数据仓库分层建模实战指南:从混乱到有序的工程实践
版本:V1.0
适合人群:数据开发工程师、ETL工程师、BI开发工程师、有一定SQL基础的数据从业者
写在前面:你是不是也遇到过这些问题?
如果你做过数据仓库开发,大概率遇到过下面这些场景:
- 老板让你查一个数据,你翻了半天发现有三张表都叫"用户订单表",但字段还不一样,不知道该用哪张
- 接手的数仓项目,表与表之间互相依赖,改了一张表,下游十几张表全挂了
- 业务方要一个报表,你发现需要JOIN七八张表,SQL写得又长又慢,跑一次要半小时
- 新来的同事问你"这张表是干嘛的",你看了半天DDL也说不清楚
- 每次大促或者业务改版,数仓就要大改一次,加班到深夜
如果你中了两条以上,别担心,这不是你一个人的问题------这是绝大多数数据仓库都会经历的"成长阵痛"。
这篇文章不跟你讲太多理论,就用大白话 + 实际代码案例,带你搞清楚一件事:怎么建一个不乱、好维护、跑得快的数据仓库。
一、先搞明白:业务库和数仓库是两码事
1.1 一个生活中的比喻

想象你要开一家餐厅:
- 业务库 就像厨房------厨师在这里切菜、炒菜、装盘,动作要快,来一个菜做一个菜
- 数仓库 就像财务室------每天晚上要统计今天卖了多少菜、哪些菜卖得好、哪个时段客人最多,目的是算账和做决策
厨房和财务室能混在一起吗?显然不能。厨房要的是快,财务室要的是准。
1.2 技术上的区别
| 对比项 | 业务库(MySQL/PostgreSQL) | 数仓库(Hive/ClickHouse/Doris) |
|---|---|---|
| 用来干嘛 | 支撑APP/网站正常运作(用户登录、下单、支付) | 做报表、分析数据、喂给算法模型 |
| 查询特点 | 一次查几条数据,要求毫秒级返回 | 一次扫几百万行,算个汇总指标 |
