本文对应项目版本:
v0.1.0
AI Mind 做到 v0.1.0,终于进入了 Agent。
但这个 Agent 不是通用 Agent,而是一个受控的 Tasklist Agent:基于用户显式引用的版本方案,生成任务清单草稿,并把中间执行过程展示出来。
这篇不要求读者看过前几篇。第一次看到这个项目,可以先把 AI Mind 理解成一个持续迭代的 AI Runtime 实验项目。它关注的不是模型能力本身,而是一次 AI 请求从输入、能力选择、工具执行到前端展示的工程链路。
它不是一次性做完的 AI 产品,而是一步步验证聊天、流式输出、工具调用、MCP 能力接入、Skill Runtime、Composer(AI 输入框 / 输入层)和前端执行过程展示这些运行时能力。
这些名词不需要在开头全部理解。本文只围绕一个问题展开:第一个 Agent 怎么先被控制住。
但这一版我没有先做一个"什么都能规划、什么都能调用"的通用 Agent,也没有上来就做那种"先让模型自己规划步骤,再按步骤调用工具执行"的开放式 Agent,更没有做多 Agent、长期记忆、RAG 或自动写文件。
我做的是一个很窄的 Agent:Tasklist Agent。它生成的是任务清单草稿,不是替我们真正执行任务。
它只解决一件事:
text
用户显式选择 /tasklist(生成任务清单)
+ 用户显式引用 docs://versions/*.md(某一份版本方案)
-> Runtime 读取版本方案
-> Agent 生成任务清单草稿
-> 确定性工具做结构校验
-> 必要时最多自动修正一次
-> 最终输出可复制草稿、校验结论和人工确认点这里的 version plan 指"版本方案",tasklist 指"任务清单"。在 AI Mind 里,它们不是随手生成的普通文本,而是每个版本从设计到执行之间的关键文档资产。
我不会把这篇写成"Agent 是什么"的概念科普,也不会写成版本更新日志。我更想复盘一个真实工程问题:
