摘要
这个论文利用3D 模型监督 LLM 模型,实现LLM性能提升。
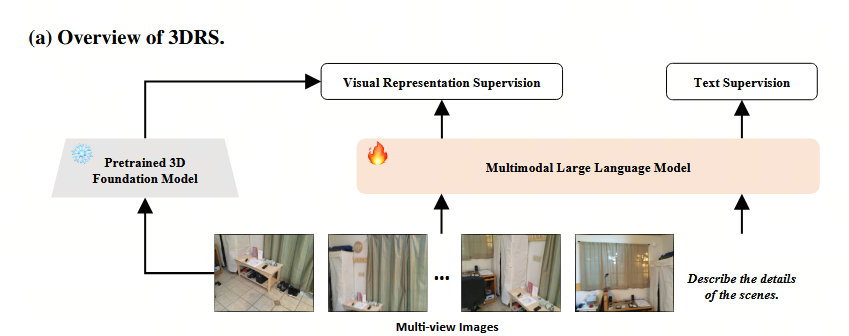
introduce
核心研究的以下问题:(1) 如何评估MLLM学习3D感知表示的能力?(2) 3D特征学习的质量如何影响下游场景理解性能?(3) 什么方法可以增强MLLM框架内的3D感知表示学习?
对于第一个问题,我们进行了全面的实验来评估三个代表性多模态语言模型(MLLMs)的3D感知能力,包括LLaVA-Next-Video 60、LLaVA-One-Vision 27 和 Qwen2-VL 47,并遵循了Video-3D LLM 63 的微调设置。具体来说,我们通过视角等变性来评估3D感知能力,通过计算同一3D体素在不同视角下的特征相似度来量化这一点。这一评估要求多模态语言模型能够在多个视角下关联同一个对象,从而反映它们的3D表示能力。我们的分析涵盖了六个数据集,涉及的任务包括3D定位 5、描述 12 和问答 2。
对于第二个问题,我们系统地分析了这些数据集上的模型性能,3D感知表示的质量与下游场景理解性能之间存在强烈的正相关关系,突显了在多模态语言模型中增强3D特征学习的必要性。
针对第三个问题,并基于我们先前的发现,我们首先引入了一种视图等价监督策略(a view equivalence supervision strategy),用于多视图学习模型(MLLMs),该策略鼓励来自不同视角但对应于同一3D位置的特征对(正样本对)之间的对齐,同时抑制不相关特征对(负样本对)之间的相似性。尽管这种方法带来了一些性能提升,但这种手工设计的单一任务目标所提供的监督对于3D学习来说本质上是有限的。
本文基于:3D基础模型如VGGT 46和FLARE 58(不仅包括对应关系学习,还包括深度估计和相机参数预测),我们提出了利用这些预训练模型的特征作为MLLMs视觉输出的对齐目标,从而促进更有效的3D感知表示学习。
具体方案
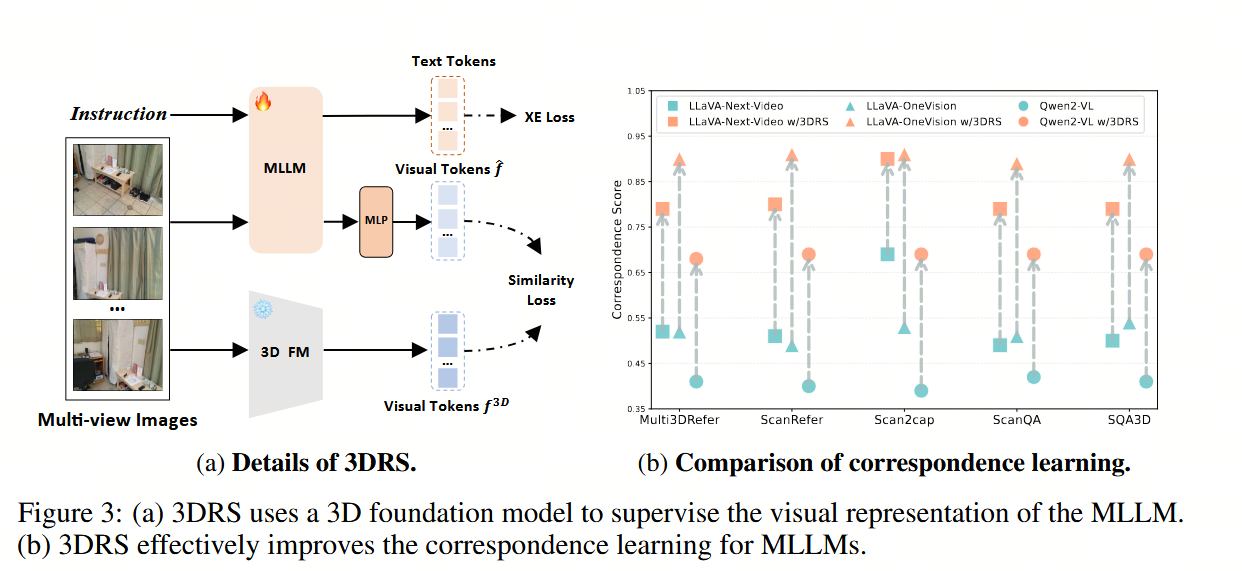
在本研究中,输入到我们的MLLM的是一组N个多视角图像I = {I1, I2, ..., IN},每个图像都与像素级别的3D坐标(深度值)。
- 特征相似性和对应分数通过余弦相似度来衡量
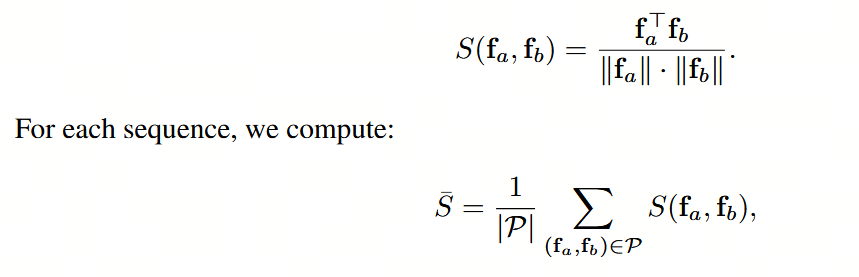
论文写的比较简单。
基础模型是 LLaVA-Next-Video 7B 60 , LLaVA-OneVision7B 27 , and Qwen2-VL 7B 47 .
正文完。