本文记录基于 Next.js 13 实现的多功能在线工具平台的前端架构设计与文件处理实践。覆盖 40+ 工具场景,采用 Next.js + Spring Boot 3.2 全栈方案。文章将深入讲解 Pages Router 的双轨路由设计、前端优先的文件处理策略,以及 Java 调用 Python 的桥接实现。
一、项目背景
最近在做一个整合 PDF 处理、图片编辑、格式转换、开发辅助等高频工具的在线平台。目标是每个工具都有真实的处理引擎、完整的用户体系,不是那种挂几个外链的导航站。
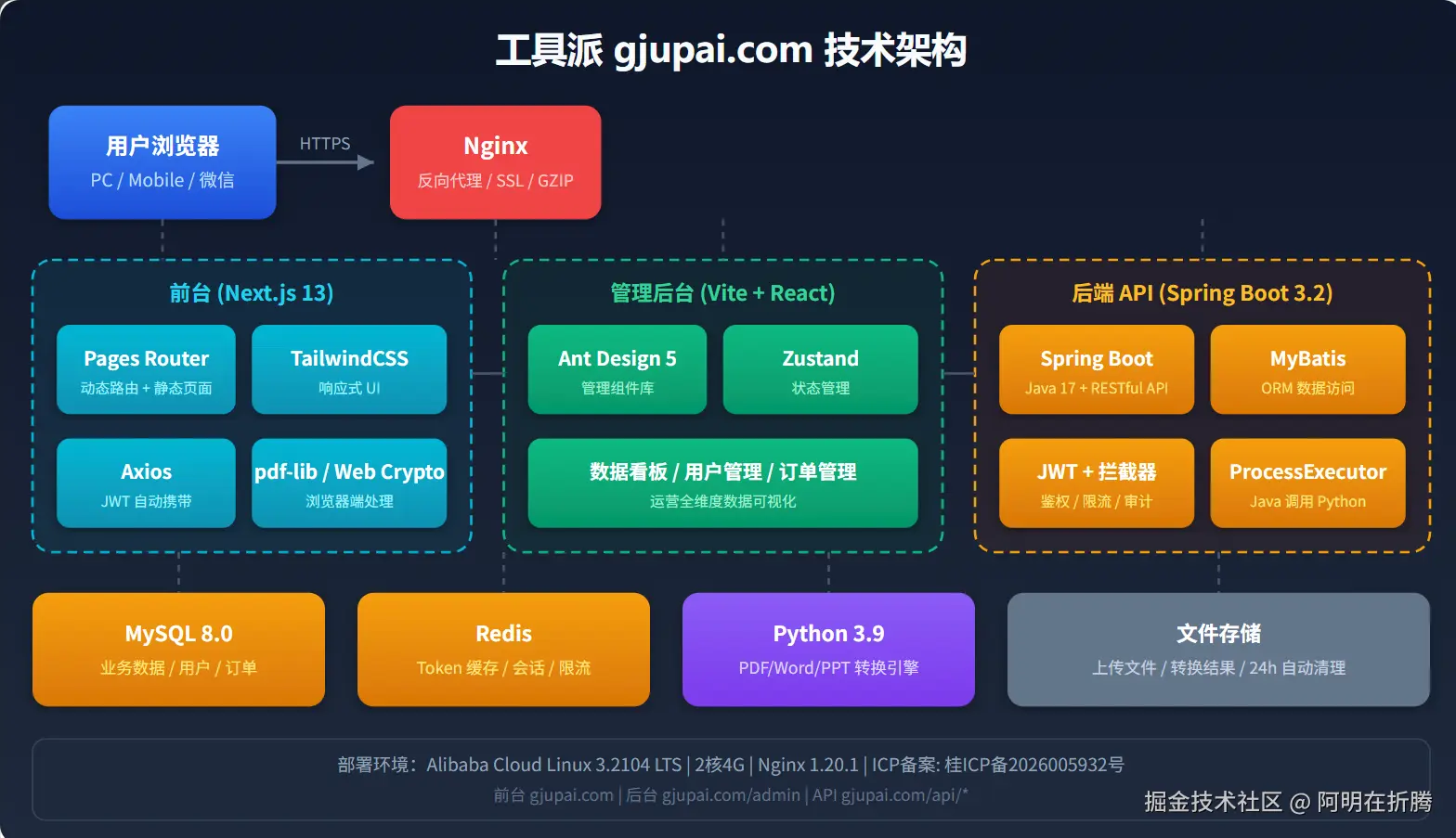
技术栈选型
| 层级 | 技术 | 版本 | 选型理由 |
|---|---|---|---|
| 前台 | Next.js | 13 (Pages Router) | SSR 利于 SEO,动态路由适合工具化场景 |
| 前台 | TailwindCSS | 3.3 | 原子化 CSS,快速迭代 UI |
| 后台 | Vite + React | 4.5 + 18 | 管理后台轻量启动,Ant Design 5 组件丰富 |
| 后端 | Spring Boot | 3.2.5 | Java 生态成熟,适合复杂业务 |
| 数据库 | MySQL + Redis | 8.0 / 7.0 | 业务数据 + Token 缓存双剑合璧 |
| 转换引擎 | Python | 3.9 | pdf2docx、PyMuPDF、Ghostscript 等库成熟稳定 |
二、Next.js 路由设计:双轨制架构
42 个工具怎么组织路由?每个工具一个页面文件会导致 42 个 .tsx 文件,维护成本爆炸。但如果全走动态路由,纯前端工具(如二维码生成器)又没必要统一到一个 2000 行的页面里。
我的解法是双轨路由:

轨道 A:动态路由 [code].tsx
负责所有需要后端服务器处理文件的工具:
- PDF 处理(转换、压缩、合并拆分)
- Office 转换(Word/Excel/PPT 互转)
- 图片处理(压缩、格式转换、批量处理)
- 音视频(压缩、格式转换、提取音频)
核心路由守卫逻辑:
scss
// src/pages/tools/[code].tsx
const PURE_FRONTEND_TOOLS = [ 'batch_rename', 'qrcode_generator', 'file_encryptor', 'data_cleaner', 'regex_tester', 'chart_generator', // ... 共 28 个纯前端工具];
export default function ToolDetailPage() {
const router = useRouter();
const { code } = router.query;
useEffect(() => {
if (!code) return;
const backendCode = Array.isArray(code) ? code[0] : code;
// 白名单命中 → 跳转独立页面
if (PURE_FRONTEND_TOOLS.includes(backendCode)) {
router.replace(`/tools/${backendCode}`);
return;
}
// 否则留在动态路由页面,走后端处理流程
loadToolDetail(backendCode);
}, [code]);
// ... 2000+ 行的工具详情页渲染
}轨道 B:独立页面 {code}.tsx
每个纯前端工具拥有独立的页面文件,不依赖后端文件转换,直接在浏览器中完成处理:
ruby
// src/pages/tools/batch_rename.tsx
// src/pages/tools/qrcode_generator.tsx
// src/pages/tools/file_encryptor.tsx
// ...这些页面的共同特点是:
- 从后端只获取工具元数据和额度信息
- 文件处理完全在浏览器内完成(
pdf-lib、crypto.subtle、JSZip等) - 处理结果通过
URL.createObjectURL(blob)生成本地下载链接
为什么不用 App Router?
项目启动时 Next.js 13 的 App Router 还不够稳定,且 Pages Router 的动态路由语法 [param] 对于工具型站点更直观。另外,项目大量使用了 getServerSideProps 来做 SEO 数据注入,迁移成本较高。如果今天重新选型,我可能会评估 App Router 的 Server Components 对首屏性能的提升。