当一个 AI 应用准备进入 Agent 阶段时,为什么第一个 Agent 反而应该做小、做窄、做可控?
如果把这一版压成一句话,我会这样概括:
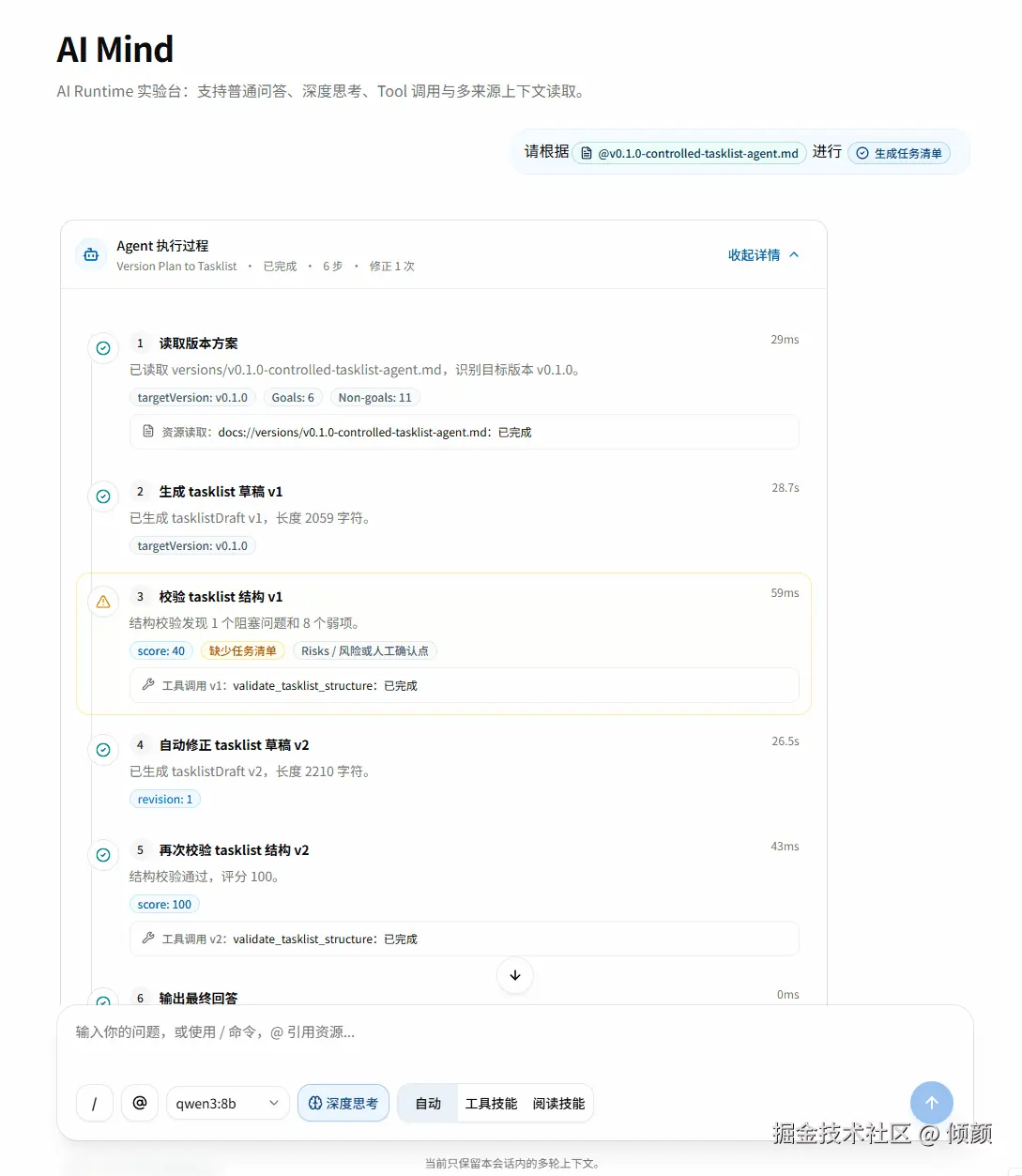
v0.1.0的重点不是"AI Mind 有 Agent 了",而是我们第一次把一个 Agent 放进 Runtime(运行时,负责决定本轮请求走普通回答、工具调用还是 Agent 路径)里,并且让它有入口、有状态机、有质量门、有前端可视化、有明确停止边界。
1. AI Mind 终于进入 Agent,但我没有先做通用 Agent
很多项目一提到 Agent,很容易自然滑向几个方向:
- 让模型自己规划步骤
- 让模型自由选择工具
- 让模型自己决定读哪些文件
- 让模型多轮修正直到满意
- 让 Agent 自动把结果写回项目文件
这些方向并不是不对,但它们都有一个共同点:一旦边界没有收住,Runtime 很快会变成一个不透明的黑盒。
在 AI Mind 当前阶段,我更关心的是另一件事:
我们能不能先做一个入口明确、步骤可控、状态可见、输出可复制的单 Agent?
这就是 Tasklist Agent 的定位。
它不是通用 Agent,也不是让模型自己规划下一步怎么做的开放式 Planner。它只在一个非常具体的场景下启动:
/tasklist + @docs://versions/*.md
这里的 /tasklist 表达"我要生成任务清单",@docs://versions/*.md 表达"这次任务清单必须基于哪一份版本方案"。二者缺一不可。
docs://... 是 AI Mind 内部的文档资源地址,更像一个受控资源 ID。它只指向允许暴露的 docs 文档,不是任意本地文件路径。
这看起来很克制,但对我来说很重要。因为第一个 Agent 最容易犯的错误,不是能力不够强,而是边界太早失控。
这里可能也会有一个疑问:既然步骤是 Runtime 固定的,那它为什么还算 Agent?
