目录
背影
摘要
LSTM的基本定义
LSTM实现的步骤
BILSTM神经网络
基于双向长短期神经网络bilstm的径流量预测
完整代码:基于双向长短期神经网络bilstm的径流量预测,基于gru神经网络的径流量预测(代码完整,数据齐全)资源-CSDN文库 https://download.csdn.net/download/abc991835105/89127617
效果图
结果分析
展望
参考论文
背影
基于双向长短期神经网络bilstm的径流量预测,长短期神经网络是一种改进党的RNN神经网络,克服了梯度爆炸的问,
摘要
自编码神经网络,可以MATLAB跑,可以通过AI查重,LSTM原理,基于双向长短期神经网络bilstm的径流量预测,基于gru神经网络的径流量预测
LSTM的基本定义
LSTM是一种含有LSTM区块(blocks)或其他的一种类神经网络,文献或其他资料中LSTM区块可能被描述成智能网络单元,因为它可以记忆不定时间长度的数值,区块中有一个gate能够决定input是否重要到能被记住及能不能被输出output。
图1底下是四个S函数单元,最左边函数依情况可能成为区块的input,右边三个会经过gate决定input是否能传入区块,左边第二个为input gate,如果这里产出近似于零,将把这里的值挡住,不会进到下一层。左边第三个是forget gate,当这产生值近似于零,将把区块里记住的值忘掉。第四个也就是最右边的input为output gate,他可以决定在区块记忆中的input是否能输出 。
图1 LSTM模型
图1 LSTM模型
LSTM有很多个版本,其中一个重要的版本是GRU(Gated Recurrent Unit),根据谷歌的测试表明,LSTM中最重要的是Forget gate,其次是Input gate,最次是Output gate
训练方法
为了最小化训练误差,梯度下降法(Gradient descent)如:应用时序性倒传递算法,可用来依据错误修改每次的权重。梯度下降法在递回神经网络(RNN)中主要的问题初次在1991年发现,就是误差梯度随着事件间的时间长度成指数般的消失。当设置了LSTM 区块时,误差也随着倒回计算,从output影响回input阶段的每一个gate,直到这个数值被过滤掉。因此正常的倒传递类神经是一个有效训练LSTM区块记住长时间数值的方法。
lstm的步骤
1 , LSTM的第一步是确定我们将从单元状态中丢弃哪些信息,这个策略有一个被称为遗忘门的sigmoid层决定。输入ht-1和xt遗忘门对应单元状态ct-1中每个数输出一个0到1之间的数字。1代表"完全保持",0表示"完全遗忘"。
让那个我们回到我们的语言模型例子中尝试基于所有之前的词预测下一个词是什么。在这个问题中,单元状态中可能包括当前主题的性别,因此可以预测正确代词。当我们看到一个新的主题的性别时,我们想要忘记旧主题的性别。
=(W*h-1,x+b)
下一步将决定我们在单元状态中保存那些新信息。包括两个部分;第一"输入门层"的sigmoid层决定我们将更新那些值,第二,tanh层创建可以添加到状态的新候选值ct-1的向量。在下一步中,我们将结合这两个来创建状态更新。
在我们语言模型的例子中,我们想要将新主题的性别添加到单元格状态,以替换我们忘记的旧主题
=(W*h-1,x+b)
=tanh(W*h-1,x+b)
现在是时候将旧的单元状态ct-1更新为新的单元状态ct,之前的步骤已经决定要做什么,我们只需要实际做到这一点。我们将旧状态乘以ft,忘记我们之前决定忘记的事情,然后我们添加*Ct .这是新的候选值,根据我们的决定更新每个州的值来缩放。
在语言模型的情况下,我们实际上放弃了关于旧主题的性别的信息并添加新信息,正如我们在前面的步骤中所做的那样。
C=C-1+(1-)
最后,我们需要决定我们要输出的内容,此输出将基于我们的单元状态,但将是过滤版本,首先,我们运行一个sigmoid层,它决定我们要输出的单元状态的哪些部分,然后我们将单元状态设置为tanh(将值推到介于-1和1之间)并将其乘以sigmoid门的输出,以便我们只输出我们决定的部分。
对于语言模型示例,由于它只是看到一个主题,他可能想要输出与动物相关的信息,以防接下来会发生什么,例如,他输出主语是单数还是复数,一边我们知道动词应该与什么形式供轭。
O=(Wh-1,x+b)
h=O*tanh©
Bilstm神经网络
BiLSTM(双向长短时记忆网络)是一种特殊的循环神经网络(RNN),它能够处理序列数据并保持长期记忆。与传统的RNN模型不同的是,BiLSTM同时考虑了过去和未来的信息,使得模型能够更好地捕捉序列数据中的上下文关系。在本文中,我们将详细介绍BiLSTM的数学原理、代码实现以及应用场景
基于双向长短期神经网络bilstm的径流量预测,
部分代码
clc
clear
close all
rng(1)
a,ax,ay = xlsread('数据搜集.xlsx');
num = a(:,2:end);
n = randperm(length(num));
m = 13;
input_train =num((1:m),1:4);%训练数据输出数据
output_train = num((1:m),5);%训练数据输入数据
input_test1 = num(14:17,1:4);%验证数据输出数据
output_test1 = num(14:17,5);%验证数据输入数据
input_test = num(18:21,1:4);%测试数据输出数据
output_test = num(18:21,5);%测试数据输入数据
inputn,inputps=mapminmax(input_train',-1,1);%训练数据的输入数据的归一化
outputn,outputps=mapminmax(output_train',-1,1);%训练数据的输出数据的归一化de
%% Define Network Architecture
% Define the network architecture.
numFeatures = 4;%输入层维度
numResponses = 1;%输出维度
% 200 hidden units
numHiddenUnits = 130;%第一层维度
% a fully connected layer of size 50 & a dropout layer with dropout probability 0.5
funbilstm
% Specify the training options.
