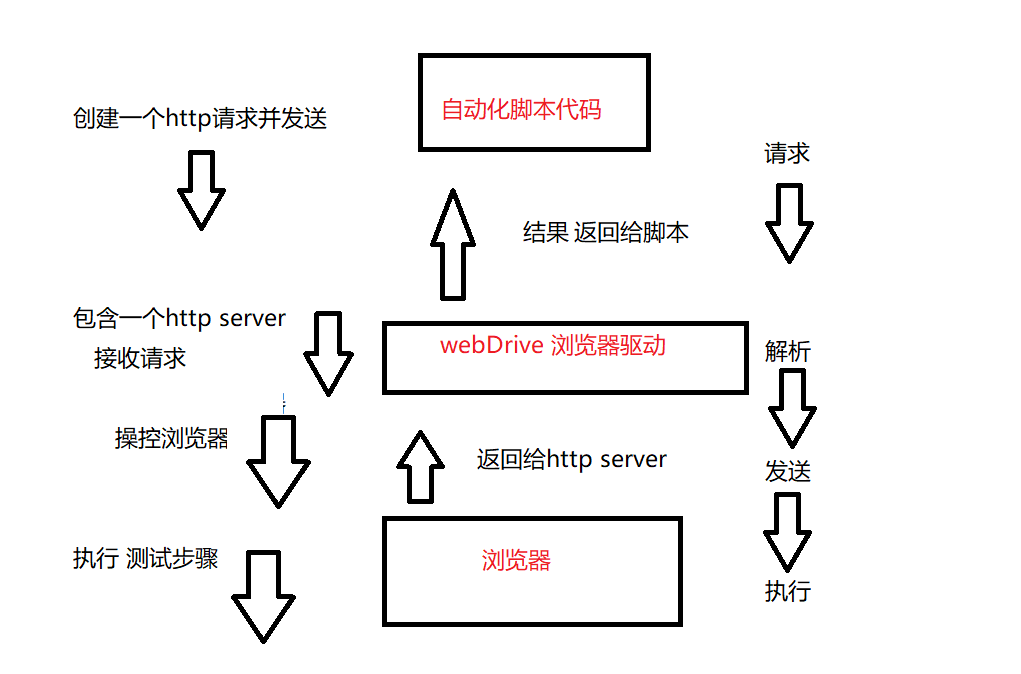
web自动化测试的前提是,能够自动化的打开浏览器, 通过访问web服务器 来对 服务器界面进行一系列操作
程序就序通过 驱动 来打开浏览器 ,并且执行一系列操作 (类似于要使用鼠标键盘等都需要有 驱动才能用)
WebDriverManager(驱动管理)
WebDriverManager 是 开源Java库, 通过完全自动化的方式 对 Selenium WebDrive所需的驱动程序 进行管理 ;
//依赖 <dependency> <groupId>io.github.bonigarcia</groupId> <artifactId>webdrivermanager</artifactId> <version>5.8.0</version> <scope>test</scope> </dependency>
Selenium
Selenium 是 web自动化测试工具, 提供方法来进行web自动化测试 (通过Selenium来编写web自动化测试脚本)
// 依赖 <dependency> <groupId>org.seleniumhq.selenium</groupId> <artifactId>selenium-java</artifactId> <version>4.0.0</version> </dependency>
自动化测试
public void t1() throws InterruptedException { // 1. 驱动程序管理的自动化 对于谷歌浏览器驱动的自动化管理 WebDriverManager.chromedriver().setup(); // 2. 增加浏览器配置 :创建驱动对象要强制指定 允许访问多有链接 // 允许访问所有连接 (打开才能访问百度地址) ChromeOptions options = new ChromeOptions() ; options.addArguments("--remote-allow-origins=*"); // 3. 打开浏览器 WebDriver driver = new ChromeDriver(options); // 暂停3秒方便观看 Thread.sleep(3000); // 4. 输入百度地址 driver.get("https://www.baidu.com"); // 暂停3秒方便观看 Thread.sleep(3000); //5. 找到百度输入框 并且输入 "自动化测试" driver.findElement(By.xpath("//*[@id=\"kw\"]")).sendKeys("自动化测试"); // 暂停3秒方便观看 Thread.sleep(3000); // 6. 找到"百度一下" 按钮 , 点击搜索 driver.findElement(By.xpath("//*[@id=\"su\"]")).click(); // 暂停3秒方便观看 Thread.sleep(3000); //7.关闭浏览器 driver.quit(); } // 通过测试调用上面的t1方法 ; @Test public void t1() throws InterruptedException { WebTest webTest = new WebTest() ; webTest.t1(); System.out.println(111); }
添加指定类加载的路径
<build> <plugins> <plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>exec-maven-plugin</artifactId> <configuration> <mainClass>Test1</mainClass> // 主类加载的路径从test目录下找 <!-- 指定从测试类路径加载 --> <classpathScope>test</classpathScope> </configuration> </plugin> </plugins> </build>
Selenium + 驱动 +浏览器的工作原理
// 加个slf4j 方便查看 <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-jdk14</artifactId> <version>2.0.7</version> </dependency>
引入Junit的依赖方便测试
<dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.11</version> <scope>test</scope> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.11</version> <scope>compile</scope> </dependency>
自动化测试常用函数
元素定位
1.CssSelector (选择器)
通过选择器来选中页面指定的标签元素 ; (通过 id 或 子类选择器进行元素的定位)
// id选择定位 例如: 定位百度搜索按钮: #su // 子类选择器. 定位百度热搜 // 根据子类一层一层选择 #s-hotsearch-wrapper > div > a.hot-title > div > i.c-icon.hot-title-icon
2.XPath (路径)
xml 路径语言, 不仅可以在 xml文件中 查照信息 , 也可以在html中选取结点 ;
获取HTML所有节点
//*
获取HTML指定节点
//[指定节点] 例如: //input 获取所有input节点 //*[@id="kw"] 获取id为kw的节点
获取节点的 直接子节点
/ 获取直接子节点 例如: 获取id为form元素下的 第一个span , 第一个i //*[@id="form"]/span[1]/i[1]
获取节点的 父节点
.. 获取父节点 例如: 获取input节点的父节点 //input/..
