随着 AI 语音技术快速发展,文本转语音(TTS)模型正从「能说话」迈向「像真人一样自然交流」,但在多语言覆盖、零样本语音克隆以及复杂口音与方言支持等方面,现有系统仍普遍面临生成链路复杂、训练成本高、跨语言泛化能力有限等问题。
在这一背景下,OmniVoice 的发布,为多语言语音生成带来了新的突破。该模型由 Xiaomi AI Lab Next-gen Kaldi 团队推出,支持超过 600 种语言,并同时具备 Voice Clone、Voice Design 与 Auto Voice 等能力。相比传统 TTS 模型普遍采用的「文本→语义→声学」两阶段生成流程,OmniVoice 采用了一种类似扩散语言模型的离散非自回归(NAR)架构,可直接将文本映射为多码本声学 token,大幅简化了语音生成链路。
这种架构上的变化,不仅降低了传统离散 NAR 模型在复杂流程中的性能瓶颈,也让 OmniVoice 在语音自然度、可懂度以及跨语言一致性上取得了更好的表现。与此同时,模型还引入全码本随机掩码训练策略,并基于预训练大语言模型进行初始化,在提升训练效率的同时,进一步增强了语音生成质量。
更重要的是,OmniVoice 并不只是一个「支持多语言」的 TTS 模型。