| 数据更新 | 频繁增删改,数据随时在变 | 基本只追加,改得很少 |
| 表设计 | 拆得很细,避免数据重复(比如用户信息和订单分开) | 经常合并成宽表,减少JOIN |
最常见的坑 :很多新人做数仓,直接把业务库的表结构搬过来,然后发现查起来特别慢、SQL特别难写。原因就在于------业务库的设计思路跟数仓完全不一样。
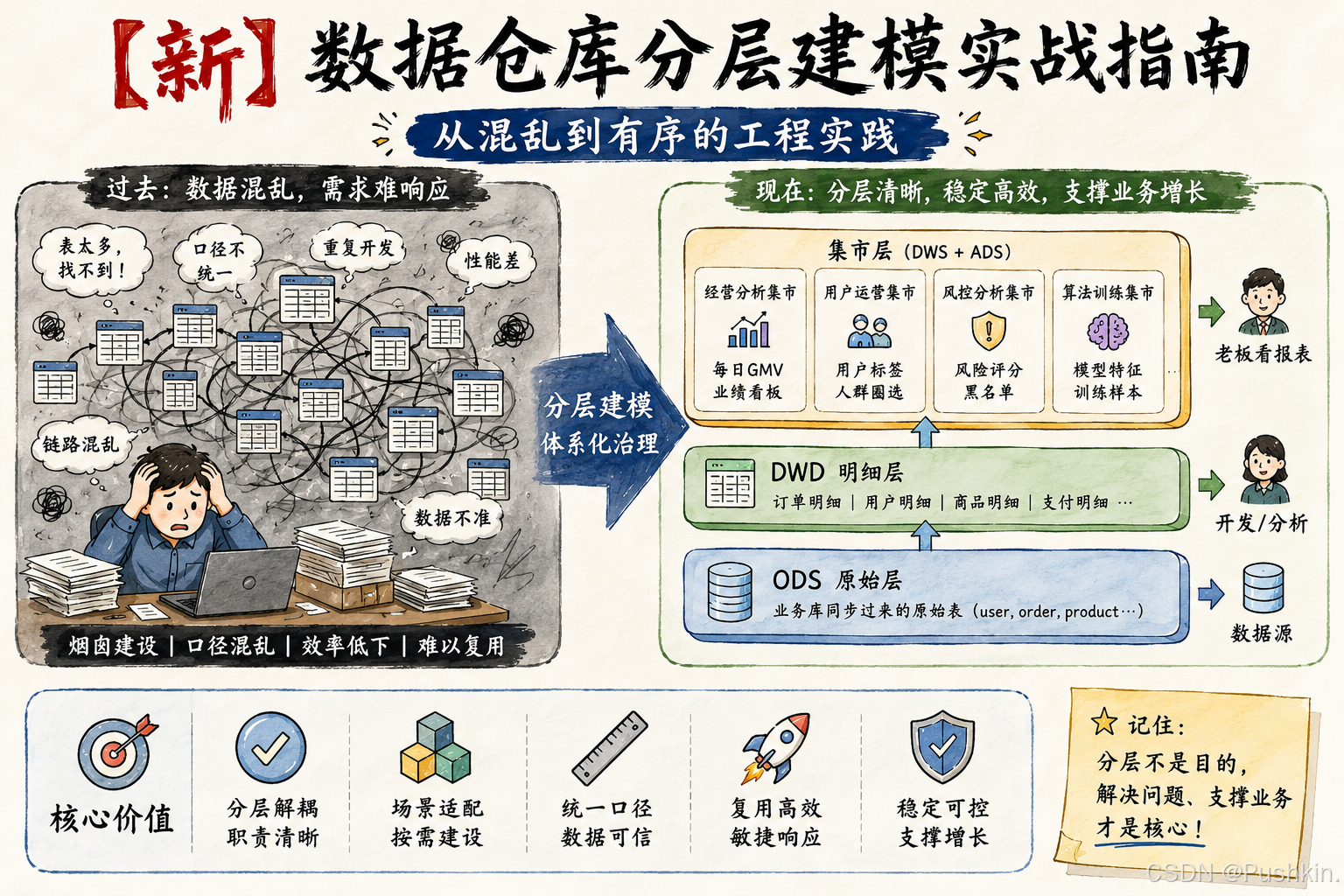
二、数仓为什么要分层?
2.1 不分层的数仓长什么样
假设你接手了一个没有分层的数仓,所有表都堆在一起,大概是这样:
ads_user_order_report -- 用户订单报表
ods_user -- 用户原始数据
dwd_order_detail -- 订单明细(但没人记得这是哪层的)
temp_20240301 -- 临时表,不知道谁建的
user_order_amount_summary -- 用户订单金额汇总
ods_order -- 订单原始数据
report_daily_gmv -- 每日GMV报表
... 还有200多张表问题很明显:
- 找不到表------不知道哪张表能用,只能到处问
- 不敢改表------不知道下游谁在用,改了可能出事故
- 重复造轮子------A团队建了一张"用户订单表",B团队又建了一张"用户交易表",其实是一回事
- 数据对不上------同一张报表,不同的人查出来的数不一样
2.2 分层就像给仓库贴标签
分层的核心思想很简单:把数据按"加工程度"分成不同的层级,每一层只做一件事。
常见的分层结构:
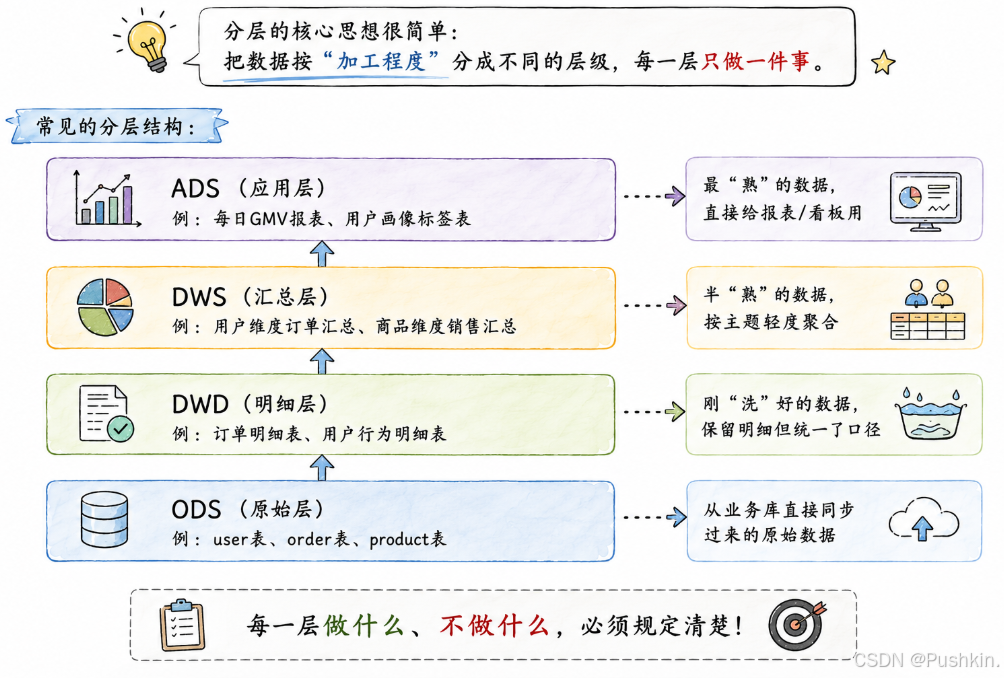
每一层做什么、不做什么,必须规定清楚。 这就是本文要讲的核心。
三、核心问题:DWS层到底该放在哪?
