在日常办公或数据处理任务中,我们经常需要将 Word 文档里分散的表格汇总到 Excel 中进行计算或分析。面对几十页甚至上百页的文档,手动复制+粘贴不仅效率低下,且极易出现单元格错位、格式丢失等问题。本文将带你探索如何利用 Python 实现数据从 Word 到 Excel 的自动化迁移。
为什么选择自动化方案?常见技术方案对比
在处理 Word 表格导出任务时,开发者有多种选择,比如手动复制、使用 VBA 等等。我们需要根据业务场景、开发成本以及处理效果来找到最适合的:
- 手动复制粘贴:适用于处理极少量的单一表格。缺点在于无法保持长文本的段落格式,且在处理含有合并单元格的复杂表格时,数据容易发生偏移。
- VBA (Visual Basic for Applications):Office 自带的脚本语言,可以快速将 Word 中的表格导出。虽然无需安装第三方库,但其语法陈旧、调试困难,且高度依赖 Microsoft Office 环境,无法在没有安装 Office 的服务器或 Linux 环境上运行,具有一定的设备局限性。
- 开源 Python 库(如 python-docx):这类工具灵活性高,但在处理复杂格式(如嵌套表格、复杂的行列跨度映射)时,往往需要编写大量底层逻辑代码,开发成本较高,需要具备一定的编程知识。
- 专业类库(Spire 系列组件) :功能强大、API 简单易懂。它最大的优势在于独立性 (无需安装 Office)和高集成度。它将复杂的 Word DOM 结构映射与 Excel 坐标系转换进行了底层封装,开发者只需通过简单的 API 调用,就可以精准保留原文档的逻辑结构和文本格式。
方案对比表:
| 维度 | 手动操作 | VBA 宏 | 开源 Python 库 | Spire 系列专业组件 |
|---|---|---|---|---|
| 执行效率 | 极低 | 中 | 高 | 极高 |
| 环境依赖 | 需人工参与 | 需安装 Office | 需配置多种依赖 | 独立运行(零依赖) |
| 合并单元格支持 | 差(易乱序) | 较好 | 一般(需自行实现逻辑) | 完美支持 |
| 复杂场景适配 | 难 | 较难 | 难 | 易(API 高级封装) |
综合来看,对于追求高效率和系统稳定性的企业级开发,使用 Spire.Doc for Python 配合 Spire.XLS for Python 是当前最优的实战选型。
环境准备
在开始编写脚本之前,请确保你的 Python 环境中已安装相关组件。这两个库分别负责解析 Word 的流式文档结构和构建 Excel 的行列坐标体系:
bash
pip install Spire.Doc
pip install Spire.XLS你可以分别安装 Word 和 Excel 组件,也可以直接安装 Spire.Office for Python,它包含了 Spire.Doc for Python,Spire.XLS for Python,Spire.Presentation for Python 和 Spire.PDF for Python。此外所有组件都提供免费版用于小项目或测试。
如何构建 Python 导出表格的代码
为了让你更清晰地理解 Spire.Doc 和 Spire.XLS 导出 Word 表格的逻辑,我们将整个实现过程拆解为以下核心步骤:
1. 引入必要的类库
首先,我们需要在脚本开头引入 Spire 的核心模块。通过引入 spire.doc 和 spire.xls 及其通用常量模块,我们才能在 Python 中调用其封装好的文档处理引擎,从而实现对 Word DOM 树的解析和 Excel 工作簿的构建。
python
from spire.doc import *
from spire.doc.common import *
from spire.xls import *
from spire.xls.common import *
import os2. 初始化对象与加载源文件
分别创建 Document 和 Workbook 对象。随后,使用 LoadFromFile 方法加载待处理的源 Word 文档,并调用 Worksheets.Clear() 移除工作簿中默认生成的空白表,以确保输出结果不受默认工作表的干扰。
python
# 创建 Word 文档对象并加载文件
document = Document()
document.LoadFromFile("E:/input/项目进度.docx")
# 创建 Excel 工作簿并清空默认工作表
workbook = Workbook()
workbook.Worksheets.Clear()3. 遍历 Word 文档多层级结构
Word 的数据存储具有明显的层级性(Section > Table > Row > Cell)。我们需要使用嵌套循环依次遍历文档中的 Section (节) 和 Table (表格) 。对于每一个发现的表格,我们通过 workbook.Worksheets.Add() 动态创建一个工作表,并通过 sheet_index 实现自动命名,确保一表一页。
python
sheet_index = 0
for s in range(document.Sections.Count):
section = document.Sections.get_Item(s)