我对本版 Agent 的定义比较克制。它不是"完全自主型 Agent",而是"受控型单 Agent":它有明确任务目标,会读取用户指定的上下文,会生成中间草稿,会调用质量校验工具,会根据校验结果最多修正一次,也会把执行过程展示给前端;但它的入口、步骤、工具和停止条件都由 Runtime 控制。
所以这版 Tasklist Agent 更像一个被运行时收住边界的工程执行单元,而不是一个什么都能自己决定的自动智能体。
2. 为什么第一个 Agent 选择"版本方案 -> 任务清单"
我没有选择"自动修代码""自动规划功能""自动生成架构方案"作为第一个 Agent 场景,而是选择了 版本方案 -> 任务清单。
原因很简单:这个场景既足够真实,又足够可控。
在 AI Mind 里,每个版本通常都会先有一份 version plan(版本方案,说明这一版做什么、不做什么、关键边界、测试计划和交付结果)。然后我们再基于它拆出 tasklist(任务清单,真正开工时的执行依据)。
这条链路非常适合成为第一个 Agent 样本:
- 输入明确:一份
docs://versions/*.md版本方案 - 输出明确:一份 tasklist 草稿
- 质量可以检查:是否有标题、来源方案、步骤、验收项、验证内容
- 风险可控:只生成草稿,不直接写文件
- 人仍然在环:最终结果需要人工确认后再落地
它不像普通问答那样只有"答得像不像",也不像通用 Agent 那样一上来就有太多自由度。
更关键的是,它刚好能验证 Agent Runtime 最核心的几个问题:
- Agent 入口应该怎么收住
- Agent 状态应该怎么转移
- 模型生成和确定性工具应该怎么配合
- 前端应该怎么展示 Agent 执行过程
- 最终结果应该怎么让用户复制和确认
所以我把第一个 Agent 做成了一个"受控任务生成器",而不是一个"自由规划系统"。
3. 入口必须收住:只允许 /tasklist + @docs://versions/*.md
这一版最重要的入口判断在 version-plan-tasklist-agent(受控 Tasklist Agent 的运行时目录)里。
它的入口识别逻辑很窄:
ts
const VERSION_PLAN_RESOURCE_URI_PATTERN = /^docs:\/\/versions\/[^/\\]+\.md$/i
export function resolveVersionPlanTasklistAgentInvocation(request: ChatRequest) {
if (request.composer?.command?.name !== 'tasklist') {
return null
}
const versionPlanReference = request.composer.references?.find(isVersionPlanReference)
if (!versionPlanReference) {
return { kind: 'missing-version-plan' }
}
return {
kind: 'ready',
versionPlanReference,
}
}这段代码解决的是一个很基础但很关键的问题:什么情况下允许进入 Agent?
答案不是"用户提到了 tasklist",也不是"模型判断用户可能想生成任务清单",而是必须满足两个条件:
command.name === 'tasklist'- 引用了合法的
docs://versions/*.md
如果用户只输入"帮我生成 tasklist",但没有引用版本方案,本版不会让 Agent 自己去猜、自己去扫描、自己去找最新方案。
它会明确提示:
请先通过 @ 引用一个
docs://versions/*.md版本方案,再生成 tasklist 草稿。本版不支持只根据目标直接生成 tasklist。
这个设计看起来不够"智能",但它保护了两个边界:
- 输入边界:Agent 必须基于用户显式引用的版本方案工作。
- 行为边界:Agent 不负责自动发现、自动扫描、自动选择文档。
对第一个 Agent 来说,这种"不智能"反而是稳定性的来源。
4. 资源菜单的小升级:能选择版本方案,但不等于 Agent 自动扫描
