文章目录
Apache Kafka 是一个开源的 分布式事件流平台 ,它可以像一个超级消息队列,让不同系统之间能够 高吞吐量、低延迟 地传递和处理实时数据。
核心特点
- 高吞吐量:单机可处理数十万条/秒
- 低延迟:毫秒级消息传递
- 持久化:消息持久化到磁盘,不会丢失
- 分布式:天然支持集群扩展
- 容错性:副本机制保证高可用
核心概念
为了快速建立一个清晰的认知,可以把 Kafka 的架构想象成一个高效的邮政系统,核心角色是这样的:
| 概念 | 邮政系统比喻 | 具体说明 |
|---|---|---|
| Topic(主题) | 信箱名 | 消息的逻辑分类,发送方指明将"信件"投递到哪个主题(信箱),而接收方则从特定的主题中取信。 |
| Partition(分区) | 信箱下的多个格子 | 每个主题会被分为一个或多个分区,是实现Kafka高吞吐和并行处理的关键。不同分区可以分布在不同的服务器上。 |
| Producer(生产者) | 寄信人 | 负责创建并发布消息到指定Kafka主题的应用程序。 |
| Consumer(消费者) | 收信人 | 负责订阅主题并拉取消息进行处理的应用程序。 |
| Consumer Group(消费者组) | 合伙收信的团队 | 一个或多个消费者组成一个组。组内的每个消费者负责处理不同分区的消息,共同完成对主题所有消息的消费。 |
| Broker(代理节点) | 邮局分局 | Kafka集群中的一个节点(一台服务器)。多个Broker组成一个Kafka集群,共同处理海量数据。 |
| Offset(偏移量) | 格子里的邮件编号 | 分区内每条消息的唯一序列号,消费者依靠它来记录自己读到了哪条消息,即使重启也不会丢掉进度。 |
| Replica(副本) | 邮件的备份 | 分区副本,保证高可用 |
整体架构图
存储层
消费者集群
Kafka Cluster
生产者集群
Consumer Group B
Consumer Group A
Broker 3
Broker 2
Broker 1
Controller 集群
副本同步
副本同步
副本同步
副本同步
副本同步
副本同步
元数据管理
元数据管理
元数据管理
提交偏移量
存储元数据
Producer 1
Producer 2
Producer 3
Controller Leader
Controller Follower
Controller Follower
Partition 0
Leader
Partition 1
Follower
Partition 2
Follower
Partition 1
Leader
Partition 0
Follower
Partition 2
Leader
Partition 0
Follower
Partition 1
Follower
Consumer A1
Consumer A2
Consumer B1
__consumer_offsets
消费者偏移量存储
__cluster_metadata
集群元数据存储
KRaft模式
核心机制
-
消息存储与可靠性
- 磁盘存储 :与传统消息中间件不同,Kafka将所有消息持久化到磁盘 。但它巧妙地利用了顺序读写的特性,使其性能堪比内存读写。
- 副本机制 :每个分区都可以有多个副本(Replica),分布在不同的Broker上。其中一个是Leader副本 ,负责处理所有读写请求;其他是Follower副本,负责从Leader同步数据。当Leader宕机时,会从Follower中选举出新的Leader,确保系统高可用。
- ISR机制:Kafka维护了一个"同步副本集",只有跟上Leader进度的Follower才能进入这个集合。这个机制在保证数据不丢失的同时,也维持了系统的高可用性。
-
高性能的秘密
- 分区并行:一个主题的数据被分散到多个分区,不同的分区可以分布在不同的服务器上。生产和消费都可以以分区为单位并行操作,极大地提升了吞吐量。
- 批量与异步:生产者不会一条一条地发送消息,而是积攒一批(batch)后一次性发送。这种批量处理减少了网络开销,提升了效率。
- 零拷贝(Zero-Copy)技术:在将数据从磁盘发送给消费者的过程中,Kafka利用操作系统特性,实现了数据从磁盘文件(经由Page Cache)直接发送到网络中,减少了数据在内核空间和用户空间之间的不必要拷贝,大幅降低了CPU和内存开销。
主要应用场景
凭借其强大的性能,Kafka被广泛应用于各种需要处理海量实时数据的场景:
- 异步通信与流量削峰:比如在订单系统中,用户下单是一个核心流程,而发送通知短信是次要流程。Kafka可以让主流程处理完订单后立即返回,再将通知任务异步处理,避免因次要流程缓慢而阻塞主流程。