3.1 一个真实的冲突案例
假设业务方提了个需求:要做一张"用户交易状态汇总表",方便分析用户下单情况。
这时候会出现两种思路:
思路A(数仓工程师的视角):
"DWD层已经有订单明细表了,DWS层也有用户聚合表,直接JOIN一下不就行了?不用新建表。"
sql
-- 思路A:复用现有表,通过JOIN获取数据
SELECT
u.user_id,
u.user_name,
u.register_date,
COUNT(o.order_id) AS order_count,
SUM(o.pay_amount) AS total_amount
FROM dwd_user_info u
LEFT JOIN dwd_order_detail o ON u.user_id = o.user_id
GROUP BY u.user_id, u.user_name, u.register_date;思路B(数据分析师的视角):
"我要一张宽表,所有字段都在一张表里,我直接SELECT就行,不用每次写JOIN。"
sql
-- 思路B:直接查宽表
SELECT
user_id,
user_name,
register_date,
order_count,
total_amount,
last_order_date,
avg_order_amount
FROM ads_user_order_summary
WHERE dt = '2025-05-01';谁对谁错?
其实都没错,但诉求不一样:
| 角色 | 核心诉求 | 想要的方案 |
|---|---|---|
| 数仓工程师 | 表越少越好、复用率越高越好 | 思路A(复用现有表) |
| 数据分析师 | SQL越简单越好、查询越快越好 | 思路B(建宽表) |
问题的根源:传统做法把DWS层既当"公共汇总层"又当"分析消费层",结果就是------数仓工程师觉得DWS应该规范、可复用,分析师觉得DWS应该好用、查询快。两边打架。
3.2 解决方案:把DWS"搬"到集市层
核心思路就一句话:DWD层只管"把数据洗干净、标准化",集市层(DWS+ADS)只管"让分析的人好用"。
改完之后,分层结构变成这样:
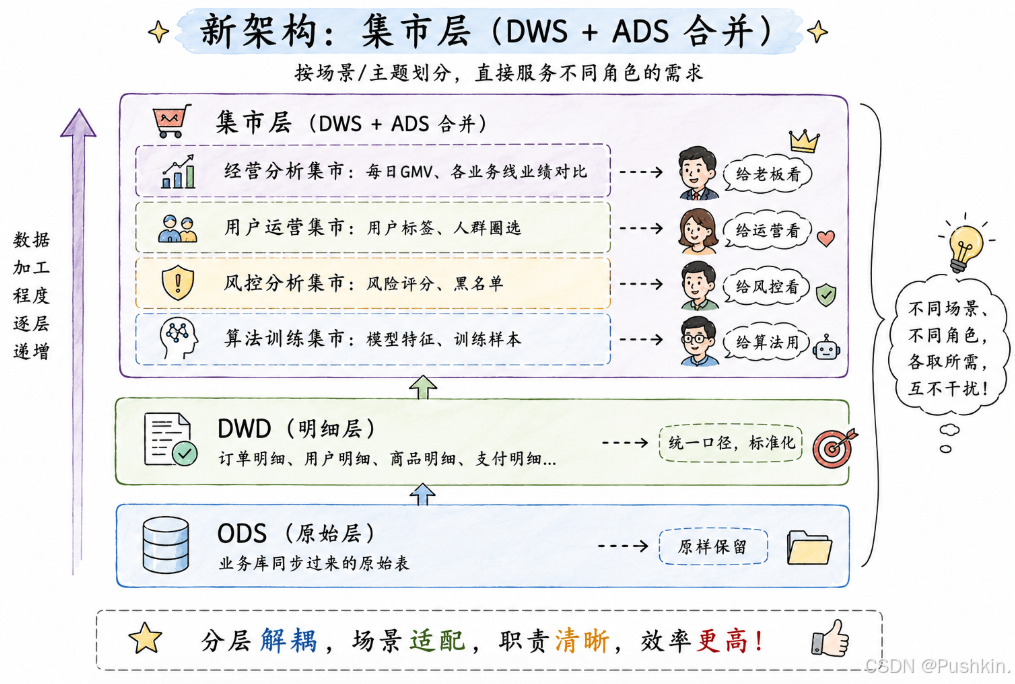
关键变化:
- DWD层做减法:不再往DWD层塞各种分析字段,DWD只保留业务最核心的明细数据
- 集市层做加法:DWS和ADS合并,按使用场景分成不同的"集市",每个集市独立建设
- 各管各的:DWD层由数仓团队统一维护,集市层可以按场景分配给不同的人负责
四、DWD层怎么建:把数据"洗干净、标准化"
4.1 DWD层的核心任务
DWD层(Data Warehouse Detail)是数仓的"地基"。地基打不好,上面盖什么都会歪。
DWD层要做的事:
- 把ODS层的原始数据清洗(去重、补全、格式统一)
- 把不同来源的同类数据统一口径(比如APP端和PC端的订单合并成一张表)
- 把业务含义标准化 (比如状态码
1/2/3翻译成待支付/已支付/已发货)
DWD层不要做的事:
- ❌ 不要为了某个报表的需求,往DWD表里加字段
- ❌ 不要做高度聚合(比如"每个用户每月的总金额"这种放到集市层去做)
- ❌ 不要直接给业务方查,DWD层是给下游层用的
4.2 一个实际的DWD表设计案例
假设业务库有两张表:
业务库的user表:
| id | name | phone | city_id | create_time | status |
|---|---|---|---|---|---|
| 1001 | 张三 | 13800138000 | 110100 | 2024-01-15 | 1 |
| 1002 | 李四 | 13900139000 | 310100 | 2024-02-20 | 1 |
业务库的city表:
| city_id | city_name | province_id |
|---|---|---|
| 110100 | 北京 | 110000 |
| 310100 | 上海 | 310000 |
DWD层的设计(用户明细表):
sql
CREATE TABLE dwd_user_info_df (
user_id BIGINT COMMENT '用户ID',
user_name STRING COMMENT '用户姓名',
phone STRING COMMENT '手机号',
city_id STRING COMMENT '城市ID',
city_name STRING COMMENT '城市名称(从city表关联过来)',