实现节点属性的 匹配
[@...] 匹配节点的属性 例如: //*[@value=8] 匹配属性value=8的节点 //*[@id="kw"] 获取id为kw的节点
通过索引的方式获取对应节点的内容
XPath 的索引是 从 1 开始
[1] 获取第一个 例如: 获取id为form元素下的 第一个span , 第一个i //*[@id="form"]/span[1]/i[1]
操作测试元素
根据上面的选择器选择页面元素后, 就可以通过各种方法 , 操作 元素 ;
1.模拟点击 : click()
// 百度首页的百度一下按钮, id是 su , // 通过 findElement() 方法搜索 页面元素 // By 设置查照元素用 什么 选择器 // .click() 模拟点击 driver.findElement(By.cssSelector("#su")).click();
2.模拟键盘输入: sendKeys()
// 百度首页的输入框 id是 kw , // 搜出来输入框, 然后通过 sendKeys() 模拟输入陶喆, 然后点击 百度一下按钮, 搜索陶喆 driver.findElement(By.cssSelector("#kw")).sendKeys("陶喆"); driver.findElement(By.cssSelector("#su")).click();
3.清除文本内容: clear()
// 当文本框里 有内容后 , 后面在 跟 sendKeys() 是会将新输入的内容, // 加在 输入框里的内容 的 后面 // 所以 在输入框里输入的内容不正确, 想重新输入新的内容, 通过 clear(),清空输入框里的内容 // 再通过sendKeys() 输入新内容 输入陶喆后 , 清空 , 搜索 周杰伦 driver.findElement(By.cssSelector("#kw")).sendKeys("陶喆"); driver.findElement(By.cssSelector("#kw")).clear(); driver.findElement(By.cssSelector("#kw")).sendKeys("周杰伦"); driver.findElement(By.cssSelector("#su")).click();
4.获取文本信息: getText()
判断获取到的元素 对应的文本内容是否符合预期
// 这里的文本是 <span> 文本 <span> 的文本 , 如果是 <title value="文本"> 这样的 属于是标签属性的内容 String text = driver.findElement(By.cssSelector("#hotsearch-content-wrapper > li:nth-child(3) > a")).getText(); System.out.println("获取到的内容: "+text);
5.获取当前页面的标题: getTitle()
获取到当前标签页的标题 ;
// 获取到标题: 百度一下, 你就知道 String text = driver.getTitle() ; System.out.println("获取到的标题: "+text);
6.获取当前标签页的URL: getCurrentUrl()
获取百度首页的url String text = driver.getCurrentUrl() ; System.out.println("获取到的内容: "+text);

窗口
当打开一个新的页面时, 在新的标签页里,我们可以看到新的元素,可以在新页面上 操作 ;
但是程序,不行, 程序手里还是拿的旧的标签页的 句柄
切换窗口
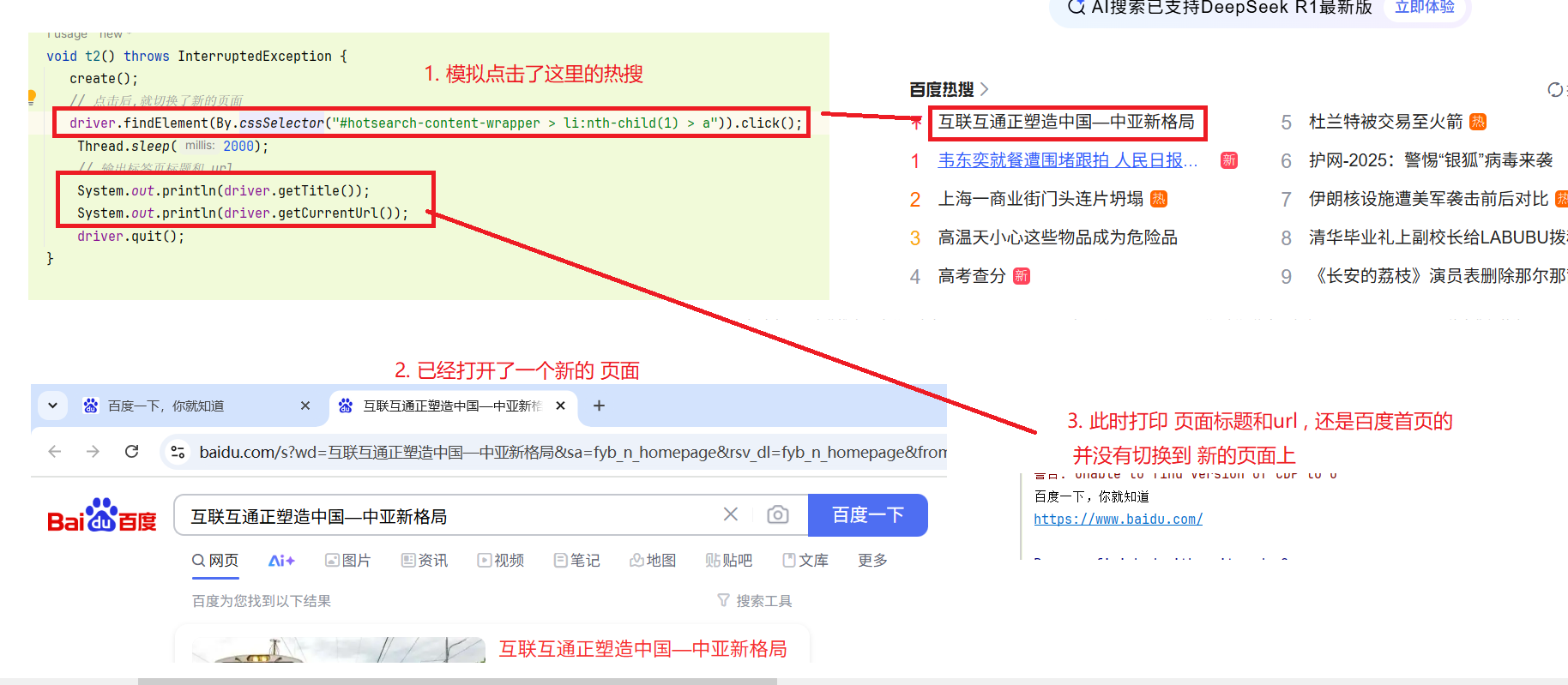
1.获取当前页面句柄: getWindowHandle() ;