- 日志聚合与分析:这也是Kafka最经典的应用场景。各业务系统的海量日志可以被迅速发送到Kafka,再由Logstash、Flink等下游系统消费并进行实时分析或归档存储。
- 流数据处理:Kafka常与Flink或Spark Streaming等框架结合,构建实时数据处理管道,例如网站的实时推荐、用户行为分析、金融风控等。
- 事件溯源:将系统状态的每一次变更都记录为不可变的事件序列,Kafka可以作为存储这些事件的可靠后端,使得重建系统任意时间点的状态成为可能。
使用 Docker搭建一个单机 Kafka 开发环境
下面的 docker-compose 配置使用了较新的 KRaft 模式(Kafka Raft Metadata mode),它可以不再依赖 ZooKeeper,更加轻量。
步骤一:创建 docker-compose.yml 文件
在你的工作目录下,创建一个名为 docker-compose.yml 的文件,并写入以下内容:
yaml
version: '3'
services:
kafka:
image: apache/kafka:4.2.0
container_name: kafka-dev
ports:
- "9092:9092"
environment:
# KRaft 模式必需配置
KAFKA_ENABLE_KRAFT: 'yes' # 启用 KRaft 模式
KAFKA_NODE_ID: 1 # 节点 ID
KAFKA_PROCESS_ROLES: broker,controller # Combined 角色
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@localhost:9093 # Controller 集群
# 监听器配置(关键:明确指定 controller 监听器)
KAFKA_LISTENERS: PLAINTEXT://:9092,CONTROLLER://:9093
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,CONTROLLER:PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
# 自动创建 Topic
KAFKA_AUTO_CREATE_TOPICS_ENABLE: 'true'
# 关键:官方镜像的配置方式(注意:没有 CFG_ 前缀)
# 这些是直接对应 server.properties 的配置项
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: '1'
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: '1'
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: '1'
KAFKA_DEFAULT_REPLICATION_FACTOR: '1'
volumes:
- kafka_data:/var/lib/kafka/data
volumes:
kafka_data:步骤 2:启动 Kafka
在 docker-compose.yml 文件所在目录下,打开终端执行以下命令:
bash
docker-compose up -d等待一会儿,Kafka 服务就在后台启动成功了。
步骤 3:验证功能
执行以下命令进入 Kafka 容器内部:
bash
docker exec -it kafka-dev /bin/bash进入容器后,使用自带的脚本创建一个 Topic 并进行测试:
bash
# 创建一个名为 'test-topic' 的 Topic
./opt/kafka/bin/kafka-topics.sh --create --topic test-topic --bootstrap-server localhost:9092
# 查看 Topic 列表
./opt/kafka/bin/kafka-topics.sh --list --bootstrap-server localhost:9092
# 查看 Topic 详情
./opt/kafka/bin/kafka-topics.sh --describe --topic test-topic --bootstrap-server localhost:9092
# 启动一个生产者,发送几条消息(输入后按回车)
./opt/kafka/bin/kafka-console-producer.sh --topic test-topic --bootstrap-server localhost:9092
> Hello Kafka!