province_id STRING COMMENT '省份ID',
register_date STRING COMMENT '注册日期',
user_status STRING COMMENT '用户状态:active-正常/inactive-注销',
etl_time STRING COMMENT '数据同步时间'
)
COMMENT '用户明细表-每日全量'
PARTITIONED BY (dt STRING COMMENT '分区日期')
STORED AS PARQUET;关键设计点:
- 关联了city表:把城市名称直接放到DWD表里,下游不用每次都JOIN
- 状态码翻译 :
1→active,0→inactive,让人一眼能看懂 - 加了分区:按天分区,查询时只扫指定分区,效率高
- 用了Parquet格式:列式存储,压缩比高,查询快
4.3 DWD层设计的"三要三不要"
| 要做 | 不要做 |
|---|---|
| ✅ 统一数据口径(比如金额统一用元还是分) | ❌ 为某个报表加专属字段 |
| ✅ 关联常用的维度表(城市、类目等) | ❌ 做高度聚合(按用户/按天汇总) |
| ✅ 数据清洗(去重、补默认值、格式统一) | ❌ 直接暴露给业务方查询 |
五、集市层怎么建:按场景"各做各的"
5.1 集市层的核心思路
集市层的核心思路就一句话:谁用、怎么用,就怎么建。
不同角色对数据的需求完全不同:
- 老板看报表:要的是"今天卖了多少钱""跟昨天比涨了还是跌了" → 需要按天汇总的指标表
- 运营做活动:要的是"最近30天买过东西的用户" → 需要用户维度的行为标签表
- 风控查风险:要的是"同一个IP下了多少单" → 需要设备/IP维度的聚合表
- 算法训练模型:要的是"用户过去7天的行为序列" → 需要特征宽表
如果把这些需求都塞到一张表里,这张表会有几百个字段,没人看得懂。 所以必须按场景拆分。
5.2 经营分析集市案例
需求:老板每天要看GMV、订单量、客单价等核心指标。
DWS层设计(按天汇总):
sql
CREATE TABLE dws_trade_platform_1d (
dt STRING COMMENT '日期',
gmv_amount DECIMAL(18,2) COMMENT 'GMV金额',
gmv_cnt BIGINT COMMENT 'GMV订单数',
pay_amount DECIMAL(18,2) COMMENT '支付金额',
pay_cnt BIGINT COMMENT '支付订单数',
refund_amount DECIMAL(18,2) COMMENT '退款金额',
refund_cnt BIGINT COMMENT '退款订单数',
avg_order_amount DECIMAL(18,2) COMMENT '客单价'
)
COMMENT '交易核心指标-天粒度'
PARTITIONED BY (dt STRING)
STORED AS PARQUET;ADS层设计(给看板用):
sql
CREATE TABLE ads_dashboard_daily (
dt STRING COMMENT '日期',
gmv_amount DECIMAL(18,2) COMMENT '今日GMV',
gmv_amount_yesterday DECIMAL(18,2) COMMENT '昨日GMV',
gmv_amount_last7d_avg DECIMAL(18,2) COMMENT '近7日平均GMV',
gmv_amount_yoy DECIMAL(10,4) COMMENT '同比增速',
gmv_amount_dod DECIMAL(10,4) COMMENT '环比增速',
pay_user_cnt BIGINT COMMENT '支付用户数'
)
COMMENT '经营看板-每日核心指标'
PARTITIONED BY (dt STRING)
STORED AS PARQUET;分层逻辑:
DWD订单明细表
│
▼
DWS按天汇总(GMV、订单量、支付金额等)
│
▼
ADS计算同比环比(给看板直接展示)5.3 用户运营集市案例
需求:运营要能按各种条件圈选用户(比如"北京、最近30天下过单、客单价大于200的女性用户")。
DWS用户维度汇总(天粒度):
sql
CREATE TABLE dws_user_trade_1d (
user_id BIGINT COMMENT '用户ID',
dt STRING COMMENT '日期',
order_cnt BIGINT COMMENT '当日订单数',