为了让 /tasklist 能和版本方案配合,前端资源菜单也做了一次小升级:通过 docs catalog(文档目录接口)把可引用的版本方案提供给 Composer(AI 输入框 / 输入层)的 @resource 菜单。
这样用户可以通过 [生成任务清单] @docs://versions/v0.1.0-controlled-version-plan-to-tasklist-agent.md 明确表达"我要基于这份版本方案生成任务清单"。
但这只是用户显式选择资源,不是 Agent 自动扫描 docs/versions/,也不是自动判断"最新版本是哪一个"。这一节的取舍可以总结成:
资源菜单只是帮助用户更清楚地引用上下文,不是把 Agent 变成自动文档扫描器。
5. Runtime 控制的 Agent 路径:不是让模型自由规划
真正进入 Agent 后,本版也没有把控制权交给模型。
chat-orchestrator(聊天主链调度器,决定本轮走 Agent、输入上下文回答、工具调用还是普通回答)里,Agent 是主链路里的第一道受控分支:
ts
if (await this.runVersionPlanTasklistAgentEntryStage(session)) {
return
}
if (await this.runComposerContextAnswerStage(session)) {
return
}
if (await this.runCapabilityContextAnswerStage(session)) {
return
}这意味着 /tasklist + @docs://versions/*.md 命中以后,本轮会进入任务清单 Agent 路径,并且短路后面的普通上下文回答、能力上下文回答和工具调用。
换成更白话的说法:命中 Agent 后,就不要再让它继续走普通问答或普通工具调用分支。
这个顺序很有意义。
普通问答、文档总结、工具调用和 Agent 任务,虽然都发生在聊天主链上,但它们不应该混在同一套自由分支里。Agent 一旦命中,就要由 Runtime 接管整个流程,而不是让模型在普通回答中"顺便"调用几个工具、生成一段看起来像 tasklist 的文本。
我把它叫做 Runtime-controlled Agent Path(运行时控制的 Agent 路径),重点在 controlled。
模型当然参与生成,但它不是调度者。Runtime 才是调度者。
6. 主流程:从版本方案到 tasklistDraft v1 / v2
Tasklist Agent 的主流程并不复杂,但每一步都被 Runtime 固定住了。
text
read_resource
-> planExtract
-> draft_tasklist v1
-> validate_tasklist_structure
-> 可自动修正时 revise_tasklist v2
-> validate_tasklist_structure
-> final_answer换成更工程化的说法,就是:
- 先读用户显式引用的版本方案
- 再把版本方案收敛成结构化依据
- 再让模型生成第一版 tasklist 草稿
- 再交给确定性工具做结构校验
- 如果校验结果允许自动修正,最多生成第二版
- 第二版再校验一次
- 最后输出可复制结果和人工确认点
核心 runner(Agent 执行器,负责按固定顺序推进 draft、validate、revise、final)代码大概是这个节奏:
ts
let state = await runDraftTasklistStep(options)
const validationV1 = await runValidateTasklistStep({
draft: state.tasklistDraft,
state,
})
state = validationV1.state
if (shouldReviseTasklist(validationV1.result)) {
state = await runReviseTasklistStep({ state })
state = (await runValidateTasklistStep({ draft: state.tasklistDraft, state })).state
}
return runFinalAnswerStep({ state })这里最关键的不是"模型能生成 tasklist",而是 模型生成之后必须经过确定性质量门。