tables = section.Tables
for t in range(tables.Count):
table = tables.get_Item(t)
# 动态创建工作表并递增索引
sheet = workbook.Worksheets.Add(f"Table_{sheet_index + 1}")
# ... (后续数据提取)
sheet_index += 14. 提取单元格文本与格式映射
由于 Word 单元格内可能包含多个段落,所以我们需要遍历 Paragraphs 集合并手动拼接换行符 \n,以保留文本的原始换行结构。最后,通过 Style.WrapText = True 开启 Excel 的自动换行功能。
python
# 遍历行与列
for r in range(table.Rows.Count):
row = table.Rows.get_Item(r)
for c in range(row.Cells.Count):
cell = row.Cells.get_Item(c)
cell_text = ""
for p in range(cell.Paragraphs.Count):
paragraph = cell.Paragraphs.get_Item(p)
cell_text += paragraph.Text.strip() + "\n"
# 写入 Excel 坐标并设置换行
sheet.Range[r + 1, c + 1].Text = cell_text.strip()
sheet.Range[r + 1, c + 1].Style.WrapText = True5. 自动化布局优化与资源释放
数据填充完成后,利用 AutoFitColumns() 和 AutoFitRows() 方法让程序自动根据内容调整列宽和行高。最后释放内存,确保系统资源回收。
完整代码示例
将上述的步骤整合,即可得到这个高效的 Word 表格导出脚本:
python
from spire.doc import *
from spire.doc.common import *
from spire.xls import *
from spire.xls.common import *
import os
# 创建 Word 文档对象并加载文件
document = Document()
document.LoadFromFile("/input/项目进度.docx")
# 创建 Excel 工作簿并删除默认工作表
workbook = Workbook()
workbook.Worksheets.Clear()
# 遍历 Word 文档中的所有节
sheet_index = 0
for s in range(document.Sections.Count):
section = document.Sections.get_Item(s)
# 获取当前节中的所有表格
tables = section.Tables
for t in range(tables.Count):
# 获取当前表格
table = tables.get_Item(t)
# 新建工作表
sheet = workbook.Worksheets.Add(f"Table_{sheet_index + 1}")
# 遍历表格行
for r in range(table.Rows.Count):
row = table.Rows.get_Item(r)
# 遍历单元格
for c in range(row.Cells.Count):
cell = row.Cells.get_Item(c)
# 提取单元格中的文本
cell_text = ""
for p in range(cell.Paragraphs.Count):
paragraph = cell.Paragraphs.get_Item(p)
cell_text += paragraph.Text.strip() + "\n"
# 去除末尾换行
cell_text = cell_text.strip()
# 写入 Excel 单元格
sheet.Range[r + 1, c + 1].Text = cell_text
# 设置自动换行
sheet.Range[r + 1, c + 1].Style.WrapText = True
# 自动调整列宽行高
sheet.AllocatedRange.AutoFitColumns()
sheet.AllocatedRange.AutoFitRows()
sheet_index += 1
# 保存为 Excel 文件
workbook.SaveToFile("/output/word表格.xlsx", ExcelVersion.Version2016)
document.Close()
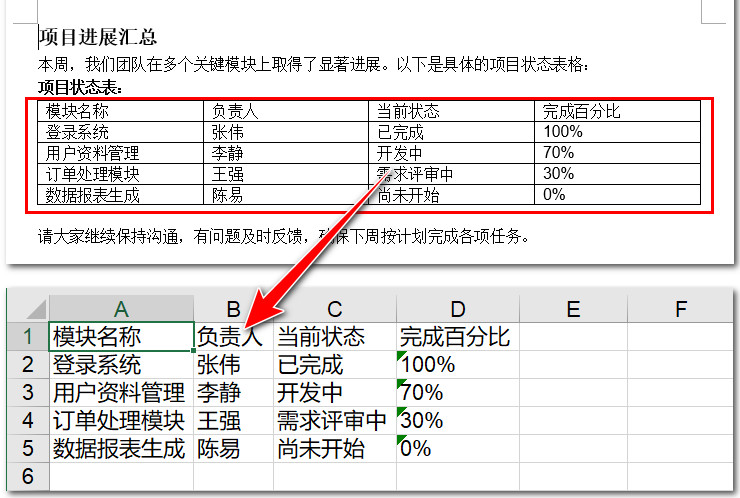
workbook.Dispose()下面是原始 Word 文档与提取到的表格的对比示意图:
结语
通过 Python 结合 Spire.Doc 与 Spire.XLS 库,我们仅需几十行代码就能解决复杂的文档数据提取难题。这种方案不仅保留了原始数据的段落结构,还通过自动化布局极大提升了结果文件的可用性。如果你正在处理大批量的文档自动化工作,不妨尝试这种更专业、更稳健的开发路径。