order_amount DECIMAL(18,2) COMMENT '当日订单金额',
pay_cnt BIGINT COMMENT '当日支付订单数',
pay_amount DECIMAL(18,2) COMMENT '当日支付金额',
first_order_time STRING COMMENT '首次下单时间',
last_order_time STRING COMMENT '末次下单时间'
)
COMMENT '用户交易行为-天粒度'
PARTITIONED BY (dt STRING)
STORED AS PARQUET;DWS用户维度汇总(长周期):
sql
CREATE TABLE dws_user_trade_nd (
user_id BIGINT COMMENT '用户ID',
dt STRING COMMENT '统计日期',
近7天order_cnt BIGINT COMMENT '近7天订单数',
近7天order_amount DECIMAL(18,2) COMMENT '近7天订单金额',
近30天order_cnt BIGINT COMMENT '近30天订单数',
近30天order_amount DECIMAL(18,2) COMMENT '近30天订单金额',
近90天order_cnt BIGINT COMMENT '近90天订单数',
近90天order_amount DECIMAL(18,2) COMMENT '近90天订单金额',
total_order_cnt BIGINT COMMENT '历史总订单数',
total_order_amount DECIMAL(18,2) COMMENT '历史总订单金额',
last_order_date STRING COMMENT '最近下单日期'
)
COMMENT '用户交易行为-多周期汇总'
PARTITIONED BY (dt STRING)
STORED AS PARQUET;ADS用户标签表(给运营直接用):
sql
CREATE TABLE ads_user_profile_tags (
user_id BIGINT COMMENT '用户ID',
dt STRING COMMENT '日期',
city_name STRING COMMENT '所在城市',
gender STRING COMMENT '性别',
age_group STRING COMMENT '年龄段',
is_vip BOOLEAN COMMENT '是否VIP',
is_active_30d BOOLEAN COMMENT '近30天是否活跃(下过单)',
is_high_value BOOLEAN COMMENT '是否高价值用户(近90天消费>1000)',
order_frequency STRING COMMENT '下单频率:low/medium/high',
avg_order_amount DECIMAL(18,2) COMMENT '平均客单价'
)
COMMENT '用户画像标签表'
PARTITIONED BY (dt STRING)
STORED AS PARQUET;运营圈选用户时,SQL就很简单了:
sql
-- 运营要圈选:北京、近30天下过单、高价值的女性用户
SELECT user_id
FROM ads_user_profile_tags
WHERE dt = '2025-05-01'
AND city_name = '北京'
AND gender = 'female'
AND is_active_30d = true
AND is_high_value = true;5.4 集市层设计的核心原则
| 原则 | 说明 | 反例 |
|---|---|---|
| 按场景建表 | 经营分析、用户运营、风控分析各建各的 | 一张表塞几百个字段,什么场景都用 |
| 粒度明确 | 每张表必须有明确的粒度(按天/按用户/按订单) | 一张表里既有天粒度又有用户粒度 |
| 字段分组 | 相关字段放一起,命名有规律 | 字段名乱七八糟,看不出含义 |
| 控制字段数 | 单表建议不超过200个字段 | 一张表500+字段,没人看得完 |
六、实战:从需求到落地的完整流程
6.1 接到需求后的思考顺序
当你接到一个数据需求时,按这个顺序思考:
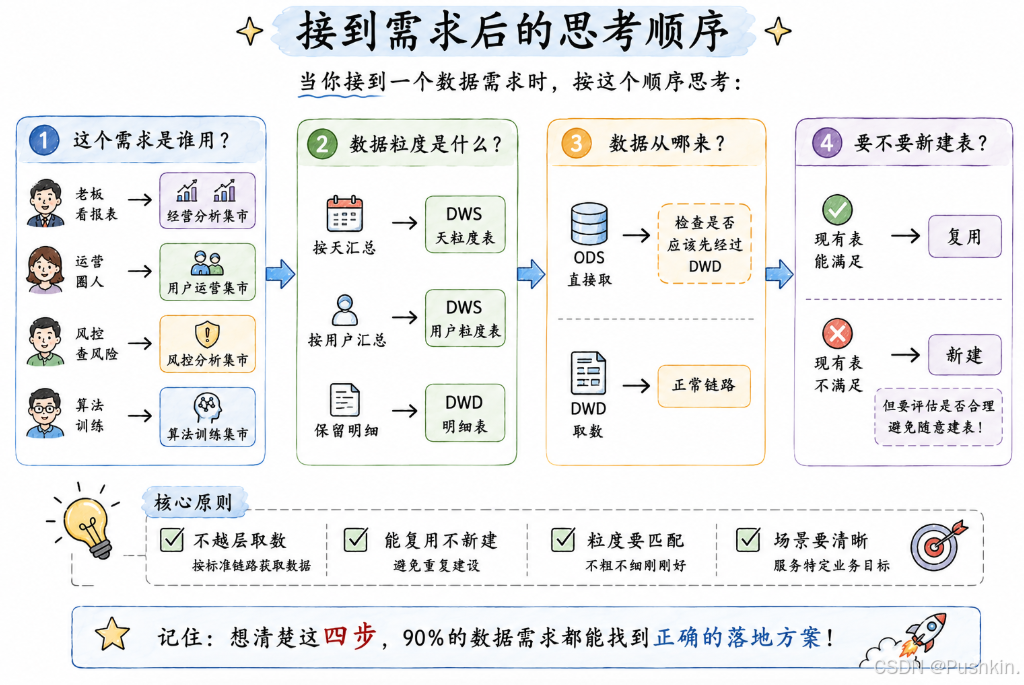
6.2 一个完整的需求落地案例
需求描述:运营团队需要一张表,能看到每个用户的基本信息、历史订单情况、最近一次下单时间,用于做用户分层运营。
第一步:判断归属
这是运营圈人用的 → 归属用户运营集市