三、文件处理体系:前端优先,后端兜底
在线工具平台的核心是文件处理能力。我的设计哲学是:
能前端处理的绝不走服务器。减少带宽消耗、降低服务器压力、保护用户隐私。
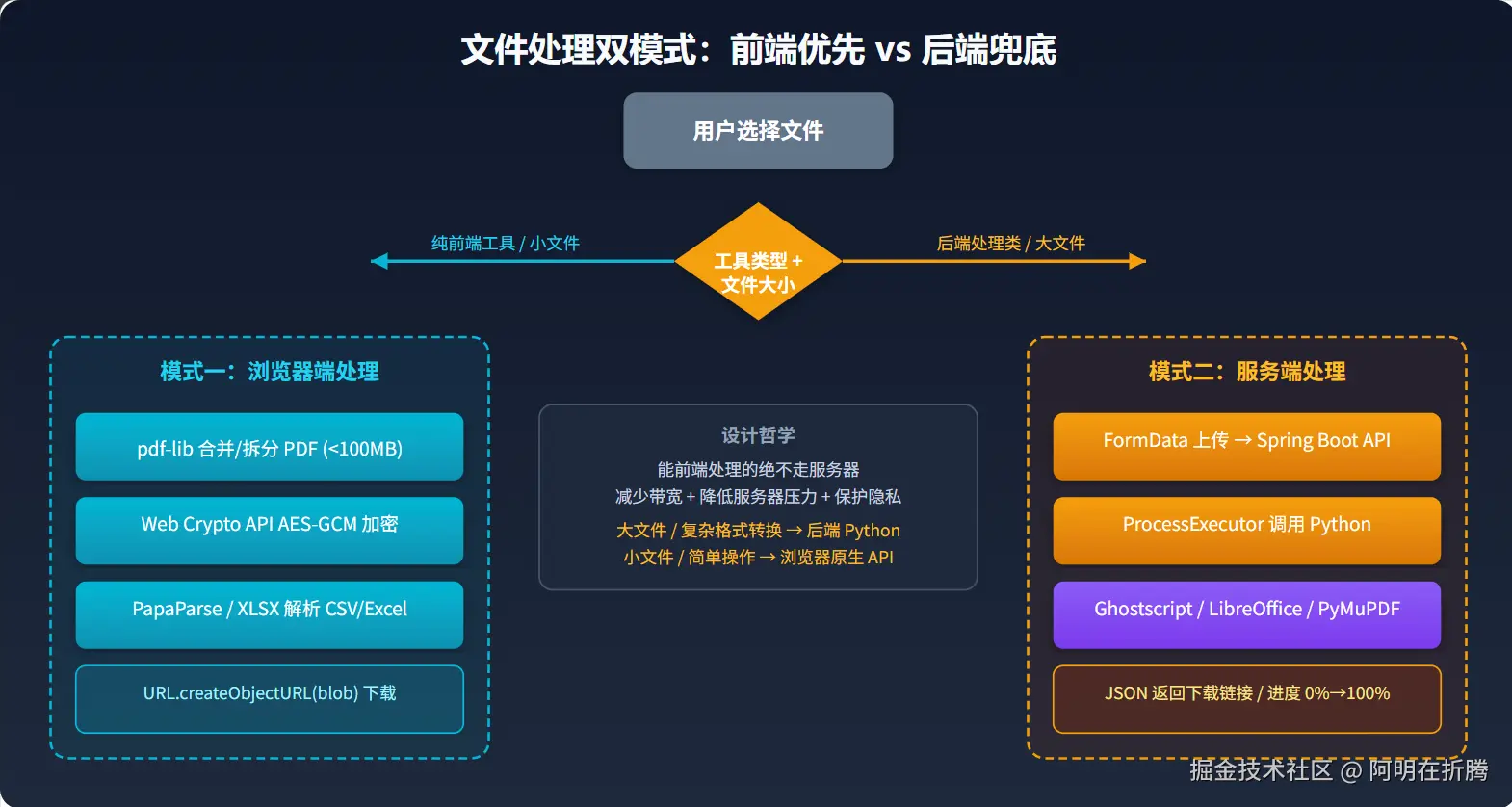
模式一:浏览器端处理(纯前端)
1. PDF 合并/拆分(pdf-lib)
对于小于 100MB 的 PDF 文件,直接在浏览器内完成合并,免去上传等待:
ini
// src/utils/pdfUtils.ts
import { PDFDocument } from 'pdf-lib';
const FRONTEND_SIZE_LIMIT = 100 * 1024 * 1024; // 100MB
const FRONTEND_FILE_COUNT_LIMIT = 10;
export function canProcessInFrontend(files: File[]): boolean {
if (files.length > FRONTEND_FILE_COUNT_LIMIT) return false;
const totalSize = files.reduce((sum, f) => sum + f.size, 0);
return totalSize <= FRONTEND_SIZE_LIMIT;
}
export async function mergePdfsInFrontend(
files: File[],
outputFileName: string
) {
const mergedDoc = await PDFDocument.create();
let totalPages = 0;
for (const file of files) {
const arrayBuffer = await file.arrayBuffer();
const pdf = await PDFDocument.load(arrayBuffer);
const pages = await mergedDoc.copyPages(pdf, pdf.getPageIndices());
pages.forEach((page) => mergedDoc.addPage(page));
totalPages += pages.length;
}
const mergedBytes = await mergedDoc.save({
useObjectStreams: true,
addDefaultPage: false,
});
const blob = new Blob([mergedBytes], { type: 'application/pdf' });
return {
url: URL.createObjectURL(blob),
fileName: outputFileName,
size: blob.size,
pageCount: totalPages,
};
}2. 文件 AES-GCM 加密(Web Crypto API)
文件加密这种敏感操作,走前端意味着用户的密码和文件不会离开浏览器:
javascript
const SALT_LEN = 16;
const IV_LEN = 12;
const ITERATIONS = 100000;
async function getKey(password: string, salt: Uint8Array): Promise<CryptoKey> {
const enc = new TextEncoder();
const keyMaterial = await crypto.subtle.importKey(
'raw', enc.encode(password), { name: 'PBKDF2' },
false, ['deriveKey']
);
return crypto.subtle.deriveKey(
{ name: 'PBKDF2', salt, iterations: ITERATIONS, hash: 'SHA-256' },
keyMaterial,
{ name: 'AES-GCM', length: 256 },
false, ['encrypt', 'decrypt']
);
}
async function encryptFile(file: File, password: string): Promise<Blob> {
const salt = crypto.getRandomValues(new Uint8Array(SALT_LEN));