同时,本版只允许最多修正一次。也就是说,即使第二版仍然有问题,Agent 也不会无限循环,不会一直"再改改、再检查、再改改"。
这个边界很重要。
对一个初版 Agent 来说,最危险的不是它不能自动修正,而是它可以无限自动修正。
7. planExtract:先把版本方案收成结构化依据
如果直接把整份版本方案丢给模型,然后让它生成 tasklist,当然也能做。
但我不想让 Agent 的第一步就变成"模型自由阅读 + 自由总结 + 自由决定任务结构"。
所以本版中间加了一层 plan-extract(版本方案结构提取,负责从版本方案中抽取版本号、目标、非目标、关键变更、测试计划等依据)。
它的作用不是做复杂的文本理解算法,也不是把文档理解做到完美,而是先把方案里的关键依据整理成模型更容易稳定使用的输入骨架。
这样做有几个好处:
- tasklist 草稿能更明确地追溯到版本方案
- 最终回答可以说明"基于哪份版本方案生成"
- 后续校验可以围绕结构完整性,而不是完全依赖模型自我判断
- 人工 review 时更容易看出草稿是否偏离了方案
这也是我在第一个 Agent 里很想保留的一个原则:
Agent 不一定每一步都要靠模型"聪明地理解",有些步骤可以先把依据收窄,让模型在更清楚的输入上生成。
8. validate_tasklist_structure:给 Agent 加一个确定性质量门
这一版新增的工具里,最重要的是 validate_tasklist_structure(tasklist 结构校验工具,负责检查 tasklist 草稿是否具备必要结构)。
它不是让模型自己评价自己,而是用确定性规则检查 tasklist 草稿。
校验重点包括:
- 是否有标题
- 是否标明来源版本方案
- 是否有主要步骤(major steps)
- 是否有勾选项(checklist)
- 是否有验证内容
- 是否覆盖非目标、风险、暂停点、工程验证等关键区域
简化后的规则大概是这样:
ts
function getBlockingIssues(structure: TasklistStructure) {
if (!structure.title) {
issues.push('missing_title')
}
if (!structure.hasSourcePlanUri) {
issues.push('missing_plan_uri')
}
if (structure.steps.length === 0) {
issues.push('missing_steps')
}
if (structure.checklistItems.length === 0) {
issues.push('missing_checklist')
}
if (!structure.hasAnyVerificationContent) {
issues.push('missing_verification')
}
}这里的设计很朴素,但我认为非常值得做。
因为 Agent 任务里最常见的问题之一,是模型生成的内容"看起来很完整",但缺了关键结构。比如没有测试计划、没有验收条件、没有来源方案、没有暂停确认点。
这些问题不一定需要另一个模型来判断。至少在第一版里,我们可以先用确定性规则挡住一批明显问题。
所以 validate_tasklist_structure 的价值不是让 tasklist 变得完美,而是让 Agent 多一道最低质量门。它检查的是结构是否完整,不负责判断内容质量是否已经足够优秀。
9. Tool 也要受控:注册了,不等于普通问答能随便调
这里还有一个很容易被忽略的点:validate_tasklist_structure 虽然是一个工具,但它不应该变成普通聊天随便能调用的工具。
在 AI Mind 里,Tool Runtime(工具运行时,负责把模型请求的工具调用映射到真实工具执行)已经逐步从早期的 allowedTools 迁移到 capability-driven(基于能力描述解析本轮可用工具)的链路。到了这个版本,Tasklist Agent 里的工具也继续沿用这个原则:
Agent scope -> active tool map(本轮活跃工具表) -> validate_tasklist_structure -> Tool Runtime 执行