第二步:确定粒度
按用户维度 → 粒度是用户
第三步:确定数据来源
- 用户基本信息 →
dwd_user_info_df - 订单信息 →
dwd_order_detail_di - 需要关联 → 通过
user_id关联
第四步:设计表结构
sql
-- 集市层:用户运营-用户分层宽表
CREATE TABLE ads_user_operation_segment (
user_id BIGINT COMMENT '用户ID',
dt STRING COMMENT '日期',
-- 用户基本信息
user_name STRING COMMENT '用户姓名',
phone STRING COMMENT '手机号',
city_name STRING COMMENT '城市',
register_date STRING COMMENT '注册日期',
-- 订单统计
total_order_cnt BIGINT COMMENT '历史总订单数',
total_order_amount DECIMAL(18,2) COMMENT '历史总订单金额',
last_order_date STRING COMMENT '最近下单日期',
days_since_last_order INT COMMENT '距上次下单天数',
-- 用户分层标签
user_level STRING COMMENT '用户等级:S/A/B/C'
)
COMMENT '用户运营-用户分层宽表'
PARTITIONED BY (dt STRING)
STORED AS PARQUET;第五步:写SQL
sql
INSERT OVERWRITE TABLE ads_user_operation_segment PARTITION (dt = '${bizdate}')
SELECT
u.user_id,
'${bizdate}' AS dt,
u.user_name,
u.phone,
u.city_name,
u.register_date,
COALESCE(o.total_order_cnt, 0) AS total_order_cnt,
COALESCE(o.total_order_amount, 0) AS total_order_amount,
o.last_order_date,
DATEDIFF('${bizdate}', o.last_order_date) AS days_since_last_order,
CASE
WHEN COALESCE(o.total_order_amount, 0) >= 5000 THEN 'S'
WHEN COALESCE(o.total_order_amount, 0) >= 2000 THEN 'A'
WHEN COALESCE(o.total_order_amount, 0) >= 500 THEN 'B'
ELSE 'C'
END AS user_level
FROM dwd_user_info_df u
LEFT JOIN (
SELECT
user_id,
COUNT(order_id) AS total_order_cnt,
SUM(pay_amount) AS total_order_amount,
MAX(dt) AS last_order_date
FROM dwd_order_detail_di
GROUP BY user_id
) o ON u.user_id = o.user_id;第六步:验证
- 数据量对不对?(跟业务库对比一下总数)
- 金额对不对?(抽几个用户手动算一下)
- 跑得快不快?(看执行计划,有没有数据倾斜)
七、避坑指南:数仓开发最常见的10个坑
坑1:直接从ODS层取数,跳过DWD层
sql
-- ❌ 错误做法:直接从ODS取数
SELECT * FROM ods_order WHERE dt = '2025-05-01';
-- ✅ 正确做法:从DWD层取数
SELECT * FROM dwd_order_detail_di WHERE dt = '2025-05-01';为什么不行? ODS层是原始数据,可能有脏数据、口径不统一。DWD层已经做了清洗和标准化,从DWD取才能保证数据质量。
坑2:DWD层塞了太多分析字段
sql
-- ❌ 错误做法:DWD表里加了"近30天订单数"这种分析字段
CREATE TABLE dwd_user_info_df (
user_id BIGINT,
user_name STRING,
order_cnt_30d BIGINT, -- 这个不该出现在DWD层!