当打开了一个新的页面后 , 虽然我们可以看到已经出现新页面了 但是 driver 手里还是拿着 就页面的 句柄 System.out.println(driver.getWindowHandle()); // 点击后,就切换了新的页面 driver.findElement(By.cssSelector("#hotsearch-content-wrapper > li:nth-child(1) > a")).click(); Thread.sleep(2000); // 输出标签页标题和 url System.out.println(driver.getWindowHandle()); // 最后输出的句柄一样 B3313DFFA505E60BDD9F5CE66995FDFB B3313DFFA505E60BDD9F5CE66995FDFB
2.获取当前所有页面的句柄: getWindowHandles() ;
// 获取浏览器现在打开的所以页面的句柄
3.切换当前driver的句柄: driver.switchTo().window(页面句柄)
// 一般来说, 测试中不会打开多个页面, 要切换到最新的页面, // 需要获取 所有的 页面句柄, 然后遍历 , 如果有句柄和当前的句柄不一样 // 就代表这个不同的句柄是最新的页面, 所以可以切换到这个句柄, 这样来实现 // 将当前句柄切换到最新页面 ; 在百度首页, 点击热搜后 , 出现新页面 // 点击后,就打开了新的页面 driver.findElement(By.cssSelector("#hotsearch-content-wrapper > li:nth-child(1) > a")).click(); Thread.sleep(2000); 将当前句柄, 切换到最新的页面 //获取 所有句柄 Set<String> windowHandles = driver.getWindowHandles(); for(String win : windowHandles){ // 如果当前driver手上的句柄 和 这个句柄不一样, 就切换 if(!driver.getWindowHandle().equals(win)){ driver.switchTo().window(win); } } // 输出标签页标题和 url System.out.println(driver.getTitle()); System.out.println(driver.getCurrentUrl());
此时 句柄就已经切换到新的页面上了

关闭窗口
driver.close() 关闭当前的标签页
在百度首页, 点击热搜,打开新窗口, 然后切换到新窗口的句柄 , 关闭新窗口 ; 此时就只剩下一个 百度首页, 新打开的页面已经 通过close() 关闭掉了
// 点击后,就打开了新的页面 driver.findElement(By.cssSelector("#hotsearch-content-wrapper > li:nth-child(1) > a")).click(); Thread.sleep(2000); //获取 所有句柄 Set<String> windowHandles = driver.getWindowHandles(); for(String win : windowHandles){ // 如果当前driver手上的句柄 和 这个句柄不一样, 就切换 if(!driver.getWindowHandle().equals(win)){ driver.switchTo().window(win); } } // 输出标签页标题和 url System.out.println(driver.getTitle()); System.out.println(driver.getCurrentUrl()); Thread.sleep(3000); // 关闭新窗口 driver.close();
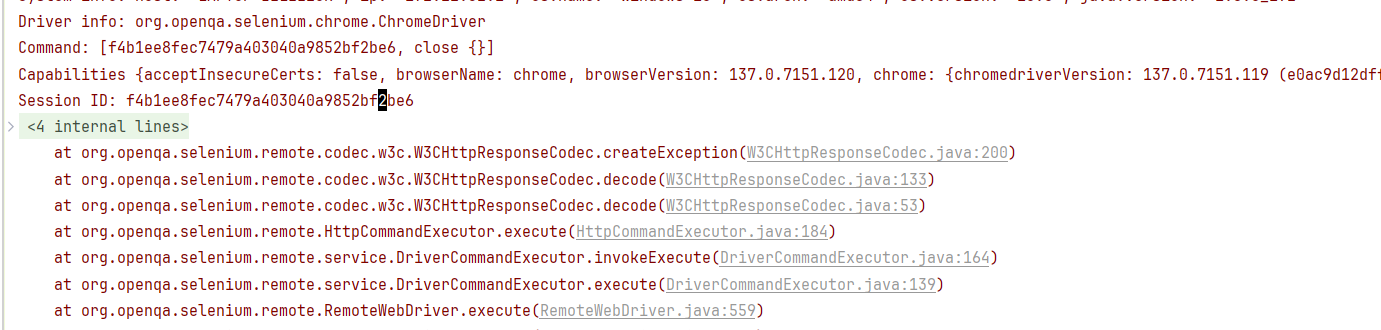
关闭页面后,无法直接在关闭
// 当通过 close 关闭掉 新的窗口后 , 在执行close关闭后 报错 ; driver.close(); Thread.sleep(3000); driver.close();
注意句柄的切换
-
因为前面通过了切换句柄, 切换到最新的页面
-
然后通过close()关闭了 页面 , 再调用close() 报错
-