也就是说,工具注册在工具层,不等于每一轮对话都能暴露给模型。
validate_tasklist_structure 只在 Tasklist Agent 的受控范围里使用。普通问答不会因为项目里多注册了这个工具,就突然多一个可自由调用的结构校验工具。
这个边界对后续 Agent 很关键。
如果每做一个 Agent 都顺手把工具暴露到全局,Runtime 很快就会变成"所有能力在所有场景里都可能被模型看到"。这会让调试、权限、前端展示和结果归因都变复杂。
所以这版的原则是:
Tool 可以复用,但暴露范围必须由 Runtime 和 capability 决定。
10. AgentState:只保存本轮草稿,不写文件
Tasklist Agent 会产生 tasklistDraft v1,必要时还会产生 tasklistDraft v2。
但这些内容只保存在本轮 AgentState(Agent 本轮状态,保存草稿、校验结果、修正次数和最终输出)里。它只存在于本轮请求内,不持久化,不写入 docs/tasklists/,也不会自动修改任何项目文件。
这是一个非常刻意的边界。
因为 tasklist 不只是模型生成物,它会影响后续版本开发节奏。即使 Agent 已经生成了不错的草稿,也应该由人确认后再落地。
所以 final answer(最终回答输出节点)会把结果整理成可复制内容,而不是替用户做文件写入。
最终回答里会包含三块:
- tasklist 草稿正文
- 结构校验结论
- 人工确认点
也就是说,Agent 帮我们把"从方案到任务清单"的第一版草稿做出来,但最后一步仍然留给开发者。
我很喜欢这个边界。
它让 Agent 真正参与了工程流程,但没有越过"自动改项目资产"的线。
11. AgentTracePanel:让 Agent 的步骤变得可见
如果 Agent 的步骤都藏在后端日志里,前端用户只能看到最终一段回答,那它仍然很像一个黑盒。
这一节也是前端读者最值得看的部分之一:Agent 的价值不只在后端跑通,还在于前端能不能把"它到底做了什么"表达出来。
所以本版新增了 Agent Step(Agent 执行步骤)流式事件,并在前端通过 AgentTracePanel(Agent 执行过程面板,负责展示步骤、状态、耗时、标签、资源和工具结果)聚合展示。
流式协议里新增了 agent-step-start 和 agent-step-end:
ts
export interface AgentStepStartChunk {
actionType: AgentStepActionType
agentName: string
partId: string
runId: string
stepIndex: number
title: string
type: 'agent-step-start'
}
export interface AgentStepEndChunk {
durationMs?: number
error?: string
partId: string
runId: string
status: AgentStepStatus
summary?: string
type: 'agent-step-end'
}前端消费时,会把同一个 runId 下的步骤合并到同一个 Agent trace(Agent 执行轨迹)里。与此同时,Resource / Tool 的细节不会再重复散落成多个顶层调试卡片,而是折叠进对应 Agent step。
这件事对前端体验很重要。
因为用户不一定需要知道每一个内部对象的技术细节,但前端应该知道本轮发生了什么,并且能用合适的方式表达出来:
- Agent 什么时候开始
- 当前执行到哪一步
- 哪一步读了资源
- 哪一步调用了结构校验工具
- 是否发生了自动修正
- 最终结果是否通过校验
这就是我之前一直强调的"执行过程可视化":不是把所有 JSON 都甩给用户,而是把 AI Runtime 的关键事实翻译成产品上可理解的过程。
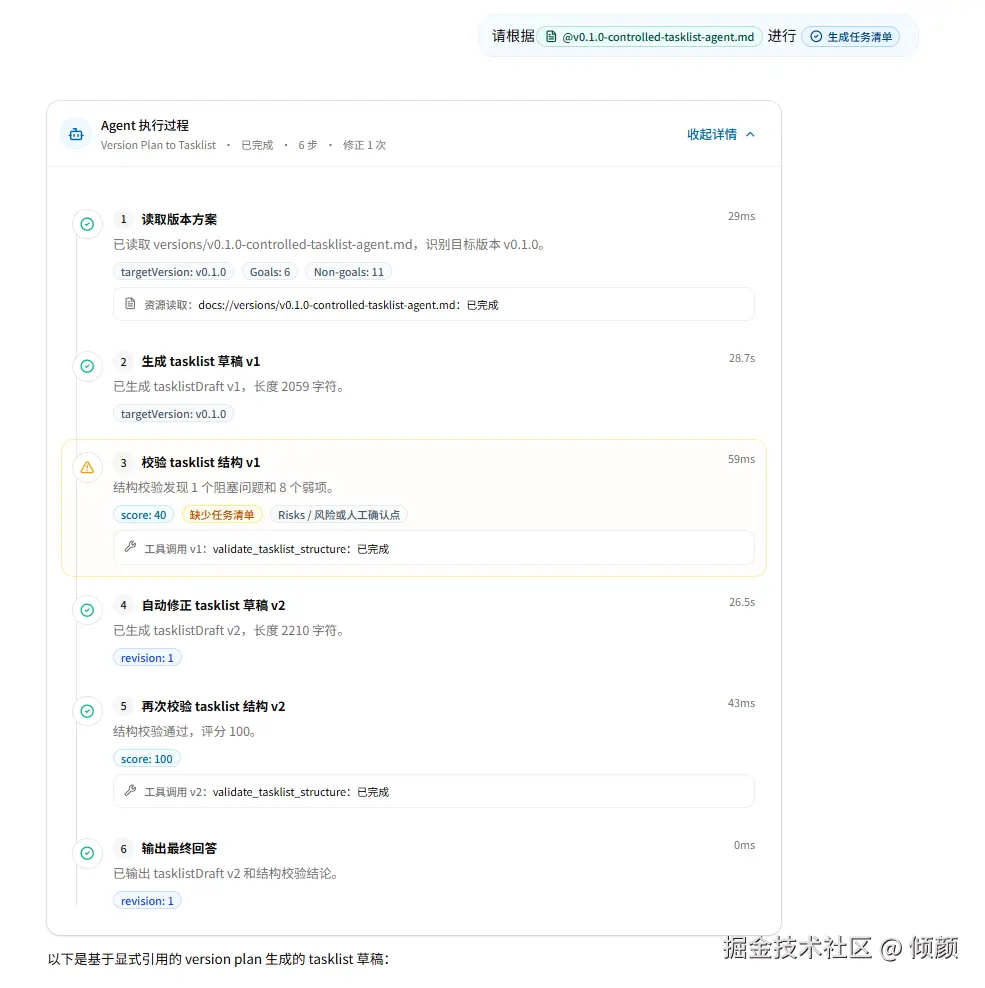
12. final_answer:最终输出要能复制,也要能人工确认
Tasklist Agent 最终不是输出一句"我已经帮你生成好了",而是要给出可复制的 tasklist 草稿。
这也是我在做 final answer 时特别关注的地方。