...
);为什么不行? DWD层应该是"业务事实的标准化","近30天订单数"是分析结果,应该放在集市层。DWD层加了分析字段后,这张表就不再是"明细"了,而且每次更新都要重新算30天,效率极低。
坑3:一张表塞所有场景的字段
sql
-- ❌ 错误做法:一张表有300个字段,经营分析、风控、算法全在里面
CREATE TABLE ads_user_all_in_one (
user_id BIGINT,
-- 经营分析字段
total_order_amount DECIMAL(18,2),
-- 风控字段
ip_cnt_7d BIGINT,
device_cnt_7d BIGINT,
-- 算法字段
feature_1 DOUBLE,
feature_2 DOUBLE,
... -- 总共300个字段
);为什么不行? 不同场景的更新频率不同(经营分析T+1、风控可能要求实时)、存储需求不同(算法特征需要保留历史版本)。混在一起只会互相拖累。
坑4:粒度不明确
sql
-- ❌ 错误做法:一张表里既有天粒度又有用户粒度
CREATE TABLE dws_user_order (
user_id BIGINT,
dt STRING,
order_cnt_1d BIGINT, -- 天粒度
order_cnt_30d BIGINT, -- 月粒度
total_order_cnt BIGINT -- 历史粒度
);为什么不行? 天粒度表应该每天全量更新,历史粒度表只需要增量更新。混在一起会导致更新逻辑复杂、存储浪费。应该拆成三张表。
坑5:表之间循环依赖
表A → 依赖表B的数据
表B → 依赖表C的数据
表C → 依赖表A的数据 ← 循环了!怎么避免? 严格遵守分层规范:ODS→DWD→DWS→ADS,只能从上往下依赖,不能反过来,也不能绕圈。
坑6:不建分区
sql
-- ❌ 错误做法:不建分区,每次查询全表扫描
CREATE TABLE dwd_order_detail (
order_id BIGINT,
user_id BIGINT,
...
);
-- ✅ 正确做法:按天分区
CREATE TABLE dwd_order_detail_di (
order_id BIGINT,
user_id BIGINT,
...
)
PARTITIONED BY (dt STRING);为什么重要? 不建分区的话,查一天的数据也要扫全表,效率差几十倍甚至上百倍。
坑7:不写注释
sql
-- ❌ 错误做法:字段名看不懂,还没有注释
CREATE TABLE t1 (
c1 BIGINT,
c2 STRING,
c3 INT
);
-- ✅ 正确做法:表名、字段名、字段含义都要清楚
CREATE TABLE dwd_order_detail_di (
order_id BIGINT COMMENT '订单ID',
user_id BIGINT COMMENT '下单用户ID',
pay_amount DECIMAL(18,2) COMMENT '实付金额(元)'
);坑8:临时表不清理
很多团队都有这种表:temp_xxx、test_xxx、backup_xxx、xxx_20240301。建的时候说"用完就删",结果用了一年还在。
怎么解决?
- 临时表命名加前缀:
tmp_用户名_日期_用途 - 设置生命周期:临时表最多保留7天,到期自动删除
- 定期清理:每月做一次临时表清理
坑9:不控制数据倾斜
sql
-- ❌ 容易倾斜的JOIN:某个key的数据量特别大
SELECT * FROM dwd_order_detail o
LEFT JOIN dwd_blacklist_user b ON o.user_id = b.user_id;
-- 如果黑名单里有几百万"刷单账号",这些账号的订单会全堆到一个reduce上怎么解决?