> This is a test.新开一个终端,再次进入容器启动消费者,查看消息:
bash
# 新终端2:启动消费者
docker exec -it kafka-dev /bin/bash
./opt/kafka/bin/kafka-console-consumer.sh --topic test-topic --bootstrap-server localhost:9092 --from-beginning
# 应该立即看到:
# Hello Kafka!
# This is a test.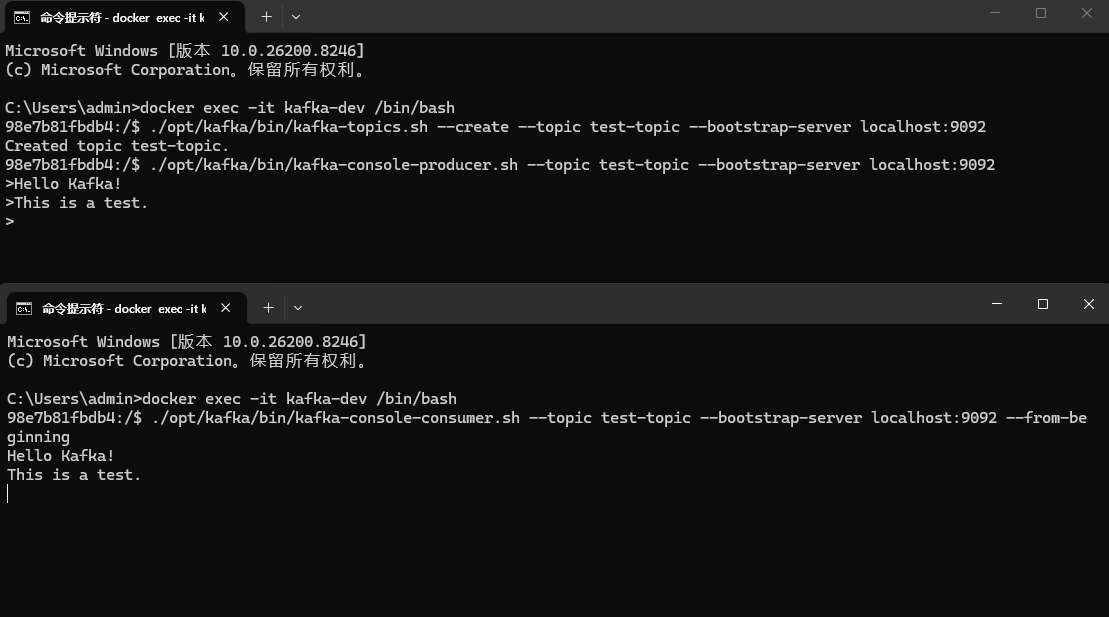
案例
案例演示如何在Python代码中集成Kafka。本案例使用afka-python:纯 Python 实现,简单易用,适合学习和功能测试。
第一步:安装依赖
bash
pip install kafka-python第二步:生产者代码示例
python
from kafka import KafkaProducer
import json
# 连接 Kafka
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
value_serializer=lambda v: json.dumps(v).encode('utf-8') # 将消息序列化为 JSON
)
topic = 'test-topic-python'
print("=== Kafka 消息发送器 ===")
print(f"连接到: localhost:9092")
print(f"目标主题: {topic}")
for i in range(10):
message = {'id': i, 'content': f'Hello Kafka from Python: {i}'}
future = producer.send(topic, value=message)
# 等待发送结果
record_metadata = future.get(timeout=10)
print(f"消息发送成功 -> 主题:{record_metadata.topic}, 分区:{record_metadata.partition}, 偏移量:{record_metadata.offset}")
print("输入消息内容后按回车发送,输入 'quit' 或 'exit' 退出程序")
print("-" * 40)
try:
while True:
# 获取用户输入
user_input = input("请输入消息: ").strip()
# 检查退出条件
if user_input.lower() in ['quit', 'exit', 'q']:
print("程序退出")
break
# 跳过空消息
if not user_input:
print("消息不能为空,请重新输入")
continue
# 构建消息
message = {
'content': user_input,
# 'timestamp': time.time() # 如果需要时间戳可以取消注释
}
try:
# 发送消息
future = producer.send(topic, value=message)
# 等待发送结果(可选,用于确认发送成功)
record_metadata = future.get(timeout=5)
print(f"✓ 消息发送成功 -> 主题:{record_metadata.topic}, 分区:{record_metadata.partition}, 偏移量:{record_metadata.offset}")
print()
except Exception as e:
print(f"✗ 消息发送失败: {e}")
print()
except KeyboardInterrupt:
print("\n\n用户中断程序")
finally:
# 确保所有消息都发送完毕
producer.flush()
producer.close()
print("已关闭 Kafka 连接")第三步:消费者代码示例
python
import json
from kafka import KafkaConsumer
# 连接 Kafka
consumer = KafkaConsumer(
'test-topic-python', # 要消费的主题
bootstrap_servers=['localhost:9092'],
group_id='python-consumer-group', # 消费者组 ID
auto_offset_reset='earliest', # 从最早的消息开始读取
enable_auto_commit=True, # 自动提交偏移量
value_deserializer=lambda x: json.loads(x.decode('utf-8')) # 反序列化 JSON
)
print("开始消费消息...")