它不仅覆盖中文、英文、日文、韩文等主流语言,还支持河南话、四川话、东北话等中文方言,以及美式、英式、澳式、印度口音等多种英语变体。配合仅需数秒参考音频即可完成的零样本语音克隆能力,使其在 AI 配音、数字人、跨语言内容生成以及全球化语音交互等场景中展现出极强的应用潜力。
目前,HyperAI 官网(hyper.ai)的教程版块已经上线了「OmniVoice:支持 600+ 语言的高质量 TTS」,一键即可启动,低门槛部署。
在线运行:
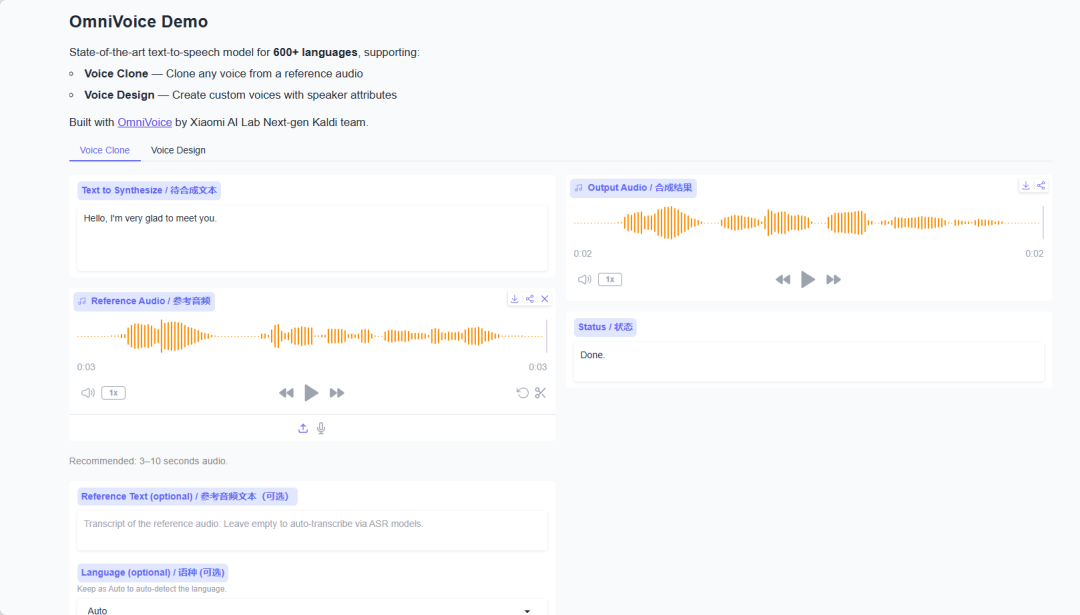
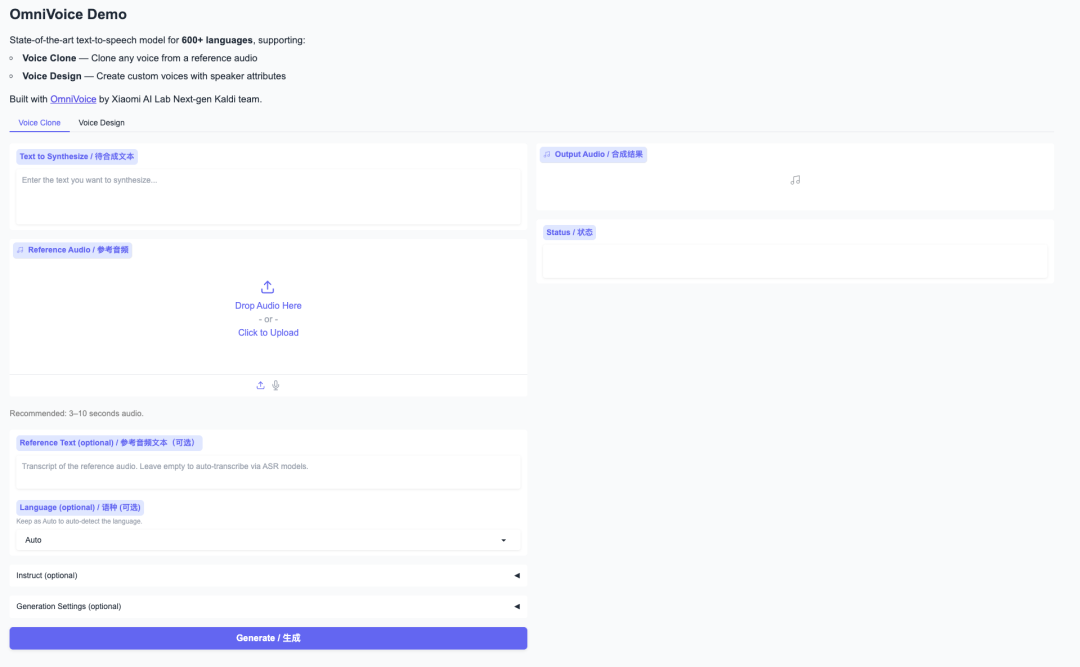