因为 此时 driver 手里的句柄 , 还是热搜页面 , 但是热搜页面已经 关闭了 ,不存在这个页面了
-
所以 需要 更换句柄 将 ,句柄切换回 百度首页的页面 (前面已经保存了 所有页面的句柄)
// 继续通过切换句柄 for(String win : windowHandles){ // 如果当前driver手上的句柄 和 这个句柄不一样, 就切换 if(!driver.getWindowHandle().equals(win)){ driver.switchTo().window(win); } }
窗口大小设置
窗口最大化/最小化/全屏/指定大小
// 将浏览器窗口最小化 driver.manage().window().minimize() ; // 窗口最大化 driver.manage().window().maximize(); // 窗口全屏 driver.manage().window().fullscreen(); // 设置窗口大小 driver.manage().window().setSize(new Dimension(500 , 600));
屏幕截屏
使用自动化脚本时,如果发生报错 通过 截屏来, 查看当时发生错误的 页面时 什么样子的
屏幕截屏依赖 <dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifactId> <version>2.6</version> </dependency>
在百度首页截图 , 截图后保存文件 my.png // 获取截图 File file = ((TakesScreenshot)driver).getScreenshotAs(OutputType.FILE); // 创建出截图文件 FileUtils.copyFile(file , new File("my.png"));
可以看到截图文件 ;
进阶版
测试用例截图 可能成百上千, 这么多堆在一起 , 非常难找 所以 测试截图分
日期/测试方法名+时间 的目录形式存储 ; (时间要精确到 毫秒 也就是 : yyMMdd:HHmmssSS , 年月日,时分秒 毫秒 , 毫秒用SS ;
//日期: 做目录, 不同日期不同目录
// 时分秒毫秒: 分 不同的截图文件
最后的截图文件名: 方法名+时分秒毫秒.png
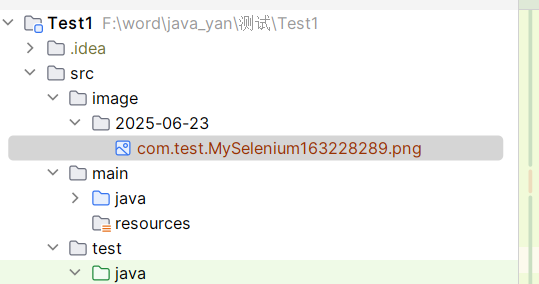
void t4() throws InterruptedException, IOException { create(); getTakeScreenShot(getClass().getName()); // 通过反射,获取当前测试类的名字 Thread.sleep(2000); driver.quit(); } void getTakeScreenShot(String str) throws IOException { // 获取截图 File file = ((TakesScreenshot)driver).getScreenshotAs(OutputType.FILE); // 创建出截图文件 // 年月日 格式 SimpleDateFormat s1 = new SimpleDateFormat("yyyy-MM-dd") ; // 时分秒毫秒 格式 SimpleDateFormat s2 = new SimpleDateFormat("HHmmssSS") ; // 通过当前时间来获取 时间 , 并且按上面的 格式来 // 日期: 年月日 , 用来分目录 String dirTime = s1.format(System.currentTimeMillis()) ; // 截图文件名称, 时分秒毫秒, String fileTime = s2.format(System.currentTimeMillis()) ; // 最后文件存放在 src/image/yyyy-MM-dd/ 方法名 + HHmmssSS .png 文件 String fileName = "src/image/" + dirTime +"/" + str + fileTime +".png"; FileUtils.copyFile(file , new File(fileName)); }