const iv = crypto.getRandomValues(new Uint8Array(IV_LEN));
const key = await getKey(password, salt);
const data = new Uint8Array(await file.arrayBuffer());
const encrypted = await crypto.subtle.encrypt(
{ name: 'AES-GCM', iv }, key, data
);
// salt(16) + iv(12) + encrypted
const result = new Uint8Array(SALT_LEN + IV_LEN + encrypted.byteLength);
result.set(salt, 0);
result.set(iv, SALT_LEN);
result.set(new Uint8Array(encrypted), SALT_LEN + IV_LEN);
return new Blob([result], { type: 'application/octet-stream' });
}3. CSV/Excel 数据清洗(PapaParse + XLSX)
ini
import Papa from 'papaparse';
import * as XLSX from 'xlsx';
function handleFile(f: File) {
const ext = f.name.split('.').pop()?.toLowerCase();
if (ext === 'csv') {
Papa.parse(f, {
complete: (results) => {
const data = results.data as string[][];
setHeaders(data[0]);
setRows(data.slice(1).filter(r => r.some(c => c !== '')));
},
skipEmptyLines: true,
});
} else if (ext === 'xlsx' || ext === 'xls') {
const reader = new FileReader();
reader.onload = (e) => {
const data = new Uint8Array(e.target?.result as ArrayBuffer);
const workbook = XLSX.read(data, { type: 'array' });
const sheet = workbook.Sheets[workbook.SheetNames[0]];
const json = XLSX.utils.sheet_to_json(sheet, { header: 1 }) as any[][];
// ... 数据清洗逻辑
};
reader.readAsArrayBuffer(f);
}
}模式二:服务端处理(Java + Python 桥接)
大文件或复杂格式转换(如 Word 转 PDF、视频压缩)必须走后端。核心流程:
前端上传:
ini
const handleUpload = async () => {
// 1. 前端 PDF 优先处理(小文件免上传)
if (isPdfMergeSplitTool && operationType === 'merge') {
if (canProcessInFrontend(files)) {
const result = await mergePdfsInFrontend(files, 'merged.pdf');
setResultUrl(result.url);
return;
}
}
// 2. 启动模拟进度条
let simulatedProgress = 0;
const progressInterval = setInterval(() => {
simulatedProgress += Math.random() * 4 + 2;
if (simulatedProgress >= 90) {
simulatedProgress = 90;
clearInterval(progressInterval);
}
setProgress(Math.min(simulatedProgress, 90));
}, 300);
// 3. 构建 FormData
const formData = new FormData();
if (isPdfMergeSplitTool && operationType === 'merge') {