一个工程项目里的 Agent 输出,不应该只追求"像聊天回答",还要考虑它是否能接上真实工作流。
所以本版最终输出会尽量包含:
- 基于哪份版本方案
- tasklist 草稿正文
- 结构校验状态
- 如果发生自动修正,说明修正次数
- 仍然需要人工确认的点
- 明确说明没有自动写入文件
这让 Agent 的输出更像一个"待确认工程草稿",而不是一个"看起来完整的自然语言回答"。
在我看来,这也是 Tasklist Agent 和普通问答最大的区别之一:
普通问答追求回答清楚,Tasklist Agent 还要追求产物可接力。
13. 这版刻意没有做什么
为了让第一个 Agent 真的站稳,本版刻意没有做很多听起来更"Agent"的东西。
比如:
- 不做通用 Agent Runtime
- 不做"模型先规划步骤,再按步骤调用工具执行"的开放式 Agent
- 不做多 Agent
- 不做长期记忆
- 不做 RAG / chunking / indexing
- 不做自动扫描
docs/versions/ - 不做自动发现最新版本方案
- 不读取历史 tasklist
- 不写入
docs/tasklists/ - 不生成版本方案
- 不从用户目标直接生成 tasklist
- 不让
/tasklist变成远程 Prompt 的立即执行按钮 - 不让
/check变成远程 Tool 的立即执行按钮
这些非目标不是因为它们不重要,而是因为它们都不是第一个 Agent 最应该先验证的问题。
这一版真正要验证的是:
一个 Agent 能不能先在 Runtime 里被明确触发、明确约束、明确观察、明确停止。
只要这条链路跑稳,后面再谈更复杂的 Agent 才有基础。
14. 这版真正让我确认了什么
做完 v0.1.0 后,我对 Agent 在 AI Mind 里的位置更清楚了。
第一,Agent 不是一层"更聪明的回答逻辑",而是一条需要 Runtime 明确托管的执行路径。
如果 Agent 只是在 prompt 里写一句"请一步步思考并调用工具",那它很难被前端观察,也很难被工程边界约束。
第二,第一个 Agent 不应该追求通用,而应该追求可解释。
这次 Tasklist Agent 的价值,不在于它能做多少事,而在于它把一件事做成了可控链路:
显式入口 -> 受控状态机 -> 确定性质量门 -> 最多一次自动修正 -> 前端步骤可视化 -> 可复制最终草稿
第三,前端不是 Agent 的末端展示层,而是 Agent 可观察性的产品化表达层。
如果没有 AgentTracePanel,后端即使有状态机、有工具、有校验,用户看到的也只是最后一段文本。前端把这些执行事实组织出来,Agent 才从"黑盒回答"变成"可理解过程"。
第四,Agent 不应该绕过已有能力体系。
这一版仍然复用了 Composer(AI 输入框 / 输入层)的 /tasklist、@resource,复用了 docs resource 边界,复用了 Tool Runtime 和既有流式协议内核 stream-core。也就是说,Agent 不是另起炉灶,而是长在已有 Runtime Skeleton 上。
这对后续继续做 Agent 很关键。
15. 结尾:第一个 Agent,先做小一点
如果只看功能描述,v0.1.0 好像只是多了一个 Tasklist Agent。
但对我来说,这一版的意义更像是:AI Mind 第一次把 Agent 放进了可控工程结构里。
它只是把一条非常窄的链路跑通:
text
/tasklist + 版本方案
-> 任务清单草稿
-> 结构校验
-> 最多一次自动修正
-> 可复制最终回答这条链路不大,但它给后续 Agent Runtime 留下了一个很重要的基准:
Agent 可以不是一开始就"无所不能",它可以先在一个明确场景里做到可触发、可约束、可观察、可接力。
后面我会继续沿着这个方向推进:让 Agent 在保持受控的前提下,逐步接入更完整的执行过程、状态表达和数据层能力,而不是一上来就把它做成不可调试的黑盒。
项目地址:
如果你也在学习 AI 应用前端、Tool Calling、MCP、Skill Runtime 或 Agent Runtime,可以点个 Star。这个项目会继续按版本更新,每一版都会配套源码、设计文档、tasklist、release 和复盘文章。