最后 图片截图文件为
等待
一般代码的执行速度要比 页面渲染的速度要快 : 当页面还没渲染完, 代码就通过 findElement() 查找元素来进行操作 , 就会报错
因为元素还没渲染出来 , 代码就已经在操作元素了 ; 需要等待页面渲染完成先 ;
selenium 提供3种方法来 等待元素渲染
强制等待
通过 Thread.sleep() 让线程休眠, 实现等待
优先: 使用简单,
缺点: 影响效率 (如果有1000个用例 , sleep3秒, 用例测试完最少要 3000秒 , 耗费时间太多了 , 一般来自动化测试完不超过1-2分钟)
隐式等待
隐式等待是一种 智能等待 , 可以在 指定时间 内不断查找元素 ,如果找到了, 才会让代码继续执行 , 如果超时都没有找到 , 就报错
driver.manage().timeouts().implicitlyWait(超时时间)
隐式等待 通过 Duration.ofxxx 来设置超时时间 , 有毫秒,秒,分钟...单位 // 隐式等待 毫秒 driver.manage().timeouts().implicitlyWait(Duration.ofMillis(2000)) ; //隐式等待 秒 driver.manage().timeouts().implicitlyWait(Duration.ofSeconds(2)) ;
隐式等待特点
-
只有在 findElement 这样查找元素的方法, 才会自动调用 (在查找元素前, 会先进行隐式等待 对元素进行查找 , 找到了 ,才 会继续执行 下面的 findElement() , 这样来避免 因为 页面渲染慢的问题, (我先替你找一下, 防止你找不到报错))
-
隐式等待的作用域是全局的 , 只要前面定义了隐式等待 , 后面 的findElement 不需要在调用等待, 都会用到前面的隐式等待 (直到 driver.quit() 才结束)
-
隐式等待只能用于 查找元素 , (例如: sendKeys() 操作不会触发等待); 所以会出现 sendKeys() 还没有输入完 , 下面的代码就开始执行了 ;
-
因为隐式等待只有 查找才会触发, 所以只能用于查找元素时
显示等待
显示等待也是一种智能等待 , 在指定超时时间范围 只要能满足 条件 就会继续执行后续代码 ;
// 显示等待功能 能实现更高级的 断言 , 但是用起来麻烦 // 需要 创建显示等待的对象 // 指定好 超时时间 和 条件 时间 until()条件 new WebDriverWait(driver , Duration.ofSeconds(3)).until(条件) ; // 或 条件分出来 WebDriverWait wait = new WebDriverWait(driver , Duration.ofSeconds(3)) ; wait.until(条件) // until (条件) 条件的 类型是ExpectedConditions类里的方法 , 返回值是 boolean
ExpectedCondition的方法
-
elementToBeClickable( 元素) : 用于检查 元素 是否可见, 并且启用 ,
-
textToBe(元素, string) : 检查元素文本是否和string相同 (例如:<text>aaa</text> 里的文本 就 和 aaa 相同 , 精准匹配)
-
attributeContains(元素 , 属性 , String) : 检查元素的属性是否 包含有 String (模糊匹配)
WebDriverWait wait = (WebDriverWait) new WebDriverWait(driver , Duration.ofSeconds(3)); wait.until(ExpectedConditions. attributeContains(By.cssSelector("#su"), "value", "百度")); // 这里 就是 su元素 的value属性里是否 包含有 "百度"
-