files.forEach((f) => formData.append('files', f));
formData.append('toolCode', 'pdf_merge_split');
formData.append('mode', 'merge');
} else {
formData.append('file', file!);
}
// 附加工具参数(JSON 序列化)
if (isPdfToTool) {
const params = { format: targetFormat, pageRanges: pdfPageRanges, dpi: pdfDpi };
formData.set('targetFormat', JSON.stringify(params));
}
// 4. 上传
const uploadRes = await fetch(`/api/tool/upload/${actualToolCode}`, {
method: 'POST',
headers: token ? { Authorization: `Bearer ${token}` } : {},
body: formData,
});
const uploadData = await uploadRes.json();
if (uploadData.code === 200) {
clearInterval(progressInterval);
setProgress(100);
setResultUrl(uploadData.data.resultUrl);
}
};后端桥接(Java 调用 Python):
vbnet
// ProcessExecutor.java
@Component
public class ProcessExecutor {
public ProcessResult execute(String pythonPath, String scriptPath,
int timeoutSeconds, String... args) {
// Windows 兼容处理
boolean isWindows = pythonPath.contains("\") || pythonPath.contains(":");
List<String> commandList = new ArrayList<>();
if (isWindows) {
commandList.add("cmd.exe");
commandList.add("/c");
commandList.add("chcp 65001 >nul && " + pythonPath + " "
+ scriptPath + " " + String.join(" ", args));
} else {
commandList.add(pythonPath);
commandList.add(scriptPath);
for (String arg : args) commandList.add(arg);
}
ProcessBuilder builder = new ProcessBuilder(commandList);
builder.environment().put("PYTHONIOENCODING", "utf-8");
builder.redirectErrorStream(true);
Process process = builder.start();
boolean finished = process.waitFor(timeoutSeconds, TimeUnit.SECONDS);
if (!finished) {
process.destroyForcibly();
return new ProcessResult(false, "处理超时", null, elapsedTime);
}
// 读取 Python 输出的 JSON 结果
String output = IOUtils.toString(process.getInputStream(), StandardCharsets.UTF_8);
return new ProcessResult(true, null, output, elapsedTime);
}
}Python 转换引擎(PDF 压缩示例):
python
# pdf_compress.py
def compress_with_ghostscript(input_path, output_path, level,
target_size_kb=None, image_quality=None):
