Claude 4 vs GPT-5:2026年开发者大模型 API 选型完整指南
Claude Opus 4.6 与 GPT-5 是 2026 年企业级 API 部署的两大顶级选择。Claude Opus 4.6 以百万 Token 超长上下文和 SWE-bench Verified 80.8% 的代码理解能力见长;GPT-5 标准版以更低的输入定价($1.25/M Token)和更快的推理速度在成本敏感场景占优。选择哪个,取决于你的核心场景和预算上限。
核心参数一览
维度 Claude Opus 4.6 GPT-5(标准版)
上下文窗口 1,000,000 Token 400,000 Token
输入价格 15.00/M Token 1.25/M Token
输出价格 75.00/M Token 10.00/M Token
视觉能力 ✅ ✅
SWE-bench Verified 80.8% ~80%
SWE-bench Pro 45.89%(Opus 4.5) 57.7%(GPT-5.4)
Terminal-Bench --- 75.1%
Computer Use --- ✅
发布方 Anthropic OpenAI
数据来源:pricepertoken.com、morphllm.com、benchlm.ai,2026年5月数据。
两个模型均支持多轮对话、函数调用(Tool Use)和批量 API 处理。GPT-5 还拥有 Computer Use 能力(直接控制浏览器和桌面),Claude Opus 4.6 则在 1M Token 超长上下文方面无对手。
性能基准:编码与推理谁更强?
代码生成与重构是开发者最关心的维度。
根据 BenchLM 2026 年综合排行,GPT-5.4 在整体综合得分上略微领先,Claude Opus 4.6 紧随其后,差距极小。细分来看:
●SWE-bench Verified(真实 GitHub Issue 修复):Claude Opus 4.6 以 80.8% 略高于 GPT-5 的约 80%
●SWE-bench Pro(更复杂多文件工程任务):GPT-5.4 以 57.7% 领先 Opus 4.5 的 45.89%
●Terminal-Bench 2.0(终端自主执行任务):GPT-5 系列占据前列,终端操控能力更强
●代码重构与保守修改:SitePoint 开发者基准测试中,Claude Sonnet 4.6 平均每任务高出 GPT-5 约 2.6 分,更擅长"最小改动、不引入回归"场景
●TypeScript 严格模式:Claude 生成的代码通过 tsc --strict 校验的比例高于 GPT-5
结论:复杂多文件重构和长代码库理解场景选 Claude;SWE 级别的自主 Agent 修 Bug 和终端执行场景选 GPT-5。
定价深度拆解:同样的预算能跑多少请求?
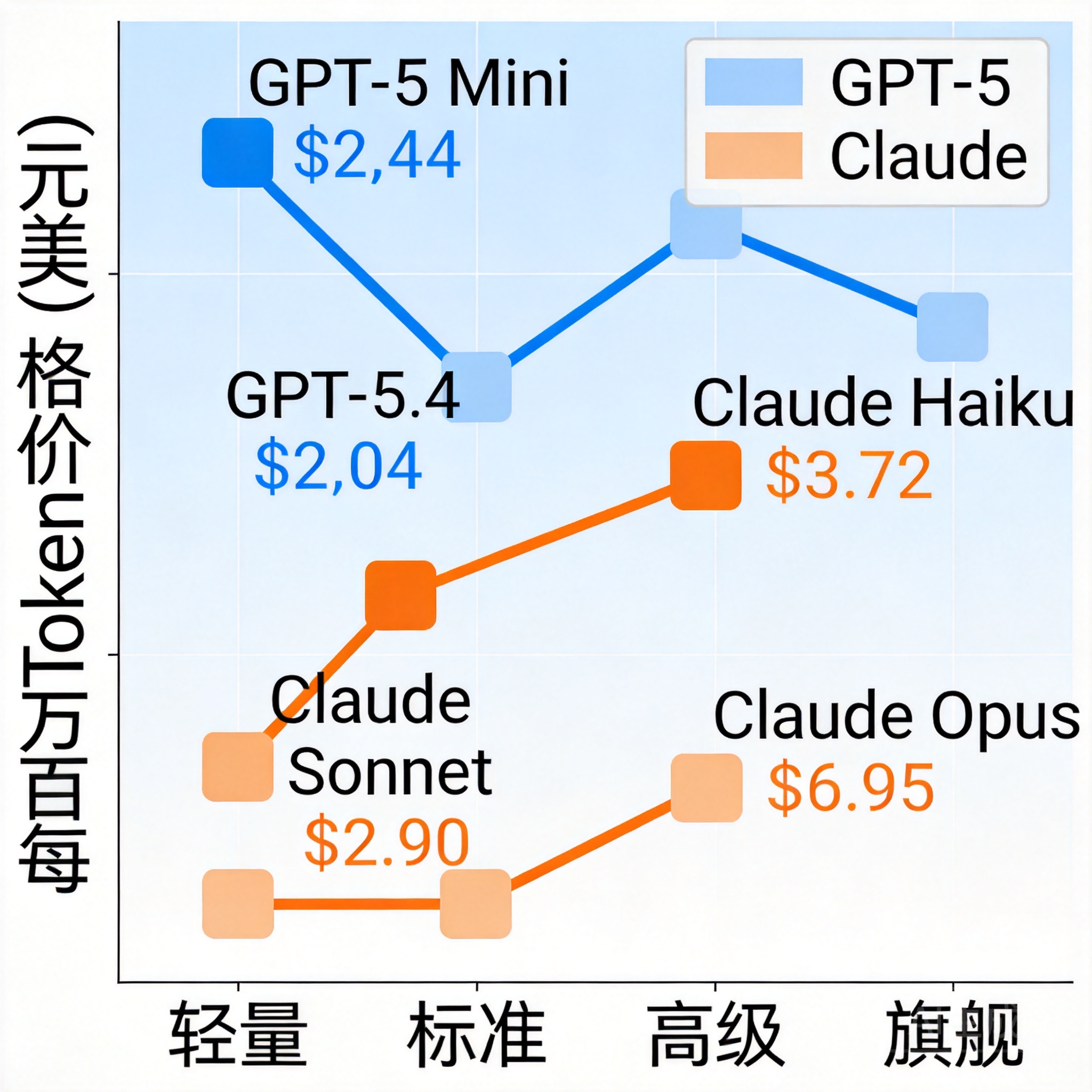
Claude 和 OpenAI 均提供分级产品线,实际成本差异可达 10 倍以上:
模型 输入价格 输出价格 适用场景
GPT-5 Mini 0.25/M 2.00/M 高频轻量任务(FAQ、分类、摘要)
GPT-5 标准 1.25/M 10.00/M 通用应用主力模型
GPT-5.4(高性能) 2.50/M 15.00/M 推理密集型任务
Claude Haiku 4.5 1.00/M 5.00/M 轻量对话,成本优先
Claude Sonnet 4.6 3.00/M 15.00/M 中端主力,含 1M 上下文
Claude Opus 4.6 15.00/M 75.00/M 顶级推理、长文档分析
实际成本换算(以 1000 次请求 × 平均 2000 Token 输入 + 500 Token 输出为例):
●GPT-5 标准:约 $2.75
●Claude Sonnet 4.6:约 $7.50
●Claude Opus 4.6:约 $37.50
对于高频 API 调用场景,GPT-5 标准版的性价比优势明显。Claude 的成本优势体现在超长上下文:Sonnet 4.6 和 Opus 4.6 均以标准价格提供完整 1M Token 上下文,无需额外付费------而处理同等长度文档时,竞品通常收取额外溢价。
根据 SiliconData 2026 年 3 月 API 定价报告,Claude API 价格在过去一年已下降约 40%,持续向开发者友好方向演进。
四大核心场景:怎么选才对?
场景一:长文档分析与知识库问答
选 Claude Opus 4.6 或 Sonnet 4.6。
1M Token 上下文意味着可以一次性传入约 75 万字的 PDF 报告,或整个中型代码仓库,无需分块检索。GPT-5 的 400K 上下文虽也可观,但在超长文档场景仍需额外工程。
典型应用:法律合同批量审查、财报全文分析、大型代码库 Code Review。
场景二:高频轻量 API(对话机器人、内容分类)
选 GPT-5 Mini 或 GPT-5 标准版。
GPT-5 Mini 以 0.25/M 输入提供可用质量,是目前主流商业模型中性价比最高的轻量级选择。Claude Haiku 4.5 定价 1/M,适合对准确性要求稍高的轻量任务。
场景三:自主 Agent / 工作流自动化
GPT-5 更全面,Claude 更稳健。
GPT-5 的 Computer Use(浏览器/桌面控制)、五级推理模式控制,以及 Terminal-Bench 75.1% 的执行成功率,使其在端到端自动化任务中更强。Anthropic 的 MCP(Model Context Protocol)标准则让 Claude 在结构化工具调用和 Agent 编排上表现更一致,与 n8n、Dify 等框架集成更顺滑。
场景四:内容创作与写作
选 Claude。
根据 AImagicX 2026 年 4 月基准报告,Claude Opus 4.6 在写作质量上领先 GPT-5.4,在 Gemini 3.1 Pro 的对比中也保持优势。长文生成、多风格写作、文档撰写场景 Claude 更自然。
如何不改代码在两个模型之间切换?