presenceOfElementLocated(元素) : 检查 页面中是否 有 元素
-
urlToBe( URL ): 检查当前页面的地址 是否和 URL相同
WebDriverWait wait = (WebDriverWait) new WebDriverWait(driver , Duration.ofSeconds(3)); wait.until(ExpectedConditions. urlToBe("www.baidu.com")); // 页面的地址包含https:// 所以 上面的www.baidu.com 是不同的url
隐式等待 和 显示等待
如果 同时使用 隐式等待 和 显示等待 两种等待 , 最终的运行时间是多少;
System.out.println(new SimpleDateFormat("HH:mm:ss").format(System.currentTimeMillis())); driver.manage().timeouts().implicitlyWait(Duration.ofSeconds(4)) ; driver.findElement(By.cssSelector("#su")); WebDriverWait wait = (WebDriverWait) new WebDriverWait(driver , Duration.ofSeconds(10)); wait.until(ExpectedConditions. presenceOfElementLocated(By.cssSelector("#su"))); System.out.println(new SimpleDateFormat("HH:mm:ss").format(System.currentTimeMillis())); // 设置两个等待 , 最终结果
两个等待同时一起用,最终结果不可预测
浏览器操作
打开某个网站
//1.打开某个网站 driver.navigate().to( url ); // 2. 简洁的方法 driver.get(url) ;
浏览器的 前进/后退/刷新
// 后退 driver.navigate().back(); // 前进 driver.navigate().forward(); // 刷新 driver.navigate().refresh();
相当于这个
弹窗
弹窗不属于 页面上的元素 , 同时 如果页面出现弹窗 , 那么 是不能再页面上进行 查找等元素操作 , 需要处理了弹窗
selenium 提供了 Alert 弹出接口
警告弹出+确认弹窗
弹窗可能是: 1. 警告弹窗,只要一个确认按钮 或 2. 确认弹窗 : 有确认按钮和取消按钮
// 获取页面的弹窗 Alert alert = driver.switchTo().alert() ; // 确认 alert.accept(); // 取消 alert.dismiss();
提示弹窗
弹出里让 你输入 数据 , 有确认有取消的 弹窗
// 获取页面弹窗 Alert alert = driver.switchTo().alert() ; // 先输入内容到 弹窗里的输入框 alert.sendKeys(内容); // 确认或取消 alert.accept() ; alert.dismiss() ;
文件上传
当点击页面上的上传文件时, 会弹出系统的 文件选择窗口
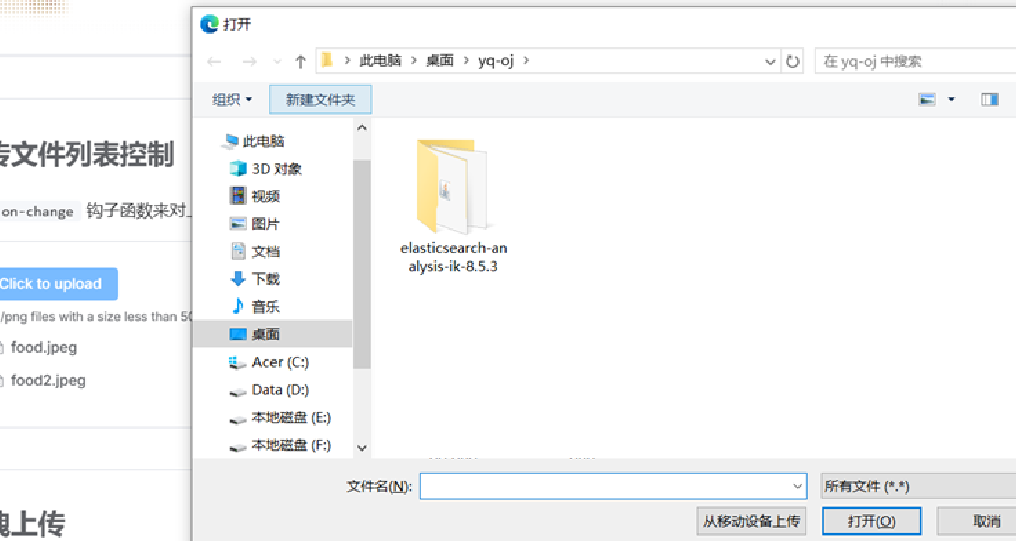
这是windows 系统的 文件选择窗口 , 不属于浏览器, 更不属于页面 , 所以 driver 不能操作这个窗口
但是可以通过 sendKeys 来指定 上传的文件
// 文件上传 // 先查找到 文件上传的 元素 WebElement element = driver.findElement(By.cssSelector("文件上传的元素")) ; // 指定要上传的文件是哪一个 , 例如: D://图片.png element.sendKeys("要上传的文件地址");
浏览器参数设置
设置无头模式
设置无头模式运行 , 那么自动化测试时, 就看不到 测试时的操作(看不到浏览器打开,操作元素 这些东西了....)