for message in consumer:
print(f"收到消息: {message.value} (分区:{message.partition}, 偏移量:{message.offset})")第四步:查看结果
分别在两个终端运行生产者和消费者脚本:
bash
python D:\demo\kafka\producer.py
python D:\demo\kafka\consumer.py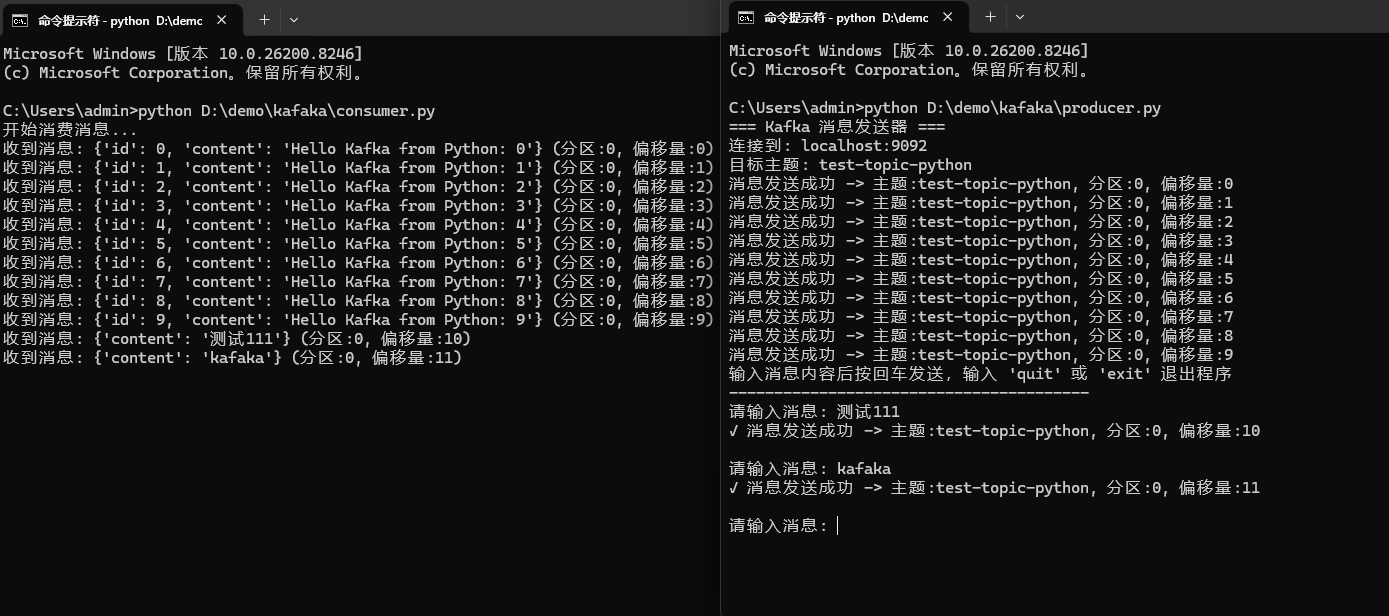
总结
总的来说,Kafka不是一个简单的消息队列,而是一个功能强大的事件流平台 ,其核心设计围绕分区、顺序写入和副本机制展开,赋予了它在分布式环境下处理海量实时数据的能力。