% Train for 60 epochs with mini-batches of size 20 using the solver 'adam'
maxEpochs = 100;%最大迭代次数
miniBatchSize = 2;%最小批量
% the learning rate == 0.01
% set the gradient threshold to 1
% set 'Shuffle' to 'never'
options = trainingOptions('adam', ... %解算器
'MaxEpochs',maxEpochs, ... %最大迭代次数
'MiniBatchSize',miniBatchSize, ... %最小批次
'InitialLearnRate',0.001, ... %初始学习率
'GradientThreshold',0.01, ... %梯度阈值
'Shuffle','every-epoch', ... %打乱顺序
'Plots','training-progress',... %画图
'Verbose',0); %不输出训练过程
%% Train the Network
net = trainNetwork(inputn,outputn,layers,options);%开始训练
inputn_test=mapminmax('apply',input_test',inputps);
inputn_test1=mapminmax('apply',input_test1',inputps);
%% Test the Network
y_pred = predict(net,inputn_test,'MiniBatchSize',2)';%测试仿真输出
y_pred1 = predict(net,inputn_test1,'MiniBatchSize',2)';%测试仿真输出
y_pred(y_pred<-1)=-1;
y_pred=(mapminmax('reverse',y_pred',outputps))';
y_pred1=(mapminmax('reverse',y_pred1',outputps))';
y_pred0 = predict(net,inputn,'MiniBatchSize',2);%训练拟合值
y_pred0=(mapminmax('reverse',y_pred0,outputps));
weilai = \[\];
inp = num(end,2:end)';
for ii = 1:5
inputn_testw=mapminmax('apply',inp,inputps);
y_predw = predict(net,inputn_testw,'MiniBatchSize',2)';%测试仿真输出
end
%
% load maynet.mat
y_pred=(double(y_pred));
figure%打开一个图像窗口
plot(14:17,y_pred1(:,1),'b-')%黑色实线,点的形状为
hold on%继续画图
plot(18:21,y_pred(:,1),'k-')%黑色实线,点的形状为
hold on%继续画图
plot(14:21,output_test1(:,1) ;output_test(:,1),'r-o')%红色实线,点的形状为o
hold off%停止画图
title('测试图')%标题
ylabel('碳排放量(亿吨)')%Y轴名称
legend('测试值','预测值','实际值','Location','southeast')%标签
set(gca,'fontsize',12)
error1 = y_pred-output_test;%误差
figure
plot(error1(:,1),'k-')
title('测试误差图')
ylabel('误差(亿吨)')
set(gca,'fontsize',12)
MSE,RMSE,MBE,MAE =MSE_RMSE_MBE_MAE(output_test,y_pred);
result_table = table;
result_table.sim = y_pred;
result_table.true = output_test;
writetable(result_table,'./结果.csv')
function MSE, RMSE, MBE, MAE,MAPE =MSE_RMSE_MBE_MAE(confirm_out,simout)
%confirm_out 真实验证值
%sim_out 预测值
N=length(simout);
MSE=sum( (simout-confirm_out).^2 ) /N ; %均方误差
RMSE=sqrt(sum( (simout-confirm_out).^2 ) /N ); %均方根误差
MAE=sum( abs(simout-confirm_out) ) /N ; %平均绝对误差
MBE=sum( simout-confirm_out ) /N ;%平均偏差
MAPE=sum( abs(simout-confirm_out)./ confirm_out) /N ; %平均绝对误差
end
结果图
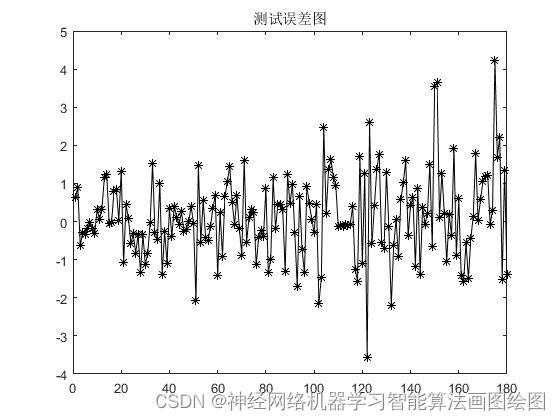
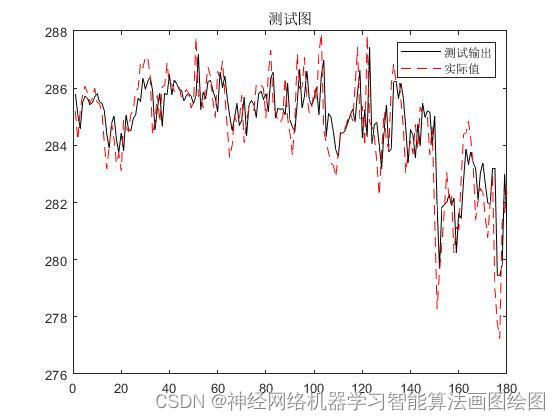
结果分析
从图中可以看出来,基于双向长短期神经网络bilstm的径流量预测,,预测准确,泛发性好
展望
双向长短期神经网络在处理有时间关联性的问题方面,拥有独特的优势,预测结果更平滑,稳定,并且可调参,路径跟踪属于时间序列的数据,,双向LSTM可以和其他是算法结合,比如粒子群优化双向LSTM参数,DBN+双向LSTM,等
参考论文
基于LSTM的负荷预测,基于BILSTM的负荷预测,基于GRU的负荷预测,基于BIGRU的负荷预测,基于BP神经网络的负荷预测_gru负荷预测-CSDN博客 https://blog.csdn.net/abc991835105/article/details/135724288