前面启动浏览器创建 driver的时候 , 就配置浏览器允许 任何链接访问的 参数
通过 addArguments() 的方法 设置 浏览器无头模式运行
WebDriverManager.chromedriver().setup(); // 打开谷歌浏览器 ChromeOptions options = new ChromeOptions(); // 允许任何链接访问 options.addArguments("--remote-allow-origins=*") ; // 设置 无头模式 options.addArguments("-headless") ; // 打开浏览器 this.driver = new ChromeDriver(options); // 访问百度 driver.get("https://www.baidu.com");
设置浏览器加载策略
自动化测试浏览器加载策略有 3种:
-
NORMAL (等全部元素,资源加载完)
-
NONE (不需要等元素加载完)
-
EAGER (只需要等元素加载完, 不需要等 图片资源)
// 默认情况: 等全部元素 和 图片等资源 加载完 (默认) options.setPageLoadStrategy(PageLoadStrategy.NORMAL) ; //不用等元素加载完 options.setPageLoadStrategy(PageLoadStrategy.NONE) ; // 只需要等 页面Dom元素加载完 , 图片等资源不需要 options.setPageLoadStrategy(PageLoadStrategy.EAGER) ;
通过这个用例来测试
// 后退 driver.navigate().back(); Thread.sleep(2000); // 前进 driver.navigate().forward(); Thread.sleep(2000); // 刷新 driver.navigate().refresh();
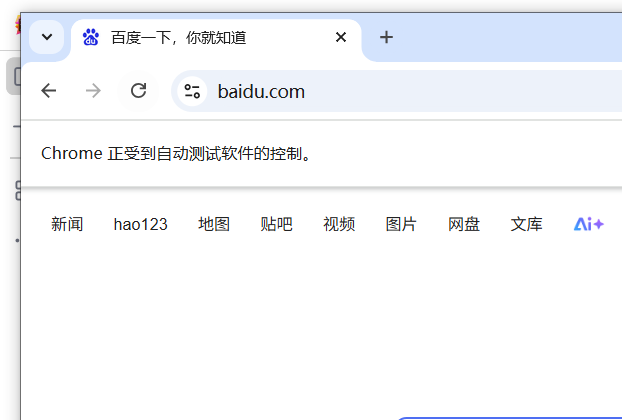
-
NORMAL (等全部元素,资源加载完)
会等页面完全加载 (这里的刷新按钮已经出来了, 就是页面已经加载完了, 如果没有是不会出现刷新页面的按钮的)
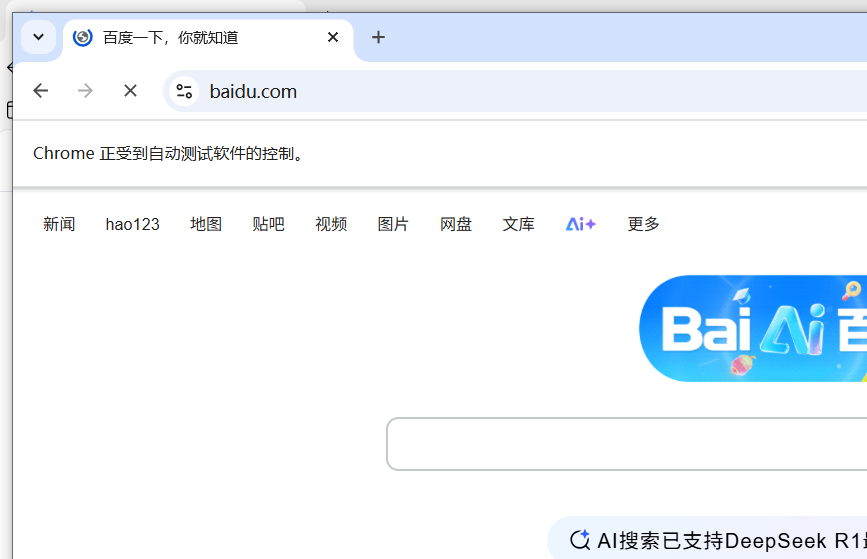
2. NONE (不需要等元素加载完)
还没有等页面加载完就快速执行操作,后退,前进,刷新,关闭了 (这里的刷新按钮还没有出来,就是还没有加载完成)
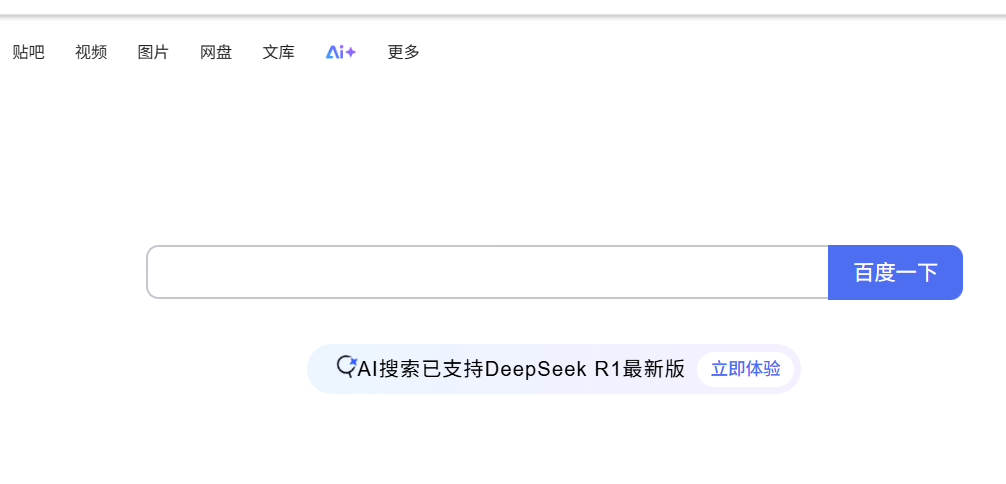
3. EAGER (只需要等元素加载完, 不需要等 图片资源)
不需要等图片资源加载就 执行 (图片还没有出来, 但是元素出来了, 就直接指向后面的)