demo 示例
更多在线教程:
欢迎登录官网查看更多内容:
Demo 运行
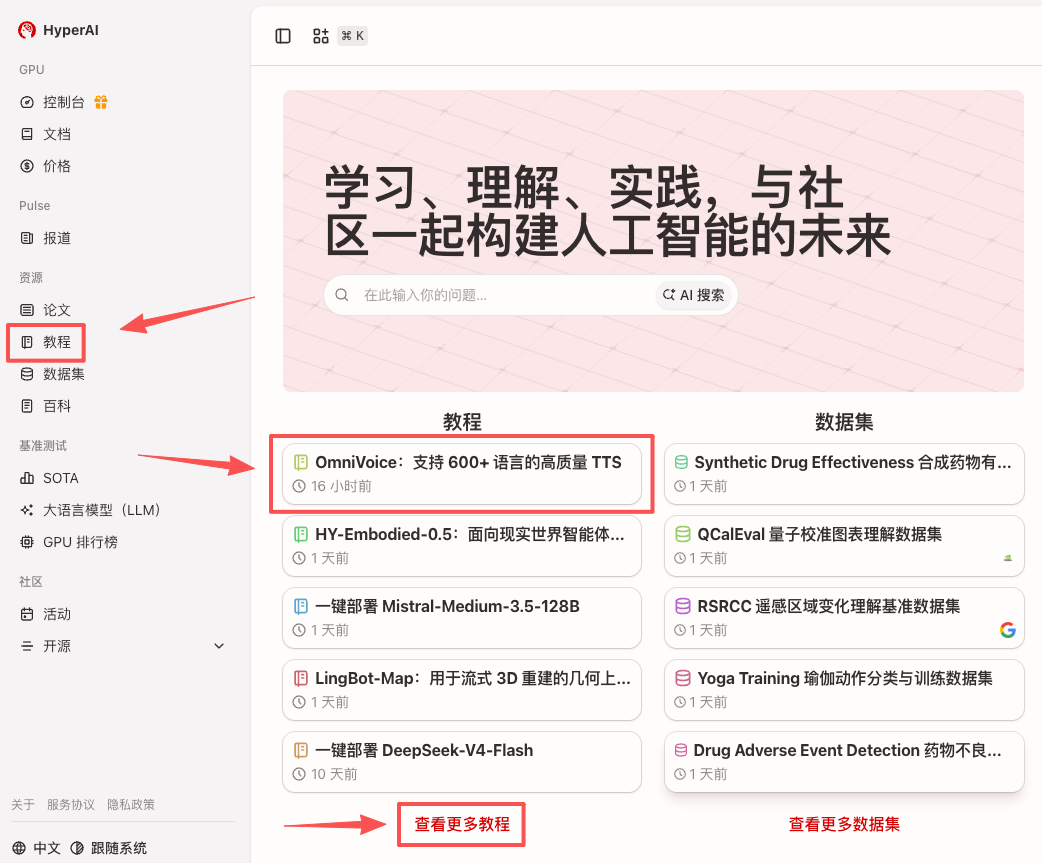
1.进入 hyper.ai 首页后,选择「教程」页面,或点击「查看更多教程」,选择「OmniVoice:支持 600+ 语言的高质量 TTS」,点击「运行此教程」。
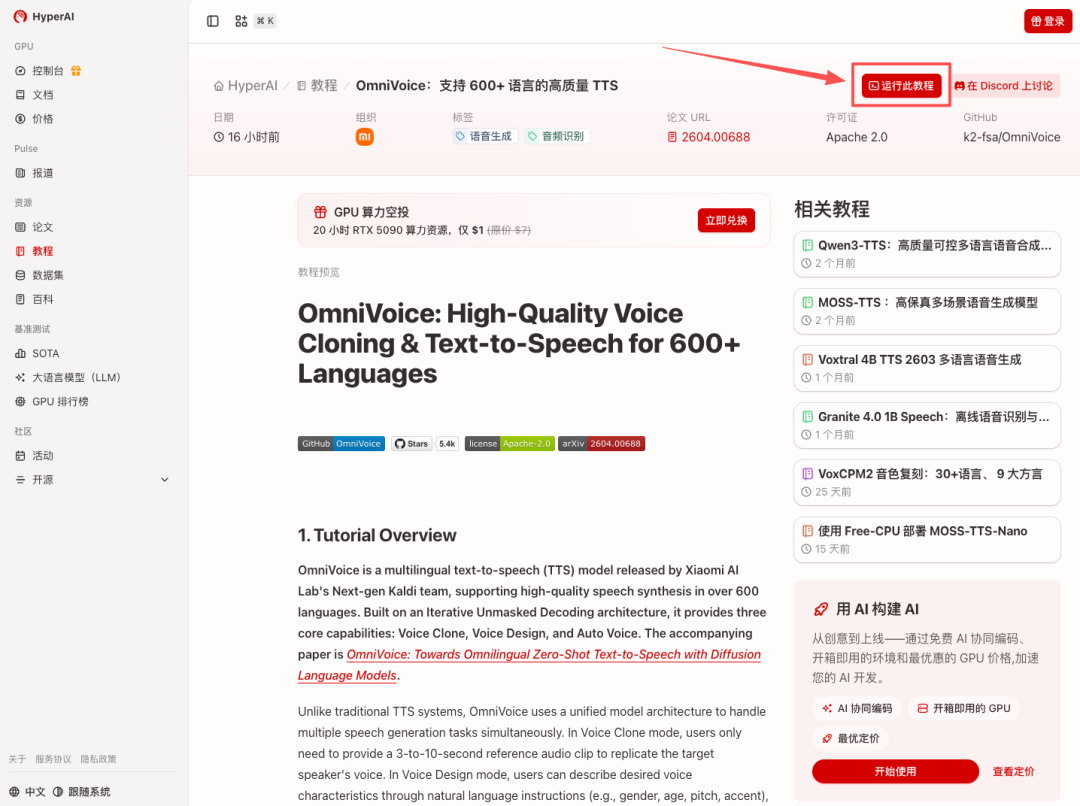
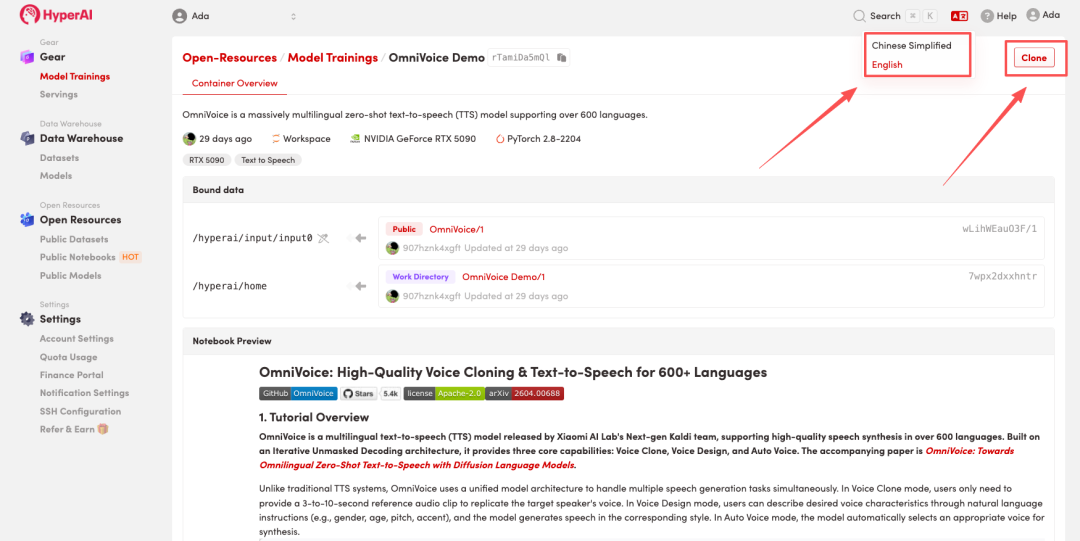