Claude 和 OpenAI 的 SDK 结构不同,直接切换需要改接口调用方式。有一种方案可以规避这个问题:
部分推理平台(如https://www.qiniu.com/ai/models )同时兼容 OpenAI 和 Anthropic 双 API 格式,接入后可通过切换 model 参数在 Claude Opus 4.6、GPT-5、DeepSeek 等模型间自由切换,无需修改业务代码,适合需要 A/B 测试不同模型的团队。
标准 OpenAI SDK 调用示例:
from openai import OpenAI
client = OpenAI(
api_key="your_api_key",
base_url="https://your-proxy-endpoint/v1"
)
切换模型只需改 model 参数
response = client.chat.completions.create(
model="claude-opus-4-6", # 或 "gpt-5",其余代码不变
messages={"role": "user", "content": "请分析以下代码的性能问题..."}
)
这种方式还便于在生产环境中做成本对比:对同一批任务分别调用 GPT-5 和 Claude Sonnet 4.6,再对比输出质量与费用,找到最优模型组合。
选型决策树
你的核心需求是什么?
│
├── 超长文档(>200K Token)处理 → Claude Opus 4.6 / Sonnet 4.6
│
├── 高频轻量任务(成本优先)→ GPT-5 Mini 或 GPT-5 标准
│
├── 代码生成 / 重构
│ ├── 复杂多文件重构,保守修改 → Claude Sonnet 4.6
│ └── 自主 Agent 修 Bug,终端执行 → GPT-5.4
│
├── 自动化 Agent(端到端操控浏览器/桌面)→ GPT-5(Computer Use)
│
├── 内容写作 / 长文生成 → Claude Opus 4.6
│
└── 需要同时测试多个模型 → 使用兼容双 API 的推理平台
常见问题
Q:Claude 4 和 Claude Opus 4.6 是同一个东西吗?
是的。Claude 4 系列包含 Opus 4.6(顶级推理)、Sonnet 4.6(中端主力)、Haiku 4.5(轻量低成本)三个档位,Opus 4.6 是目前 Claude 系列能力最强的版本。Q:GPT-5 和 GPT-5.4 有什么区别?
GPT-5 是 OpenAI 2025 年发布的旗舰基础模型,GPT-5.4 是其在推理和工具使用上的强化版本,定价更高(2.50/M vs 1.25/M 输入),适合推理密集型任务。GPT-5.5 是 2026 年的新一代完整重训版本,是首个完全重新训练的基础模型。Q:Claude 的 1M Token 上下文需要额外付费吗?
不需要。Claude Sonnet 4.6 和 Opus 4.6 的完整 1M Token 上下文包含在标准定价中,不额外收费。Claude Sonnet 4.5 超过 200K Token 后才有溢价。Q:企业接入建议用官方 API 还是第三方平台?
官方 API(api.anthropic.com / api.openai.com)数据隐私保障更直接,适合合规要求严格的场景。第三方兼容平台适合需要多模型切换、统一计费或国内访问便捷性的团队,选择时关注服务商的数据协议和稳定性。Q:DeepSeek 也很强,为什么只对比 Claude 和 GPT-5?
DeepSeek V4 在编码基准上声称与 Claude Opus 4.6 接近,但输入价格约 $0.28/M,相差约 50 倍。对预算敏感且可接受开源模型的团队,DeepSeek 值得单独评估;本文聚焦企业级稳定性和综合能力最强的闭源旗舰模型对比。
总结
Claude Opus 4.6 和 GPT-5 在 2026 年已达到近乎同等的顶级水准,差异更多体现在场景适配而非绝对能力高下。
●预算有限、高频调用:优先 GPT-5 标准($1.25/M 输入)
●超长文档、写作创作:优先 Claude Sonnet 4.6 或 Opus 4.6
●自主 Agent、终端自动化:优先 GPT-5.4
●代码重构、严格 TypeScript:优先 Claude Sonnet 4.6
实际选型建议:用同一套测试集对两个模型分别跑基准,结合真实业务的 Token 消耗估算月成本,再做最终决策。
据 Artificial Analysis 2026 年 5 月数据,两个模型的 API 性能和定价均处于动态调整中,建议定期复查选型策略以反映最新动态。
延伸资源
●多模型 API 统一接入(支持 Claude / GPT-5 / DeepSeek 切换):https://www.qiniu.com/ai/models
●官方定价参考:https://platform.claude.com/docs/en/about-claude/pricing · https://openai.com/api/pricing/
本文内容基于 2026年05月 公开数据整理,涉及定价和基准数据以各模型官方最新公告为准。