使用 Actions 模拟点击
Actions actions = new Actions(driver); // 要移动到的元素 WebElement webElement = driver.findElement(By.xpath("")); //鼠标移动到 元素位置 .click点击元素 .perform() 执行前面的动作链 actions.moveToElement(webElement).click().perform(); // yqoj里模拟鼠标点击代码框, 然后ctrl+a全选, 删除, 输入代码 , Actions actions = new Actions(driver); WebElement webElement = driver.findElement(By.xpath("//*[@id=\"app\"]/div/div[2]/div[2]/div[2]/div[1]/div/div[2]/div[2]/div")); actions.moveToElement(webElement) .click() .keyDown(Keys.CONTROL) .sendKeys("a") // Ctrl + A 全选 .keyUp(Keys.CONTROL) .sendKeys(Keys.BACK_SPACE) // 删除选中内容 .sendKeys("public class Solution{\n" + // 输入新内容 " public static int countCharacterOccurrences(String str, char ch){\n" + " int count = 0;\n" + " char[] arr = str.toCharArray() ;\n" + " for (char c : arr) {\n" + " if (c == ch) {\n" + " count++;\n" + " }\n" + " }\n" + " \n" + " return count;\n" + " }\n" + "}") .perform();
在idea中添加断言
-ea -Dfile.encoding=UTF-8
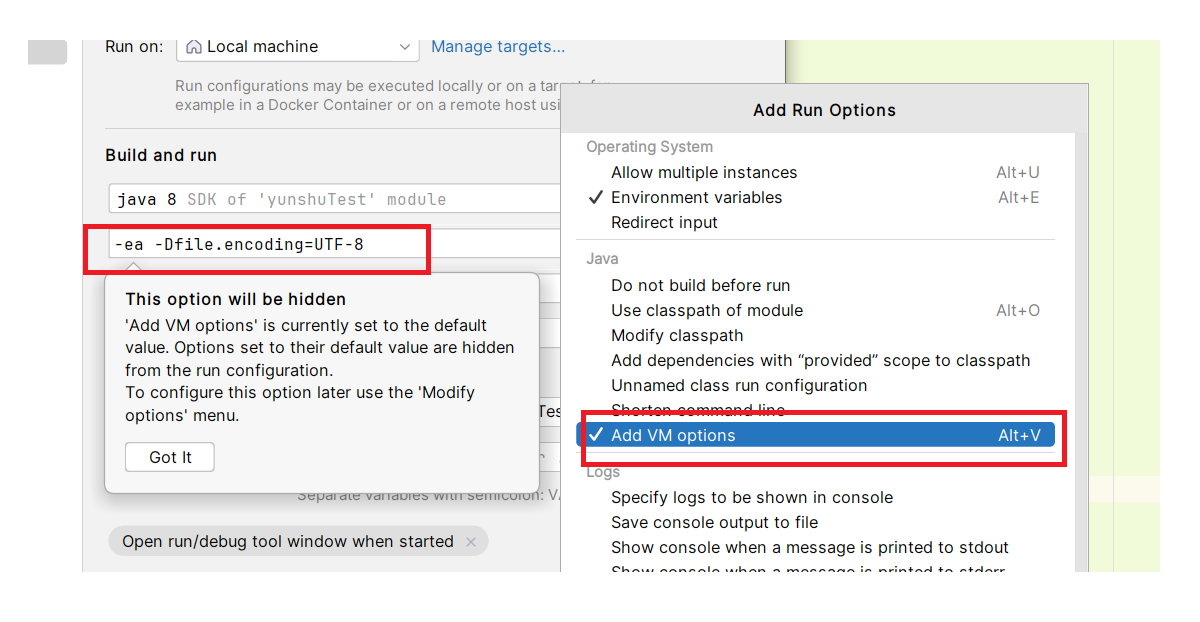
开启断言后可以使用 : assert 进行断言判断 : 例如这里 1==2返回false那么断言就是失败 ;

获取当前执行的方法
通过匿名内部类 来 getClass().getEnclosingMethod() 方法
创建一个匿名内部类对象,从他的类对象中获取当前方法的 方法对象 , 在获取方法对象的 名字
new Object() {}.getClass().getEnclosingMethod().getName()