2.页面跳转后,点击右上角「Clone」,将该教程克隆至自己的容器中。
注:页面右上角支持切换语言,目前提供中文及英文两种语言,本教程文章以英文为例进行步骤展示。
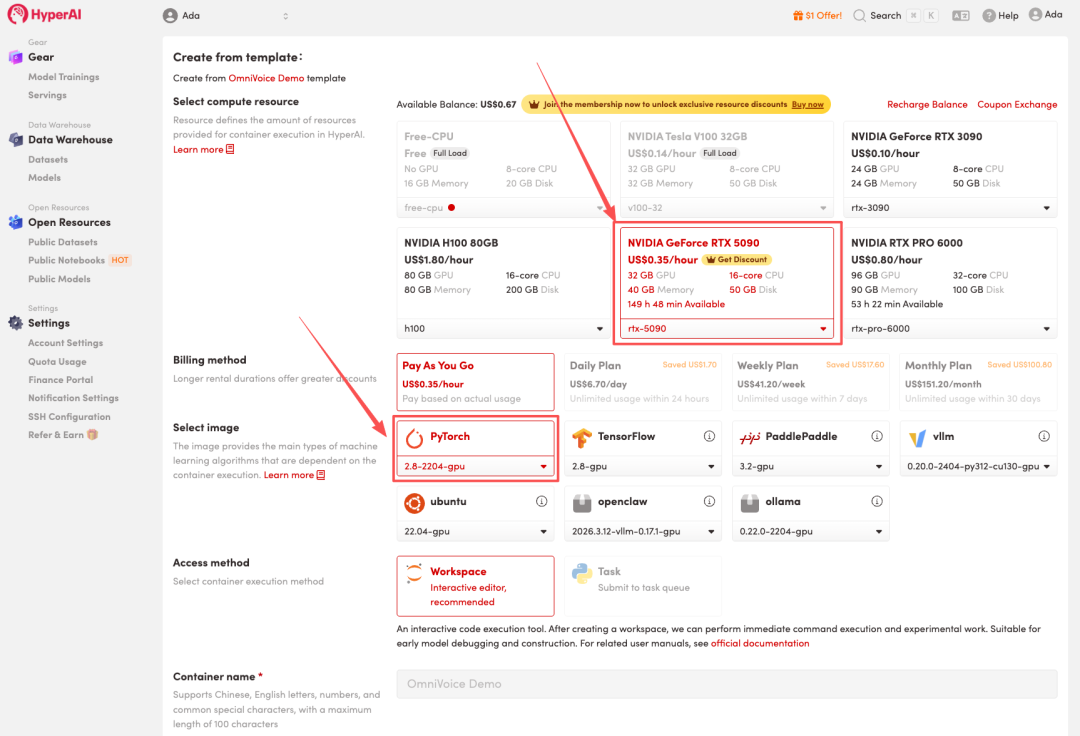
3.选择「NVIDIA RTX 5090」以及「PyTorch」镜像,点击「Continue job execution(继续执行)」。
HyperAI 为新用户准备了注册福利,仅需 1,即可获得 20 小时 RTX 5090 算力(原价 7),资源永久有效。
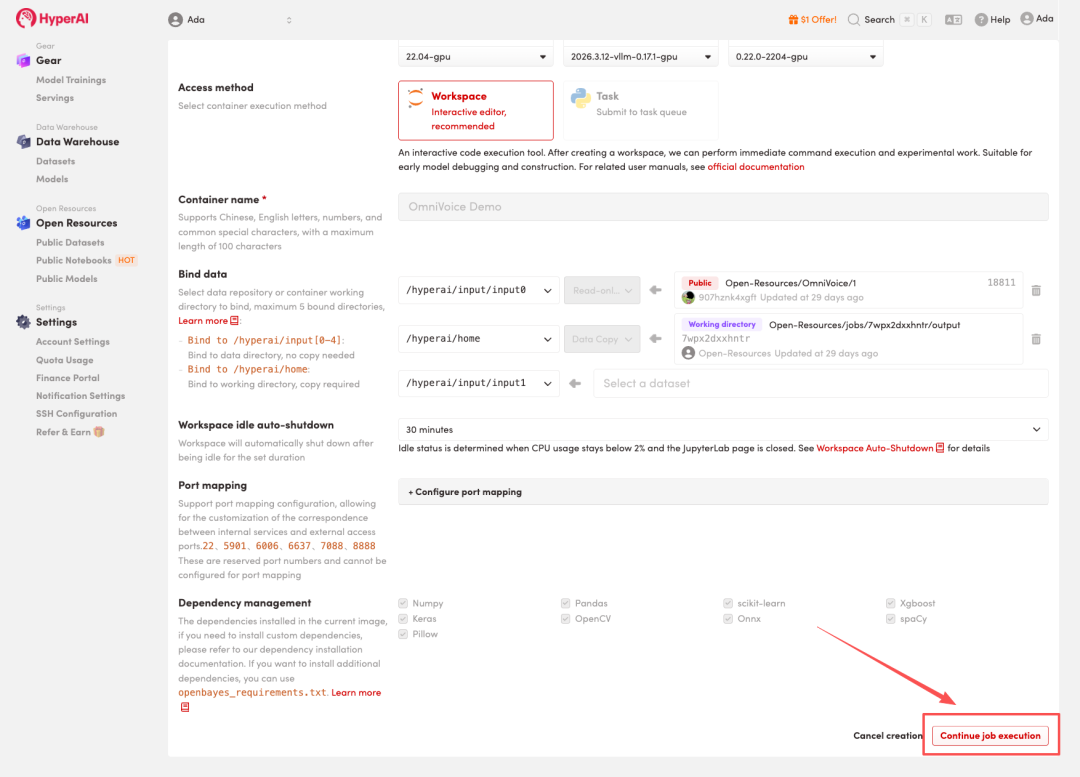