gs_cmd = find_ghostscript() # gswin64c / gswin32c / gs
settings_map = {
'low': '/printer', # 300 DPI
'medium': '/ebook', # 150 DPI
'high': '/screen', # 72 DPI
}
cmd = [
gs_cmd, '-sDEVICE=pdfwrite',
'-dCompatibilityLevel=1.4',
f'-dPDFSETTINGS={settings_map[level]}',
'-dDownsampleColorImages=true',
'-dColorImageResolution=' + str(target_dpi),
'-dCompressFonts=true',
'-dSubsetFonts=true',
f'-sOutputFile={output_path}',
input_path
]
result = subprocess.run(cmd, capture_output=True, text=True, timeout=300)
return { 'success': result.returncode == 0, 'output': output_path }四、性能与体验优化
1. 文件大小分级策略
| 场景 | 阈值 | 处理方式 |
|---|---|---|
| PDF 合并/拆分 | ≤ 100MB,≤ 10 个文件 | 浏览器端 pdf-lib 处理 |
| PDF 合并/拆分 | > 100MB 或 > 10 个文件 | 上传后端 Python 处理 |
| 图片压缩 | 不限(前端 Canvas) | 浏览器端 Canvas 压缩 |
| 视频/GIF | 单文件 ≤ 50MB | 上传后端 FFmpeg 处理 |
| Word/PPT 转 PDF | 不限 | 后端 LibreOffice 转换 |
2. 进度条设计
后端处理类工具需要进度反馈。我的方案是前端模拟 + 后端确认:
scss
// 前端启动模拟进度(每 300ms 增加 2~6%)
const progressInterval = setInterval(() => {
simulatedProgress += Math.random() * 4 + 2;
if (simulatedProgress >= 90) {
simulatedProgress = 90;
clearInterval(progressInterval);
}
setProgress(Math.min(simulatedProgress, 90));
}, 300);
// 后端返回后冲到 100%
if (uploadData.code === 200) {
clearInterval(progressInterval);
setProgress(100);
}这种方案避免了 WebSocket 的复杂度,用户感知上足够流畅。
五、踩坑记录
-
Next.js Pages Router 刷新 404
部署后发现直接刷新
/tools/pdf_to_word会 404。解决:Nginx 配置try_files回退到index.html,由 Next.js 客户端路由接管。 -
Python 进程假死
早期未设置超时,大 PDF 转换时 Python 进程挂死导致 Java 线程阻塞。解决:
ProcessExecutor增加waitFor(timeout)机制,超时强制destroyForcibly()。 -
Windows 本地开发 vs Linux 生产环境
Python 路径、LibreOffice 路径、Ghostscript 路径在不同系统完全不同。解决:配置文件中按系统类型分别指定路径,启动时做环境检查。
-
文件类型白名单绕过
早期只检查后缀名,有被上传
.pdf.exe的风险。解决:后缀名 + MIME 类型双重校验,后端存储时重命名为 UUID。
六、总结
这个项目让我对"全栈独立开发"有了更深的理解:
- 路由设计:双轨制不是过度设计,而是 42 个工具在可维护性和用户体验之间的最优解
- 文件处理:前端优先策略让平台在 2核4G 的服务器上也能流畅运行,同时保护了用户隐私
- 跨语言桥接:Java + Python 不是最优解,但在现有团队技能栈和开源生态下是最务实的选择
如果你也在做类似的工具平台,欢迎交流。项目已开源核心思路,具体代码涉及商业逻辑不便公开,但本文的架构设计和核心片段应该足够参考。
- 项目已上线,地址请查看我的主页
如果这篇文章对你有帮助,欢迎点赞收藏。有问题可以在评论区讨论,我会尽量回复。