- JOIN前过滤掉已知的"大key"
- 使用MapJoin(小表JOIN大表时)
- 对倾斜key加随机前缀打散
坑10:不监控数据质量
数据跑完了≠数据是对的。常见的数据质量问题:
- 数据量突增/突降:昨天100万条,今天10万条 → 可能数据没同步过来
- 主键重复:同一张表里出现了两条相同主键的数据 → 可能去重逻辑有问题
- 金额异常:出现了负数金额或者超大金额 → 可能数据源有问题
- 空值率突增:某个字段昨天99%有值,今天50%是空 → 可能上游改了字段
最低限度的监控:
sql
-- 每天跑完数据后,检查这几个指标
SELECT
dt,
COUNT(*) AS total_cnt, -- 总行数
COUNT(DISTINCT user_id) AS unique_user_cnt, -- 去重用户数
COUNT(CASE WHEN order_id IS NULL THEN 1 END) AS null_order_cnt -- 空值数
FROM dwd_order_detail_di
WHERE dt >= DATE_SUB(CURRENT_DATE(), 7)
GROUP BY dt;八、治理:怎么让数仓不乱下去
8.1 最简单的治理规则
不需要复杂的工具,先做到以下五条:
| 规则 | 说明 | 违反后果 |
|---|---|---|
| 不能反向依赖 | DWD不能依赖DWS/ADS的数据 | 分层乱了 |
| 不能跨层取数 | ADS只能依赖DWS,不能直接取DWD | 中间层失去意义 |
| 不能从ODS直连 | 必须经过DWD清洗后再用 | 数据口径不统一 |
| 表名要规范 | 前缀标明层级:ods_/dwd_/dws_/ads_ | 找不到表 |
| 字段要注释 | 每个字段必须有COMMENT | 没人知道字段含义 |
8.2 定期做"大扫除"
就像家里要定期打扫一样,数仓也要定期清理:
每月做一次:
- 找出一周内没有被查询过的表 → 确认是否可以删除
- 找出临时表 → 超过7天的删除
- 找出重复的表(名字不同但数据一样)→ 合并或删除
每季度做一次:
- 检查各层的表数量占比是否合理
- 检查存储成本最高的20张表 → 优化或下线
- 检查数据质量监控的告警记录 → 修复反复出现的问题
8.3 怎么判断数仓"乱不乱"
几个简单的指标:
| 指标 | 健康值 | 危险值 |
|---|---|---|
| 表名带前缀的比例 | >95% | <80% |
| 有字段注释的比例 | >90% | <70% |
| 临时表占总表数的比例 | <5% | >15% |
| 一周无查询的表占比 | <10% | >25% |
| 跨层依赖占比 | <5% | >15% |
九、总结:记住这三句话就够了
如果你看完了全文,但觉得内容太多记不住,那就记住这三句话:
第一句:DWD层只管"洗干净"
DWD层就是做数据清洗和标准化。把业务库的原始数据洗干净、统一口径、关联常用维度,然后交给下游。不要在DWD层做分析、不要为了某个报表加字段。
第二句:集市层只管"好用"
集市层(DWS+ADS)就是让用数据的人方便。经营分析要什么就建什么,用户运营要什么就建什么,按场景拆分,不要混在一起。
第三句:分层规范就是"交通规则"
红灯停、绿灯行,看起来是限制,其实是保证所有人都不堵车。数仓的分层规范也一样------ODS→DWD→DWS→ADS,只能从上往下,不能反过来。做到了这一点,数仓就不会乱。
附录:常用SQL模板
A1. DWD层数据同步模板
sql
-- 每日增量同步(适用于有更新时间的表)
INSERT OVERWRITE TABLE dwd_table_name_di PARTITION (dt = '${bizdate}')
SELECT
id,
field1,
field2,
-- 统一金额单位(假设业务库是分,这里转成元)
amount_cent / 100.0 AS amount_yuan,
-- 统一状态码
CASE status
WHEN 1 THEN 'active'
WHEN 2 THEN 'inactive'
ELSE 'unknown'
END AS status_name,
-- 补全默认值
COALESCE(city_id, '-1') AS city_id,
CURRENT_TIMESTAMP() AS etl_time
FROM ods_table_name
WHERE dt = '${bizdate}'
AND is_deleted = 0; -- 过滤已删除的数据A2. DWS层汇总模板
sql
-- 天粒度汇总
INSERT OVERWRITE TABLE dws_table_name_1d PARTITION (dt = '${bizdate}')
SELECT
user_id,
'${bizdate}' AS dt,
COUNT(order_id) AS order_cnt,
SUM(pay_amount) AS order_amount,
COUNT(DISTINCT product_id) AS product_cnt,
MIN(create_time) AS first_order_time,
MAX(create_time) AS last_order_time
FROM dwd_order_detail_di
WHERE dt = '${bizdate}'
GROUP BY user_id;A3. 数据质量检查模板
sql
-- 插入数据前检查源表数据量
-- 如果源表数据量为0,说明数据没同步过来,直接退出
SELECT COUNT(*) FROM ods_source_table WHERE dt = '${bizdate}';
-- 如果结果为0,则不执行后续SQL最后的话 :数仓建设不是一锤子买卖,而是一个持续迭代的过程。不要追求一开始就完美,先做到"有分层、有规范",然后在实践中不断优化。记住:好的数仓是"长"出来的,不是"设计"出来的。