4.等待分配资源,当状态变为「Running(运行中)」后,点击「Open Workspace」进入 Jupyter Workspace。
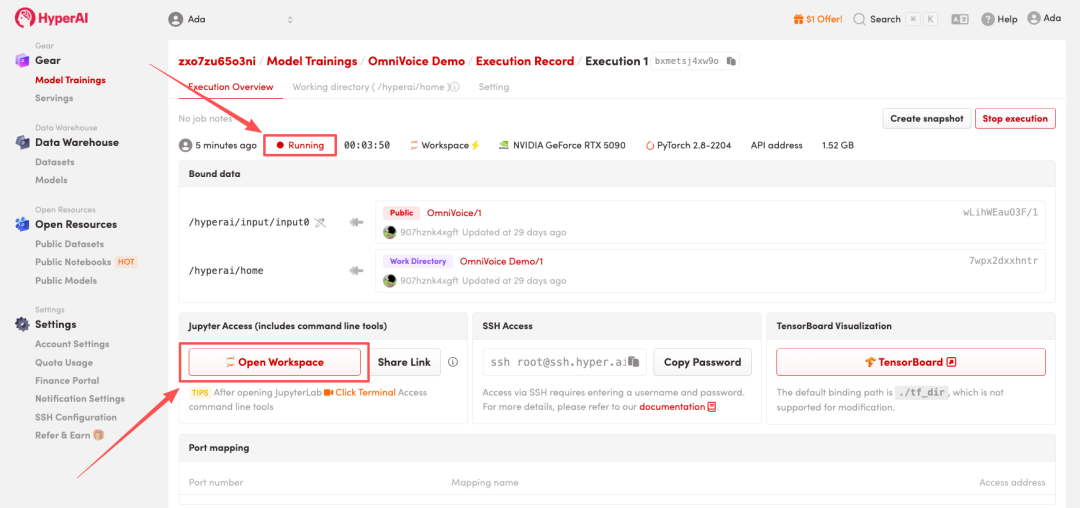
效果展示
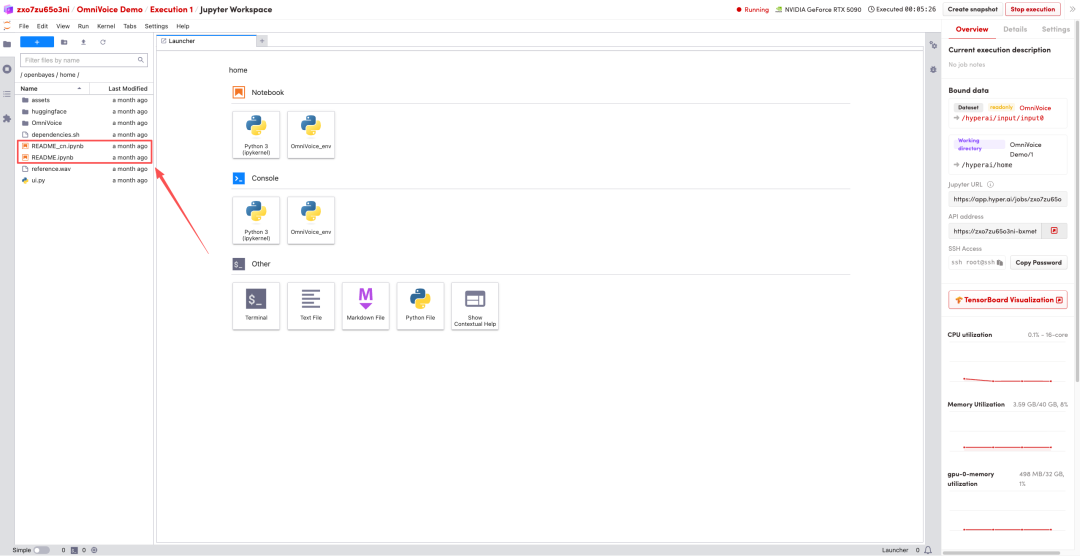
1.页面跳转后,点击左侧 README 文件,进入后点击上方 Run(运行)。
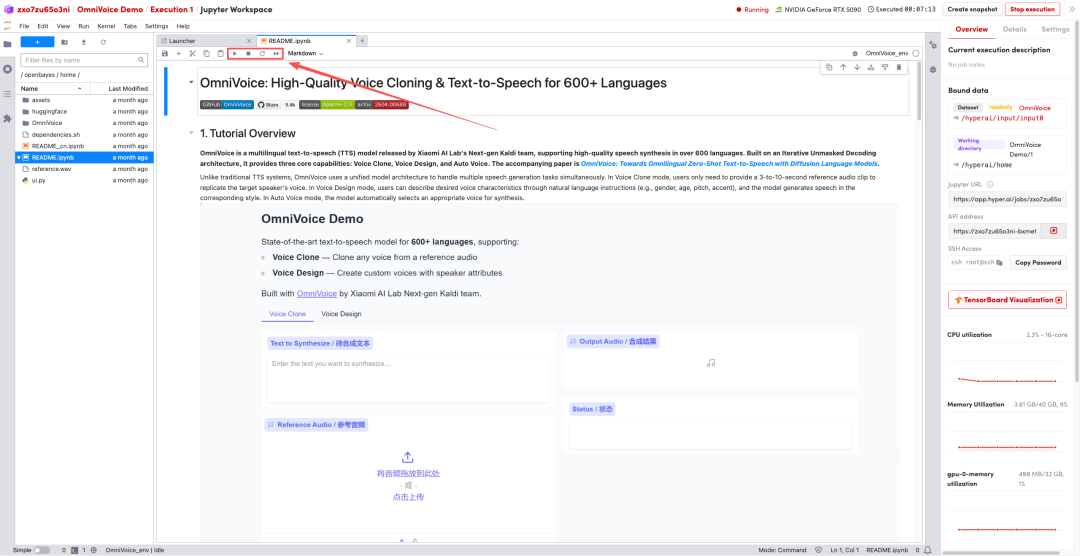
2.待运行完成后,即可点击右侧 API 地址跳转至 demo 页面。